

Passer d'un notebook de recherche à un service de production performant est souvent un parcours du combattant. Entre les versions de librairies qui divergent, les formats de modèles incompatibles d'un framework à l'autre, et des performances d'inférence décevantes, le déploiement devient vite un goulot d'étranglement.
Ce problème se pose avec d'autant plus d'acuité aujourd'hui. Les ressources GPU sont de plus en plus sollicitées et coûteuses, et la question du format de serving n'a jamais été aussi stratégique : quel format pour quel usage, et comment unifier le déploiement quel que soit l'outil utilisé en amont ?
C'est précisément là qu'ONNX entre en jeu.
1. Au fait, c’est quoi ONNX ?
Lancé en 2017 par Microsoft et Meta, ONNX (Open Neural Network Exchange) n’est pas un énième framework de Deep Learning. C’est un standard ouvert conçu pour que les modèles soient enfin portables.
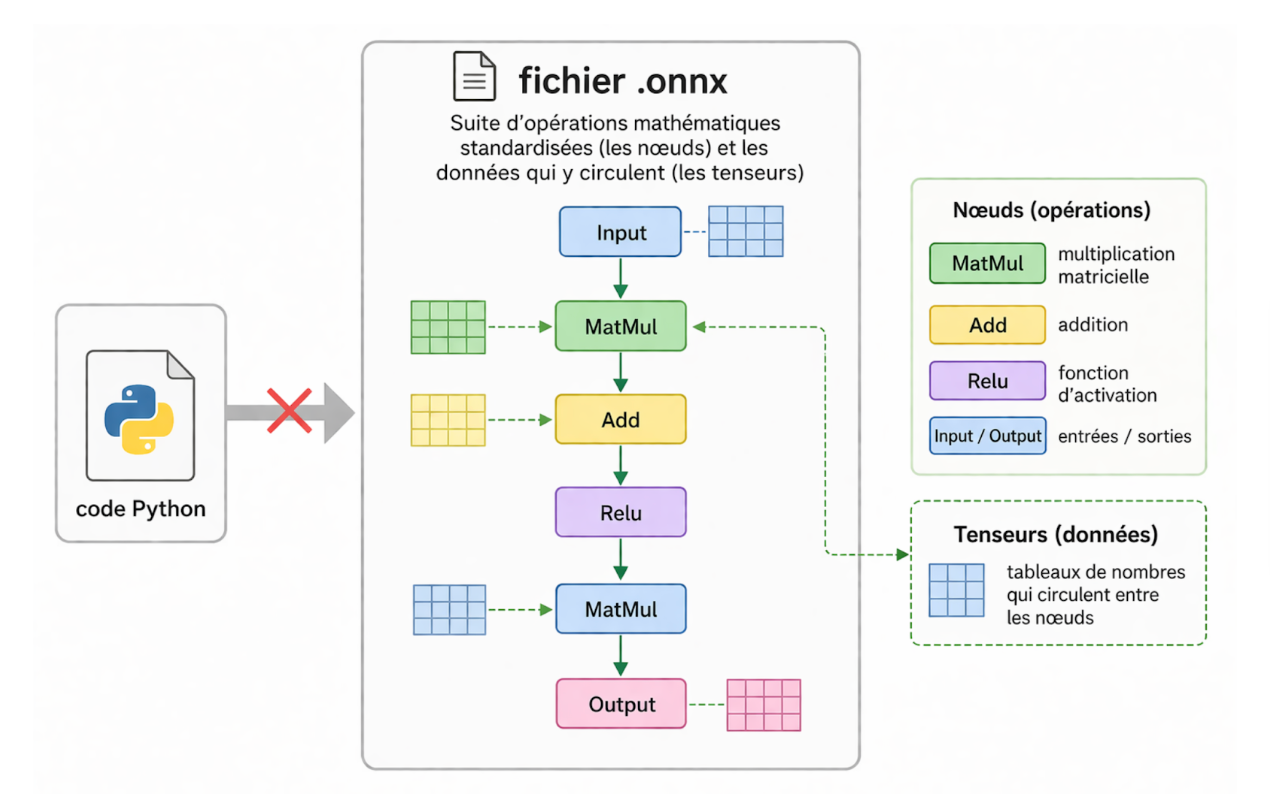
L'idée est de traduire votre code (souvent impératif et lié à un framework) en un graphe de calcul statique. Dans ce fichier .onnx, on ne trouve plus de code Python, mais une suite logique d’opérations mathématiques standardisées (les nœuds) et les données qui y circulent (les tenseurs).
Pour que cela fonctionne, ONNX repose sur un binôme :
- Le format de fichier : Une structure rigoureuse qui fige l'architecture et les poids du modèle.
- ONNX Runtime (ORT) : Le moteur qui va "lire" ce fichier. C’est lui qui fait le gros du travail en exécutant le modèle de la manière la plus optimisée possible sur le matériel donné.
2. Pourquoi s'embêter à convertir ses modèles ?
On ne passe pas à ONNX juste pour le plaisir de rajouter une étape de conversion. On le fait pour répondre à des problématiques concrètes de production.
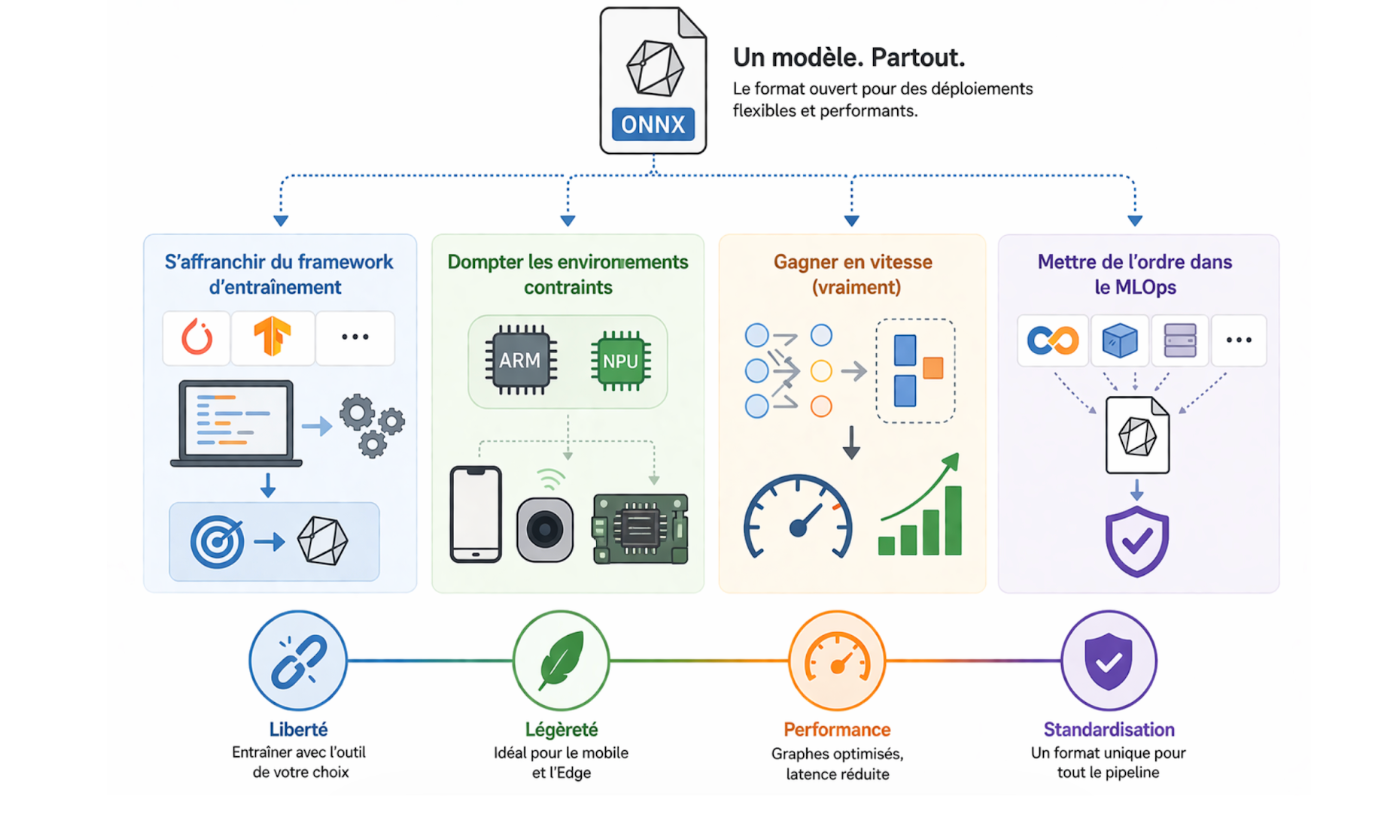
S'affranchir du framework d'entraînement
Une équipe data science travaille sous PyTorch, mais l'infrastructure de prod est en C++ ou en .NET. Sans ONNX, ce désalignement impose soit de contraindre les choix techniques de l'équipe data, soit de réécrire le serving. ONNX sert de pont : on entraîne d'un côté, on déploie de l'autre, sans friction.
Gérer les environnements contraints
Sur des cibles de déploiement mobile ou embarquées (objets connectés, edge), embarquer TensorFlow ou PyTorch est impensable — le poids des dépendances le rend inenvisageable. ONNX Runtime est significativement plus léger et taillé pour ces architectures (ARM, NPU).
Gagner en vitesse d'inférence
ONNX Runtime ne se contente pas d'exécuter le graphe, il l'optimise. Il peut par exemple fusionner plusieurs couches consécutives pour réduire le nombre d'opérations. En pratique, on observe régulièrement des gains de latence significatifs par rapport à une inférence native PyTorch, sans modification du modèle.
Choisir le bon format selon le cas d'usage
ONNX n'est pas le seul format de sérialisation disponible. Selon le contexte, d'autres formats coexistent et ont chacun leur périmètre :
- Pickle / joblib : format par défaut de scikit-learn, simple mais non sécurisé et non portable entre versions Python
- TorchScript : format natif PyTorch pour la production, mais limité à l'écosystème PyTorch
- Safetensors : format léger et sécurisé pour sérialiser les poids, sans le graphe de calcul, utilisé massivement dans l'écosystème Hugging Face
- GGUF : format optimisé pour les LLMs, pensé pour l'inférence locale sur CPU avec quantization intégrée
ONNX se positionne comme le format le plus polyvalent pour les modèles ML classiques et les architectures de vision : portable, optimisé à l'exécution, et supporté par la majorité des runtimes et plateformes de serving.
Platform engineering : standardiser le serving à l'échelle
Dans une logique de platform engineering, ONNX devient un levier de standardisation du serving. Plutôt que de laisser chaque équipe gérer son propre runtime (PyTorch ici, TensorFlow là, scikit-learn ailleurs), adopter ONNX comme format de sortie unique permet de construire une plateforme de serving homogène : un seul runtime à maintenir, une seule interface à exposer, des pipelines de validation automatisables. C'est particulièrement pertinent dans les organisations qui gèrent plusieurs modèles en production et cherchent à réduire la charge opérationnelle des équipes platform.
3. Comment l'utiliser ?
Le passage d'un modèle natif à une inférence ONNX optimisée suit un certain workflow en trois étapes : l'exportation, la validation et l'exécution.
Étape 1 : Exporter (Convertir le modèle)
C'est l'étape où l'on traduit le modèle depuis son framework d'origine vers le format ouvert .onnx. La méthode varie selon l'outil utilisé :
- PyTorch : On utilise la fonction native torch.onnx.export. Le processus repose souvent sur le "tracing" : on fournit une donnée fictive (dummy input) au modèle, et PyTorch enregistre toutes les opérations mathématiques effectuées pour tracer le graphe de calcul.
- TensorFlow / Keras : L'export n'est pas toujours natif. On utilise généralement la librairie dédiée tf2onnx pour convertir un modèle sauvegardé (SavedModel ou checkpoint) en fichier ONNX.
- Scikit-learn : Pour les modèles de ML classique (Random Forest, SVM, etc.), on utilise sklearn-onnx, qui convertit les pipelines scikit-learn en opérateurs ONNX standardisés.
Étape 2 : Vérifier (Inspecter le fichier .onnx)
Une fois le fichier obtenu, il est crucial de s'assurer que la conversion s'est bien déroulée et de comprendre l'interface du modèle (ses entrées/ sorties). Deux outils sont indispensables :
- Onnx.checker : C'est une fonction Python (onnx.checker.check_model()) qui valide la conformité du fichier .onnx aux spécifications officielles du standard (versions des opérateurs, types de tenseurs, etc.).
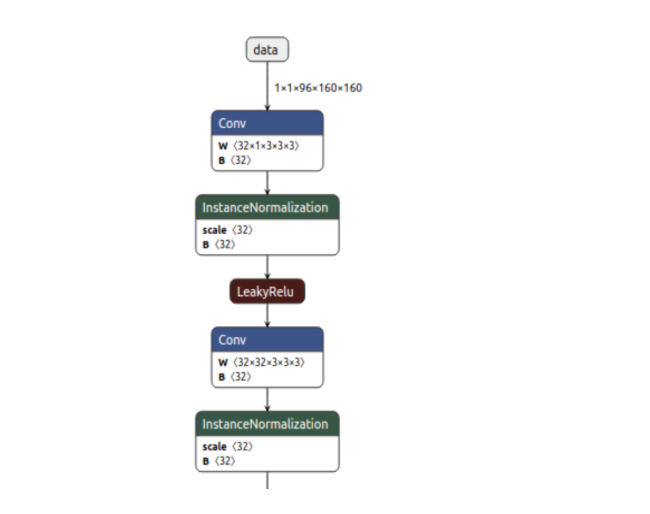
- Netron : C'est l'outil de visualisation standard de l'industrie. Netron permet d'ouvrir le fichier .onnx et d'inspecter visuellement tout le graphe de calcul. Il est essentiel pour identifier le nom exact des tenseurs d'entrée (input_name) et de sortie (output_name), ainsi que leurs dimensions (shapes), informations nécessaires pour l'étape suivante.
Étape 3 : Lancer (Inférence avec ONNX Runtime)
C'est ici que l'on utilise ONNX Runtime (ORT) pour exécuter le modèle. ORT remplace le framework d'entraînement (PyTorch, TF) en production.
3.1. Installation
Les paquets sont disponibles sur PyPi. Vous devez choisir entre la version CPU (plus légère) et GPU (pour de meilleures performances sur matériel compatible Nvidia) :
# Pour une exécution sur CPU uniquement
pip install onnxruntime
# Pour profiter de l'accélération GPU (via CUDA)
pip install onnxruntime-gpu
3.2. Code d'exécution (Python)
Le workflow de code est standardisé et extrêmement efficace :
Importer ORT et créer une session d'inférence en chargeant le modèle.
import onnxruntime
session = onnxruntime.InferenceSession("chemin_vers_mon_modele.onnx")Récupérer les informations sur le modèle. Netron vous a donné les noms des tenseurs, mais vous pouvez aussi les interroger programmatiquement :
# Récupérer les métadonnées (nom des entrées/sorties)
input_info = session.get_inputs()
output_info = session.get_outputs()
print(f"Modèle avec {len(input_info)} entrée(s) et {len(output_info)} sortie(s).")Lancer l'inférence avec la méthode run(). Il faut passer un dictionnaire mappant les noms des entrées à vos données réelles (souvent des tableaux NumPy). Vous pouvez aussi spécifier une liste des noms de sorties à retourner (à laisser vide pour toutes les sorties).
# Exemple d'inférence
# data_x est votre tableau NumPy contenant les données à prédire
results = session.run(["nom_du_tenseur_de_sortie"], {"nom_du_tenseur_dentree": data_x})4. Avantages
Interopérabilité entre frameworks
ONNX joue le rôle d'un format pivot : peu importe que votre modèle ait été entraîné avec PyTorch, TensorFlow ou scikit-learn, il s'exporte en .onnx et s'exécute de la même façon. Cela découple la phase d'entraînement de la phase de déploiement : une équipe data science peut travailler avec ses outils habituels sans contraindre les choix de l'équipe MLOps côté serving.
Optimisations hardware automatiques
ONNX Runtime utilise le concept d'Execution Providers : des plugins qui font le lien entre le graphe ONNX et un hardware spécifique. Au lancement de l'inférence, le runtime sélectionne automatiquement le meilleur provider disponible sur la machine : CPUExecutionProvider par défaut, CUDAExecutionProvider sur GPU Nvidia, CoreMLExecutionProvider sur Apple Silicon, ou encore des providers dédiés aux NPUs sur les devices edge.
Concrètement, le même fichier .onnx tourne sans modification sur une machine de dev CPU, un serveur GPU en prod, ou un Raspberry Pi. C'est le runtime qui gère les optimisations bas niveau (fusion d'opérateurs, parallélisme, quantization à l'exécution) , pas le développeur. Des retours terrain confirment des gains de performance significatifs par rapport à PyTorch natif, avec des économies directes sur les coûts de serving.
Portabilité multi-environnements
Un fichier .onnx s'exécute sur n'importe quel environnement disposant d'un ONNX Runtime, sans avoir à embarquer le framework d'entraînement. Que ce soit côté serving Python, dans une application .NET, ou sur un device edge, le modèle reste le même. C'est un avantage dans les organisations où plusieurs équipes, langages ou plateformes coexistent.
Simplicité côté inférence
ONNX Runtime a des dépendances légères. Côté serving, pas besoin de recréer l'environnement Python d'entraînement, le runtime suffit. Cela réduit la complexité des images Docker, accélère les cold starts, et limite les risques de régression liés aux upgrades de dépendances.
Sécurité par rapport à pickle
Le format .pkl exécute du code arbitraire au chargement, un vecteur d'attaque connu. ONNX est un format déclaratif : il décrit un graphe de calcul, sans exécution de code. C'est un argument concret pour standardiser le format de sérialisation des modèles dans une organisation.
Standardisation des pipelines MLOps
Adopter ONNX comme format de sortie unique impose un contrat clair entre data scientists et équipes de déploiement : peu importe le framework utilisé en amont, le livrable est toujours un .onnx. Cela simplifie les pipelines CI/CD, permet d'automatiser la validation des modèles et réduit les frictions entre équipes.
Pérennité des modèles
Contrairement à pickle, un fichier .onnx reste chargeable après des upgrades majeurs de librairies ou de version Python. C'est un avantage concret pour comparer un ancien modèle à un nouveau, auditer un modèle en production, ou rejouer une inférence des mois plus tard.
5. Inconvénients
Conversion non triviale sur les modèles complexes
L'export vers ONNX repose sur la traçabilité du graphe de calcul du modèle. Les architectures avec des flux de contrôle dynamiques posent problème. Certains modèles nécessitent de réécrire des parties du code pour les rendre exportables, ce qui peut représenter 1 à 2 jours de travail, et dans certains cas, la conversion est tout simplement impossible.
Support des graphes dynamiques limité
ONNX a été conçu pour des graphes de calcul statiques, c'est-à-dire des modèles dont la structure est fixe à l'export. Les LLMs utilisent des mécanismes dynamiques (gestion du KV cache, longueur de séquence variable…) que ONNX supporte mal. Pour cette raison, ONNX n'est pas adapté au déploiement de LLMs. D'autres formats et runtimes ont émergé pour répondre spécifiquement à ce cas d'usage, comme GGUF.
Debugging difficile
En cas d'erreur à l'inférence, le message peut être cryptique. Contrairement à PyTorch où la stack trace remonte directement au code Python, une erreur ONNX renvoie souvent à des problèmes de shape ou de type de tenseur difficiles à localiser sans tooling dédié (Netron pour l'inspection du graphe, onnx.checker pour la validation).
Performances dégradées dans certains scénarios
ONNX Runtime n'est pas systématiquement plus rapide. À gros batch size ou sur des architectures peu courantes, les performances peuvent être inférieures à celles d'un runtime natif optimisé. Il est recommandé de benchmarker avant de généraliser l'adoption.
Dépendance à l'écosystème de build
En dehors des plateformes disposant de wheels précompilés (Linux x86, Windows), installer et compiler ONNX Runtime peut être complexe. Sur des environnements non standards, la mise en place peut s'avérer laborieuse.
Conclusion : Le standard qui réconcilie Data et Ops
ONNX ne résout pas tous les problèmes de déploiement, et ce serait une erreur de le présenter comme une solution universelle. Il ne convient pas aux LLMs et son adoption nécessite un effort organisationnel.
Mais pour les modèles ML classiques, il reste aujourd'hui le format le plus solide pour standardiser le serving à l'échelle. Il découple proprement l'entraînement du déploiement, s'adapte au hardware disponible sans modification du modèle, et s'intègre naturellement dans une logique de platform engineering.
Dans un contexte où les ressources GPU sont de plus en plus contraintes et coûteuses, optimiser ce qu'on peut sur CPU avec un runtime léger et portable n'est plus un détail.
