

Introduction
Cet article est la seconde partie de l'article sur la KubeCon & CloudNativeCon 2026 (Partie 1)
Vous y retrouverez une synthèse des concepts et nouveautés qui ont été présentés au cours des conférences auxquelles j’ai pu assister
Argocd MCP - 1 an après, ça donne quoi ?
Initialement, les LLM sont limités, car ils ne peuvent que générer du texte, et ne peuvent pas interagir avec le monde réel. Pour les rendre interactifs, le protocol MCP (Model Context Protocol) sert de connecteur universel entre un client IA, et un service externe, tel qu’un cluster Kubernetes, un compte Github, ou un service tel qu’ArgoCD.
Ce protocole, s’appuyant sur le format JSON RPC, repose sur des outils (fonctionnalités), ressources (éléments observables), des prompts (instructions données à un modèle IA), et permet également l’authentification de ses utilisateurs via du SSO.
Pour mettre en pratique le concept de MCP, l’équipe ArgoCD a créé un projet expérimental open source nommé argocd-mcp-server qui implémente une correspondance directe avec toutes les actions réalisables via l’interface d’ArgoCD : l'IA découvre les outils disponibles, choisit le bon, exécute l'action (comme synchroniser une application) et traduit le résultat pour l'utilisateur. Trois cas d'usage puissants sont démontrés :
- La création d'applications à partir de manifestes YAML fournis en texte brut.
- La création automatique d'applications pour chaque répertoire d'un dépôt de code.
- Rollback automatique : l'agent IA déploie une nouvelle version, la surveille un certain temps et, si l'application se dégrade, restaure automatiquement la version précédente.
Dans un contexte où la scalabilité est un enjeu, où sont hébergés des milliers d’applications dans des centaines de clusters, et où certaines équipes manquent d’expertise technique, le support technique peut devenir un goulot d’étranglement à cause du temps de diagnostic.
C’est dans ce contexte que la première tentative d’utilisation du MCP ArgoCD échoua. Bien que ce dernier permettait l’extraction des logs, des évents Kubernetes, et l’état des applications pour les transmettres à un LLM capable de diagnostiquer les pannes, l’adoption de la part des utilisateurs fût très faible, car ceux-ci, familier avec Kubernetes, préféraient consulter directement les logs, plutôt que de cliquer sur un bouton et attendre le retour de l’IA.
Ce MCP est donc d’avantage à destination d’équipes gravitant autour de l’écosystème Kubernetes, sans avoir les compétences techniques à son administration. Intégré dans un canal, ou avec un chatbot, il révèle son intérêt pour les équipes moins techniques, ou les développeurs, qui peuvent à présent diagnostiquer des erreurs, sans avoir besoin d’ouvrir de tickets.
Comment sécuriser l’accès aux MCP en entreprise ?
Le "Model Context Protocol" (MCP) est un protocole conçu pour permettre aux modèles d'IA de communiquer avec des bases de données et des fonctionnalités externes via des adaptateurs unifiés, évitant ainsi d'avoir à écrire du code d'intégration personnalisé pour chaque API. Cependant, son adoption rapide a révélé de grands défis pour les entreprises en matière de sécurité, d'observabilité, de conformité et de gestion des locataires (tenancy).
Initialement, les MCP ont été pensés pour des serveurs déployés localement sur le poste du développeur, nécessitant de stocker des clés d'API ou des access token directement sur la machine. Dans un contexte d’entreprise, ne pas avoir de vision sur les tokens générés pour les utilisateurs de leurs outils, et sur leurs permissions représente un risque en termes de sécurité et de conformité, d’autant plus dans le cas d’utilisation de serveurs SaaS pour MCP.
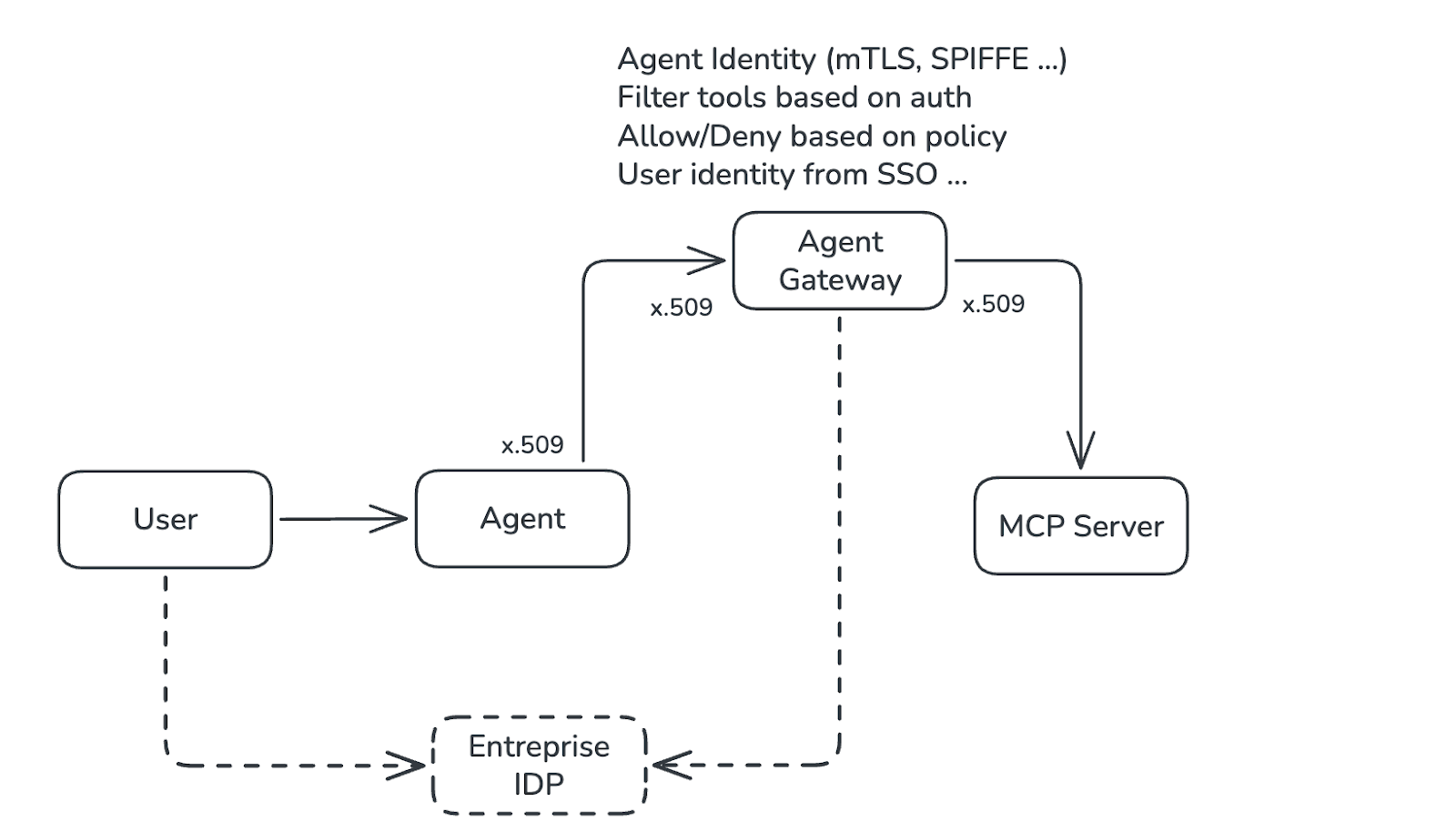
Dès lors que l’utilisation des MCP est adoptée en entreprise, la solution pour simplifier la gestion des access tokens, et l’organisation des MCP consiste à les héberger sur un serveur distant, et à les exposer via leur HTTP en les faisant passer par une Agent Gateway. En se basant sur l’API Gateway de Kubernetes, celle-ci optimise la connexion entre votre agent IA, et tous autres agents déployés dans votre environnement.
Déployé de la sorte, on peut alors centraliser et imposer des politiques d’authentification, d’autorisation, et mettre en place du monitoring sur ces MCPs avant que l’IA ne puisse accéder aux données internes de l’entreprise.
Il est donc possible de gérer l’authentification aux serveurs MCP via les outils SSO mis en place dans l’entreprise. L’approche consiste à lier l’accès MCP à un fournisseur d’identité interne, tel que Okta par exemple. On peut ainsi dynamiquement autoriser ou bloquer l’accès total au MCP, ou limiter les fonctionnalités suivant le profil de l’utilisateur.
Pour plus d’informations, je vous invite à consulter la documentation sur l'autorisation des MCP, ainsi que les bests practices en matière de sécurité
Vous pouvez également consulter le blog de Solo.io
De l’Ingress vers l’API Gateway, les solutions pour faciliter cette migration
Pendant longtemps, Ingress a été l'API principale pour gérer le trafic HTTP externe, mais son utilisation s'est complexifiée avec le temps. Ingress manquait de portabilité et la multiplication des fonctionnalités a conduit à une gestion fastidieuse via de multiples annotations sur un seul objet partagé par de nombreuses personnes. L'archivage très récent du projet Ingress NGINX rend la transition vers l'API Gateway encore plus logique et inévitable.
L'API Gateway bénéficie d'une conception hautement collaborative développée en dehors du projet Kubernetes, permettant des évolutions plus rapides. L'une de ses forces majeures est la séparation des rôles à travers ressources:
- GatewayClasses : Elles permettent aux utilisateurs de comprendre facilement et explicitement les fonctionnalités disponibles via le modèle de ressources Kubernetes
- Gateways : Ils permettent le partage des Load Balancer et des VIPs en autorisant des ressources de routage indépendantes à se connecter à la même Gateway.
- Typed Routes & Backends : API Gateway supporte différents types de routes et de backend afin d’être flexible dans le choix des protocoles (HTTP, GRPC…) ou backend targets (Service Kubernetes, bucket, fonctions…)
Voir la documentation sur l’API Gateway
La migration de l’Ingress traditionnel vers l’API Gateway n’est donc aujourd’hui plus une option. Cependant, de nombreux acteurs mettent à disposition des Controllers répondant à des besoins parfois différents les uns des autres. Il peut ne pas être évident de choisir alors parmi plus de 40 Controllers.
Pour faciliter ce choix, et trouver le Controller qui correspond à nos besoin, les mainteneurs du projet API Gateway ont mis à disposition un Controller Matching Wizard qui donne une liste de Controller basée sur la liste des fonctionnalités souhaitées (est-ce qu’on a besoin de routing HTTP? De requests Mirroring ? De gestion des CORS? … )
Il existe également des outils développés par la communauté qui permettent de faciliter cette migration :
- Ingress2Gateway : Un outil qui lit vos ressources Ingress et génère automatiquement le code YAML approprié pour les CRD de l'API Gateway.
- Gtwctl : Un outil en ligne de commande qui aide à visualiser et à comprendre comment les multiples objets réseau interagissent entre eux, capable même de générer un graphique des connexions.
Contrat API pour les ressources Crossplane
Crossplane est un outil de définition d’infrastructure Cloud, à l’instar de Terraform, qui se déploie dans votre cluster Kubernetes. Grâce à ces Custom Resources Definition (CRDs), il permet de traîter les composants de votre infrastructure comme des composants Kubernetes, notamment via la définition de manifestes et à l'interface avec votre cloud provider. Couplé à un modèle GitOps se basant sur le déploiement avec ArgoCD, on obtient une stack solide permettant le scaling à grande échelle.
Cependant, un problème organisationnel survient : Comment définir la responsabilité des équipes sur les ressources Cloud ainsi créées, lorsque les stacks à déployer ont des dépendances avec des ressources gérées par d’autres équipes ? On peut se représenter ce problème en prenant l’exemple de la création d’une landing zone, qui va embarquer des services de sécurité gérés par une autre équipe dédiée.
En mettant en place un contrat d’API, on cherche à valider en amont la définition du manifeste. Celui-ci se compose d’un schéma explicite, une documentation générée, et de règles de versionnement. Grâce à ce contrat, le client sait exactement ce qu’il obtiendra, et le processus d’intégration (CI) peut valider les ressources avant leur déploiement.
Exemple d’un contrat d’API (source)
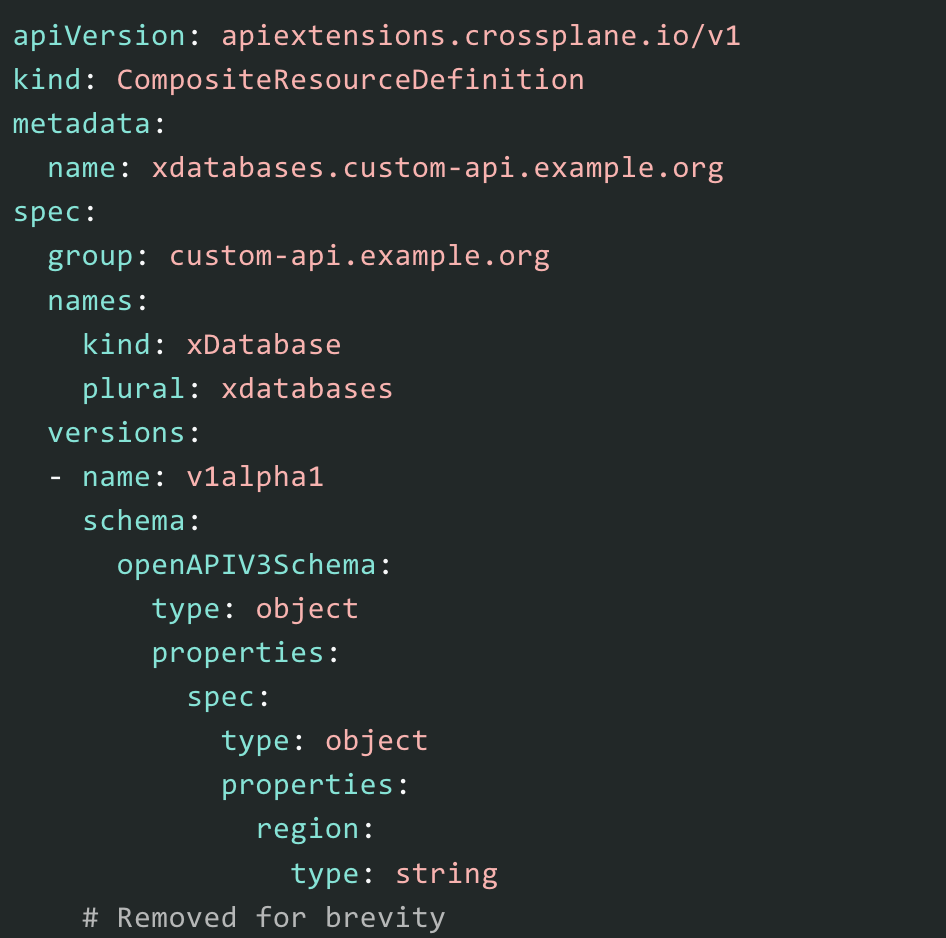
Et de son utilisation
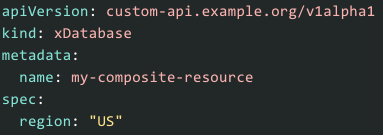
Cette fonctionnalité permet donc de définir des manifestes Crossplane, qui auront pour finalité de déployer des composants d’infrastructure cloud, dans lesquels on peut ajouter des champs customs permettant d’assurer la traçabilité de ces composants, et donc de résoudre la problématique de définition de la responsabilité des équipes.
Ceux-ci sont disponibles une fois la ressource Crossplane créée, dans la section .status.<custom_field>.
Pour plus d’informations sur l’implémentation des Composite Resources, consultez cette documentation qui reprend point par point les éléments abordés ici.
Conclusion
L’organisation des équipes, et des entreprises autour de Kubernetes pousse les projets déployés au sein de ce dernier à évoluer et devenir plus accessibles pour les utilisateurs. On se rapproche davantage d’une offre plateforme, où prime la clarté et la facilité de gestion de ressources par équipe. On découvre alors que les principaux utilisateurs de cette plateforme ne sont pas, en première intention, les OPS qui pendant des années opéraient dans cet écosystème, mais des profils moins experts avec une vision plus métier sur les services déployés…
Ceci a été mon sentiment tout au long de cette KubeCon, où Kubernetes devient plus flexible, où ses contraintes physiques deviennent de plus en plus invisibles aux yeux des utilisateurs. La multiplication des solutions boostées à l’IA prend davantage de place sur la scène Kubernetes, où celui-ci s’adapte pour intégrer de façon plus transparente les contraintes liées à l'utilisation de ces mêmes solutions embarquant de l’IA.
