

Une fois de plus, la KubeCon revient ! Cette année, Amsterdam a pu accueillir cet évènement avec ses 13 000 visiteurs, et quelques centaines d'exposants sur la semaine du 23 Mars. Riche en annonces, conférences et de présentations en tous genres, c’était l’occasion idéale de s’informer sur les dernières nouveautés, d’échanger avec les mainteneurs des différents projets et initiatives CNCF, mais également de constater de ses propres yeux les changements majeurs qui s'opèrent dans l’écosystème Kubernetes.
Dès la Keynote, on se rend compte que l’IA occupe une place centrale dans les discussions, en commençant par l’annonce du partenariat Platinum avec Nvidia, et sa contribution de 4 millions de dollars à la CNCF pour faciliter l’accès aux GPU des projets et initiatives CNCF. Une place est également accordée à des projets comme LLM-D, Kueue, ou encore F5, qui se concentrent sur des optimisations Kubernetes dédiées à l’IA (distributed LLM inference, networking, scheduling …).
Cependant, bien que l’engouement pour l’IA se fait sentir, on relève tout de même une volonté de faire évoluer l’écosystème Kubernetes vers un écosystème plus abordable pour des utilisateurs non OPS. De faciliter son usage en le rendant plus dynamique, et plus souple, afin de permettre l’intégration d’offres plateforme, jusqu’à vouloir rendre Kubernetes complètement transparent.
Vous pourrez, tout au long de cet article, découvrir une synthèse des conférences auxquelles j’ai pu assister, ainsi que mes impressions.
Helm 4 est sorti, que faut-il retenir ?
Helm, le gestionnaire de paquets pour Kubernetes, célèbre ses 10 ans d'existence avec la sortie de Helm 4. Sortie en novembre dernier, cette nouvelle version n’est pas une réécriture, comme l’ont pu laissé sous-entendre certaines rumeurs, mais vient accompagnée de son lot de nouveautés.
Parmi celles-ci, on compte l’ajout d’un moteur de plugins basé sur WASM (WebAssembly), l’intégration du Server-Side Apply, ou encore la préparation de l’API Chart v3.
La structure de Helm 4 prend en compte les nouvelles fonctionnalités des Charts en version 3 (apiVersion: v3), tout en garantissant une compatibilité avec la version 2. Les propositions de changement majeurs suivent un processus de transparence : HIPs (Helm Improvement Proposals), inspirés des PEPs de Python. Cette version permettra de résoudre des limitations techniques, offrant par exemple du séquençage de ressources, l’utilisation de moteurs de templates alternatifs à Go, la modification du .helmignore pour se rapprocher du fonctionnement du .gitignore, ou encore, définir les dépendances de chaques Charts sous forme de plugins.
Une attention est particulièrement portée sur la simplification du système de signature des Charts Helm. Historiquement basé sur PGP, il sera remplacé par de nouveaux mécanismes de signatures comme Cosign, ou SSH keys. Le support de la norme OCI (Open Container Initiative) permet désormais la définition d’un fichier policy.json, utilisable pour bloquer des registries. Enfin, le mirroring de registry est maintenant pris en charge, et facilitera la migration des Charts d’une registry à une autre.
Helm 4 n’est donc pas une réécriture de Helm 3, il vient avec son lot de nouveautés permettant une utilisation plus simple des charts tout en ajoutant des fonctionnalités intéressantes quant à la gestion et à la protection de celles-ci dans un contexte d’entreprise.
Pour plus d’informations, Voir la Release page et la page d'Overview
Faîtes vous vraiment confiance à vos PDB ?
Un Pod Disruption Budget (PDB) est une ressource Kubernetes destinée à empêcher que trop de Pods d’une même application ne soient supprimés simultanément. Ils garantissent la disponibilité des applications dans un contexte à forte scalabilité.
Cependant, les PDBs ne protègent que contre les perturbations volontaires, transitant via des appels API du type Evictions (par exemple : la mise à jour d’un déploiement, le nettoyage d’un nœud, de l’autoscalling …).
Ils ne sont également pas pris en compte lors de perturbations involontaires, telles qu’une panne matérielle, une coupure réseau, un manque de ressources sur une nœud, ou la suppression d’instances préemptibles (Spot).
On peut également rencontrer des problèmes lorsque la configuration est trop stricte, (maxUnavailable: 0, minAvailable: 100%).
Cette configuration bloque entièrement l’API d’éviction, et si on essaye de vider un nœud, le processus bloquera indéfiniment, car le PDB interdira le déplacement des pods vers un autre nœud, et paralysera ainsi les opérations de maintenance de la plateforme.
Face à cette problématique, l’administrateur dispose de trois leviers d’actions :
- Contourner l’API d’évictions en supprimant directement la ressource, ignorant ainsi la protection du PDB
- Forcer le grace-period=0. Si le nettoyage du node n’aboutit pas dans le temps imparti, cette option force la suppression des pods, en ignorant le PDB
- Utiliser les Priority Classes, qui permettent d’assigner une priorité relative aux pods. Si le cluster est plein, un pod ayant une haute priorité peut supprimer de force un pod de priorité inférieure, pour prendre sa place sur un noeud, ce qui passera outre les restrictions du PDB
Parmi ces possibilités, celle qui semble la plus flexible est celle qui consiste à définir des Priority Class pour nos workloads, hiérarchisées suivant la criticité de nos applications. Ne nécessitant pas d’interventions manuelles, ni de spécifier des paramètres supplémentaires, le combo Priority Class - PDB assure la haute disponibilité de nos workloads de façon transparente.
Gérer les ResourceQuotas au niveau Cluster avec Kro et Kyverno
Kubernetes nous offre la possibilité, grâce à une ressource appelée “Quota”, de limiter par namespace la quantité de CPU/RAM allouées aux applications déployées. Dans le cas d’une organisation déployant les projets de plusieurs équipes dans le même cluster, il est compliqué d’obtenir une vision sur la quantité totale de Quotas définis pour chaque équipe, ainsi que de les faire évoluer. A cette problématique de maintenabilité et de visibilité, la combinaison de Kro et Kyverno semble offrir une solution en permettant de définir des Quotas par équipes au niveau du cluster.
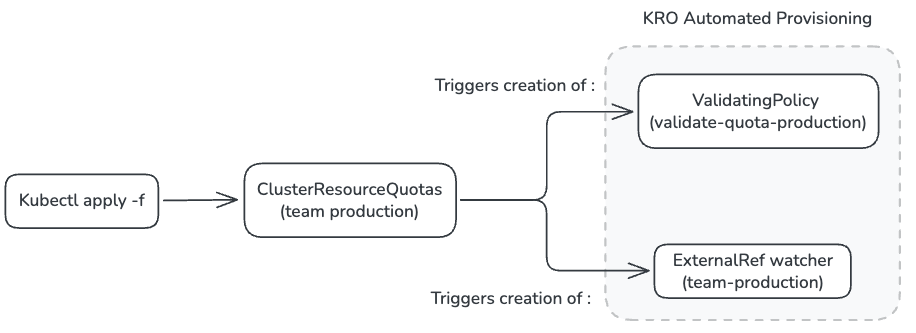
Tout d’abord, Kro est un opérateur définissant un ensemble de ressources Kubernetes via la création d’une ressource RGD (Resource Graph Definition). Grâce au RGD, il déploie les composants nécessaires au bon fonctionnement d’un service, et les observe continuellement dans le cluster. Il permet également de définir une ressource Cluster Resource Quota :
Enfin, Kyverno permet de définir des policies dans le cluster afin de valider la création de ressources Kubernetes. Il vérifie si les requêtes la définition d’une ressource (par exemple, Deployment) enfreint les règles mises en place par ces policies, afin de valider, ou de rejeter la création de cette ressource.
En définissant les règles Kyverno dans le RGD de Kro, on peut récupérer les variables teamName, et ainsi obtenir une validation des quotas utilisées par chaque équipe.
On passe alors d’un modèle où la définition du Quota pour chaque équipe se fait par namespace, à une configuration où la seul définition de la ressource ClusterResourceQuotas (définie dans le RGD), va permettre la création des ResourceQuotas dans chaque namespace appartenant à une équipe, et de centraliser leur gestion. Kyverno vient ensuite automatiquement valider ou refuser la modification des ResourceQuotas, garantissant un respect des règles de ressources définies pour chaque équipe.
Cluster In-Place update, et nouveautés associées
Kubernetes repose sur le principe de l'immuabilité : lorsqu'un Pod ou une Machine doit être modifié, le système ne le met pas à jour In-Place, mais supprime l'ancien pour en recréer un nouveau. Ce modèle est simple, robuste et prévisible, car il garantit que toutes les machines démarrent depuis une image de base de confiance, évitant ainsi les drifts de et facilitant le dépannage.
Cependant, bien que l'immuabilité soit puissante, elle crée des frictions matérielles et applicatives. Le redéploiement d'un cluster entier peut être problématique si la création de machines virtuelles est lente ou si les ressources (comme les GPU) viennent à manquer. De plus, certaines applications (comme les bases de données qui doivent synchroniser leurs données ou workload LLM) supportent mal les interruptions brusques et les redémarrages de nœuds.
Pour offrir une approche plus douce, le projet Cluster API a introduit la possibilité de faire des mises à jour “In-Place”. Le système fonctionne via un composant appelé : Update Extension. Le Cluster API évalue d'abord s'il dispose d'un "budget d'indisponibilité" (défini par le paramètre max unavailable). S’il peut satisfaire le maxUnavailable, il évalue si les modifications demandées peuvent être faîtes In-Place, sans redémarrage du nœud. Si les modifications nécessitent un redémarrage, comme par exemple un changement au niveau du kernel, elle est appliquée de façon traditionnelle.
Les paramètres maxUnavailable et maxSurge jouent un rôle central dans l’orchestration des mises à jour. Le premier définissant le nombre de machines pouvant être indisponibles, le second, le nombre maximum d’instances pouvant être ajoutées temporairement au pool.
Prenons le cas d’un groupe de noeuds constitué de trois noeuds : Dans le cas d’une mise à jour des noeuds du Control Plane :
- maxUnavailable = 0, maxSurge = 1 : Kubernetes va d’abord créé un 4e noeud, puis supprimer l’un des anciens noeuds, et répéter l’opération jusqu’à remplacer le nodepool
- maxUnavailable = 1, max Surge = 0 : Suppression d’un des trois nœuds, de sorte à pouvoir le recréer avec la mise à jour. Processus répéter jusqu’à la fin de l’opération
Pour la mise à jour des noeuds du Control Plane In-Place :
- maxUnavailable = 0, maxSurge = 1 : Kubernetes va d’abord créé un 4e noeud, mettre à jour les noeuds 2 et 3, puis supprimer le noeud 1
- maxUnavailable = 1, max Surge = 0 : Kubernetes met à jour les nœuds 1 à 3 sans redémarrage ni création de nouveau nœuds.
Une nouvelle fonctionnalité à également été ajoutée dans les versions récentes de Kubernetes, permettant de fluidifier la mise à jour des versions de Kubernetes déployées sur les nœuds. Il s’agit du Chain Upgrades, qui permet d’augmenter réduire le nombre de redémarrages nécessaires pour passer d’une version X à une version Y. Cela fonctionne en deux étapes : admettons que notre cluster soit en version 1.31, et que l’on souhaite faire la mise à jour vers la version 1.34.
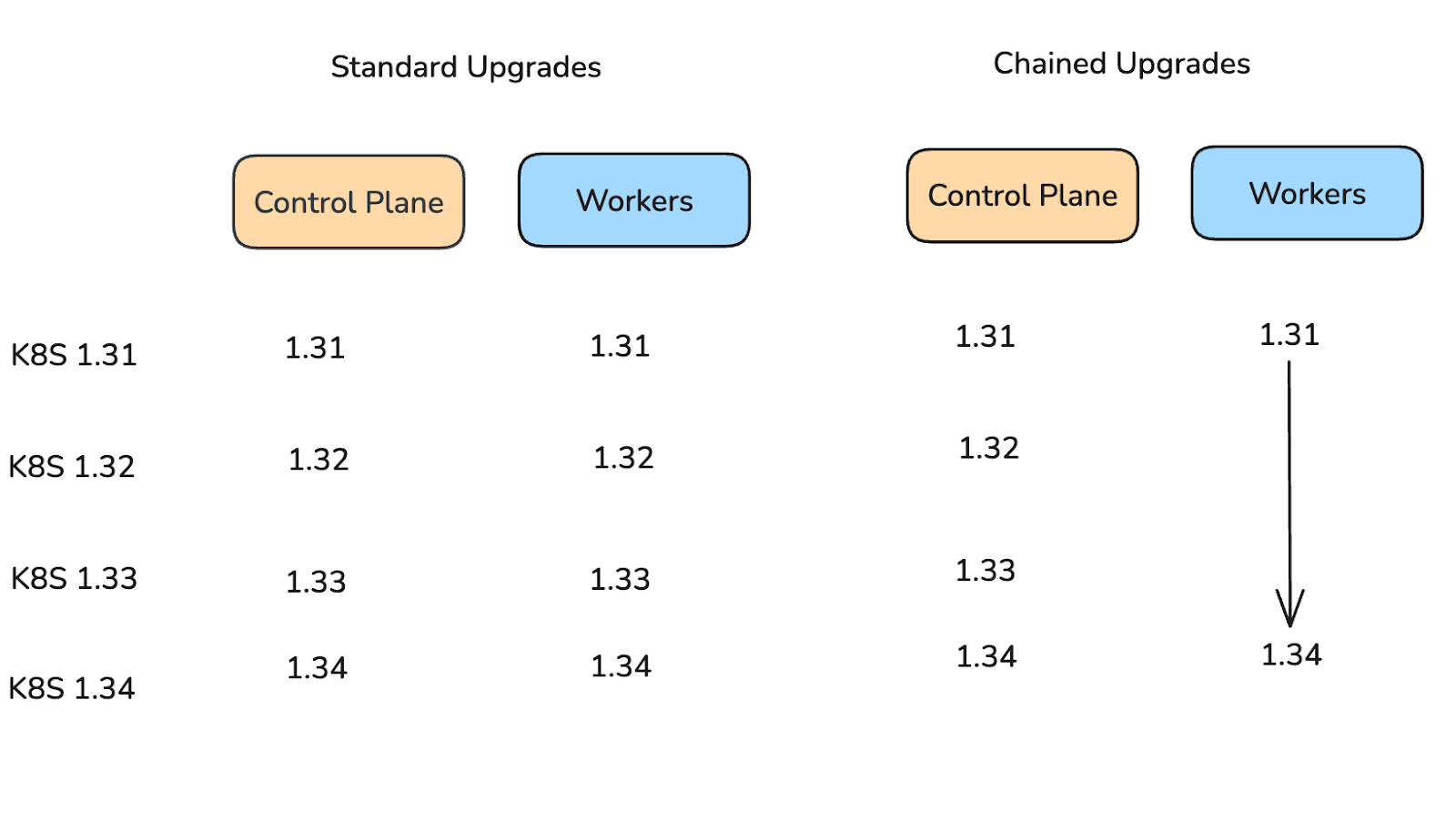
Les nodes du Control Plane sont les premiers à être mis à jour, un par un et version par version, afin d’assurer la stabilité du cluster. Une fois terminé, c’est au tour des Workers nodes de se mettre à jour. Au lieu de passer par chaque version entre la 1.31, et la 1.34, ils ne redémarrent qu’une seule fois en version 1.34.
Voir la documentation sur les Chained Upgrades
Ces nouveautés rendent la maintenance des nœuds dans Kubernetes beaucoup plus souple, et permettent à des workloads sensibles à la disruption d’être déployés dans un environnement plus stable. Cependant, ce ne sont pas des fonctionnalités qui by-pass le mécanisme de “drain” des nœuds, pour des changement nécessitant un redémarrage, mais elles évitent des perturbations qui peuvent être évitées lorsque le reboot des nœuds n’est pas requis pour appliquer une modification.
Optimisation du cycle de vie des noeuds, et fonctionnalités annoncées
Historiquement Kubernetes a été conçu pour orchestrer de simples microservices web stateless. Aujourd’hui, le contexte a changé : Kubernetes héberge massivement de workload dédié à l’IA, nécessitant des accélérateurs très coûteux (GPU, TPU), et gérant des Batch hautement sensibles. Dans ce contexte, la moindre minute d’indisponibilité des nœuds peut représenter une perte financière conséquente.
L’ancien modèle standard de Kubernetes ne semble alors ne plus être adapté, et des problématiques se révèlent :
- Une maintenance trop agressive : Aujourd'hui, mettre un nœud en maintenance déclenche une expulsion immédiate (drain) des applications, ce qui est très perturbant et gaspille des ressources avant même que la machine ne soit hors ligne.
- Une "préparation" binaire (Node Readiness) : Kubernetes considère un nœud comme prêt dès que le service de base (kubelet) démarre, ignorant si les pilotes matériels complexes (ex: drivers GPU) ou la configuration réseau sont réellement prêts à servir l'application.
- Une découverte matérielle chaotique : La gestion des étiquettes (labels) pour identifier le matériel est fragmentée, empêchant le planificateur (scheduler) de prendre les bonnes décisions de placement, ce qui peut anéantir les performances d'un entraînement d'IA.
- Le problème de la gravité des données : L'expulsion d'un pod applicatif lourd (modèles LLM de plusieurs téraoctets) entraîne de longs temps de redémarrage (téléchargement de modèle, chauffage du cache), détruisant la disponibilité de l'application.
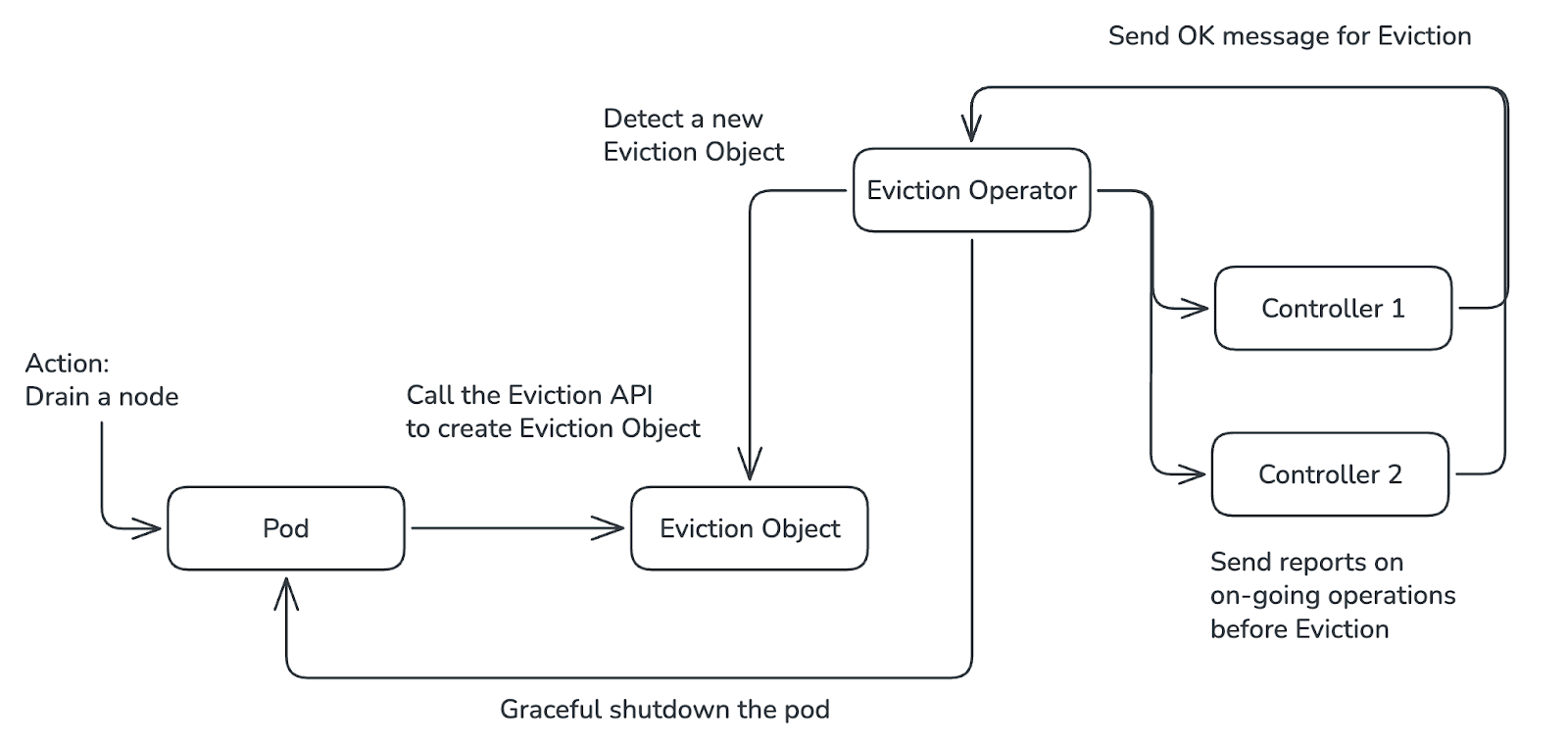
Pour rendre la maintenance des nœuds moins disruptive, une nouvelle API est en cours de développement : Eviction Request.Contrairement à l’ancienne méthode, qui supprimait le pod instantanément, cette API crée une “intention” observable. Ainsi, l’Eviction Request Operator peut détecter cette demande, et dispose d’un lapse de temps pour déplacer les données présent sur le node en toute sécurité. Il crée des Controllers qui lui font des rapports en temps réel sur le statut de ces opérations. Une fois terminé, les controllers envoient un signal à l’Eviction Request Operator qui requête l’API d'Éviction pour supprimer proprement le Pod.
Dans les environnements Kubernetes modernes, les nœuds ont des dépendances très fortes avec l’infrastructure, tel que le réseau, les drivers de stockages, les GPU … Pour s’assurer de la disponibilité d’un noeud, avant qui ne reçoive de la charge, et pour répondre à ces nouvelles contraintes, il est à présent possible de définir des Readiness Rules (voir la documentation) qui permettent, via des Custom Resource Definition (CRD), de mettre en place des critères définissant si un nœud est prêt pour recevoir des workload.

(exemple depuis la documentation)
Ce que montre principalement ce sujet, est que la place des nœuds, et donc leur orchestration, est en train d’évoluer au sein de Kubernetes, dans le but de devenir transparent pour les développeurs. Kubernetes évolue vers de nouvelles abstractions, on peut citer par exemple le Workload API, ou encore le Dynamic Resources Allocation, qui poussent à traîter les workloads comme un ensemble, au lieu de pods individuels, de sorte à ce que les utilisateurs n’aient plus à se préoccuper des limites physiques des noeuds.
Conclusion
A travers ces échanges, on constate une chose fondamentale : Kubernetes évolue. Il s’adapte à un monde qui change très vite, où l’IA est omniprésente, et où les contraintes de stabilité et de disponibilité liées au déploiement de ces LLM et autres agents poussent ce dernier à innover.
Faciliter les mises à jour des nœuds, optimiser leur cycle de vie, ou encore dépasser les limitations des ressources natives à Kubernetes. Ces projets et nouvelles fonctionnalités se positionnent comme de nouvelles solutions à des problématiques inhérentes au fonctionnement de Kubernetes, le transcendant et le préparant pour un monde où celui-ci semble avoir la première place pour héberger les plateformes que nous utiliserons demain.
