
Il y a un an, j’écrivais un livre blanc qui faisait l’état des lieux d’un paysage informatique en pleine mutation. Déjà à l’époque, le risque d’une perte de qualité dans notre code, ainsi que d’une perte de maintenabilité était non seulement déjà identifié, mais déjà mitigé avec un certain nombres de bonnes pratiques, auxquelles j’ai apposé le nom “Prompt Driven Développement” (PDD).
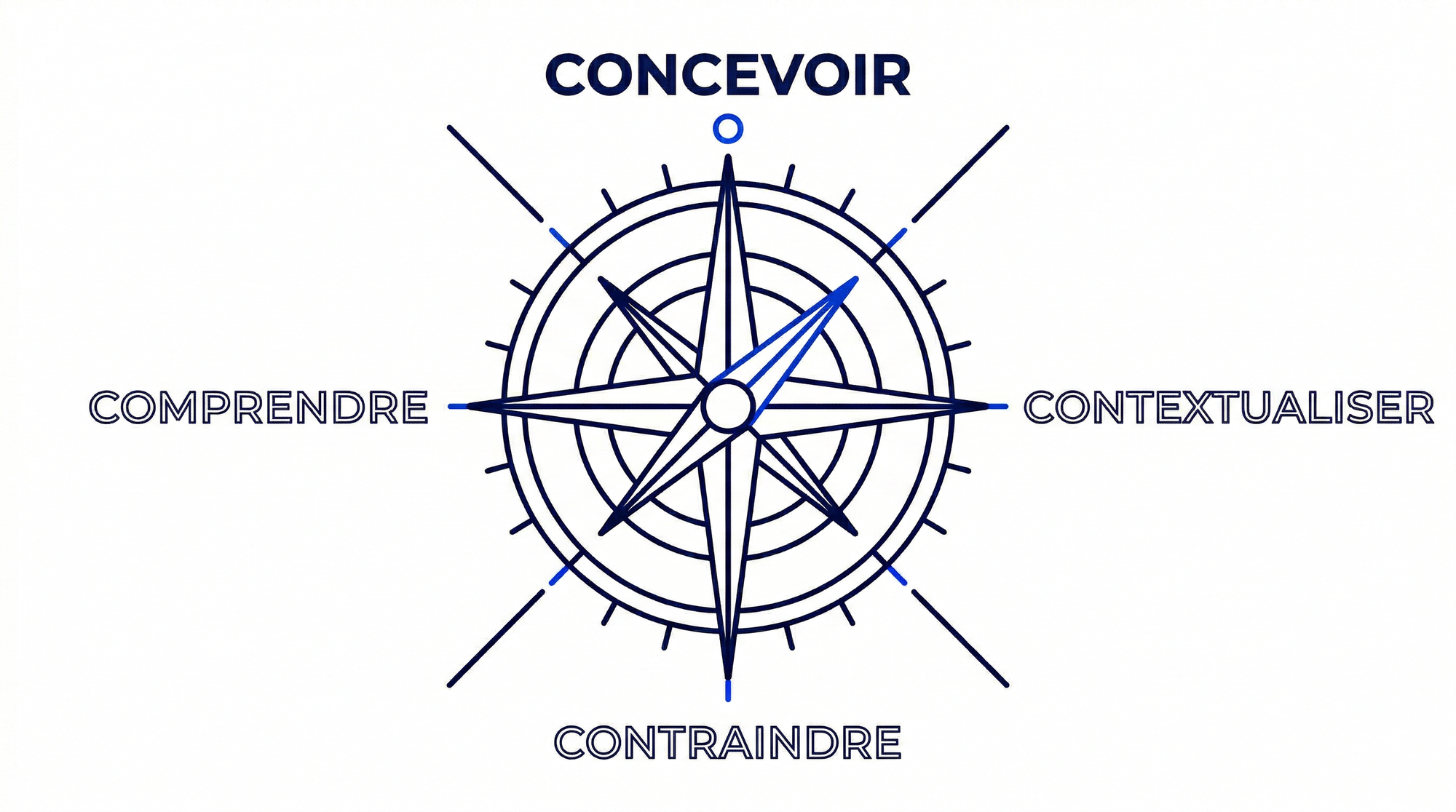
Le but de cet article est de prendre un peu de recul sur ces bonnes pratiques, comprendre quels sont les concepts qui se cachent derrière et pouvoir généraliser à toutes vos intéractions avec l’IA. Développement informatique ou non d’ailleurs. Ces concepts, vous l’aurez peut être deviné, mais ce sont les “4C”.
- Concevoir
- Contextualiser
- Contraindre
- Comprendre
Isoler les invariants
Reprenons un peu cette image du paysage informatique. Dire qu’il est en train de changer c’est minimiser l’ampleur de l’impact de l’IA sur notre métier.
Ma manière de coder d’il y a 3 mois n’a absolument rien à voir avec celle d’il y a 2 ans.
Ma manière de coder aujourd’hui, dans un monde post Claude Opus 4.5, n’a rien à voir avec celle d’il y a 3 mois.
Ma manière de coder demain n’aura absolument rien à voir avec celle d’aujourd’hui. Probablement.
Pour pouvoir tenir le rythme, il faut trouver des enseignements qui s’appliquent aujourd’hui et s’appliqueront demain. Dans un monde où d’apparence tout change, il faut trouver ce qui ne change pas.
Je vais partir du postulat que l’ingénierie informatique n’est pas en train de disparaître, que ce sont nos moyens d'interaction avec ces systèmes qui évoluent. Je pourrais faire plusieurs articles pour détailler ces deux phrases, mais ça n’est pas le sujet aujourd’hui. Une image vaut bien deux articles pour l'instant. Voilà mon postulat résumé :
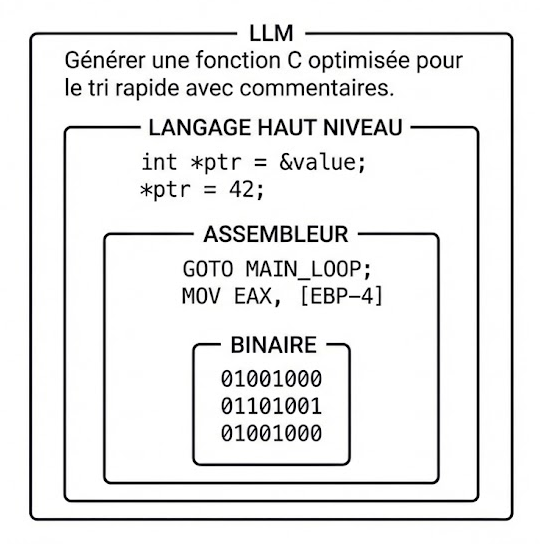
De plus, les LLMs sont bien partis pour être des constantes dans le monde du développement informatique, et être au cœur de ces nouveaux moyens d'interaction.
Les 4C
Les 4C sont une boussole pour vous guider dans vos intéractions avec l’IA. On pourrait parler de prompt engineering mais en réalité les 4C commencent avant votre premier prompt, et finissent après le dernier
Les 4C ne sont pas une obligation, ni une liste à cocher mais bien un prisme par lequel voir vos intéractions avec le LLM.
Concevoir
C’est l’étape la plus importante.
Concevoir c’est réfléchir en amont à la tâche à réaliser. Expliciter le scope, l’attendu. Faire des schémas, des spécifications détaillées… En gros c’est répondre à la question “Quel est le problème métier, et quelle solution technique peut le résoudre”.
En soi, ça n'a pas vraiment changé par rapport à la conception dans l’informatique “pré IA”, au détail près qu’il faut être encore plus rigoureux. L’IA ne pardonne pas, si il y a une ambiguïté dans votre conception ou un comportement qui n’a pas été explicité, vous pouvez être sûrs que ça posera problème plus tard. Plus tard ça peut être 5 minutes plus tard quand l’IA demandera des précisions, mais ça peut également être une semaine plus tard, quand vous vous rendrez compte que la fondation même de votre application n’est pas stable, et que tout est à refaire.
Pour ces raisons, c'est également l’étape qui prend le plus de temps. Comprendre ce qui est nécessaire et suffisant pour traduire un besoin métier en besoin technique n’a jamais été évident, que ça soit pour l’expliquer à des humains ou à une IA. Mais c'est aujourd'hui primordial. Et pour ça il convient également d'avoir une compréhension profonde du besoin métier.
Pour vous donner une idée de la place de la conception dans mon workflow avec des chiffres concrets :
Une session de développement de 6h en autonomie de la part de l'IA, c'est au moins 3h de conception en amont, probablement plus. Je suspecte qu’au fur et à mesure que les modèles et ma capacité à concevoir s’améliorent, ces deux chiffres grimperont en tandem.
Je base ces chiffres sur une session de dev avec Claude Code et Claude Opus 4.5 dont vous pouvez voir les détails ci-dessous. La conception m’a pris l'après midi, de 14h à 17h environ, puis Claude Opus 4.5 a généré 38.6K lignes de code entre 17h et 23h, en autonomie.
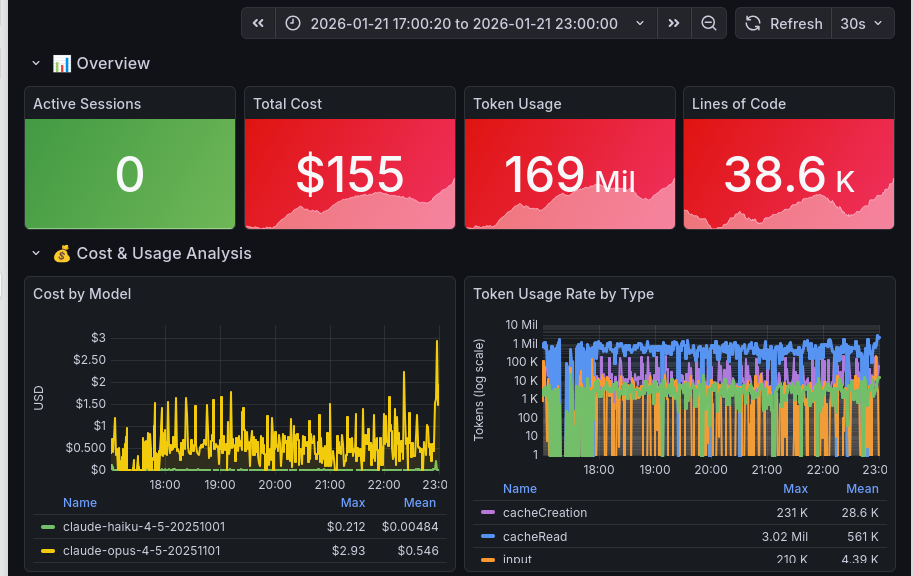
Ça représente 155$ d’équivalent en appels API, mais je suis passé par l’abonnement Claude Code MAX qui coûte la somme “dérisoire” de 216€/mois.
Je prépare un REX détaillé du projet concerné, avec le détail du workflow utilisé, stay tuned.
Contextualiser
Contextualiser c’est donner à l’IA le contexte nécessaire pour qu’elle puisse prendre des décisions pertinentes, si jamais elle en a besoin.
Il y a deux types de contextes :
Le contexte technique
C’est tout ce qui à trait à l’environnement technique de la solution à réaliser. Si vous êtes un grand fan de Svelte, si vous avez une version spécifique en tête d’un outil, si vous avez des bonnes pratiques de développement en place dans votre entreprise/projet… Tout ce que l’IA ne peut pas deviner juste en lisant votre code.
Mais attention à ne pas trop en faire, on y reviendra dans l’optimisation de votre workflow.
Le contexte métier
Un projet informatique c’est avant tout une solution technique à un problème métier.
Bien souvent votre solution technique a un petit goût de déjà vu pour l’IA. Je ne remets pas en cause l'originalité de votre réfléxion, mais le LLM a été entraîné sur des millions de bases de code.
Par contre, le problème métier auquel vous souhaitez répondre c’est une autre histoire. La notion même de ce qui constitue un problème est liée à notre condition d’humains. Il est assez irréaliste d’expliquer à une machine qu’on préfère telle couleur, que telle application existe parce qu’on a la flemme de faire telle action ou qu’il faut partir du principe que notre utilisateur fera des actions non optimales si on lui laisse cette opportunité (pour ne pas dire idiotes).
Mais on peut essayer de s’en rapprocher. C’était déjà pas évident à expliquer à une équipe de dev, c’est pour ça qu’on produit en amont des “contrats” sur ces aspects métier, comme des maquettes, des User Stories… L’idée derrière ces artéfacts, c’est d’éviter d’interpréter différemment le problème, et de s’aligner sur la solution.
Aujourd’hui les LLMs sont capables de consommer ces artéfacts pour avoir une idée de la direction générale à suivre.
Contraindre
Contraindre c’est donner des objectifs clairs et se battre contre le caractère probabiliste d’un LLM.
Cette notion de probabilité est centrale quand on travaille avec des LLMs. Centrale parce qu’on veut s’en débarrasser, et avoir en sortie une solution conforme à nos attentes.
Pour ça rien ne vaut des explications de ces attentes :
- Quels sont les critères qui nous permettent de dire qu’une solution est acceptable.
- Quels sont les comportements à éviter
Ce qui est bien en informatique c’est que bien souvent, on peut utiliser ces attentes pour en faire des contraintes déterministes, comme des tests.
D'ailleurs, Contraindre vaut pour la destination en elle-même, mais également le chemin pour y arriver. Si vous aimez que l’IA procède d’une manière ou d’une autre, il ne faut pas hésiter à lui forcer la main. Que ça soit en instaurant des tâches séparées à effectuer séquentiellement, ou en forçant l'exécution de scripts à certains moments clés (via des Hooks).
Comprendre
Comprendre, c’est rester maître de la solution produite.
Toute entorse à cette règle peut être considérée comme de la dette technique.
Après Concevoir, c’est la deuxième étape la plus importante. En tant que développeur, vous êtes responsable et garant de la qualité de vos livrables.
Si vous mettez en prod une application qui affiche des informations personnelles sur vos utilisateurs, ça n’est pas la faute du LLM. C’est la vôtre.
Évidemment avec la quantité de code qui peut être produite ça n’est pas toujours évident de suivre, c’est là que des concepts d’ingénierie logicielle bien connus comme “KISS” (Keep It Simple, Stupid) entrent en jeu. La tentation d'over-engineer peut être très forte quand on n’écrit pas le code. Il faut résister au nom de la maintenabilité.
Tant que vous n’êtes pas à l’aise avec l’utilisation de LLM, d’un workflow ou même simplement d’un nouveau modèle, je recommanderai de lire consciencieusement le code généré, de la même manière que vous le feriez avec une PR.
C’est un gros travail, et à terme, certaines optimisations peuvent permettre de prendre un peu de hauteur. Mais comme pour la conception, le maître mot est “rigueur”.
C’est bien simple, tant que vous ne pouvez pas dire avec certitude “ça me convient”, alors il faut passer plus de temps à Comprendre.
Les 4C et les outils du dev augmenté
On peut diviser les 4C en 2 catégories :
L’une que je qualifierai d’“incompressible”: c’est le travail qui incombe à l’humain peu importe la complexité et la maturité de son workflow. Ce sont les étapes de “hands-off”, de transmission de l’information. De l’humain à la machine et vice versa.
L’autre, vous l’aurez deviné, que je considère “compressible” : c’est là où on a de la marge d’optimisation, par l’intermédiaire d’outils ou à une granularité plus fine via des artéfacts de dev comme des skills et autres.
Je ne répéterai jamais assez que Concevoir et Comprendre sont les deux aspects les plus importants du travail du développeur. La capacité à traduire un besoin métier et à assurer la qualité de la solution produite est ce qui fait votre valeur en tant que développeur.
Par contre, travailler sur votre workflow pour optimiser votre utilisation des multiples outils, orchestrer vos agents et automatiser le plus de tâches ingrates possible est ce qui vous fera transcender votre condition de développeur pour atteindre le mythique statut de “développeur 10x”.
Il existe de nombreux skills et autres “harnais” (harness) agentiques mis à votre disposition par la communauté, même si les adopter “bêtement” rentre en conflit avec Comprendre. Celà reste néanmoins une option et n’hésitez pas à jeter un coup d'œil du côté de “superpowers” qui est cli-agnostique et force by design une attention toute particulière à Concevoir.
Optimiser son workflow
Je ne vous donnerai pas plus de skills tous faits, de prompt en tout genre. Je souhaite éviter l’obsolescence de cet article. Par contre laissez moi vous parler de quelques concepts que je considère centraux pour optimiser la partie Compressible de votre workflow. Vous verrez d’ailleurs que bien souvent ces concepts ne sont ni plus ni moins que de l’ingénierie logicielle. Il y a vraiment des choses qui ne changent pas.
L’idée est de faire changer la responsabilité de camp, que ça soit le LLM qui s’occupe d’une partie de votre workflow.
Contextualiser
L’enjeu est double : permettre au LLM de trouver lui-même ce dont il a besoin, tout en évitant de surcharger sa fenêtre de contexte.
Pour ça on ne peut pas ne pas parler de la “Separation Of Concerns”. Chez Ippon on en parle conjointement avec le PDD depuis les tous débuts, car c’est au cœur de ce qui nous a permis de produire du code de qualité avec de l’IA à l’époque. Dans un contexte de Software Craftsmanship ça prenait la forme d’architecture hexagonale, mais c’est évidemment généralisable.
Il est également possible de connecter vos agents à des sources externes (MCPs, Tools, plugins…), comme par exemple vos outils de documentation ou de gestion de projet (Confluence et Jira par exemple). Attention tout de même à la pollution du contexte. De la même manière qu’un AGENTS.md n’est pas toujours bénéfique, trop d’information peut diminuer la performance du modèle. D’autant plus que les derniers modèles sont construits pour explorer efficacement des bases de code. Rien de pire que des informations non pertinentes ou désuètes pour rendre l’IA confuse.
Contraindre
A l’heure ou j’écris ces lignes, Claude Opus 4.6 peut travailler sur des tâches qui prendraient 16h à un développeur moyen selon METR, et les réussir 50% du temps. Il y a un an, c’était moins d’une heure. Et la tendance est à l’accélération.
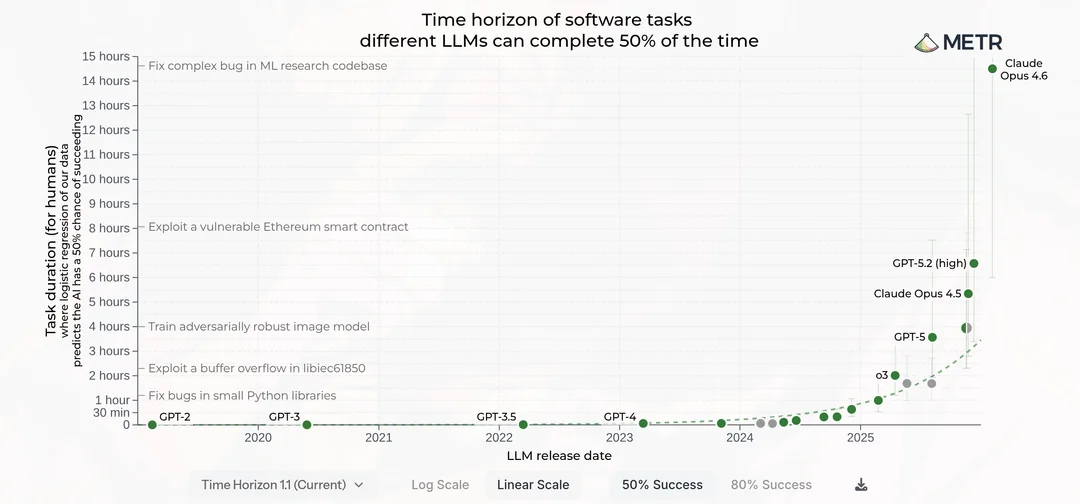
Aucun développeur ne code pendant 16h d’affilée sans aucun feedback. Je suis déjà fier quand je réussis à compiler du premier coup après 2h de dev (ou plutôt j’étais…), mais la compilation réussie est déjà un feedback.
Évidemment, il en va de même pour l’IA. Il faut qu’elle puisse valider son travail, avec le moins d'ambiguïté possible.
Pour ça je recommande chaudement la mise en place d’une stack d’observabilité qui soit facilement utilisable par l’IA. Que ça soit l’utilisation de votre navigateur (à vos risques et périls), la création de scripts pour interroger vos données, des outils de logging…
Écrire du code est une formalité, surtout sur des “petits projets” aussi il ne faut pas hésiter à créer une stack d’observabilité from scratch spécifique à votre cas d’usage pour s’assurer que notre IA ne s’éloigne pas trop des sentiers battus.
De la même manière, grâce à l’IA il n’y a plus d’excuses : testez tout. Et laissez l’IA exécuter vos tests. Personnellement, je livre uniquement si j'atteins 100% de coverage.
Comprendre
Vous ne vous attendiez peut-être pas à voir Comprendre ici puisque je l’ai qualifié d’incompressible, mais j’ai menti. En réalité, le LLM peut jouer un rôle dans la compréhension de ce qu’il a produit. Et ce de deux manières :
Le “LLM as a Judge”. L’idée est simple : faire valider son code par le LLM. Un bon exemple qui semble devenir une bonne pratique est d'avoir une boucle de validation, avec un subagent qui valide le code produit selon un certain nombre de critères.
La remontée d’information optimisée. L’idée est un peu plus complexe :
Avec la rapidité de la génération du code, le goulot d’étranglement est la validation des comportements de ce code. Être garant de la qualité c’est comprendre ce que fait le code, et on pourrait penser que c’est “relire le code”. Sauf que je ne pense pas que ça soit vrai.
Chaque développeur a des attentes différentes pour le code qu’il écrit, et chaque développeur a une manière de comprendre le code et une manière de réfléchir différente.
Personnellement je fais systématiquement des diagrammes, et je suis particulièrement fan des diagrammes de séquence. Donc je demande au LLM de générer des diagrammes sur les fonctionnalités qui viennent d’être implémentées.
Est-ce que ça suffit ? Non. Est-ce que ça aide à creuser ce qui est potentiellement flou ? Complètement.
Pour la petite histoire, j’utilise Vibe-Kanban comme interface principale pour naviguer entre mes différents projets et mes sessions de développement. J’en ai créé un fork, qui interprète les diagrammes mermaid à la volée. Cette feature de Cline et RooCode manquait trop dans mon développement.
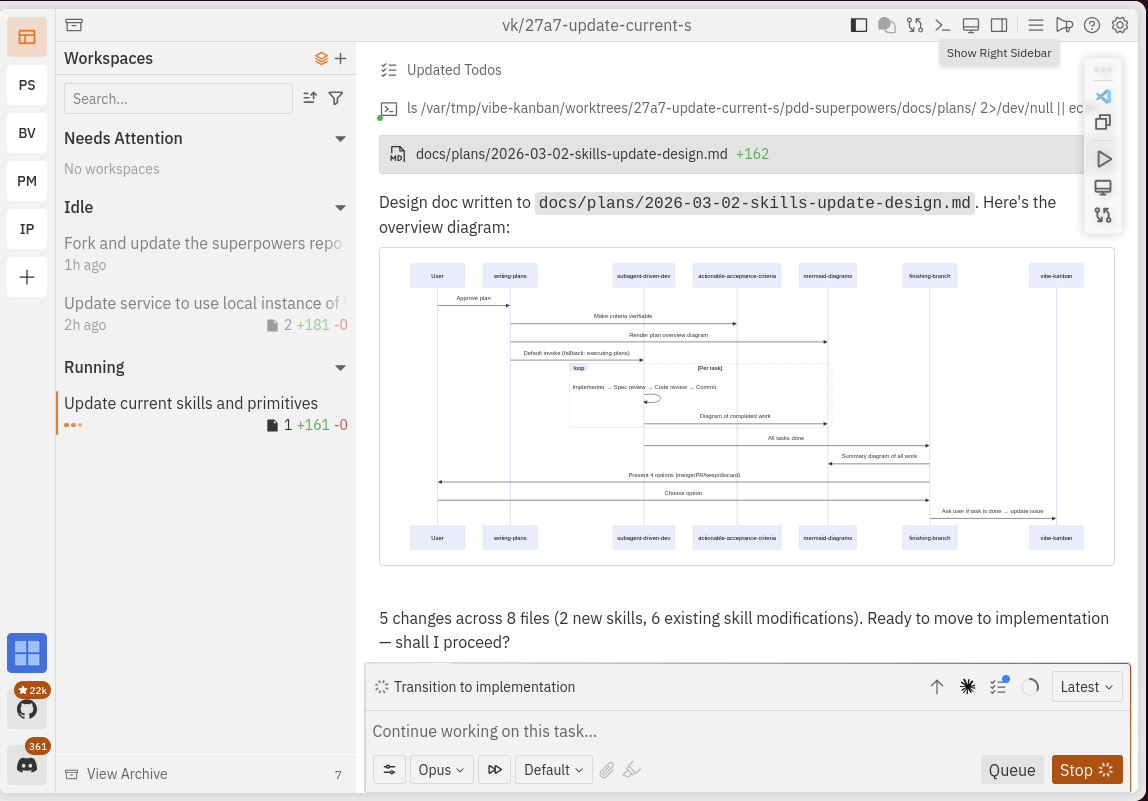
Conclusion
La forme que prend le métier de Software Engineer évolue, mais le fond ne bouge que très peu. Et contre toutes attentes, le fond c’est l’ingénierie informatique. Ces concepts, qu’ils soient appris pendant nos formations ou acquis au fur et à mesure de nos expériences, restent le cœur de nos interactions avec la machine.
Mais avec le niveau d’abstraction supplémentaire que représente le passage du code au LLM, il n’est pas évident de déceler comment les appliquer. C’est le but des 4C, qui vous permettent de faire le lien entre ce que vous savez déjà et leur nouvelle forme.
