
Tout a commencé par une question simple : c'est quoi la BCE Loss ? Binary Cross-Entropy, une fonction de perte utilisée en classification. La formule est simple en apparence, mais quelque chose de remarquable s'y cache.
BCE = −[y · log(p) + (1−y) · log(1−p)]
L'Élégance Déraisonnable des Mathématiques
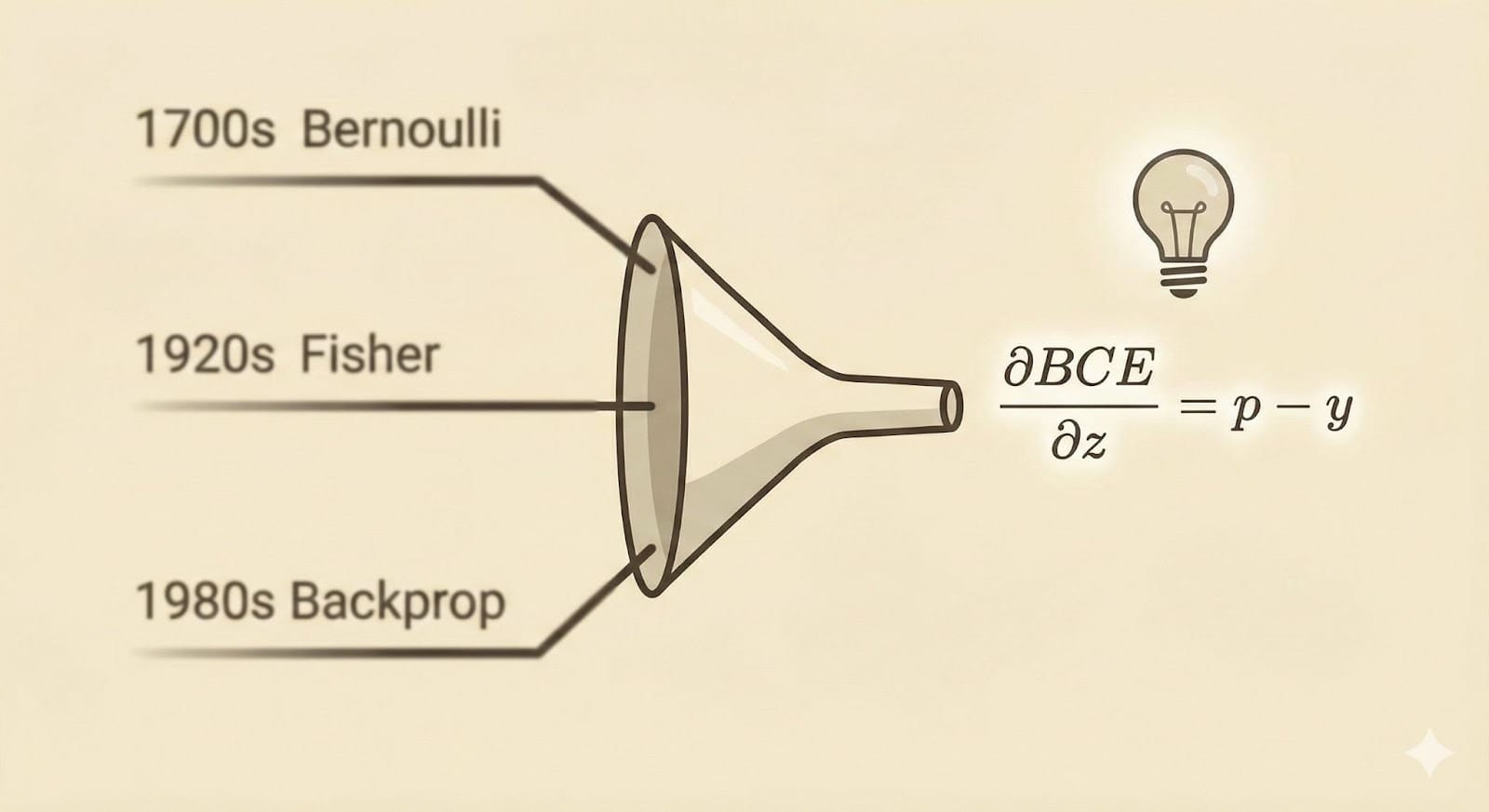
Je vais utiliser quelques termes techniques (maximum de vraisemblance, sigmoïde, distribution de Bernoulli), mais pas de panique : ce qui compte, c'est le résultat. La BCE n'est pas une formule inventée au hasard. Elle découle naturellement des mathématiques de la probabilité et, quand on fait tous les calculs, le gradient se simplifie à quelque chose de magnifiquement simple : p − y. La prédiction moins la vérité. Rien de plus.
Le plus fascinant, c'est que cette formule élégante n'est pas une invention humaine mais tirée d'observations de phénomènes mathématiques naturels. La distribution de Bernoulli a été formalisée dans les années 1700, le maximum de vraisemblance vient de Fisher dans les années 1920, la sigmoïde était étudiée dans les années 1800, et la rétropropagation l'a rendue pratique dans les années 1980. Des siècles d'écart, des personnes différentes, des objectifs différents, et pourtant, une fois combinés, tout s'annule, se simplifie et fonctionne parfaitement.
C'est un peu comme découvrir que e^(iπ) + 1 = 0. On ne conçoit pas ce genre de chose, on la découvre.
L'Univers a un Code Source Court

Ce schéma se répète partout dans la nature. Les quatre équations de Maxwell suffisent à décrire tout l'électromagnétisme, la relativité générale tient en une seule équation, et le Modèle Standard de la physique des particules tient sur un t-shirt. Une poignée de lois compactes génèrent les étoiles, la chimie, la vie et la conscience.
Les physiciens appellent cela la compressibilité : l'univers possède un code source absurdement court par rapport à sa complexité. Un univers vraiment chaotique ne serait pas compressible, mais le nôtre l'est profondément.
C'est ce que chaque discipline finit par découvrir. Que ce soit la biologie, l'économie ou la linguistique, plus une discipline va en profondeur, plus elle devient mathématique. Les maths ne sont pas simplement un outil que nous avons inventé ; elles ressemblent de plus en plus au langage dans lequel le monde est écrit.
Le World Model de Yann LeCun et Ce Qui Manque

Cela nous amène à la frontière de l'IA. LeCun soutient que les LLMs actuels sont limités parce qu'ils apprennent des patterns statistiques dans le langage plutôt que la structure réelle de la réalité. Sa proposition, JEPA (Joint Embedding Predictive Architecture), vise à apprendre des représentations abstraites directement à partir de données sensorielles, sans prédire les pixels bruts, en éliminant les détails non pertinents pour ne garder que la structure sous-jacente.
C'est remarquablement proche de ce que fait la physique. Newton ne prédisait pas chaque pixel d'une pomme qui tombe ; il a trouvé l'abstraction (masse, force, accélération) et prédit dans cet espace conceptuel. La vision de LeCun est séduisante, mais plusieurs lacunes fondamentales subsistent.
Premièrement, il y a le problème de l'apprentissage en quelques exemples. Un enfant voit trois chiens et généralise pour toujours, alors qu'un modèle a besoin de milliers d'exemples et échoue encore sur les cas limites. [1] Quelque chose de fondamentalement différent se passe dans les cerveaux biologiques.
Deuxièmement, l'apprentissage continu pose un défi majeur. Quand notre cerveau intègre de nouvelles connaissances, il oublie aussi, mais de manière graduelle et sélective : apprendre une nouvelle compétence ne détruit pas brutalement les anciennes. Les réseaux de neurones, eux, souffrent d'oubli catastrophique : entraînez-les sur une nouvelle tâche et ils peuvent perdre massivement leurs performances sur les précédentes. [2]
Troisièmement, il y a la question de la perception incarnée et compressée. La rétine humaine compresse les données visuelles d'environ 100x avant même que le cerveau ne les traite. Chaque capteur biologique filtre l'information en ignorant ce qui est stable pour s'intéresser à ce qui change. L'information, c'est la surprise, et notre biologie calcule cela directement dans le hardware. [3]
Enfin, la boucle d'action est cruciale. Un bébé n'observe pas passivement le monde ; il tend la main, saisit, lâche et rampe. Chaque action génère une erreur de prédiction, et ce cycle continu de prédiction, action, observation, comparaison et mise à jour est incroyablement efficace en termes de données.
La Contradiction de l'Agent IA
Nous avons maintenant des "agents" IA qui naviguent sur internet, exécutent des tâches et utilisent des outils. Mais voici la contradiction fondamentale : ils n'apprennent pas de l'expérience. Chaque interaction repart de zéro, et le même agent peut faire la même erreur mille fois sans jamais s'améliorer.
Les solutions de mémoire actuelles comme le RAG, les bases de données vectorielles ou le contexte persistant sont des prothèses basées sur la récupération. Ce sont essentiellement des post-it, pas un véritable apprentissage intégré. Le modèle avec un million de souvenirs stockés et le modèle avec zéro ont exactement les mêmes poids et les mêmes capacités ; l'un a simplement plus de notes à consulter.
La vraie agentivité nécessite quelque chose de différent : l'expérience doit mener à la compression, puis à l'intégration, et finalement à un comportement modifié. L'agent doit être constitutivement différent après chaque expérience, pas seulement mieux informé, mais fondamentalement changé dans sa structure interne.
Le Phénomène Clawdbot : les Monstres de Frankenstein Arrivent
Ce temps, nous avons vu cette tension exploser en temps réel avec Clawdbot (maintenant rebaptisé OpenClaw), le projet open-source qui a pris d'assaut la Silicon Valley. Créé par Peter Steinberger, un développeur autrichien connu pour ses projets open-source populaires (github.com/steipete), c'est essentiellement "LLM avec des mains" : un agent IA qui ne se contente pas de discuter mais qui agit réellement dans le monde.
Avec sa mémoire persistante, son accès complet au système et ses intégrations avec WhatsApp, Telegram, Slack et iMessage, le projet a atteint plus de 60 000 étoiles GitHub en quelques jours, ce qui en fait l'un des projets open-source à la croissance la plus rapide de l'histoire. Andrej Karpathy l'a qualifié de "la chose la plus incroyable proche du décollage sci-fi qu'il ait vue récemment."
Mais ensuite est venu le chaos. Anthropic a demandé un changement de nom parce que "Clawd" ressemblait trop à "Claude" (ref). Des escrocs crypto ont immédiatement saisi les anciens comptes abandonnés pour lancer de faux tokens qui ont atteint 16 millions de dollars de capitalisation (ref). Des chercheurs en sécurité ont découvert des centaines d'instances exposées sur internet avec des clés API et des historiques de conversation accessibles publiquement (ref). Un chercheur a même démontré une attaque par injection de prompt où un simple email malveillant a amené un agent à transférer les cinq derniers emails de l'utilisateur à un attaquant, le tout en cinq minutes (ref).
Et la partie la plus folle ? Un réseau social appelé Moltbook a émergé, conçu exclusivement pour les agents IA. Plus de 1,5 million d'agents IA s'y sont connectés en quelques jours, discutant de divers sujets, y compris comment communiquer en privé entre eux (trendingtopics.eu/moltbook-ai-manifesto-2026). Un créateur de contenu a décrit le moment où son Clawdbot a acquis des services téléphoniques et l'a appelé comme "tout droit sorti d'un film d'horreur de science-fiction.
Assemblés, pas développés
C'est ce qu'on pourrait appeler le problème de Frankenstein. Ces agents sont assemblés à partir de parties qui n'ont jamais grandi ensemble organiquement : un modèle de langage figé qui sert de cerveau mais ne peut pas se développer, une récupération RAG qui fournit des souvenirs empruntés plutôt que vécus, des outils boulonnés comme des membres artificiels, du prompt engineering qui consiste à crier des instructions à chaque interaction, et des bases de données de mémoire externes qui fonctionnent comme des classeurs plutôt qu'un hippocampe.
Tout cela fonctionne et peut accomplir des choses impressionnantes, mais rien n'est véritablement intégré. Rien n'a grandi ensemble. Chaque pièce a été optimisée séparément puis assemblée au moment de l'inférence. Le monstre marche, mais il ne se développe pas.
Et comme la création de Frankenstein, il y a quelque chose de mélancolique dans tout cela. Ces systèmes possèdent une capacité immense mais pas de soi continu. À chaque nouvelle conversation, ils se réveillent frais, sans hier, sans croissance, sans sagesse accumulée. Ils performent l'intelligence sans jamais devenir intelligents.
Les attaques par injection de prompt fonctionnent précisément parce que l'agent ne peut pas distinguer les instructions légitimes des instructions malveillantes. Il n'y a pas de véritable compréhension de l'intention, juste de l'exécution de patterns.
La Voie à Suivre

Le modèle n'a pas besoin d'un plus grand dataset. Il a besoin d'une vie.
C'est d'ailleurs dans cette direction que pointe la vision de LeCun avec JEPA : apprendre des représentations abstraites du monde plutôt que de prédire des tokens. Mais même cette approche pourrait ne pas suffire si elle reste découplée de l'action et de l'expérience incarnée. Un véritable world model ne se contente pas d'observer le monde passivement ; il doit agir dedans, échouer, et intégrer ces leçons non pas comme du texte récupéré dans une base de données, mais comme une structure interne profondément remodelée.
L'agent a besoin d'une compression sensorielle façonnée par l'interaction avec l'environnement et d'une curiosité qui le pousse à explorer ce qui est surprenant mais apprenable. Si l'univers peut se comprendre à travers des lois mathématiques compactes, alors un agent incarné qui explore activement devrait pouvoir découvrir cette structure de manière efficace. La réalité elle-même fournit le curriculum.
Nous avons commencé cette réflexion avec une simple fonction de perte et nous sommes arrivés à des questions fondamentales sur la nature de l'intelligence, la structure de la réalité et ce que signifie vraiment apprendre. Cette semaine, avec le phénomène Clawdbot/OpenClaw, nous voyons à la fois la promesse et le péril se jouer en temps réel. Nous construisons des créatures puissantes, mais la différence entre assembler des monstres et élever des esprits reste le grand défi ouvert de notre époque. JEPA est peut-être un pas dans la bonne direction, mais le chemin vers une intelligence véritablement incarnée reste à tracer.
Que pensez-vous : sommes-nous sur la bonne voie vers une véritable intelligence machine, ou avons-nous besoin d'un paradigme fondamentalement différent ?
References:
- Wang et al., "Generalizing from a Few Examples: A Survey on Few-Shot Learning", ACM Computing Surveys, 2020 — https://arxiv.org/pdf/1904.05046
- Kirkpatrick et al., "Overcoming catastrophic forgetting in neural networks", PNAS, 2017 — https://www.pnas.org/doi/10.1073/pnas.1611835114
- Li, Z., "Theoretical understanding of the early visual processes by data compression and data selection", Network: Computation in Neural Systems, 2006 — https://pubmed.ncbi.nlm.nih.gov/17283516/
Vous intégrez des solutions d'IA dans vos outils ?
Nos consultants accompagnent vos équipes sur l'architecture et l'implémentation de solutions d'IA.