
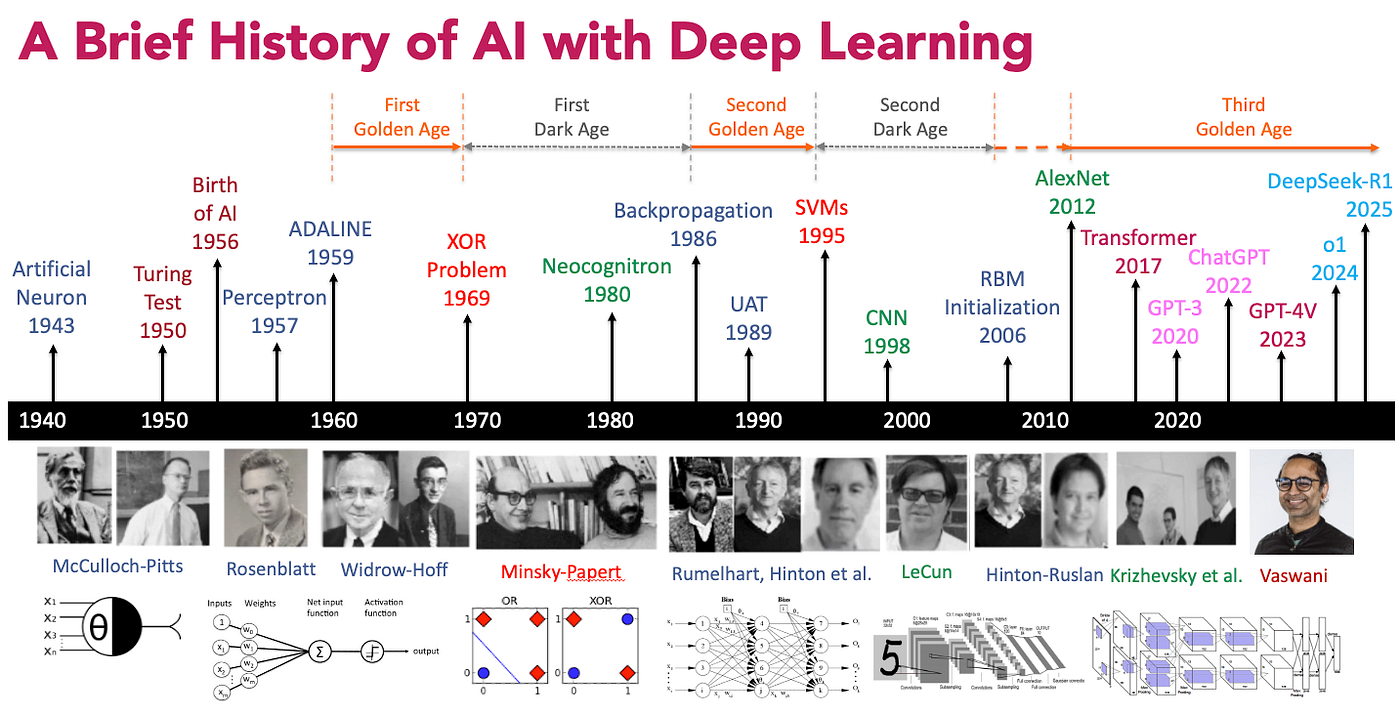
Le deep learning est aujourd’hui omniprésent dans les systèmes de vision, de langage et de recommandation. Pourtant, son succès est relativement récent à l’échelle de l’informatique. Pendant plusieurs décennies, les réseaux de neurones ont alterné entre promesses théoriques et limitations pratiques. Cette histoire est marquée par des ruptures précises : des verrous mathématiques, des limites algorithmiques et des contraintes matérielles qui ont conditionné l’émergence successive des architectures modernes. Comprendre cette trajectoire permet d’expliquer pourquoi certaines approches ont dominé à un instant donné, et pourquoi elles ont ensuite été remplacées.
1. Les débuts : le Perceptron et les premières étincelles (années 1950–1970)

En 1957, Frank Rosenblatt dévoile le Perceptron, une machine inspirée du fonctionnement du neurone humain, capable d’apprendre à reconnaître des formes simples. Le perceptron est l’un des premiers modèles formels d’apprentissage supervisé. Il repose sur une idée simple : une sortie est calculée comme une combinaison linéaire des entrées, suivie d’une fonction d’activation seuil. D’un point de vue mathématique, ce modèle apprend une frontière de décision linéaire dans l’espace des données. Tant que les classes peuvent être séparées par un hyperplan, le perceptron converge vers une solution correcte.
Ce cadre fonctionne pour des problèmes simples, mais révèle rapidement ses limites lorsqu’on s’attaque à des relations plus complexes. Le cas du XOR est devenu emblématique : deux variables binaires dont la sortie est vraie uniquement lorsqu’elles sont différentes. Dans l’espace bidimensionnel, les points positifs et négatifs sont disposés de manière croisée, ce qui rend impossible toute séparation linéaire. Le perceptron échoue non pas par manque d’entraînement, mais parce que son espace de représentation est insuffisant.
Cette observation est fondamentale : le problème n’est pas algorithmique mais structurel. Tant que le modèle reste limité à une seule couche, il ne peut pas représenter certaines fonctions pourtant triviales pour un humain. Ce constat freine durablement la recherche sur les réseaux de neurones et conduit à un recentrage vers des approches symboliques ou statistiques plus maîtrisables à l’époque.
2. Le retour : l’apprentissage par rétropropagation (années 1980)
Dans les années 1980, un petit groupe de chercheurs passionnés refuse de laisser mourir l’idée que des réseaux de neurones puissent apprendre. Parmi eux se distingue Geoffrey Hinton, futur “parrain du deep learning”, convaincu que les modèles à couches multiples pourraient accomplir ce que le perceptron avait échoué à faire.
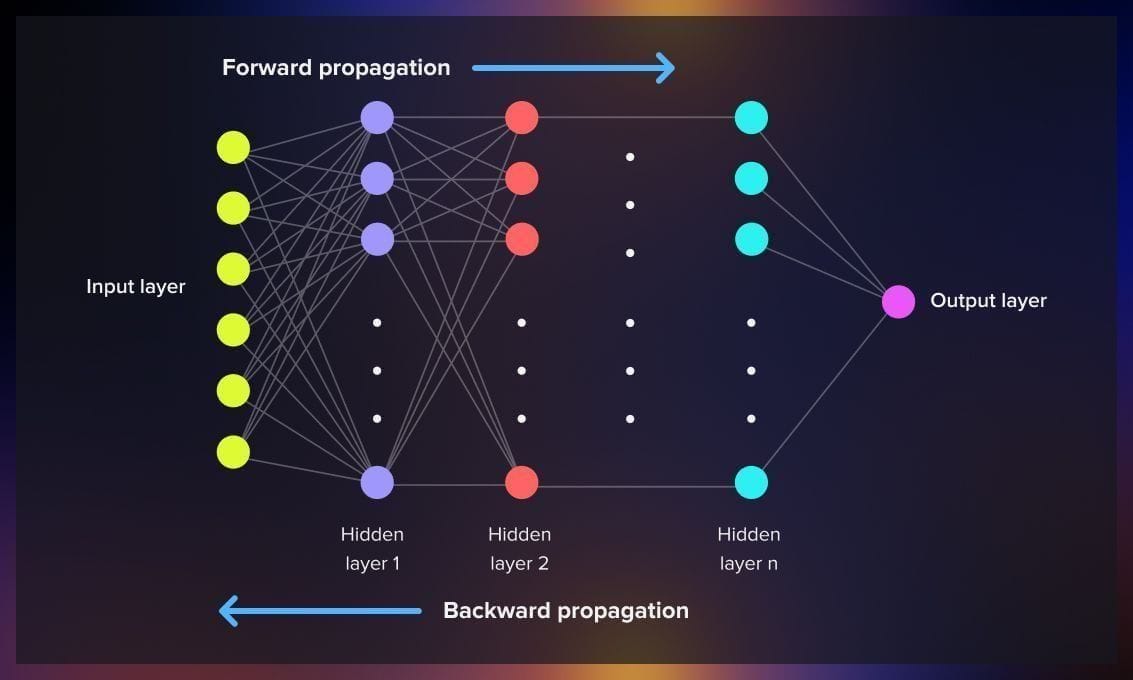
La sortie de cette impasse passe par deux idées complémentaires : l’introduction de couches cachées et un mécanisme permettant de les entraîner efficacement. Les réseaux multi-couches permettent d’empiler des transformations non linéaires successives, augmentant considérablement la capacité de représentation du modèle. Cependant, sans méthode d’optimisation adaptée, ces réseaux restent inutilisables en pratique.
La rétropropagation du gradient apporte cette solution. Le principe est de définir une fonction de perte mesurant l’erreur globale du réseau, puis de calculer son gradient par rapport à chaque paramètre à l’aide de la règle de la chaîne. L’erreur est propagée de la sortie vers l’entrée, permettant de mettre à jour chaque poids proportionnellement à sa contribution à l’erreur finale.
Ce mécanisme rend possible l’apprentissage de fonctions complexes et non linéaires, y compris celles inaccessibles au perceptron simple. Toutefois, cette avancée s’accompagne de nouvelles difficultés. Dans les réseaux profonds, les gradients peuvent devenir extrêmement faibles au fur et à mesure qu’ils traversent les couches, ralentissant voire bloquant l’apprentissage. Ce phénomène, connu sous le nom de vanishing gradient, limite la profondeur effective des réseaux entraînables à cette époque
3. L’explosion du Machine Learning (années 2000) : plus de données, plus de puissance

Au début des années 2000, les réseaux de neurones multi-couches existent déjà, et la rétropropagation est maîtrisée depuis plusieurs années. Pourtant, le deep learning ne domine pas le paysage du machine learning. Dans la pratique industrielle et académique, ce sont principalement les méthodes dites “ML classiques” ,en particulier les SVM et les modèles ensemblistes ,qui obtiennent les meilleures performances sur de nombreux problèmes. L’entraînement d’un réseau de neurones repose presque exclusivement sur des opérations algébriques : multiplications de matrices, convolutions, additions vectorielles. Ces opérations sont hautement parallélisables. Pourtant, les architectures CPU traditionnelles ne sont pas conçues pour ce type de charge. Un CPU dispose de peu de cœurs, mais très puissants, optimisés pour exécuter des tâches séquentielles complexes avec de nombreuses branches conditionnelles.
Les GPU adoptent une philosophie radicalement différente. Ils disposent de milliers de cœurs simples, capables d’exécuter la même instruction sur de grandes quantités de données en parallèle. Cette approche SIMD (Single Instruction, Multiple Data) est parfaitement adaptée aux calculs matriciels du deep learning. Une multiplication de matrices peut être découpée en milliers d’opérations indépendantes exécutées simultanément.
Il est intéressant de rappeler que les GPU n’ont pas été conçus à l’origine pour l’intelligence artificielle. Leur développement est principalement porté par l’industrie du jeu vidéo,qui avait besoin de traiter massivement des opérations graphiques sur des millions de pixels en temps réel,une contribution indirecte mais décisive à l’essor du deep learning moderne.
Cette adéquation transforme radicalement les possibilités pratiques. Des réseaux auparavant trop lents à entraîner deviennent exploitables. La profondeur des modèles augmente, les jeux de données s’agrandissent, et l’entraînement distribué devient envisageable. La montée en puissance du deep learning n’est donc pas uniquement une avancée algorithmique : elle repose sur un alignement décisif entre modèles mathématiques et architectures matérielles.
4. L’ère des architectures modernes : CNN, RNN, LSTM (années 2010)
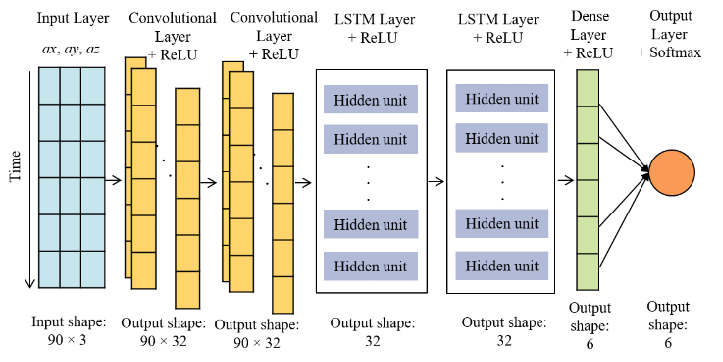
CNN : des bases théoriques à la rupture industrielle (années 1980 → 2012)
Les Convolutional Neural Networks (CNN) trouvent leurs racines bien avant leur succès industriel. Dès les années 1980, avec des travaux inspirés du cortex visuel (notamment ceux de Hubel et Wiesel, puis les modèles de Fukushima avec le Neocognitron), l’idée centrale est posée : dans une image, les motifs locaux (bords, textures, formes simples) sont plus informatifs que les relations globales pixel par pixel.
Les convolutions permettent d’appliquer les mêmes filtres sur l’ensemble de l’image, ce qui réduit drastiquement le nombre de paramètres tout en introduisant une invariance par translation : un motif appris peut être reconnu indépendamment de sa position. Cette approche rend les CNN particulièrement adaptés à la vision par ordinateur, tant du point de vue statistique que computationnel.
Pendant longtemps, ces modèles restent toutefois limités à des problèmes de petite taille, principalement en raison du manque de données annotées et de puissance de calcul. La rupture majeure intervient en 2012 avec AlexNet, qui démontre qu’un CNN profond, entraîné sur GPU et sur de grands volumes de données, peut surpasser très largement les méthodes traditionnelles en reconnaissance d’images. Cette victoire marque le début d’une évolution rapide des architectures CNN : VGG (2014), ResNet (2015), EfficientNet (2019), chacune cherchant à améliorer la profondeur, la stabilité de l’entraînement et l’efficacité computationnelle.
RNN et LSTM : modéliser la dépendance temporelle (années 1990 → 1997)
Les Recurrent Neural Networks (RNN) apparaissent dès la fin des années 1980 et au début des années 1990, avec l’objectif de traiter des données séquentielles en maintenant un état interne évoluant au fil du temps. Contrairement aux réseaux feed-forward, cette structure permet de prendre en compte l’ordre des données, ce qui est indispensable pour des tâches comme le traitement du langage naturel ou de la parole.
Cependant, l’apprentissage des RNN se heurte rapidement à des problèmes numériques majeurs, en particulier la disparition ou l’explosion du gradient lors de la rétropropagation à travers le temps. Ces phénomènes rendent très difficile l’apprentissage de dépendances longues, limitant leur efficacité sur des séquences étendues.
Pour répondre à ce verrou, les Long Short-Term Memory (LSTM) sont introduits en 1997. Ils ajoutent des mécanismes de portes (input, forget, output) permettant de contrôler explicitement le flux d’information et de conserver des dépendances à long terme. Les LSTM améliorent significativement les performances des modèles séquentiels, mais au prix d’une complexité accrue et d’un calcul intrinsèquement séquentiel, ce qui limite fortement leur parallélisation et leur passage à l’échelle sur des architectures modernes.
5. 2017 : l’arrivée des Transformers : l’onde de choc
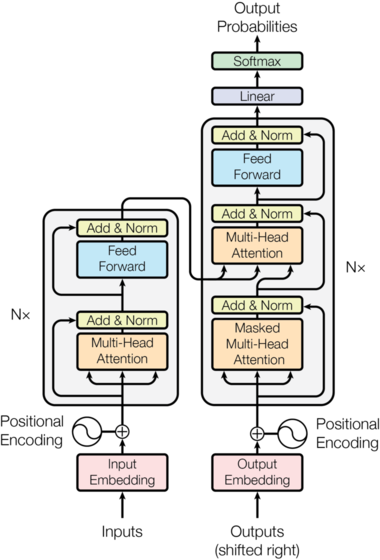
En 2017, un article au titre presque provocateur, “Attention Is All You Need”, bouleverse tout ce que l’on croyait savoir sur les réseaux de neurones. Les limites des RNN ne sont pas seulement liées à la qualité des représentations, mais aussi à leur mode de calcul séquentiel. Les Transformers proposent une alternative radicale en supprimant toute récursion temporelle. Le mécanisme de self-attention permet à chaque token d’évaluer son importance relative par rapport à tous les autres tokens de la séquence.
Concrètement, chaque élément est projeté dans des espaces de requêtes, clés et valeurs. Les produits scalaires entre requêtes et clés déterminent les poids d’attention, utilisés pour agréger les valeurs. Cette approche permet une compréhension globale du contexte, indépendamment de la distance entre les mots, et surtout une parallélisation complète du calcul.
Cette combinaison explique pourquoi les Transformers ont rapidement remplacé les architectures récurrentes. Ils sont plus rapides à entraîner, plus efficaces à grande échelle et mieux adaptés aux infrastructures modernes basées sur GPU et TPU.
6. L’ère de la Gen AI : créativité des machines (2020–2025)

Pendant longtemps, l’intelligence artificielle s’est principalement appuyée sur des modèles prédictifs ou discriminatifs. Leur objectif était clair : classer des données, estimer une probabilité conditionnelle ou prédire une valeur cible à partir d’entrées observées. Ces approches ont permis des avancées majeures dans des domaines comme la détection de fraude, la recommandation, la reconnaissance d’images ou la traduction automatique, mais elles restaient fondamentalement réactives : elles répondaient à une question précise posée par l’utilisateur ou le système.
L’IA générative introduit une rupture conceptuelle. Plutôt que de se limiter à prédire une étiquette ou une valeur, les modèles génératifs apprennent la distribution sous-jacente des données afin de produire de nouveaux échantillons plausibles. Cette approche s’est d’abord illustrée par la génération de texte, puis rapidement par la génération d’images, de code, de sons ou de vidéos. Aujourd’hui, la Gen AI est utilisée dans des domaines extrêmement variés : développement logiciel, création de contenu, assistance à la décision, recherche d’information, design, marketing, éducation ou encore santé.
Les Large Language Models (LLM) incarnent cette transition. En apprenant à prédire le prochain token sur des corpus massifs, ces modèles acquièrent une représentation statistique riche du langage. Cette représentation n’est pas limitée à une tâche unique : elle peut être réutilisée pour le résumé, la traduction, la génération de code, le raisonnement textuel ou l’interaction conversationnelle. Là où l’IA prédictive nécessitait un modèle spécifique par tâche, les LLM proposent un socle généraliste, adaptable par simple instruction ou par ajustement fin (fine-tuning).
Cette différence marque un changement profond dans la manière dont les systèmes d’IA sont intégrés aux produits. L’IA prédictive optimise des décisions dans un pipeline bien défini ; l’IA générative devient un outil transversal, capable d’interagir avec des systèmes, de produire du contenu intermédiaire et de guider des processus complexes. C’est dans ce contexte qu’émergent les agents IA : des systèmes combinant modèles génératifs, mémoire, outils externes et capacités d’action. Un agent ne se contente plus de répondre à une requête ; il peut planifier, exécuter des actions, évaluer leurs résultats et s’adapter de manière itérative à un objectif donné.
Conclusion et perspective : vers l’AGI, entre promesses et interrogations
L’évolution du deep learning, des perceptrons aux modèles génératifs actuels, montre une trajectoire claire : une augmentation continue de la capacité de représentation, de généralisation et d’autonomie des systèmes d’IA. L’émergence des LLM et des agents relance naturellement la question de l’Artificial General Intelligence (AGI), l’AGI est généralement conçue comme une intelligence de niveau humain, capable de transférer ses compétences entre domaines de manière flexible.
Les projections sur une possible AGI varient fortement, allant de quelques années à plusieurs décennies, tout en reposant sur l’hypothèse non démontrée que ce type d’intelligence soit effectivement atteignable.Certains y voient une extension naturelle des architectures actuelles à plus grande échelle ,d’autres estiment qu’un saut conceptuel majeur reste nécessaire. Cette incertitude alimente à la fois l’enthousiasme, pour les gains de productivité, de créativité et de connaissance ,et les inquiétudes, notamment en matière de contrôle, d’alignement et d’impact sociétal.
À ce stade, une chose est certaine : l’IA n’est plus seulement un outil d’optimisation ou de prédiction. Elle devient un acteur logiciel, capable de générer, raisonner et agir. Comprendre son histoire et ses mécanismes n’est donc pas un exercice académique, mais une condition essentielle pour aborder de manière lucide les choix technologiques et éthiques qui se dessinent.
