
Table des matières
- Concepts fondamentaux
- Architecture en couches
- Traitement des transactions
- Les composants en détail
- Gestion du temps et horloges
- Pricing
- Considérations de design
- Cas d'usage recommandés
Introduction
Annoncé lors de re:Invent 2024, Amazon Aurora DSQL est une base de données SQL serverless et distribuée, compatible PostgreSQL (sous-ensemble de fonctionnalités), conçue plus spécifiquement pour les workloads OLTP (Online Transaction Processing).
Amazon Aurora DSQL se distingue par son modèle actif-actif : toutes les Régions d'un cluster sont des noeuds capables de traiter à la fois les lectures et les écritures. Le service est entièrement managé, serverless, et facturé à l'usage (pay-per-use).
Cet article synthétise le fonctionnment de ce service très novateur et y ajoute une analyse détaillée du modèle de pricing, des comparatifs de performances ainsi que mon analyse des principaux cas d'usage.
1. Concepts fondamentaux
1.1 Disponibilité et durabilité
Quand on concoit une architecture compprenant une base de données deux caratéristiques sont particulièrement critiques, DSQL ne fait pas exception:
- Disponibilité : pourcentage de temps pendant lequel le système est accessible.
- Single-Région : SLA de 99.99% (< 1h de downtime/an)
- Multi-Région : SLA de 99.999% (≈ 5 min 16 s de downtime/an)
- Durabilité : garantie de préservation des données à long terme sans perte ni corruption.
- Aurora DSQL garantit zéro perte de données après un commit réussi grâce à la réplication synchrone entre région.
Important : pour bénéficier du SLA 99.999%, il ne suffit pas de déployer en multi-Région. L'application doit être conçue pour basculer automatiquement entre les Régions en cas de problème.
1.2 OLTP vs OLAP
Aurora DSQL est conçu pour l'OLTP : traitement de transactions à haut volume avec des temps de réponse rapides (ex : plateforme e-commerce traitant des commandes). Elle n'est pas destinée à l'OLAP (analyse complexe sur de grands volumes de données).
1.3 Transactions ACID
Aurora DSQL fournit des transactions ACID interactives, petite synthèse des ces notions historiques:
| Propriété | Description |
|---|---|
| Atomicité | Une transaction est traitée comme une unité indivisible : succès complet ou échec complet. |
| Cohérence | Une transaction fait passer la base d'un état valide à un autre. À ne pas confondre avec la cohérence de lecture (read-after-write consistency). |
| Isolation | Les transactions concurrentes produisent le même résultat que si elles étaient exécutées séquentiellement. |
| Durabilité | Les changements committés ne sont jamais perdus. |
Le terme "interactif" signifie qu'on peut initier une transaction, lire des données, exécuter du code applicatif, puis continuer la transaction contrairement aux transactions batch.
1.4 Niveaux d'isolation
Le niveau d'isolation d'une base de données définit le degré de visibilité qu'une transaction a sur les modifications effectuées par d'autres transactions concurrentes. Plus le niveau est élevé, plus les garanties de cohérence sont fortes, mais plus le coût en performance peut être important (gestion des locks et coordination). C'est un curseur entre performance et sécurité des données : chaque niveau élimine progressivement certaines anomalies de lecture (dirty reads, non-repeatable reads, phantom reads) au prix d'une concurrence réduite.
Aurora DSQL opère au niveau strong snapshot isolation :
| Niveau | Dirty reads | Non-repeatable reads | Phantom reads | Description |
|---|---|---|---|---|
| Read uncommitted | ✅ | ✅ | ✅ | Lit les données non committées |
| Read committed | ❌ | ✅ | ✅ | Ne lit que les données committées |
| Repeatable read | ❌ | ❌ | ✅ | Verrouille les lignes lues mais pas les "gaps" |
| Snapshot isolation | ❌ | ❌ | ❌ | Utilisé par DSQL. Vue cohérente au moment du début de la transaction. Conflit détecté sur le write set. |
| Serializable | ❌ | ❌ | ❌ | Plus strict : conflit détecté aussi sur le read set. |
Principe : chaque transaction travaille sur un snapshot de la base prise au moment où elle démarre. Pendant toute sa durée, elle ne voit pas les modifications faites par les autres transactions concurrentes.
Exemple concret :
- T1 démarre → voit le solde d'un compte = 100 €
- T2 démarre → voit le même solde = 100 €
- T2 modifie le solde à 150 € et committe ✅
- T1 essaie de modifier le solde à 80 € et tente de committer → conflit détecté, T1 est annulée (rollback) ❌
DSQL détecte que la ligne que T1 veut modifier a été changée par T2 entre le début de T1 et son commit. C'est la détection de conflit sur le write set : seules les lignes qu'on veut écrire sont vérifiées. Si deux transactions lisent la même ligne mais qu'une seule l'écrit, il n'y a pas de conflit.
Différence avec serializable :
| Niveau | Conflit sur les écritures (write set) | Conflit sur les lectures (read set) |
|---|---|---|
| Snapshot isolation | ✅ | ❌ |
| Serializable | ✅ | ✅ |
Pourquoi snapshot isolation est un bon compromis pour Aurora DSQL :
- Cohérence forte sans verrouillage bloquant : chaque transaction voit un état cohérent de la base sans poser de lock en lecture, ce qui élimine les dirty reads, non-repeatable reads et phantom reads et donc les mêmes garanties que serializable pour la majorité des cas d'usage.
- Performance en environnement distribué : dans un système multi-région comme DSQL, les verrous distribués (nécessaires pour serializable) impliquent des allers-retours réseau coûteux entre régions. Snapshot isolation évite ces verrous en lecture, ce qui réduit considérablement la latence.
- Concurrence élevée : les transactions en lecture seule ne bloquent jamais les transactions en écriture, et inversement. Cela permet un débit bien supérieur à serializable, où même les lectures peuvent provoquer des conflits.
- Trade-off maîtrisé : la seule anomalie théorique non couverte est le write skew (deux transactions lisent les mêmes données puis écrivent chacune sur des lignes différentes, créant un état globalement incohérent). En pratique, ce scénario est rare et peut être géré au niveau applicatif (par exemple avec des contraintes
CHECKouUNIQUE).
En résumé, pour un système distribué à grande échelle, snapshot isolation offre pour moi le meilleur ratio garanties de cohérence / performance.
1.5 Contrôle de concurrence : MVCC + OCC
Aurora DSQL utilise MVCC (Multi-Version Concurrency Control) avec un verrouillage optimiste (OCC) et validation rétrospective (backward validation).
MVCC : chaque modification crée une nouvelle version de la ligne. Les lecteurs voient la version valide au moment de leur transaction, sans bloquer les écritures.
Verrouillage optimiste vs pessimiste :
| Aspect | Pessimiste (PostgreSQL standard) | Optimiste (Aurora DSQL) |
|---|---|---|
| Approche | Verrouille les ressources préventivement | Laisse les transactions s'exécuter librement |
| Vérification des conflits | Pendant l'exécution | Au moment du commit |
| Avantage | Pas de retry nécessaire | Pas de contention, meilleur throughput |
| Inconvénient | Bottleneck sur les locks | Retry nécessaire en cas de conflit |
Les 3 phases de l'OCC dans DSQL :
- Exécution : toutes les requêtes SQL sont traitées, les écritures sont loguées localement.
- Validation : au commit, le système vérifie les conflits avec les transactions déjà committées (backward validation).
- Écriture : si pas de conflit, les changements sont persistés. Sinon, la transaction est annulée.
2. Architecture en couches
2.1 Vue d'ensemble
L'architecture de DSQL sépare les responsabilités en composants faiblement couplés, chacun scalant indépendamment. Ce design s'aligne sur trois principes fondamentaux :
- Chaque composant évolue et s'améliore indépendamment
- Chaque composant scale individuellement
- Chaque composant prend ses propres décisions d'isolation de sécurité
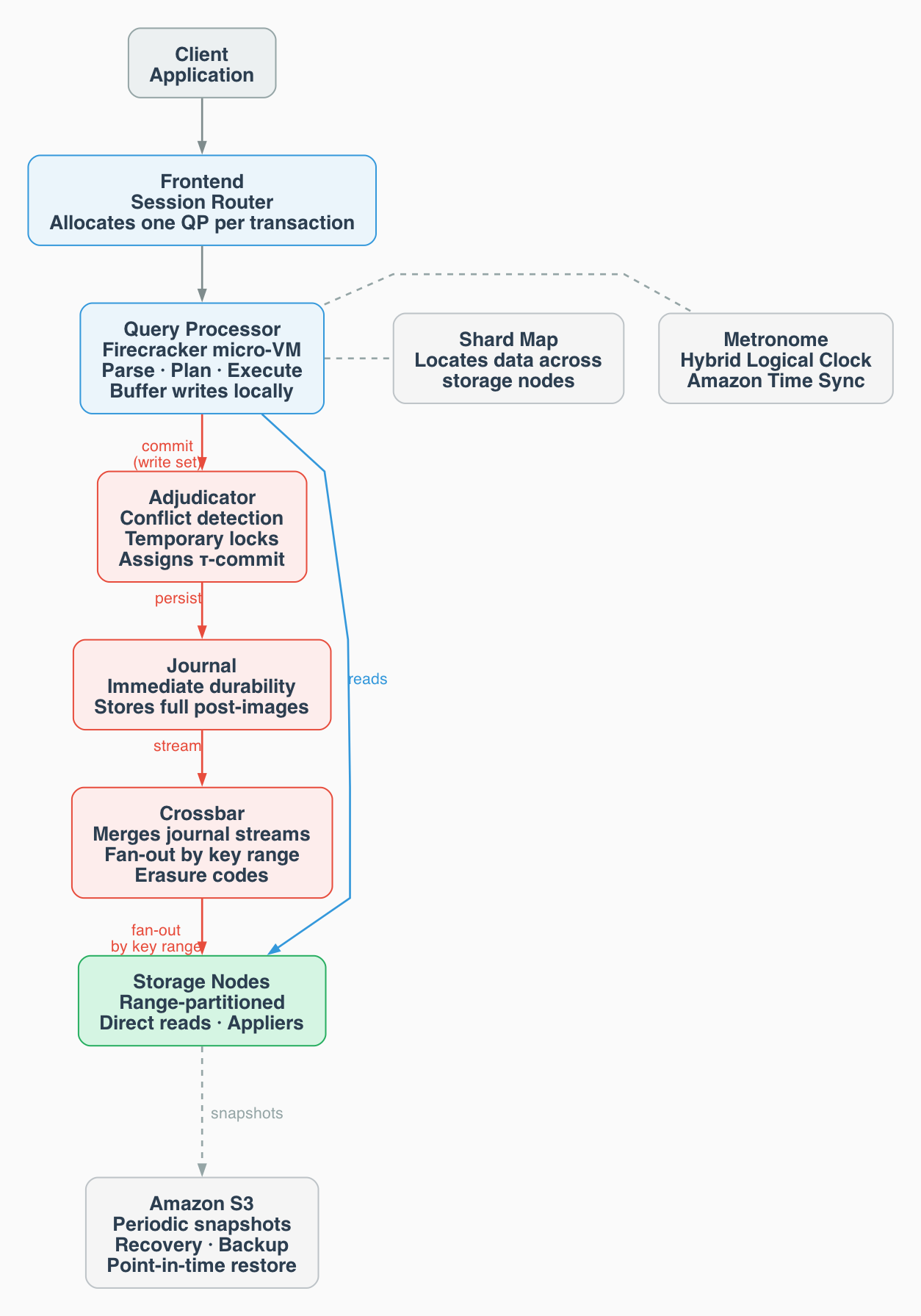
2.2 Déploiement single-Région vs multi-Région
Single-Région :
- Architecture multi-tiers (compute, commit, stockage) répartie sur 3 Availability Zones.
- Un endpoint dédié pour l'accès applicatif.
- SLA : 99.99%.
Multi-Région :
- 2 Régions synchronisées, chacune avec la même infrastructure que le single-Région.
- 1 Région témoin (witness) : participe au quorum des transactions et sert de tiebreaker en cas de partition réseau. Elle ne stocke pas de données à l'exception des logs de transsactions et n'exécute pas de transactions.
- SLA : 99.999%.
- Un endpoint par région pour l'accès applicatif.
- Maximum : 2 Régions read-write (pas plus).
2.3 Latence
| Opération | Latence cross-Région |
|---|---|
| Lectures (read-only) | Aucune, servies localement dans la Région d'origine |
| Écritures (read-write) | 2 RTT cross-Région au commit uniquement, proportionnelle à la distance entre les 2 Régions |
Point clé : la latence cross-Région s'applique par transaction, pas par statement. Peu importe le nombre de requêtes dans une transaction, le surcoût est le même.
2.4 Intégrations AWS
Aurora DSQL s'intègre nativement avec :
- IAM pour le contrôle d'accès
- CloudTrail pour l'audit
- CloudWatch pour le monitoring (métriques DPU détaillées)
- AWS Backup pour la sauvegarde et restauration
- AWS KMS pour le chiffrement au repos (clés AWS-owned ou customer-managed)
- CloudFormation / Provider terraftom AWS pour le déploiement IaC
3. Traitement des transactions
Aurora DSQL gère deux types de transactions : read-only et read-write. Il n'existe pas de transaction write-only, car toute écriture nécessite de vérifier le schéma de la table et l'unicité des clés primaires.
3.1 Transactions read-only
Le flux complet d'une transaction en lecture seule :
Étape 1 — Initiation de la transaction
- Le client émet
BEGINouSTART TRANSACTION. - Le frontend alloue un Query Processor (QP) dédié — une micro-VM spécialisée.
- Le QP lit l'heure courante via Amazon Time Sync Service et assigne le timestamp de début τ-start.
- Ce timestamp est le point de référence pour toute la transaction.
Étape 2 — Exécution des requêtes
- Le QP parse le SQL, valide la syntaxe et la sémantique, et construit le plan d'exécution.
- Il consulte la shard map pour localiser les données sur les storage nodes.
Étape 3 — Récupération des données
- Les storage nodes effectuent des vérifications pré-lecture : ils s'assurent que toutes les transactions avec des timestamps antérieurs à τ-start ont été entièrement traitées.
- Si nécessaire, les nœuds attendent (mécanisme de wait) pour maintenir les garanties de cohérence.
- Les nœuds retournent un snapshot cohérent des données telles qu'elles existaient à τ-start.
- Le QP agrège les résultats de multiples nœuds.
- Plusieurs requêtes peuvent être exécutées dans la même transaction (transactions interactives).
Étape 4 — Commit
- Pour les transactions read-only : τ-commit = τ-start.
- La transaction a une durée logique de zéro.
- Conséquence : une transaction read-only ne peut jamais échouer à cause d'un conflit.
- Aucune latence cross-AZ ni cross-Région.
3.2 Transactions read-write
Étape 1 — Initiation
- Identique aux transactions read-only.
Étape 2 — Exécution et gestion des écritures
- Le QP traite les requêtes SQL comme pour les read-only.
- Les opérations d'écriture sont spoolées localement dans le QP (bufferisées).
- En cas de rollback ou déconnexion, les écritures spoolées sont simplement supprimées.
- Mécanisme d'Early Abort : quand le QP lit depuis le stockage, le storage node indique si la version lue est la plus récente. Si la transaction tente de modifier une ligne qui a déjà une version plus récente, elle est immédiatement annulée sans attendre le commit.
Étape 3 — Traitement du commit
- Le QP consulte la shard map pour identifier les adjudicators responsables des clés modifiées.
- Il construit le write set : lignes modifiées (y compris les nouvelles lignes) + post-images.
- Il soumet le write set aux adjudicators désignés.
Étape 4 — Phase d'adjudication
- Chaque adjudicator vérifie si des écritures ont eu lieu sur les lignes modifiées depuis τ-start.
- Si un conflit est détecté par n'importe quel adjudicator → le commit est rejeté.
- Si aucun conflit :
- L'adjudicator pose des locks internes de très courte durée (uniquement pendant la phase de commit) sur les lignes affectées, garantissant un accès exclusif le temps de finaliser l'écriture dans le journal.
- Il sélectionne un τ-commit > τ-start et supérieur à tout τ-commit précédemment émis.
- Les post-images et timestamps sont écrits dans le journal.
- Après acquittement du journal → le QP confirme le commit au client.
- Du point de vue du client, la transaction est terminée.
Étape 5 — Mise à jour du stockage
- Le crossbar reçoit les écritures depuis le journal.
- Il route les lignes pertinentes vers les storage nodes appropriés selon leur plage de clés.
- Les storage nodes persistent les changements.
- Cette étape est asynchrone par rapport à la confirmation au client.
4. Les composants en détail
4.1 Query Processor (QP)
Le QP est le cœur de l'exécution SQL dans Aurora DSQL.
Caractéristiques :
- Transient, shared-nothing, soft-state : il ne persiste rien lui-même.
- Tourne dans une micro-VM Firecracker (le coeur du service AWS lambda) sur des hôtes QP (chaque hôte supporte plusieurs QPs).
- Un QP = une transaction : isolation totale entre transactions.
Ce que le QP fait :
- Parse, planifie et optimise les requêtes SQL
- Récupère les données, fusionne les résultats, effectue les agrégations
- Bufferise les écritures localement jusqu'au commit ou rollback
- Orchestre le protocole de COMMIT avec les autres composants
- Pousse les prédicats vers le stockage (predicate pushdown) pour réduire les données transférées
Ce que le QP ne fait PAS :
- Durabilité (→ journal)
- Contrôle de concurrence (→ adjudicator)
- Tolérance aux pannes (→ architecture distribuée)
- Scale-out (→ géré par le service globalement)
Pas de cache de données : contrairement aux bases traditionnelles, le QP ne cache pas les données. Ce choix qui pourrait sembler contre-intuitif, s'explique par le fait que DSQL résout autrement les problèmes que le cache adresse habituellement :
- Latence stockage élevée → optimisation du placement et des performances de la couche storage
- Accès multiples aux structures (BTrees) → opérations poussées également vers le stockage
- Cohérence crash via I/O latching → non nécessaire car le QP ne persiste rien
Résultat : performances cohérentes à toutes les échelles, sans les complexités de gestion de cache.
Modèle single-transaction : contrairement aux systèmes data warehouse, une requête s'exécute entièrement dans un seul QP. Les clients lents n'impactent pas les autres (pas de noisy neighbor).
Limite : durée maximale d'une transaction = 300 secondes (hard limit).
4.2 Adjudicator
L'adjudicator est le composant qui décide si une transaction read-write peut committer.
Sharding :
- Le key space est distribué entre les adjudicators.
- Chaque clé est possédée par exactement un adjudicator globalement.
- Le nombre d'adjudicators scale proportionnellement à la taille du key space.
Système de baux (leases) :
- Quand un adjudicator prend la responsabilité d'une plage de clés, il acquiert un bail contre un journal.
- Il maintient ce bail via des heartbeats périodiques.
- À tout moment, exactement un adjudicator a autorité sur chaque clé.
- Ce mécanisme prévient le conflits en cas de panne.
En multi-Région : les adjudicators détectent les écritures en conflit à travers toutes les Régions.
4.3 Journal
Le journal réinvente complétement l'implémentation de la durabilité dans une base de données.
Rôle : c'est le journal (et non le stockage) qui est responsable de la durabilité. Une transaction est considérée comme committée dès qu'elle est écrite dans le journal.
Contenu : le journal stocke les post-images complètes des transactions (pas juste les opérations ou les deltas). Avantages :
- Opérations de recovery prévisibles
- Traitement optimisé sur les storage nodes
- Overhead de calcul minimal pendant la réplication
Scaling : plusieurs journaux opèrent en parallèle pour gérer le haut débit. Grâce à l'ordonnancement garanti par l'adjudicator, les transactions peuvent écrire dans n'importe quel journal disponible. La sélection du journal peut être optimisée en choisissant un journal dans la même AZ que l'adjudicator qui committe.
Recovery :
- Snapshots périodiques stockés dans Amazon S3.
- En cas de recovery : chargement du dernier snapshot + rejeu du journal depuis ce point.
- Pas besoin de rejouer l'historique complet des transactions.
4.4 Crossbar
Le crossbar est l'intermédiaire entre les journals et les storage nodes.
Fonctions :
- Fusion : souscrit à tous les journals (partiellement ordonnés) et génère un flux totalement ordonné de transactions.
- Fan-out : décompose les transactions atomiques par plage de clés, pour que chaque storage node ne reçoive que les données pertinentes à son key space.
- Synchronisation : ne transmet les données qu'après avoir observé un timestamp spécifique sur tous les journals qu'il surveille (mécanisme de low-water mark).
Réduction de la tail latency via erasure codes :
- L'adjudicator divise les messages en M segments.
- Le message original peut être reconstruit à partir de k segments (k ≤ M).
- Les segments sont distribués sur plusieurs journals.
- Le crossbar peut avancer dès qu'il a reçu k segments de n'importe quel message.
- Ce design assure à la fois scalabilité et tolérance aux pannes.
4.5 Storage
Le stockage dans Aurora DSQL se distingue fondamentalement des systèmes de stockage de bases de données conventionnels.
Chemins de données :
- Écritures : Journal → Crossbar → Storage nodes.
- Lectures : QP → Storage nodes directement (bypass des composants intermédiaires pour l'efficacité).
Durabilité :
- Le stockage n'est pas responsable de la durabilité immédiate (c'est le rôle du journal).
- Il assure la durabilité long terme via des snapshots périodiques dans Amazon S3.
- Ces snapshots servent à : recovery après panne, opérations de scaling, création d'index, backup/restore (y compris point-in-time recovery).
Partitionnement : les données sont distribuées sur les nœuds par range-partitioning basé sur la clé primaire. Des réplicas de lecture supplémentaires peuvent être créés pour servir des volumes de lectures plus élevés.
Garbage collection : basée sur un trim horizon de 5 minutes (correspondant à la durée maximale d'une transaction). Chaque composant gère son propre GC basé sur le temps local, sans coordination complexe.
Tolérance aux pannes : en cas de défaillance d'un storage node, le système redistribue les partitions vers d'autres nœuds et restaure l'état depuis les snapshots.
5. Gestion du temps et horloges
La capacité de DSQL à fonctionner de manière scalable sans coordination excessive entre et au sein des Régions repose sur son utilisation très avancées des horloges.
5.1 Le problème du temps dans les systèmes distribués
Dans un système distribué, le temps pose un défi fondamental :
- Horloges physiques : intuitives et alignées avec notre perception du temps, mais souffrent de problèmes de synchronisation entre nœuds distribués.
- Horloges logiques (ex : timestamps de Lamport) : excellentes pour traquer la causalité, mais ne répondent pas aux exigences de timing d'un système transactionnel.
5.2 Hybrid Logical Clocks (HLC)
Aurora DSQL résout ce dilemme avec une horloge logique hybride (HLC) construite par-dessus Amazon Time Sync Service :
- Le système maintient à la fois une composante d'horloge physique et une composante logique.
- La valeur de l'horloge est mise à jour avant chaque opération de lecture.
- Si l'horloge physique avance plus vite (cas typique) → le temps logique se synchronise.
- Si l'horloge physique est en retard → le temps logique progresse approximativement au rythme de l'horloge physique.
Garantie fondamentale : le temps ne recule jamais, tout en maintenant un lien fort avec la réalité physique.
D'autres bases de données distribuées comme CockroachDB et MongoDB utilisent également des horloges hybrides, validant la pertinence de cette approche.
Bénéfices des HLC :
- Garanties de cohérence : quand un client lit des données depuis plusieurs nœuds, les HLC garantissent une vue cohérente. Cela permet à DSQL de lire depuis des storage nodes dans plusieurs Régions sans synchronisation.
- Gestion des transactions : chaque transaction reçoit un timestamp de début et un timestamp de commit, facilitant la détection fiable des conflits.
5.3 Linéarisabilité des transactions read-only
En pratique, la synchronisation des horloges n'est pas parfaite. Les systèmes modernes utilisent un suivi poussé des bornes d'erreur.
L'API clockbound d'Amazon EC2 fournit pour chaque mesure de temps :
- Une estimation du temps courant
- Une borne d'erreur supérieure
- Une borne d'erreur inférieure
Cela définit trois intervalles :
- Passé connu (en dessous de la borne d'erreur)
- Présent incertain (dans la borne d'erreur)
- Futur connu (au-dessus de la borne d'erreur)
En sélectionnant la borne supérieure, le QP s'assure que les données qu'il demande au stockage englobent toutes les transactions committées. C'est pourquoi les transactions read-only sont linéarisables : les opérations apparaissent s'exécuter dans un ordre cohérent et en temps réel.
5.4 Timing des transactions read-write
Pour les transactions read-write, DSQL garantit la linéarisabilité via un mécanisme plus élaboré :
Au démarrage :
- Le QP assigne un τ-start garanti dans le futur.
- Pour toute lecture, ce timestamp est passé au stockage, qui s'assure d'avoir traité toutes les transactions antérieures avant d'exécuter la lecture.
Au commit :
- L'adjudicator assigne un τ-commit.
- Le QP s'assure que ce timestamp est vérifiablement dans le passé avant de confirmer le commit au client.
Exemple concret avec deux transactions séquentielles A et B :
Transaction A :
├─ Début → τ-start
├─ Exécution (toutes les actions utilisent τ-start)
├─ Commit → τ-commitA
└─ Le système attend que τ-commitA soit vérifiablement dans le passé
avant de confirmer au client
Transaction B (démarre après le commit de A) :
├─ Début → τ-start garanti > τ-commitA
└─ B verra TOUJOURS les changements de A
Garde-fou contre les anomalies de timing : si la transaction A obtient une fenêtre de timestamp large tandis que B obtient une fenêtre plus étroite, il y a un risque que le τ-start de B soit inférieur à celui de A, malgré le fait que B démarre après A. Pour prévenir cela, le QP retarde la réponse au client jusqu'à ce que les bornes de τ-start et τ-commit soient vérifiées comme étant dans le passé.
5.5 Amazon Time Sync Service
La synchronisation du temps dans les systèmes distribués est un problème notoirement complexe, surtout en multi-Région. Aurora DSQL s'appuie sur Amazon Time Sync Service :
- Accessible depuis toutes les instances EC2
- Utilise des horloges atomiques synchronisées avec des satellites GPS
- Précision au niveau de la microseconde
- Contrairement aux approches traditionnelles basées uniquement sur NTP, le modèle hybride de DSQL fournit à la fois causalité et alignement avec le monde réel.
6. Pricing
Aurora DSQL adopte un modèle de tarification serverless pur, aligné avec la philosophie pay-per-use d'AWS. Pas d'instances à provisionner, pas de frais quand la base est idle, le service scale automatiquement à zéro.
6.1 Les deux axes de facturation
| Composant | Unité | Prix (US East - Ohio) |
|---|---|---|
| Activité base de données | DPU (Distributed Processing Unit) | $8 / million de DPUs |
| Stockage | GB-mois | $0.33 / GB-mois |
6.2 Qu'est-ce qu'un DPU ?
Le Distributed Processing Unit (DPU) est l'unité de facturation unifiée qui mesure le travail effectué par le système. Il englobe :
- Le compute : exécution des requêtes SQL (joins, fonctions, agrégations)
- Les I/O : lectures et écritures vers le stockage
- Les tâches de fond : mise à jour des statistiques, maintenance d'index, auto ANALYZE
Contrairement aux modèles traditionnels qui facturent séparément vCPU, mémoire, bande passante réseau et IOPS, le DPU consolide tout en une seule métrique. Le mix entre compute, read et write n'affecte pas le coût total : 1M de DPUs coûte $8, quelle que soit la répartition.
Monitoring via CloudWatch — 4 métriques détaillées :
| Métrique | Description |
|---|---|
ComputeDPU | Temps passé à exécuter les requêtes SQL |
ReadDPU | Ressources utilisées pour lire les données du stockage |
WriteDPU | Ressources utilisées pour écrire les données dans le stockage |
MultiRegionWriteDPU | Ressources utilisées pour répliquer les écritures vers les clusters pairés en multi-Région |
La somme de ces 4 métriques approxime l'usage total de DPUs sur la facture mensuelle. Toutes sont facturées au même tarif.
6.3 Free tier
Chaque mois, automatiquement déduit de la facture :
| Ressource | Quantité gratuite |
|---|---|
| DPUs | 100 000 DPUs/mois |
| Stockage | 1 Go/mois |
À titre de référence, AWS indique que 100K DPUs ≈ 700 000 transactions TPC-C (benchmark avec un mix 95/5 lecture/écriture). C'est suffisant pour un environnement de développement, un blog personnel, un site portfolio, ou un side project type app de budget ou CRM léger.
Note : en cas d'utilisation d'AWS Organizations, le free tier s'applique par management account.
6.4 Coûts additionnels
| Élément | Coût |
|---|---|
| Réplication inter-AZ (au sein d'une Région) | Inclus, aucun frais |
| Réplication multi-Région | Facturée via MultiRegionWriteDPU au même tarif que les écritures d'origine. Pas de frais de data transfer séparés. |
| Data transfer IN (depuis Internet/services AWS) | Gratuit |
| Data transfer OUT vers services AWS (même Région) | Gratuit |
| Data transfer OUT vers services AWS (autre Région) | Tarifs standard AWS (source et destination) |
| Data transfer OUT vers Internet | Tarifs standard AWS (100 Go/mois gratuits dans le free tier AWS global) |
| Région witness (multi-Région) | Aucun frais de DPU ni de stockage |
| Backup/Restore | Via AWS Backup, facturé selon les tarifs AWS Backup |
6.7 Optimisation des coûts
- Database Savings Plans : engagement en $/heure sur 1 an pour des réductions sur les workloads prévisibles.
- Monitoring CloudWatch : utilisez les 4 métriques DPU pour comprendre la répartition de vos coûts et identifier les optimisations possibles.
- Design des clés : éviter les hot keys réduit les retries (et donc les DPUs consommés inutilement).
- Transactions courtes : minimiser la durée des transactions réduit le risque de conflits et de retries.
7. Considérations de design
7.1 Compatibilité PostgreSQL
Aurora DSQL est compatible avec un sous-ensemble de PostgreSQL. Certaines fonctionnalités seront ajoutées au fil du temps, mais d'autres resteront différentes en raison de la nature distribuée du service. Consultez la documentation de compatibilité pour la liste complète.
7.2 Pas de locks explicites
Aurora DSQL n'implémente pas de verrouillage en raison de son contrôle de concurrence optimiste. Si votre application repose sur des locks explicites de base de données, une refactorisation sera nécessaire. Référez-vous à la documentation sur le contrôle de concurrence.
7.3 Design des clés primaires
Pour tirer le meilleur parti de DSQL, deux principes essentiels :
- Éviter les hot key writes : quand plusieurs transactions modifient la même donnée simultanément, une seule réussit et les autres doivent retenter. Utilisez des clés aléatoires (UUID) ou des composites à haute cardinalité.
- Éviter les hot key ranges : concentrer les opérations dans des plages de clés spécifiques compromet l'architecture distribuée de DSQL.
7.4 Limites
Les limites à connaitre à ne jamais oublier lors des phases de design!
Quotas cluster (ajustables via Service Quotas)
| Limite | Valeur par défaut | Ajustable ? |
|---|---|---|
| Clusters single-Région par compte AWS | 20 | Oui |
| Clusters multi-Région par compte AWS | 5 | Oui |
| Stockage max par cluster | 10 TiB (jusqu'à 256 TiB sur demande) | Oui |
| Connexions max par cluster | 10 000 | Oui |
| Taux de connexion max par cluster | 100 connexions/seconde | Non |
| Burst de connexions max | 1 000 connexions | Non |
| Jobs de restauration concurrents | 4 | Non |
Limites base de données (non ajustables)
| Limite | Valeur |
|---|---|
| Durée maximale d'une transaction | 300 secondes (hard limit) |
| Durée maximale d'une connexion | 60 minutes |
| Nombre max de Régions read-write | 2 (+ 1 witness) |
| Bases de données par cluster | 1 |
| Schémas par base de données | 10 |
| Tables par base de données | 1 000 |
| Vues par base de données | 5 000 |
| Séquences par base de données | 5 000 |
| Colonnes par table | 255 |
| Index par table | 24 |
| Colonnes par clé primaire ou index secondaire | 8 |
| Taille combinée des colonnes d'une clé primaire ou index | 1 KiB |
| Taille max d'une ligne | 2 MiB |
| Taille max d'une colonne (hors index) | 1 MiB |
| Taille max de la définition d'une vue | 2 MiB |
| Données modifiées par transaction (write) | 10 MiB |
| Lignes mutées par transaction | 3 000 lignes |
| Mémoire max par opération de requête | 128 MiB |
À noter : la limite d'une seule base de données par cluster et de 10 schémas par base sont des contraintes structurantes à prendre en compte dès la phase de design. La limite de 3 000 lignes mutées par transaction impacte directement les opérations de bulk insert/update.
Pour la liste complète et à jour, consultez la documentation officielle des quotas.
7.5 Sécurité
- Chiffrement au repos via AWS KMS (clés AWS-owned ou customer-managed)
- Contrôle d'accès via IAM (permissions au niveau du schéma)
- Audit via CloudTrail (événements de management et de données)
- Connexions : IPv4 uniquement
8. Cas d'usage recommandés
Comme nous l'avons vu Aurora DSQL est conçu pour les workloads OLTP distribués nécessitant une haute disponibilité, une scalabilité forte et réactive et une cohérence forte. Voici les cas d'usage pour lesquels le service apporte pour moi le plus de valeur d'après mes nombreux tests et premiers retours d'expérience.
8.1 Applications financières et transactionnelles
Les systèmes de paiement, de gestion de transactionsn de trading nécessitent des transactions ACID strictes avec zéro perte de données. DSQL répond à ces exigences grâce à sa réplication synchrone et son SLA de 99.999% en multi-Région. La snapshot isolation garantit que les transactions concurrentes produisent des résultats cohérents, et le mécanisme d'adjudication empêche toutes incohérences.
8.2 Architectures microservices et event-driven
DSQL s'intègre naturellement dans les architectures serverless et microservices. Chaque service peut ouvrir des connexions indépendantes, et le modèle un QP par transaction garantit l'absence de noisy neighbor. L'intégration native avec IAM permet un contrôle d'accès granulaire par service. Combiné avec Lambda, API Gateway et EventBridge, DSQL constitue la brique de persistance relationnelle d'une stack entièrement serverless. On a enfin un service équivalent à Amazon DynamoDB mais pour du SQL!
8.3 Applications nécessitant une continuité d'activité en cas de perte de région
Pour les secteurs où la continuité de service est une obligation réglementaire ou concurentielle, le déploiement multi-Région avec failover automatique et zéro perte de données offre un niveau de résilience difficile à atteindre avec des bases de données traditionnelles. La Région witness assure le quorum même en cas de partition réseau, sans stocker de données sensibles.
8.4 Application cloud native / serverless
Si vous développez une nouvelle application reposant uniquement sur du serverless et nécessitant du SQL, plus de débat ou de composition DynamoDB / Aurora / RDS. Et si l'utilisation est faible (base de paramétrage,...) le free tier absorbera l'essentiel des coûts.
8.5 Quand DSQL n'est pas le bon choix
Tout aussi important, les cas où il ne faut pas utiliser DSQL (ce n'est pas pour rien qu'il ya autant de service pour gérer des bases de données):
- Workloads OLAP : requêtes analytiques complexes sur de grands volumes → préférer Amazon Redshift ou Athena.
- Applications nécessitant la compatibilité PostgreSQL complète : triggers, stored procedures, extensions, types custom → préférer Aurora PostgreSQL classique.
- Bulk operations massives : la limite de 3 000 lignes mutées par transaction et 10 MiB par write rend les imports massifs contraignants.
- Schémas très complexes : la limite de 10 schémas par base et 1 000 tables par base peut être restrictive pour les applications monolithiques avec un modèle de données très riche.
- Workloads avec forte contention sur les mêmes lignes : le contrôle de concurrence optimiste génère des retries fréquents quand de nombreuses transactions modifient simultanément les mêmes données.
Conclusion
Amazon Aurora DSQL représente une approche fondamentalement différente de la base de données relationnelle distribuée. En séparant compute, commit et stockage en composants indépendants, en s'appuyant sur des horloges logiques hybrides pour la cohérence globale, et en adoptant un contrôle de concurrence optimiste, le service élimine de nombreuses contraintes opérationnelles traditionnelles: provisioning d'instances, fenêtres de maintenance, tuning de cache.
Les choix architecturaux (pas de cache, un QP par transaction, durabilité déléguée au journal, erasure codes dans le crossbar) sont autant de décisions qui privilégient la simplicité opérationnelle et la prévisibilité des performances au détriment de certaines fonctionnalités PostgreSQL traditionnelles. C'est un compromis assumé qui positionne DSQL comme un choix pertinent pour les applications OLTP nécessitant une forte disponibilité et une scalabilité rapide et transparente.
Dans un deuxième article nous nous plongerons dans des benchmarks entre DSQL, Amazon Aurora Postgresql standard et serverless afin de comparer les performances, la scalabilité et les coûts.