

1. Qu’est-ce que l’Event-Driven Architecture (EDA) et pourquoi est-elle incontournable en 2026 ?
Le principe
Au lieu de faire communiquer les systèmes par des appels synchrones (API REST classiques), on utilise des événements asynchrones :
- Un système publie un événement ("Commande créée", "Paiement validé")
- D'autres systèmes s'abonnent et réagissent en autonomie
- Pas de couplage direct entre producteur et consommateurs
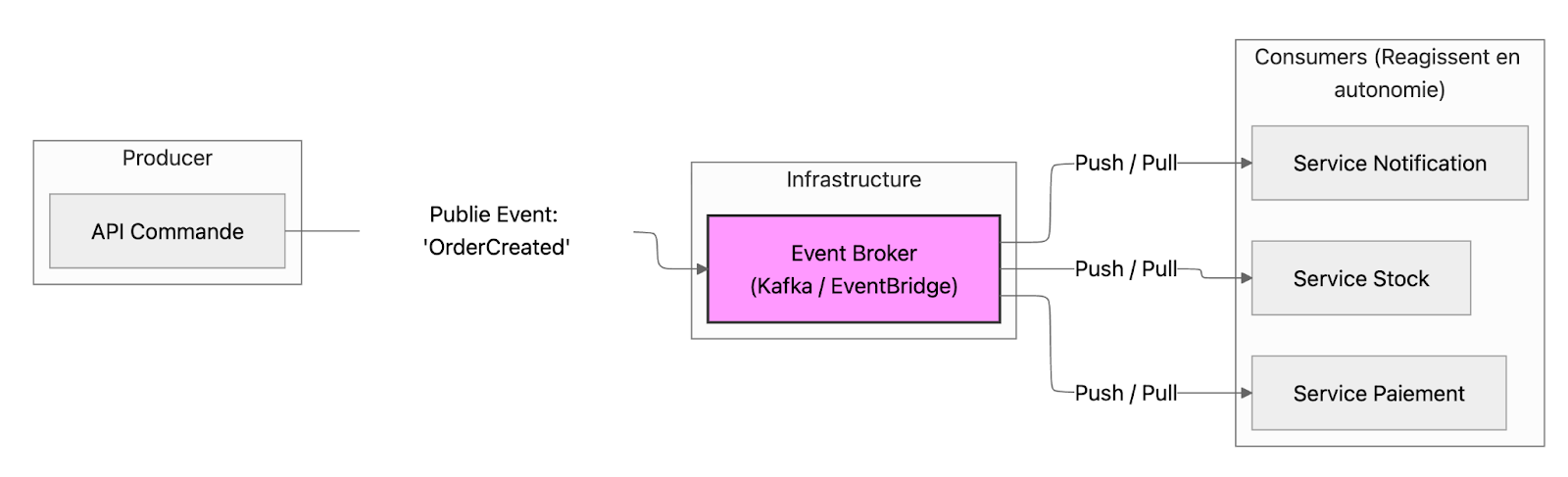
Pourquoi c'est incontournable en 2026
1. Scalabilité naturelle
- Chaque système scale indépendamment
- Pas de goulet d'étranglement synchrone
- Buffer naturel en cas de pic de charge
2. Résilience augmentée
- Si un système consommateur est down, l'événement est conservé
- Retry automatique
- Pas de cascade de pannes (mais possiblement un système partiellement à jour)
3. Business agility
- Ajouter un nouveau cas d'usage = ajouter un nouvel abonné
- Pas besoin de modifier le producteur d'événements
Comment une Event-Driven Architecture améliore-t-elle les performances d’une plateforme e-commerce ?
Contexte : Plateforme e-commerce avec 15M de visiteurs/mois
Avant (architecture synchrone) :
API Commande → appelle → API Stock
→ appelle → API Paiement
→ appelle → API Notification
→ appelle → API Facturation
→ appelle → API Fidélité
Problèmes Technique :
- Timeout si un service est lent
- 1 service down = toute la chaîne bloquée
- Temps de réponse imprévisible
Problèmes Business :
- Transactionnel qui cause des annulations de commande non voulu
Après (Event-Driven) :
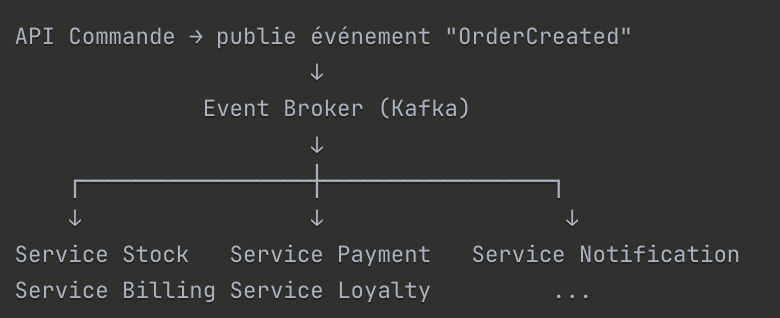
Résultats :
- Temps de réponse API divisé par 5 (300ms → 60ms)
- Disponibilité 99.95% → 99.99%
- Ajout de 3 nouveaux cas d'usage (programme fidélité, ML scoring) sans toucher au core
Quels sont les pièges à éviter avec une Event-Driven Architecture ?
❌ Piège 1 : Event Explosion Trop d'événements granulaires → complexité ingérable
Solution : Définir des événements métier significatifs (Domain Events)
❌ Piège 2 : Debugging de l'enfer "Pourquoi cette commande n'a pas généré de facture ?"
Solution : Distributed Tracing (OpenTelemetry), Event Sourcing pour audit trail
❌ Piège 3 : Eventual Consistency mal gérée Les données ne sont pas immédiatement à jour partout
Solution : UX qui assume l'asynchrone ("Votre commande est en cours de traitement")
❌ Piège 4 : Cohérence transactionnelle Le paiement et la gestion des stocks ne sont peut être pas à découpler
Stack technologique 2026
Event Brokers :
- Kafka : Standard du marché, battle-tested, écosystème riche
- AWS EventBridge : Managed, intégration native AWS
- Azure Event Grid : Pour écosystème Microsoft
- NATS : Léger, performant, moins de features
Outils complémentaires :
- Schema Registry (Confluent, AWS Glue) pour versioning des événements
- Debezium pour Change Data Capture (CDC)
- Outbox Pattern pour garantir la publication d'événements
Quand NE PAS utiliser EDA
- ❌ Application CRUD simple avec <1000 utilisateurs
- ❌ Vous n'avez pas les compétences pour opérer un event broker
- ❌ Votre business exige une cohérence stricte temps réel
2. Qu’est-ce que le pattern API-First et API Gateway et pourquoi structurer son SI avec ?
Le principe
API-First : Concevoir l'API avant d'implémenter le service
API Gateway : Point d'entrée unique qui orchestre, sécurisé, et monitore les APIs
Comment fonctionne une architecture API-First avec API Gateway ?
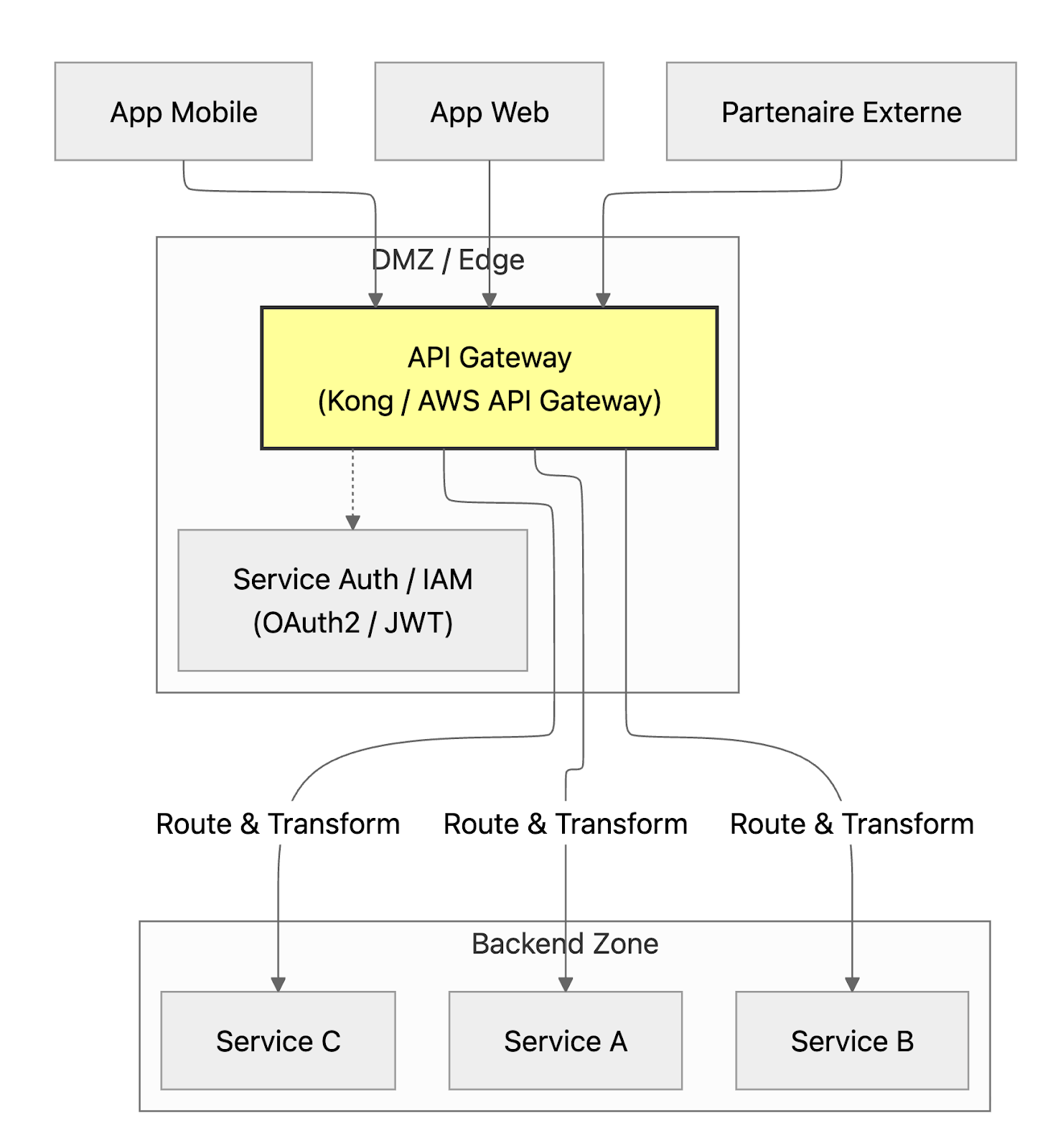
Quel est le rôle d’une API Gateway dans une architecture moderne ?
- Sécurité : Authentification, autorisation, rate limiting
- Routing : Redirection vers le bon service backend
- Transformation : Agrégation de réponses, transformation de format
- Observabilité : Logs, métriques, tracing
- Caching : Réduire la charge sur les backends
Comment une API Gateway améliore-t-elle l’architecture d’un SI bancaire ?
Problème :
- 150 APIs exposées de façon anarchique
- Chaque équipe gère sa propre sécurité
- Impossible de monitorer l'usage global
- Partenaires externes doivent s'intégrer à 20 APIs différentes
Solution :
- Déploiement d'un API Gateway (Kong)
- Catalogue d'APIs centralisé (avec équipe dédiée pour standardisation en fonction de la taille du DSI)
- Politiques de sécurité mutualisées (OAuth2, JWT)
- Developer Portal pour les partenaires
Résultats :
- Time-to-market pour nouvelle API : -60%
- Incidents de sécurité : -80%
- Taux d'adoption par les partenaires : x3
Qu’est-ce que le pattern Backend for Frontend (BFF) et quand l’utiliser ?
Plutôt qu'une API générique, on crée des APIs spécifiques par canal :
Mobile App → BFF Mobile → Services métier
Web App → BFF Web → Services métier
Partner → BFF Partner → Services métier
Avantage :
- UX optimisée par canal (mobile ≠ web)
- Évite le "over-fetching" ou "under-fetching"
- Équipes autonomes par canal
Stack technologique 2026
API Gateways Cloud :
- AWS API Gateway + Lambda
- Google Apigee
- Azure API Management
API Gateways Open Source :
- Kong Gateway (le plus populaire)
- Tyk
- Apache APISIX
Standards :
- OpenAPI 3.1 pour la spécification
- AsyncAPI pour les APIs événementielles
- GraphQL pour agrégation côté client
Quand NE PAS utiliser un API Gateway
- ❌ Vous avez <5 APIs et un seul frontend
- ❌ Communication interne uniquement (pas d'exposition externe)
- ❌ Latence critique (<10ms) où chaque hop * compte
3. CQRS + Event Sourcing - Quand lire et écrire ne font pas bon ménage
Comment fonctionnent CQRS et Event Sourcing concrètement ?
CQRS (Command Query Responsibility Segregation) :
- Séparer les modèles de lecture (Query) et d'écriture (Command)
- Deux bases de données différentes optimisées pour leur usage
Event Sourcing :
- Au lieu de stocker l'état actuel, on stocke tous les événements
- L'état actuel est reconstruit en rejouant les événements
Pourquoi CQRS et Event Sourcing sont-ils de plus en plus utilisés ?
Cas d'usage 1 : Performance
- Base d'écriture : optimisée pour les transactions (PostgreSQL)
- Base de lecture : optimisée pour les requêtes complexes (Elasticsearch)
- Scalabilité indépendante
Cas d'usage 2 : Audit et Compliance
- Traçabilité totale (banking, healthcare, fintech)
- "Comment en est-on arrivé à cet état ?"
- Replay des événements pour debugging
Cas d'usage 3 : Analytics temps réel
- Les événements alimentent directement le Data Lake
- Pas de batch ETL nocturne, tout est “pseudo” temps réel ou synchrone
Architecture concrète

Contexte : Gestion de contrats d'assurance complexes
Avant :
- Base de données unique avec 300 tables
- Requêtes d'analyse qui bloquent les écritures
- Impossible de retracer l'historique précis d'un contrat
Après (CQRS + Event Sourcing) :
- Write DB : Event Store (PostgreSQL) avec tous les événements
- Read DB 1 : Vue "contrats actifs" (MongoDB) pour les agents
- Read DB 2 : Vue "analytics" (Elasticsearch) pour le BI
- Read DB 3 : Vue "audit" pour la conformité
Résultats :
- Performance des requêtes BI : x10
- Traçabilité complète pour audit ACPR
- Capacité à reconstruire l'état à n'importe quelle date
Les pièges à éviter
❌ Piège 1 : Complexité surévaluée CQRS+ES c'est complexe. Ne l'utilisez que si vous en avez vraiment besoin.
❌ Piège 2 : Eventual Consistency Les read models ne sont pas immédiatement à jour après une commande.
❌ Piège 3 : Gestion de la migration de schéma Changer la structure d'un événement quand des millions sont déjà stockés.
Stack technologique 2026
Event Stores :
- EventStoreDB : Spécialisé, performant
- Marten (pour .NET)
- Axon Framework (pour Java)
- PostgreSQL avec tables d'événements (approche DIY)
Frameworks :
- Axon Server (Java)
- Akka (Scala/Java)
- Eventuous (.NET)
Quand NE PAS utiliser CQRS+ES
- ❌ CRUD simple sans besoin d'audit poussé
- ❌ Équipe junior sans expérience du pattern
- ❌ Pas de besoin de scalabilité différenciée lecture/écriture
4. Qu’est-ce que le Saga Pattern et comment gérer des transactions distribuées ?
Le problème
Dans un monde microservices, comment gérer une transaction qui implique plusieurs services ?
Exemple : Réservation de voyage
- Réserver vol ✅
- Réserver hôtel ✅
- Réserver location voiture ❌ ÉCHEC
→ Comment annuler le vol et l'hôtel déjà réservés ?
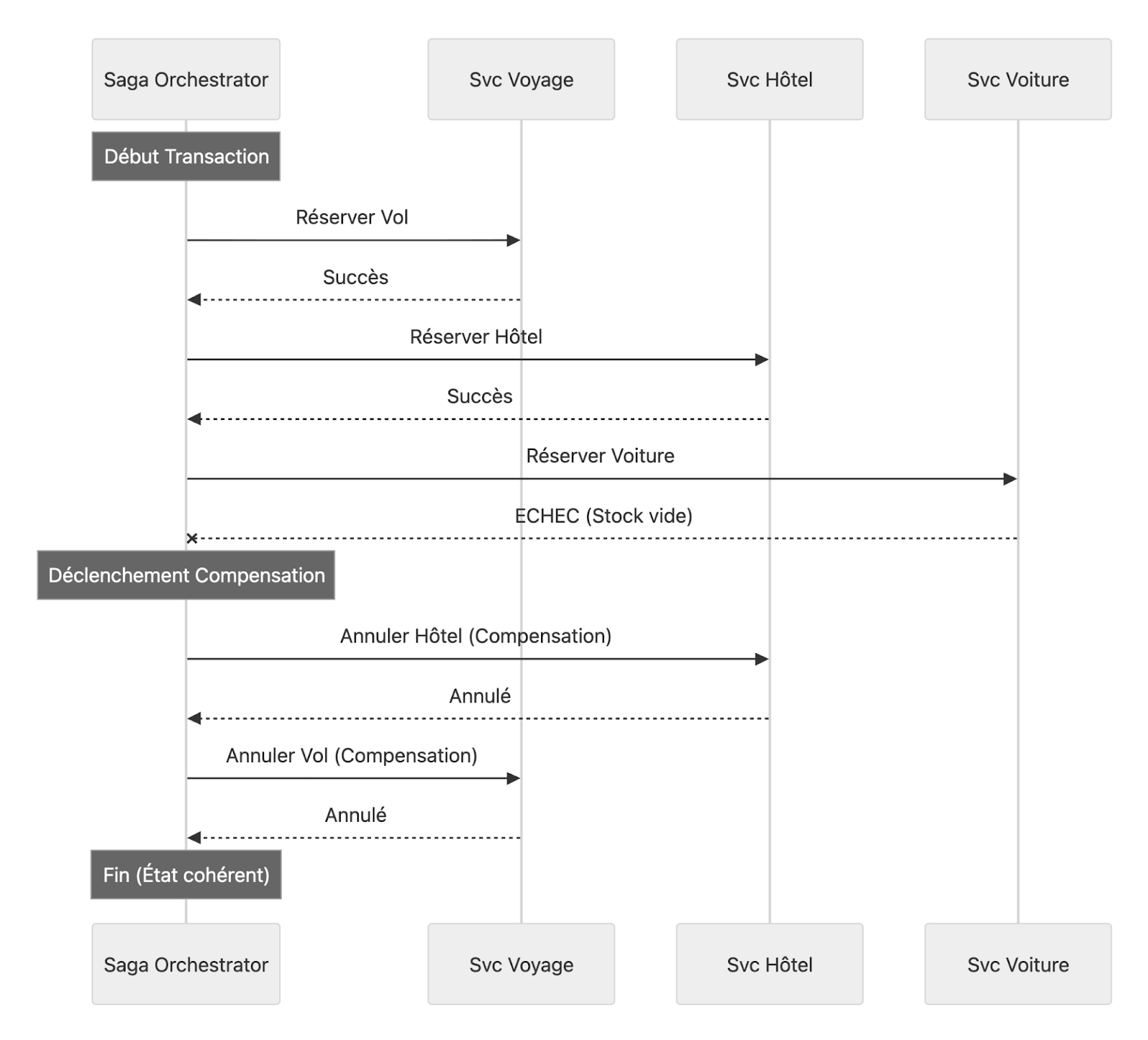
Quelles sont les différences entre orchestration et chorégraphie dans le Saga Pattern ?
Orchestration : Un coordinateur central
Saga Orchestrator
↓ Command
Service Voyage → Service Vol
↓ Command
Service Voyage → Service Hôtel
↓ Command
Service Voyage → Service Voiture (FAIL)
↓ Compensation
Service Voyage → Service Vol (annulation)
Service Voyage → Service Hôtel (annulation)
Avantages : Logique centralisée, facile à comprendre
Inconvénients : Point unique de défaillance, couplage
Chorégraphie : Coordination distribuée via événements
Service Vol → Publie "VolRéservé"
↓
Service Hôtel → Écoute → Réserve → Publie "HôtelRéservé"
↓
Service Voiture → Écoute → ÉCHEC → Publie "RéservationÉchouée"
↓
Service Vol & Hôtel → Écoutent → Annulent leurs réservations
Avantages : Découplage, pas de single point of failure
Inconvénients : Logique distribuée, plus difficile à debugger
❌ Piège 1 : Défaillance des Transactions Compensatoires
Le succès de la Saga repose entièrement sur la capacité d'annuler les opérations précédentes.
- Le Problème : Concevoir une action compensatoire qui est irréversible (ex: envoyer un e-mail à un client ou livrer un colis) ou qui échoue à rétablir l'état initial des données.
- Conséquence : Le système se retrouve dans un état incohérent et partiellement mis à jour, car l'annulation n'a pas pu être complétée.
- Conseil : Toujours s'assurer que l'action compensatoire est l'inverse sémantique de l'action initiale (ex: Débiter -> Créditer).
❌ Piège 2 : Manque d'Idempotence
En communication asynchrone (messagerie), un même message peut être livré plusieurs fois par le broker de messages (à cause des retransmissions ou des échecs temporaires).
- Le Problème : Un service exécute plusieurs fois la même étape de la Saga, suite à la réception de messages dupliqués.
- Conséquence : Effets secondaires indésirables (ex: le paiement est validé deux fois, la quantité en stock est décrémentée plusieurs fois) et erreurs métier.
- Conseil : Utiliser un identifiant de corrélation unique sur chaque message et enregistrer les ID traités dans une table Inbox ou Outbox pour ignorer les doublons.
❌ Piège 3 : Monolithe Distribué (avec l'Orchestrateur)
Le pattern d'Orchestration peut centraliser la logique de coordination.
- Le Problème : L'Orchestrateur détient trop de logique métier des services participants, et pas seulement la logique de flux. Il devient trop intelligent.
- Conséquence : Le couplage entre l'orchestrateur et les services devient fort, ce qui contredit l'objectif des microservices. L'orchestrateur devient un Single Point of Failure (SPOF).
- Conseil : L'orchestrateur doit être léger et uniquement responsable du séquençage et de la gestion des états. Les services participants doivent contenir et exposer leur propre logique métier.
❌ Piège 4 : Complexité de la Chorégraphie
Le pattern de Chorégraphie (basé sur l'échange d'événements) peut devenir ingérable.
- Le Problème : Utiliser la chorégraphie pour une Saga avec un grand nombre d'étapes ou des flux non-linéaires/conditionnels complexes.
- Conséquence : Le flux de la Saga devient difficile à visualiser, à déboguer et à modifier. La maintenance est coûteuse et les développeurs ont du mal à comprendre qui écoute quel événement.
- Conseil : Réserver la chorégraphie aux flux simples. Pour les processus complexes, l'Orchestration est souvent plus claire car le flux est explicitement défini.
❌ Piège 5 : Oubli du Traçage Distribué
Le flux d'exécution se propage sur de nombreux services.
- Le Problème : Ne pas implémenter un système pour suivre le chemin complet d'une seule Saga à travers tous les microservices.
- Conséquence : Le débogage des échecs (surtout ceux qui se produisent au milieu d'une longue séquence) est presque impossible sans savoir où la Saga a échoué et pourquoi.
- Conseil : Utiliser des outils de Distributed Tracing (comme OpenTelemetry) en s'assurant que chaque message et chaque service propage un ID de corrélation unique à la Saga.
❌ Piège 6 : Ignorer la Cohérence Finale
Le pattern Saga garantit uniquement la cohérence finale (Eventual Consistency), et non une isolation immédiate (ACID).
- Le Problème : Supposer que les données créées/modifiées par une étape de la Saga sont immédiatement stables pour les autres parties du système.
- Conséquence : D'autres transactions ou lectures (ex: un utilisateur qui consulte son panier) peuvent accéder à des données qui sont dans un état transitoire ou qui sont sur le point d'être annulées par une transaction compensatoire.
- Conseil : Gérer explicitement cet état transitoire (ex: afficher le statut Paiement en attente) ou utiliser des verrous sémantiques au niveau applicatif si une isolation plus forte est temporairement requise.
Comment implémenter un Saga Pattern dans un processus e-commerce ?
Processus de commande impliquant :
- Validation du stock
- Paiement
- Mise à jour fidélité
- Envoi confirmation
@workflow.defn
class OrderSagaWorkflow:
async def run(self, order):
try:
await workflow.execute_activity(reserve_stock, order)
await workflow.execute_activity(process_payment, order)
await workflow.execute_activity(update_loyalty, order)
await workflow.execute_activity(send_confirmation, order)
except Exception:
# Compensation automatique
await workflow.execute_activity(release_stock, order)
await workflow.execute_activity(refund_payment, order)
Stack technologique 2026
Orchestration :
- Temporal.io : Le standard émergent, robuste
- Netflix Conductor
- Camunda : BPMN pour workflows complexes
- AWS Step Functions : Managed, intégration AWS
Chorégraphie :
- Event Broker (Kafka) + Event Handlers
- Pas d'outil spécifique, c'est un pattern
Quand choisir orchestration ou chorégraphie dans une Saga ?
Découvrir les Tech Trends 2026.
Pour aller plus loin sur le sujet :
- Patterns d'Architecture 2026 - Du Hype à la Réalité du Terrain Part. 2/2
- TOGAF en 2026 - Au-delà du framework, une culture d'architecture
- Impedance Mismatch : pourquoi votre modélisation legacy tue votre expérience omnicanale et API
Vous souhaitez moderniser votre SI ?
Nos experts sont là pour vous accompagner au mieux dans vos prises de décision.
