

Le 14 Novembre dernier, le DevFest Toulouse a une nouvelle fois réuni la communauté tech locale pour une journée riche en échanges et en découvertes. Notre équipe Ippon était présente pour profiter de cette édition haute en couleur, suivre les tendances du moment et échanger avec des passionnés venus de tous horizons.
Revenons ensemble sur plusieurs conférences qui ont particulièrement retenu l’attention de nos collaborateurs.
Article co-écrit par François DE BUTTET, Justin AUBIN, Miguel BERGES ALBACETE, Tanoh N’GOYET et David DALLAGO.
Sommaire
- Sous le capot des LLMs : toutes ces questions que vous n'avez jamais osé poser à leur sujet
- Je malmène ton LLM en direct avec 10 failles de sécurités
- Porter DOOM sur Kindle : quand la passion du code nous ramène aux fondamentaux
- Veille technologique : ma méthode pour rester à jour
- La domotique débridée, du sac poubelle au sanglier !
Sous le capot des LLMs : toutes ces questions que vous n'avez jamais osé poser à leur sujet
François DE BUTTET
Conférence présentée par Guillaume LAFORGE, Developer Advocate Google Cloud.

La présentation de Guillaume Laforge explore plusieurs concepts clés et "bizarreries" des grands modèles de langage (LLM), en commençant par la raison pour laquelle ils ont souvent du mal à compter les lettres (par exemple, les 'R' dans "strawberry").
Le concept de "token"
La raison principale de cette difficulté est que les LLM ne "voient" pas les lettres individuelles. Ils traitent le langage en "morceaux", appelés tokens.
- Pourquoi des tokens ? C'est un "juste milieu" efficace. Traiter des lettres individuelles serait trop lourd pour la mémoire et la fenêtre de contexte, tandis que traiter des mots entiers créerait un vocabulaire trop vaste.
- Comment ça marche ? Des algorithmes comme le BPE (Byte-Pair Encoding) fusionnent les caractères fréquents pour créer un vocabulaire de tokens (par exemple,
u-n-r-e-l-a-t-e-ddevient progressivementun-related).
Comment les LLM choisissent le mot suivant ?
La génération de texte n'est pas prédéfinie ; elle est probabiliste. Pour une phrase comme “The cat is a...", le modèle attribue une probabilité à chaque token possible ("creature" 56 %, "magnificient" 28 %, etc.).
Pour contrôler cette sélection aléatoire, on utilise des hyperparamètres :
- Top-K : ne choisit que parmi les 'K' tokens les plus probables (ex: le Top 2).
- Température : ajuste la "créativité".
- Température basse : favorise le choix le plus probable (ex: "creature" passe à 97 %, "magnificient" 3 %).
- Température élevée : augmente le caractère aléatoire et la diversité des réponses (ex: "creature" passe à 41 %, "magnificient" 28 %, etc).
Mais ils restent non-déterministe : même avec une température de 0 et un Top-K à 1, les LLM ne sont pas totalement déterministes. Des facteurs comme les arrondis des nombres à virgule flottante introduisent de légères variations.
Concepts et bizarreries des LLM
- Foundation vs Instruction-Tuned : un modèle de "foundation (pre-trained)" se contente de prédire la suite du texte (ex: il répond à "Quelle est la capitale de la France ?" par "Quelle est la capitale de l'Allemagne ?"). Un modèle "instruction-tuned" est entraîné à suivre des instructions et répondra "Paris".
- Confabulation vs Hallucination : Guillaume suggère que le terme "confabulation" (combler des lacunes de mémoire par des falsifications que l'on croit vraies) est plus précis que "hallucination" (une expérience sensorielle) pour décrire les erreurs des LLM.
- Influence contextuelle : les LLM sont très sensibles au contexte. Une question sur le "meilleur joueur de foot" peut donner "Messi" , mais si la question contient "un ami en France me demande …", la réponse peut devenir "Mbappé".
- The Reversal Curse : les LLM ont du mal à inverser les faits. Un modèle qui sait que "La mère de Tom Cruise est Mary Lee Pfeiffer" ne saura pas forcément répondre à "Qui est le fils de Mary Lee Pfeiffer ?".
Je malmène ton LLM en direct avec 10 failles de sécurités
Justin AUBIN
Conférence présentée par Gaëtan ELEOUET, développeur JAVA pour Meritis.
Lors du DevFest Toulouse 2025, Gaëtan ELEOUET a proposé une session aussi pédagogique que percutante : montrer, en direct, comment une application intégrant un LLM peut être détournée si elle n’est pas correctement pensée.
L’objectif était simple : démontrer que les risques liés aux IA génératives ne sont pas théoriques ni réservés aux géants du secteur. Ils concernent toutes les équipes qui intègrent un modèle dans leurs services.
Pour structurer son intervention, Gaëtan s’appuie sur l’OWASP, une organisation internationale dédiée à la sécurité des applications, reconnue pour ses guides et classements qui aident les développeurs à identifier les risques et prévenir les vulnérabilités.
OWASP fournit une liste de 10 vulnérabilités sur l’IA Générative et les applications qui embarquent des LLMs. Il a notamment illustré plusieurs attaques en conditions réelles :
- Manipulation des prompts : des instructions malveillantes peuvent détourner le comportement du modèle ou lui faire révéler des informations internes.
- Exposition de données sensibles : si le modèle a accès à des bases de données ou des informations confidentielles, des fuites peuvent survenir.
- Autonomie excessive et actions non contrôlées : un LLM avec trop de permissions peut modifier des données ou effectuer des actions critiques de manière imprévue.
- Empoisonnement des données et désinformation : des données corrompues ou mal vérifiées peuvent biaiser le modèle et générer des réponses erronées ou inventées.
- Risques liés aux sorties : le modèle peut générer du code, des urls malicieux ou des contenus exploitables. Il y a notamment un vecteur d’attaque méconnu qui consiste à racheter des noms de domaines indexés par le modèle pour en faire des sites malveillants (cf. article)
- Consommation excessive de ressources : sans limites, un LLM peut utiliser disproportionnellement du calcul, des API ou de l’énergie, créant des coûts ou des problèmes de disponibilité.
Voir ces failles exploitées en live rappelle à quel point un LLM peut être manipulable, et combien sa surface d’attaque dépasse largement les schémas classiques.
Le message clé du talk est clair : la sécurité d’un LLM n’est pas “magique”, elle repose sur le travail des équipes de développement. C’est à nous de définir un périmètre d’action strict, de contrôler les entrées et les sorties, d’anonymiser les données sensibles et de surveiller la chaîne d’intégration. Bien encadré, l’IA générative devient un outil puissant; mal protégé, elle peut ouvrir une porte béante à des comportements inattendus.
Cette session a offert une bonne piqûre de rappel : intégrer l’IA, oui, mais jamais sans y appliquer les mêmes exigences de sécurité que pour le reste de notre architecture (ou même plus …).
Porter DOOM sur Kindle : quand la passion du code nous ramène aux fondamentaux
Miguel BERGES ALBACETE
Retour sur le talk de Moustapha AGACK au DevFest Toulouse 2025.
"Can it run DOOM?" si vous êtes un habitué de Reddit ou des forums tech, vous connaissez surement le mème. Mais quand Moustapha Agack, développeur TypeScript chez Zenika, arrive au DevFest Toulouse 2025 avec une liseuse Kindle à 20€ qui fait tourner le jeu DOOM, ça devient une leçon d'ingénierie système.
Ce qui m'a marqué d'entrée, c'est son honnêteté : "DOOM est sorti en 93, moi en 94, donc non, ça n'a pas du tout bercé mon enfance". Moustapha, ne triche pas avec nous. C'est un pur side-project, parti d'une curiosité.
L'architecture de DOOM, c'est une leçon de design intemporelle
Pourquoi DOOM est il porté partout, des calculatrices aux thermomix connectés ? La réponse tient dans son architecture, étonnamment moderne pour 1993 :
- Le moteur : du C pur, aucune dépendance plateforme
- Les données (WAD) : assets, maps, textures, totalement séparés
- Les interfaces : video_system, audio_system, input_system isolés dans des modules dédiés
Le cœur du jeu (le métier) est totalement séparé de la machine, et ne sait rien de la plateforme sur laquelle il tourne.
Cross-compilation vs Mac
Premier reality check : compiler un simple Hello World sur Mac et l'exécuter sur Kindle (ARM Cortex-A8) retourne un Syntax error.
# Sur Mac (x86_64)
gcc hello.c -o hello
scp hello root@kindle:/tmp/
# Sur Kindle (ARM)
./hello
# → Syntax error: "(" unexpectedLa solution de Moustapha est représentative de notre époque.
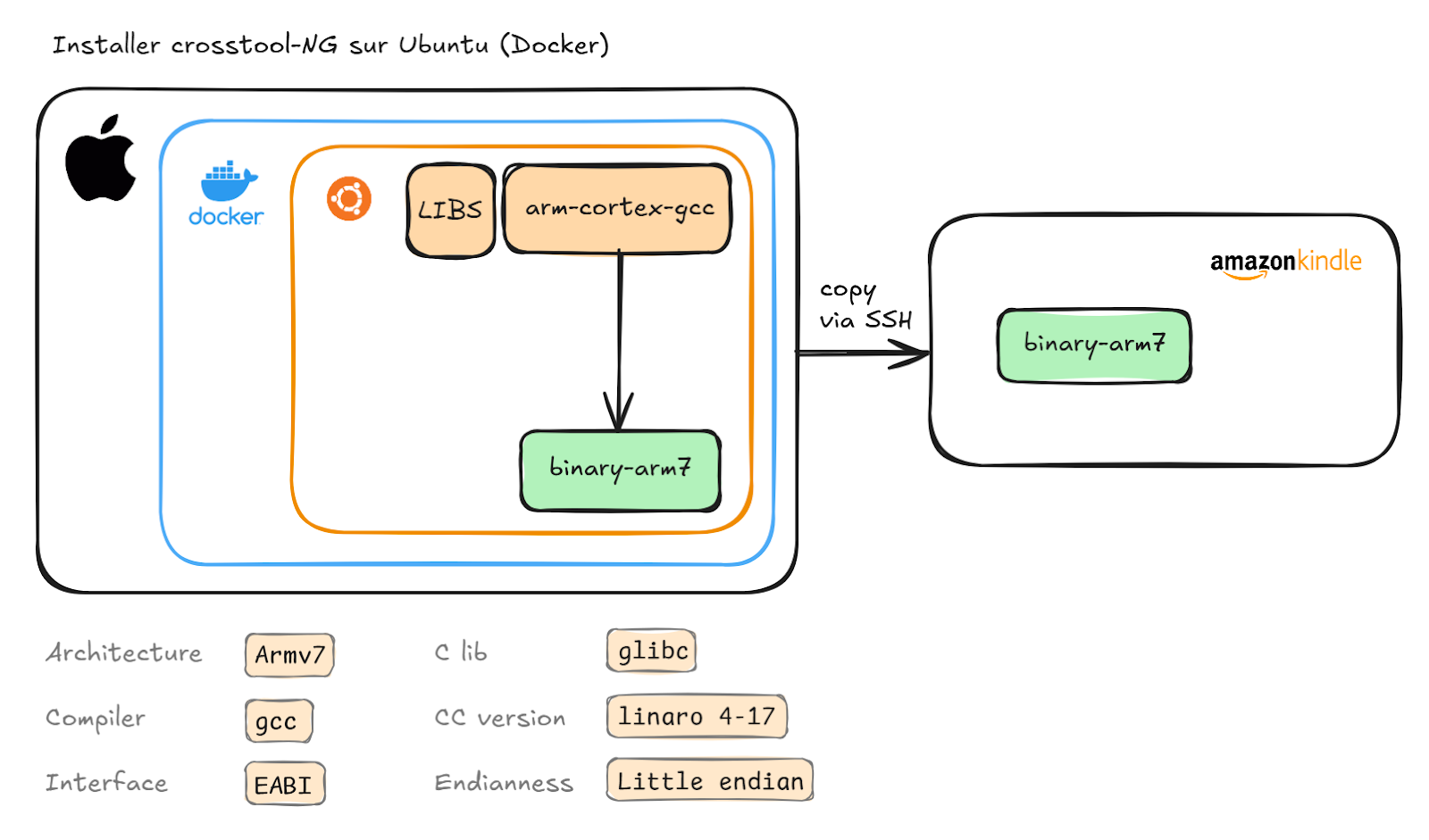
Plutôt que de configurer une toolchain complexe sur macOS (avec les warnings "attention: ne cassez pas votre Mac"), on passe par Docker avec 35 minutes de build et 16 GB de container final. Cette solution équivaudrait à ajouter un .cache() sur une requête Spark lente plutôt que d'optimiser le code. C'est pragmatique, ça marche, même si ce n'est pas la solution définitive.
Redécouvrir le hardware
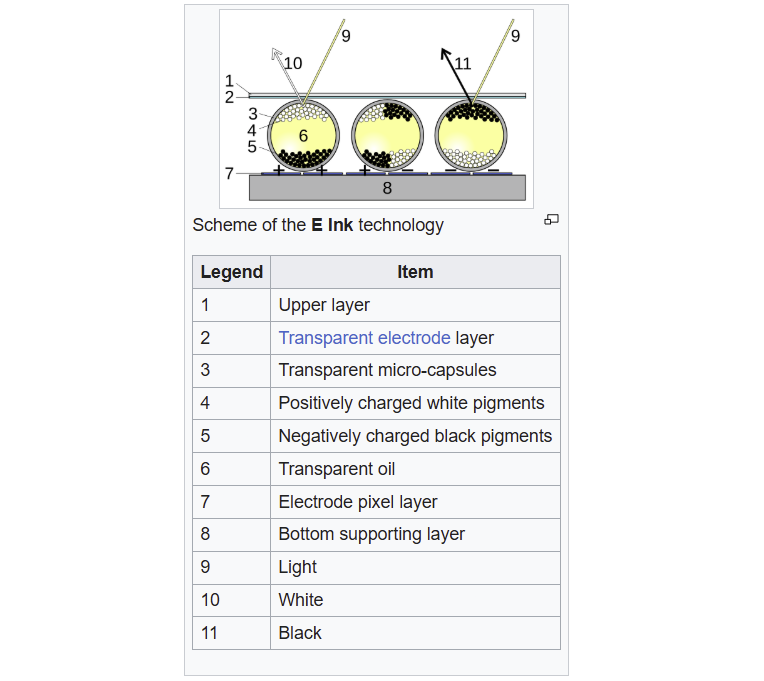
Sur le Kindle, pas d’API graphique car l’écran e-ink expose un framebuffer brut (/dev/fb0) et chaque écriture dedans déplace les microcapsules noires ou blanches chargées électriquement, qui forment les pixels affichés.
Écrire dans /dev/fb0, c’est écrire directement l’image qui s'affiche sur l’écran.
// 600 x 800 pixels = 480000 bytes
int fb = open("/dev/fb0", O_RDWR);
write(fb, pixel_data, 480000);
// Forcer le refresh e-ink
system("echo 1 > /proc/eink_fb/update_display");Ça nous rappelle qu'au final, tout finit par être des bytes écrits quelque part.
Du dithering pour sauver les FPS
Problème ? En mode grayscale (8 bits), l'écran e-ink met 600ms à rafraîchir. Inacceptable pour un jeu.
- Solution 1 : passer en noir & blanc pur (1 bit) → 125ms. C'est mieux, mais l'image devient illisible.
- Solution 2 : le dithering Floyd-Steinberg (pour vous amuser, c’est ici). C'est un algorithme inventé en 1976 qui crée une illusion de niveaux de gris en utilisant uniquement du noir et du blanc. Le principe ? Quand on force un pixel gris à devenir noir ou blanc, on "distribue" l'erreur de couleur aux pixels voisins. Cette erreur accumulée crée des motifs de points qui, vus de loin, simulent les nuances intermédiaires.

Ces deux images illustrent deux méthodes de traitement à gauche, un seuillage simple en 1 bit noir et blanc, à droite, un dithering de type Floyd–Steinberg, qui peut donner l’impression de nuances supplémentaires, alors qu’il ne s’agit en réalité que de noir et blanc répartis différemment.
Résultat ? Une illusion de niveaux de gris avec seulement du noir et blanc, et des FPS acceptables.

Ce que ce projet nous rappelle
Ce qui ressort du talk de Moustapha, c'est cette énergie brute. Personne ne lui a demandé de faire ça. Pas de business case, pas de ROI. Juste un dev qui se dit : "tiens, et si j'essayais ?".
Ce genre de projet nous ramène au concret : comprendre les couches basses, se confronter aux vraies contraintes, bricoler jusqu'à ce que ça marche. Et puis, Moustapha aurait pu garder son hack pour lui. Au lieu de ça, il monte sur scène et partage les galères, le code, ce qu'il a appris.
Porter DOOM sur une liseuse ne changera pas le monde. Mais ça rappelle pourquoi beaucoup d'entre nous ont commencé dans ce métier, la curiosité, le défi technique, cette satisfaction de faire marcher un truc "contre toute attente".
Veille technologique : ma méthode pour rester à jour
Tanoh N’GOYET
Conférence présentée par Camille ROUX, fondateur de Human Coders
Camille débute en expliquant qu'il a commencé sa veille technologique durant ses études, utilisant alors l’outil Google Reader. La veille est devenue son métier aujourd'hui : il a créé un site d'actualités et propose des formations professionnelles à travers son entreprise. La veille est au centre de ses activités car la mission de son entreprise est le partage de connaissances entre développeurs.
Méthodes classiques de veille
Camille a souligné que, lorsqu’on parle de veille technologique avec les développeurs, la majorité utilise principalement les réseaux sociaux (LinkedIn, X, YouTube, etc.) pour se tenir informés des actualités informatiques. Il a reconnu que l'avantage de cette méthode est qu’elle donne accès à des informations non sollicitées, permettant ainsi une veille assez large. Cependant, il a insisté sur l'inconvénient majeur : si on est absent des réseaux sociaux pendant quelques jours, on risque de rater des informations cruciales, surtout pour des sujets où on considère que l'actualité est vitale (par exemple les prochaines versions d'un langage de développement).
Il a ensuite abordé une autre composante de la veille pour les développeurs : les échanges avec d'autres professionnels, par exemple lors de conférences comme le DevFest. C'est une excellente source d'information et cela permet aussi une veille large car nous nous informons parfois sur des sujets auxquels nous n’aurions pas pensé. Mais il a mis en garde sur le fait que nous ne contrôlons ni la véracité de l'information ni le moment où elle arrive.
Améliorer sa veille
Choix de l’outil approprié
Face à ces limites, il nous a présenté une méthode alternative : reprendre le contrôle de sa veille en s'appuyant sur des outils qui permettent de sélectionner précisément ce que l'on veut lire. Ces outils, ce sont les lecteurs de flux RSS. Celui utilisé par Camille est le logiciel Inoreader. Il a toutefois mentionné que d'autres outils tels que Feedly (qui offre à peu près les mêmes fonctionnalités que Inoreader) existent et que le choix dépend des besoins.
Stratégies d’efficacité
Après avoir choisi l'outil, l’étape suivante est de sélectionner les flux RSS. Il conseille de commencer par intégrer des agrégateurs (tels que Journal du Hacker, Hacker News, Lobster, etc.) pour établir une base. Mais il a rapidement alerté sur le risque d'être submergé par la quantité d'informations, ce qui peut mener à l'abandon de l'outil.
Pour un tri efficace, il a partagé plusieurs stratégies :
- Score de popularité : certains outils affichent un score qui montre combien de fois une information a été consultée par les autres utilisateurs, aidant ainsi à identifier les actualités importantes.
- Résumés par IA : il n'est pas toujours nécessaire de lire les articles en entier. On peut demander à l'Intelligence Artificielle de fournir un résumé concis ou sous forme de points clés, directement dans l'outil, pour décider si un article donné mérite qu’on s’y attarde pour une lecture complète.
- Consultation hors ligne : certains outils permettent de télécharger le contenu pour le lire sans connexion.
- Traduction et audio : si la lecture en anglais est pénible, on peut traduire l'article en français, et même écouter la version audio de la traduction.
Il a insisté sur le fait que ces options sont précieuses car elles offrent différentes manières de s'informer ; souvent, un simple résumé suffit pour comprendre l'essentiel sans avoir besoin de tous les détails.
Optimisations
Une fois qu'on maîtrise la gestion d'un flux RSS, on peut en ajouter d'autres. Camille a donné plusieurs recommandations d'usage :
- Classer les flux :
- Par thème : on peut créer des répertoires pour séparer les centres d’intérêt (par exemple un pour la photographie et un autre pour le développement) et choisir quand consulter chaque catégorie.
- Par fréquence : il est important de séparer les flux qui publient un grand volume (tels que Hacker News) de ceux qui publient peu mais dont on veut lire l'intégralité (comme le blog d'un développeur qu'on apprécie et qui publie de temps en temps). Sinon, les articles moins fréquents risquent d'être noyés dans le flot d’actualités.
- Importer d'autres contenus : les lecteurs comme Inoreader ne se limitent pas aux flux RSS. On peut y intégrer :
- Des newsletters via une adresse e-mail dédiée.
- Des sites sans flux RSS.
- Des contenus de YouTube, des réseaux sociaux, et des podcasts.
- Ne pas confondre le lecteur de flux avec un gestionnaire de favoris : il a mis en garde contre l'erreur d'intégrer trop de sources au début. Il faut commencer avec un nombre très limité et ajouter des flux seulement si c'est vraiment nécessaire, quitte à les mettre dans un répertoire séparé pour voir si on les consulte réellement.
- Point de départ : si on ne sait pas par où commencer, les agrégateurs d'actualités sont un excellent début pour découvrir de nouvelles sources à ajouter progressivement.
- Suggestion de ressources : certains lecteurs peuvent suggérer des ressources en analysant les flux que l'on suit.
- Instaurer une routine : la veille demande du temps, il est donc bénéfique d'en faire une habitude professionnelle (par exemple, avec le café matinal ou dans les transports).
- Fonction "Lire plus tard" (read later) : pour les articles exceptionnels qu'on n'a pas le temps de lire tout de suite.
Pour aller plus loin
Camille a terminé en expliquant ce qu'on peut faire au-delà d'une simple consultation d’articles de veille :
- Partager sa veille : le partage est essentiel, que ce soit sur les réseaux, avec son équipe ou des contacts, car le filtre exercé par d’autres lors de leur veille technologique nous est souvent très utile pour éviter d’être noyé par le flot d’actualités.
- Utiliser des tags : les lecteurs de flux permettent souvent de générer des flux RSS en fonction de certains tags.
- Générer un récapitulatif : il a donné l'exemple de la génération automatique d'un article récapitulatif hebdomadaire de sa veille sur son blog personnel, qui devient lui-même une newsletter que d'autres peuvent intégrer à leur propre lecteur de flux RSS.
- Donner de la visibilité aux "pépites" : il a encouragé à partager les articles de qualité qui ont été peu lus, en particulier ceux des auteurs techniques francophones, afin d'accroître leur visibilité en les postant sur des agrégateurs.
La domotique débridée, du sac poubelle au sanglier !
David DALLAGO
Conférence présentée par Sylvain WALLEZ et Erwan ROUGEUX.

“Vous êtes prêts pour la conférence la plus WTF de la journée ?”
Voilà l’ouverture de la dernière conférence de la journée qui, il faut le dire, nous a régalé !Les speakers commencent par un vote à main levée : une bonne partie de la salle est utilisatrice de Home Assistant. Cette application open source à héberger soit même permet de domotiser la maison à travers des intégrations dédiées vers de multiples objets connectés : Philips Hue, modules Shelly, thermostats Airzone et de nombreux autres.
A noter que Home Assistant figure au top 10 des projets github open source par nombre de contributeurs.
Cette application permet donc de s’abstraire des applications propriétaires de ces modules et de centraliser l’ensemble de la télémétrie (ex: consommation électrique, température) ainsi que les automatisations de la maison.
Nous allons crescendo au fil du talk sur l’ensemble des automatisations mises en place par les intervenants :
- Des interrupteurs connectés pour contrôler les lumières
- Une luminosité qui s’adapte au cycle circadien
- Un ballon d’eau chaude bienveillant avec notre portefeuille : l’automatisation va asservir la production d’eau chaude aux tarifs avantageux EDF (en fonction du contrat bien sûr), ou, si possible, à la production solaire d’une installation photovoltaïque en autoconsommation
- Un canapé connecté, afin d’automatiser l’ouverture ou la fermeture du côté relax à une scène “soirée cinéma” par exemple
- ESPHome + carte ESP32 + un multiplicateur RJ9
- Un poulailler connecté (DIY là aussi)
- ESPHome + carte ESP32 + moteur électrique pour une porte s’ouvrant et se fermant au rythme des journées
- Une webcam PTZ dans le poulailler qui notifie la présence ou non de l’ensemble des poules
- Un déclenchement automatique d’un aspirateur robot lors de la sortie de la zone maison
- Une boîte aux lettres connectée
- Et enfin:
- un lave linge connecté pour calculer automatiquement la liste de courses en fonction de la consommations des pods/pastilles/poudres de lavage
- une poubelle connectée pour calculer automatiquement la liste de courses en fonction de la consommation des sacs poubelles
- le plus cocasse, une comparaison de la consommation de papier toilette de plusieurs gammes à l’aide d’une Echo Dot et d’un MCP
- une alarme automatique pour mettre en fuite des sangliers qui endommagent le jardin de Sylvain
- une webcam connectée
- une lumière sirène connectée
- et enfin, l’ouverture sur le robot de jardin connecté se dirigeant vers les sangliers pour les faire fuir
Un talk que j’ai adoré et qui m’a donné des idées d’applications à la maison et dans lequel beaucoup se reconnaîtront : la bidouille, le besoin de comprendre et de faire. Geek et fier de l’être.
Nous terminons avec ce talk une belle journée riche en rencontres et découvertes autour de l’intelligence artificielle notamment (mais pas que) ainsi que bien entendu, l’apéritif networking de rigueur.

Lien des articles du DevFest Toulouse 2024


