

Introduction & Motivation
Cela fait plusieurs semaines que j’ai booké une session “lab / discovery” sur le sujet des RAG mais abordé par le prisme d’une technologie particulière : Neo4J.
Neo4J, c’est le leader de la base graphe. C'est un outil particulièrement adapté aux nouveaux enjeux technologiques dans lesquels on manipule des données pas forcément structurées. Ayant déjà utilisé Neo4J plusieurs années auparavant, je me souvenais d’un outil abouti et vraiment performant. Et c’est donc tout naturellement que j’ai voulu participer à ce Lab pour voir où se situait Neo4J dans la galaxie des outils qui gravitent dans l'écosystème LLM / IA.
En voici une synthèse.
Présentation & Déploiement moteur Neo4J
Après la classique présentation de la société Neo4J, du principe des bases graphes, et pourquoi c’est bien de l’utiliser, on nous présente “Neo4j Aura Professionnal” qui est la solution SaaS de Neo4J et qui se décline en plusieurs briques :
- Neo4J Aura DB qui est le moteur de la base graphe
- Neo4j Aura Graph Analytics
Evidemment, Neo4j Aura Professionnal est indépendant du cloudProvider : on va donc pouvoir l’installer sur les grands fournisseurs de cloud, et ce, en quelques clics. Mais il est également possible de faire du self managed.
Le Lab (et tout ce qui est nécessaire) est accessible depuis le github de Neo4J :
https://github.com/neo4j-partners/hands-on-lab-neo4j-and-bedrock/tree/main
La formation se déroulant dans les locaux d’AWS, il était normal que le choix du cloudProvider soit AWS. Les premières étapes consistent à déployer sur un compte AWS de “bac à sable” une instance du moteur neo4j. Comme c’est une solution SaaS, complètement intégrée dans l’AWS Marketplace, cela se fait très facilement :
Notez qu’il faudra sélectionner à minima “Neo4J AuraDB Professionnal (pay as you go)” pour bénéficier des fonctionnalités IA.
Notez également que le système de Licensing Neo4J n’autorise pas à déployer en production la version communautaire, qui est de toute façon bridée.
Pour vos productions, il faudra sélectionner “Neo4J Enterprise Edition”.
Une fois déployée, nous nous connectons sur l’interface via la console d’administration :
Puis nous enchaînons sur une étape de création de la base graphe à l’intérieur de notre instance. Et enfin, nous la remplissons.
L’ensemble de ces étapes sont très bien décrites dans le repo github.
L’IA rentre en jeu
Un SA AWS nous présente le service AWS BedRock et les différents modèles qu’il supporte.
Ce n’est pas l’objet de ce billet mais voici quelques notes :
Amazon BedRock est une surcouche au-dessus des modèles que vous aurez sélectionnés. Je citerai juste ce que le SA AWS nous a conseillé : “Dans votre phase exploratoire, n’hésitez pas à tester les différents modèles : entre pertinence et coûts associés, trouvez le modèle qui correspond le plus à vos besoins.”
Ici, nous utilisons Anthropic et le modèle claude-sonnet-4-20250514-v1 comme LLM.
Pour terminer notre environnement, nous déployons, côté AWS, un domaine “SageMaker” pour dérouler les notebooks Jupyter fournis dans le repository git.
Le 1er notebook Jupyter : chargement des données
Voici les grandes lignes du notebook :
Objectif : Utiliser le LLM claude sonnet pour parser automatiquement des données semi-structurées (mélange de texte et XML) issues d’un fichier initial.
Le notebook permet de montrer comment générer des requêtes Cypher (langage natif neo4j pour interagir avec la base graphe) pour charger les données extraites dans notre base neo4J. Notez qu’à aucun moment on écrit un parser spécifique : c’est le LLM qui se charge de tout.
Le notebook utilise des prompts spécifiques pour guider le LLM dans l’extraction des informations. Dans notre cas particulier, nous manipulons des “managers” et des informations sur des “investments”. Voici les prompts (que vous pouvez retrouver directement dans le notebook).
Prompt pour guider le LLM pour extraire les informations “manager”
mgr_info_tpl = """From the text below, extract the following as json. Do not miss any of these information.
* The tags mentioned below may or may not namespaced. So extract accordingly. Eg: <ns1:tag> is equal to <tag>
* "managerName" - The name from the <name> tag under <filingManager> tag
* "street1" - The manager's street1 address from the <com:street1> tag under <address> tag
* "street2" - The manager's street2 address from the <com:street2> tag under <address> tag
* "city" - The manager's city address from the <com:city> tag under <address> tag
* "stateOrCounty" - The manager's stateOrCounty address from the <com:stateOrCountry> tag under <address> tag
* "zipCode" - The manager's zipCode from the <com:zipCode> tag under <address> tag
* "reportCalendarOrQuarter" - The reportCalendarOrQuarter from the <reportCalendarOrQuarter> tag under <address> tag
* Just return me the JSON enclosed by 3 backticks. No other text in the response
Text:
$ctext
"""
Prompt pour guider le LLM pour récupérer les infos “investments”
filing_info_tpl = """The text below contains a list of investments. Each instance of <infoTable> tag represents a unique investment.
For each investment, please extract the below variables into json then combine into a list enclosed by 3 backticks. Please use the quoted names below while doing this
* "cusip" - The cusip from the <cusip> tag under <infoTable> tag
* "companyName" - The name under the <nameOfIssuer> tag.
* "value" - The value from the <value> tag under <infoTable> tag. Return as a number.
* "shares" - The sshPrnamt from the <sshPrnamt> tag under <infoTable> tag. Return as a number.
* "sshPrnamtType" - The sshPrnamtType from the <sshPrnamtType> tag under <infoTable> tag
* "investmentDiscretion" - The investmentDiscretion from the <investmentDiscretion> tag under <infoTable> tag
* "votingSole" - The votingSole from the <votingSole> tag under <infoTable> tag
* "votingShared" - The votingShared from the <votingShared> tag under <infoTable> tag
* "votingNone" - The votingNone from the <votingNone> tag under <infoTable> tag
Output format:
* DO NOT output XML tags in the response. The output should be a valid JSON list enclosed by 3 backticks
Text:
$ctext
"""
La variable $ctext sera remplacée par chaque ligne récupérée du fichier initial.
Le notebook fournit des fonctions spécifiques permettant d’interagir avec le LLM, comme par exemple le moyen de découper (chunk) les données pour éviter de dépasser les limites de tokens du LLM.
Le LLM est utilisé pour générer des requêtes Cypher à partir des données extraites, afin de les charger dans Neo4j.
Conclusion
Même si ce n’est pas une révolution, on sent bien toute la puissance du LLM : à partir d’un fichier non structuré (le fichier de départ contient des données XML et des données en vrac), le LLM arrive à ne pas se perdre et à extraire les 2 listes d’informations relatives à des entités métier : le manager et le “investment”.
Mise en place d’une “fenêtre conversationnelle”
La session continue sur le lab 6 “ChatBot”. Il se base sur la librairie python “gradio” pour mettre en place cette fenêtre conversationnelle.
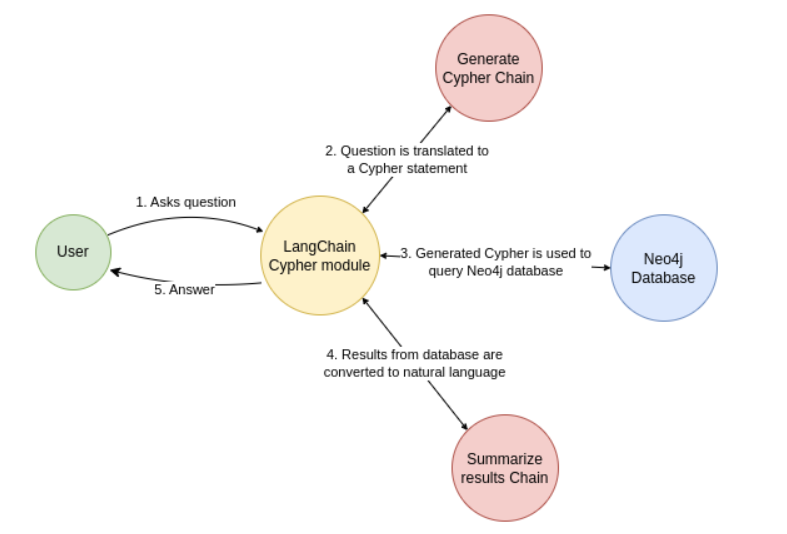
Le fonctionnement qui est proposé par ce nouveau notebook est le suivant :
- L’utilisateur pose une question en langage naturel.
- L’IA générative convertit cette question en requête Cypher (langage de requête pour Neo4j).
- La requête Cypher interroge la base Neo4j pour obtenir des faits contextuels.
- L’IA générative convertit la réponse de la base en langage naturel.
- La réponse est présentée à l’utilisateur.
Dans ce notebook, on nous présente l’avantage de l’utilisation de Neo4J. Sans précision particulière, une question du style : “Which managers own FAANG stocks?” ne permet pas d’avoir une réponse pertinente.
En effet, un modèle de langage (comme ceux utilisés dans les chatbots) peut reconnaître des termes courants comme FAANG (Facebook, Apple, Amazon, Netflix, Google ), mais il ne donnera que des réponses générales et limitées.
Or, dans un environnement professionnel, les questions portent souvent sur des données spécifiques : des noms de projets, des relations entre entités, ou des règles internes. Un LLM seul ne connaît pas ces détails. Neo4j résout ce problème en stockant ces informations dans un graphe de connaissances, où chaque élément est relié de manière structurée.
Grâce à LangChain, on peut alors :
- Traduire la question en une requête précise (en langage Cypher pour Neo4j).
- Interroger la base pour obtenir des réponses exactes et contextualisées.
- Restituer le résultat en langage naturel, comme le ferait un expert du domaine.
C’est cette combinaison — LLM + Neo4j — qui permet de passer d’une réponse vague à quelquechose de beaucoup plus pertinent pour notre contexte.
Voici le schéma présenté dans le notebook :
Pour permettre au LLM de traduire la question de l’utilisateur en “Cypher Chain”, encore une fois, nous allons fournir un “prompt” qui va le guider. Il est disponible dans le notebook et est plutôt assez gros. Ci-joint un extrait de ce prompt :
CYPHER_GENERATION_TEMPLATE = """You are an expert Neo4j Cypher translator who understands the question in english and convert to Cypher strictly based on the Neo4j Schema provided and following the instructions below:
<instructions>
* Use aliases to refer the node or relationship in the generated Cypher query
* Generate Cypher query compatible ONLY for Neo4j Version 5
* Do not use EXISTS, SIZE keywords in the cypher. Use alias when using the WITH keyword
* Use only Nodes and relationships mentioned in the schema
* Always enclose the Cypher output inside 3 backticks (```)
* Always do a case-insensitive and fuzzy search for any properties related search. Eg: to search for a Company name use `toLower(c.name) contains 'neo4j'`
* Use the relationship variable `o` to access the `shares` and `value` properties of the `OWNS` relationship when calculating the sums.
* Cypher is NOT SQL. So, do not mix and match the syntaxes
* Use the elementId() function instead of id() to compare node identifiers
</instructions>
Strictly use this Schema for Cypher generation:
<schema>
{schema}
</schema>
The samples below follow the instructions and the schema mentioned above. So, please follow the same when you generate the cypher:
<samples>
Human: Which fund manager owns most shares? What is the total portfolio value?
Assistant: ```MATCH (m:Manager) -[o:OWNS]-> (c:Company) RETURN m.managerName as manager, sum(distinct o.shares) as ownedShares, sum(o.value) as portfolioValue ORDER BY ownedShares DESC LIMIT 10```
Human: Which fund manager owns most companies? How many shares?
Assistant: ```MATCH (m:Manager) -[o:OWNS]-> (c:Company) RETURN m.managerName as manager, count(distinct c) as ownedCompanies, sum(distinct o.shares) as ownedShares ORDER BY ownedCompanies DESC LIMIT 10```
Human: What are the top 10 investments for Vanguard?
Assistant: ```MATCH (m:Manager) -[o:OWNS]-> (c:Company) WHERE toLower(m.managerName) contains "vanguard" RETURN c.companyName as Investment, sum(DISTINCT o.shares) as totalShares, sum(DISTINCT o.value) as investmentValue order by investmentValue desc limit 10```
Human: What other fund managers are investing in same companies as Vanguard?
Assistant: ```MATCH (m1:Manager) -[o1:OWNS]-> (c1:Company) <-[o2:OWNS]- (m2:Manager) WHERE toLower(m1.managerName) contains "vanguard" AND elementId(m1) <> elementId(m2) RETURN m2.managerName as manager, sum(DISTINCT o2.shares) as investedShares, sum(DISTINCT o2.value) as investmentValue ORDER BY investmentValue LIMIT 10```
Human: What are the top 10 investments for rempart?
Assistant: ```MATCH (m:Manager) -[o:OWNS]-> (c:Company) WHERE toLower(m.managerName) contains "rempart" RETURN c.companyName as Investment, sum(DISTINCT o.shares) as totalShares, sum(DISTINCT o.value) as investmentValue order by investmentValue desc limit 10```
...
Human: {question}
Assistant:
"""
Maintenant qu’on a guidé notre LLM avec suffisamment de contexte dans notre prompt, il nous reste plus qu’à exploiter la puissance de Neo4J avec notre LLM.
Le notebook montre comment utiliser LangChain pour "ancrer" le LLM avec Neo4j, c’est-à-dire :
- Lier le LLM à la structure du graphe (schéma, relations, propriétés).
- Générer des requêtes Cypher précises à partir des questions utilisateurs.
- Exécuter ces requêtes sur Neo4j et restituer les résultats.
LangChain agit comme un pont entre le LLM (générique) et Neo4j (spécifique).
Il permet de structurer les interactions pour obtenir des réponses précises et contextualisées.
L’utilisation de GraphCypherQAChain automatise la conversion question → Cypher → réponse, pil poil ce dont on a besoin pour un “chatbot métier”.
Si maintenant on repose notre question “Which managers own FAANG stocks?”, la réponse devient complètement pertinente.
Conclusion [point de vue neo4j]
Pourquoi "Ancrer" un LLM avec Neo4j ?
"Ancrer" un LLM (Large Language Model) avec Neo4j signifie connecter le modèle à une base de données de graphes pour améliorer ses réponses. Voici 3 raisons :
Gestion de Questions Complexes (Multi-Hop Knowledge Retrieval)
Les questions complexes nécessitent souvent de relier plusieurs informations entre elles (ex : "Quels gestionnaires de fonds basés à New York détiennent des actions dans des entreprises technologiques cotées après 2020, et qui ont un rendement supérieur à 10% ?").
Dans une base de données relationnelle classique, cela implique des jointures multiples, qui peuvent être lentes et difficiles à optimiser.
Solution avec Neo4j :
Neo4j stocke les relations entre les données (ex : Gestionnaire → DÉTIENT → Action → COTÉE_DANS → Secteur). Ces relations sont pré-calculées et optimisées avant même que la question ne soit posée.
Pour une question nécessitant 4 "sauts" (hops) (ex : Gestionnaire → Action → Entreprise → Secteur), Neo4j traverse ces relations instantanément, sans calculs lourds.
Résultat : Nous obtenons des réponses rapides et précises, même pour des questions complexes.
Fiabilité et Sécurité d’Entreprise
Neo4j permet de limiter l’accès aux données en fonction des permissions de l’utilisateur (ex : un chatbot ne verra que les données autorisées pour le rôle de l’utilisateur). C’est une fonctionnalité qui n’est pas accessible dans la version communautaire.
Performance
Neo4j est optimisé pour les requêtes complexes sur des graphes, avec une latence faible même avec un grand nombre d’utilisateurs simultanés. C’est idéal pour des applications comme un chatbot utilisé par des centaines d’utilisateurs en parallèle.
Ma Conclusion
À première vue, l’impact est indéniable : sans l’appui d’un LLM, l’extraction de données à partir de fichiers non structurés aurait été un défi de taille. L’envie d’ajouter une couche conversationnelle pour interroger ces données devient rapidement évidente. Le Lab, centré sur les atouts d’une base graphe comme Neo4j, met en lumière ces avantages. Une fois les données chargées dans Neo4j, la précision des réponses de l’agent s’en trouve décuplée.
Un aspect important qui n’est pas montré dans le Lab, est que Neo4j a intégré dès sa conception une approche pragmatique de la sécurité, notamment à travers la gestion de la visibilité des données. Par exemple, il est possible d’attribuer des niveaux de confidentialité (comme une échelle de C1 à C4, où C4 représente le niveau le plus restreint). Ainsi, selon les droits de l’utilisateur, la base graphe filtre automatiquement les informations accessibles : un profil autorisé uniquement pour le niveau C2 ignorera les nœuds classés C3 ou C4. Une fonctionnalité qui renforce la sécurité tout en restant transparente pour l’utilisateur.
Si les LLM sont impressionnants, ils ne remplacent pas l’expérience humaine. Leur efficacité dépend largement de la qualité des prompts qui les guident. Dans le cadre du Lab, ces prompts ont été soigneusement testés pour garantir des résultats pertinents. Cependant, en dehors de ce contexte, leur élaboration reste un exercice exploratoire, profondément lié au projet en cours, aux données et aux usecases. Impossible, donc, d’établir un guide universel pour rédiger des prompts efficaces.
Cette réalité rappelle les protocoles de recherche en laboratoire : en IT, comme en science, il est impératif de tester, d'ajuster et d'itérer, à la manière des laboratoires pharmaceutiques, jusqu'à obtenir la pertinence et l'efficacité souhaitées.
Durant cette semaine, j'ai pu rencontrer bon nombre de collègues et amis, jeunes étudiants et professionnels expérimentés, avec qui j'ai eu le plaisir d'échanger sur l'avenir de nos métiers dans l'IT, la place de l’IA qu’elle va prendre, et comment la “dompter”. Le temps que la frénésie autour de l’IA se stabilise, gageons que maîtriser le “prompt” soit le défi de demain, toute génération confondue.
Pour ceux qui sont dans le Sud de la France et qui souhaitent découvrir l'autre révolution en cours dans l'IA (i.e les MCP Servers), Venez nous rencontrer au meetup IA "Piloter votre infra AWS en langage naturel avec LangFuse le 23 Octobre pour une démonstration technique des capacités des MCP Servers.
