
Mise en place d'une stack entière de gestion des patchs sur votre infrastructure.
Partie 2/2 - Surveillance
Nous avons vu dans un premier temps comment mettre en place la gestion de mise à jour sur notre infrastructure. Nous allons voir maintenant comment surveiller que le patching se déroule bien et que les reboots nécessaires soient effectués.
Notification Intégrée
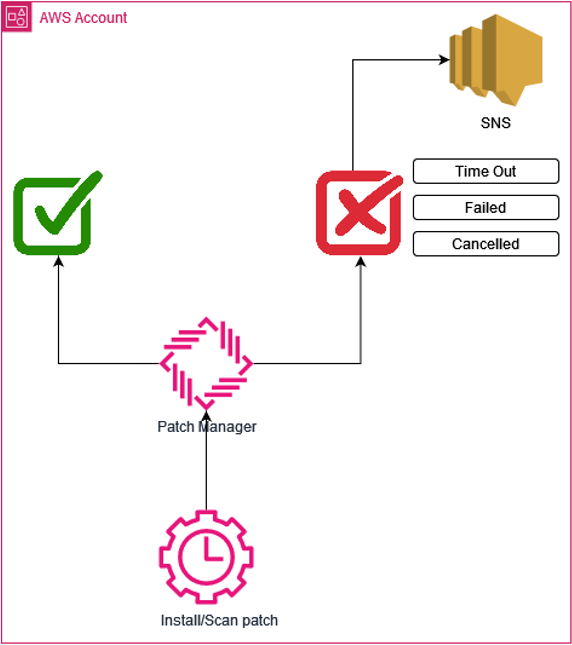
Dans notre Maintenance Windows et notre task "AWS-Run-PatchBaseline", nous avons la possibilité d'activer les notifications en fonction des évènements qui se produisent.
- Success : La tâche s'est réalisée avec brio.
- InProgress : La tâche est en cours.
- Failed : La tâche ne s'est pas bien déroulée.
- Timeout : Le tâche n'est pas allée jusqu'au bout et a atteint son temps d'exécution.
- Cancelled : La tâche a été interrompue de manière intentionnelle.
En fonction des events sélectionnés, lorsqu'ils se produiront, la tâche fera appel au service AWS Simple Notification Service (SNS) vers un topic configuré au préalable.
Notification Personnalisée
Dans le cadre où l'auto reboot n'est pas par défaut, il faut que nous soyons notifiés des instances en attente de redémarrage.
Exemple
Nous rajoutons une “task lambda” dans notre Maintenance Windows.
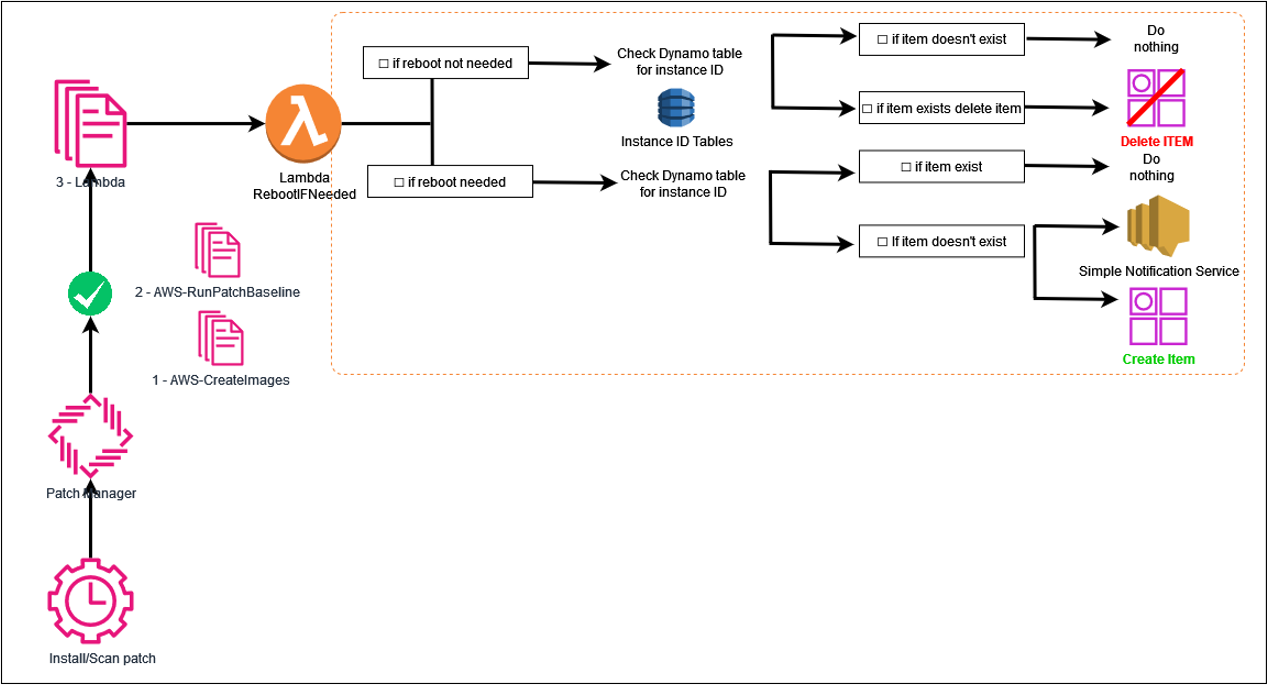
Cette lambda récupère l'instance id dans l'event et vérifie son statut via l'API de SSM.
Après que les deux premières Tasks se soient effectuées, vient l’étape où l’on fait appel à une lambda dans lequel on envoie des métadonnées. Dans ces métadonnées on récupère l’instance id, sur lequel on pourra faire des actions de vérification de statut. Ainsi, si l’instance est en attente de reboot, une notification sera envoyée et l’instance sera inscrite dans un “item” de dynamoDB. Ceci nous permettra de ne pas envoyer de notification tous les jours à l’équipe responsable du reboot de cette même instance si son statut ne change pas.
Supervision
Ou “Comment faire en sorte que les équipes jouent le jeu.”
Maintenant que tout est mis en place, il faut s'assurer que les équipes ajoutent les tags sur leurs instances. Dans un environnement automatisé, les tags doivent être ajoutés dans le code de déploiement de la stack (avec terraform par exemple), or vous n'avez pas forcément accès à tous les projets. Pour cela nous pouvons utiliser le service AWS Config et son option de remédiation.
AWS Config peut être personnalisé par une lambda. Cette lambda peut faire une vérification des tags et donner un statut de conformité aux instances avec une description. Config permet ensuite d'appliquer une remédiation (automatique ou manuelle). Cette remédiation est aussi personnalisée par une seconde lambda dans laquelle on va pouvoir, en plus d'ajouter des tags, interagir avec un outil de ticketing afin de faire une demande aux équipes concernées de mettre le tag dans le code.
AWS Config possède déjà une règle permettant de vérifier les tags, mais celle-ci est incomplète comme nous allons l’expliquer dans les cas suivants.
Dans notre “Compliance Lambda“ nous allons évaluer plusieurs cas de conformité et de non conformité (liste non exhaustive).
Non conforme :
- Absence de l’agent SSM : Avec ou sans tag, si l’agent n’existe pas, aucune mise à jour ne sera faite.
- Le tag avec la clé “Patch Group” n’existe pas
- La clé Patch Group existe mais n’a pas de valeur
- La valeur est bien là mais n’est pas correct (se réfère à une liste récupérée dynamiquement)
Non applicable :
- Instance supprimée : quand l’instance est “Terminated” elle remonte quand même sur AWS Config et ne doit pas faire partie de la vérification de conformité.
Conforme :
- Le tag existe et contient les bonnes références.
A chacun des cas, une description peut être donnée au rapport de conformité, ce qui facilite le suivi et l’établissement des actions à entreprendre afin de rendre l’instance conforme.
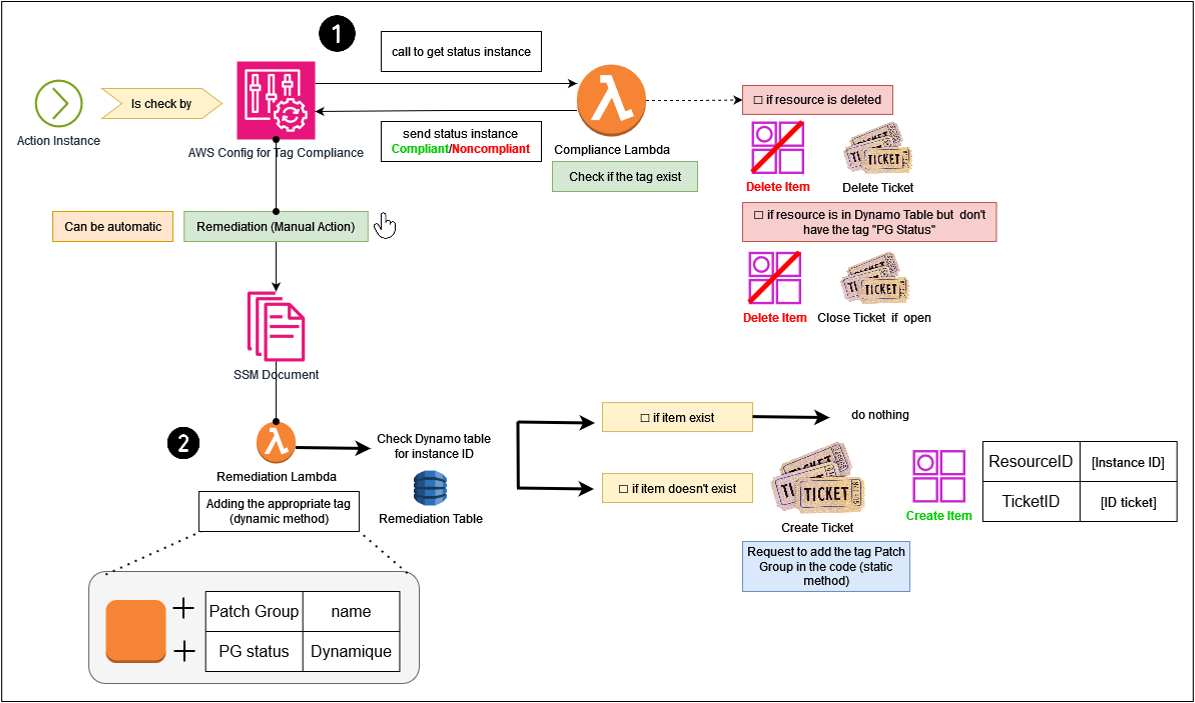
AWS Config va capturer n’importe quel événement sur les instances (configurable pour ne pointer que quelques actions) et ensuite lancer la lambda sur ces instances une par une. La lambda vérifie l'existence du tag et donne le statut de conformité en fonction.
La remédiation peut se faire manuellement dans un premier temps pour ne pas brusquer les équipes avec des mises à jour qui se feraient automatiquement sur leur instance (donc il sera nécessaire de remédier au cas par cas).
Une fois le processus bien rodé et l’équipe habituée au processus de patching, il sera possible de le mettre en automatique.
Puisque l’on ne peut pas savoir si le tag “Patch Group” a été mis manuellement ou par le code, la lambda peut aussi créer un nouveau tag indiquant que le tag “Patch Group” a été ajouté automatiquement par la remédiation. Ainsi, la “compliance lambda” pourra faire une vérification de ce tag pour effacer ou non l'instance de la DynamoDB (si le tag est ajouté par l’équipe as code, le tag “PG Status” sera forcément effacé car il est unique à la lambda).
Et voilà ! C’est ainsi que se termine notre voyage dans la gestion des mises à jour sur notre infrastructure.
