

Airbyte est un outil open source qui permet de réaliser de l’ingestion de données sans avoir à implémenter les processus d’extraction et de chargement des données. En effet, il simplifie le processus pour l’utilisateur en lui faisant seulement configurer des sources (API, base de données, etc), des destinations (Data Warehouse, Data Lake, etc) et une connexion entre celles-ci. Si vous souhaitez découvrir l’outil plus en profondeur, je vous conseille l’article d’Amin Bazaz : Ingestion de données dans ma plateforme : Airbyte répond présent !
La configuration des sources et destinations se fait via des formulaires sur l’interface de l’outil et est possible grâce à ce qu’Airbyte nomme des connecteurs. En effet, chaque source ainsi que chaque destination possède un connecteur associé. Airbyte propose actuellement plus de 300 connecteurs et permet également de créer son propre connecteur custom s’il n’est pas déjà existant ; ce à quoi nous allons nous intéresser dans cet article.
Pré-requis
Installer Docker
L’installation de Docker se fait via le site officiel en téléchargeant le logiciel d’installation : Installer Docker
Si ce n’est pas déjà fait, il faut créer le groupe docker et y ajouter un user, sans quoi vous ne pourrez pas lancer Airbyte (hors sudo). Ceci se fait avec les commandes suivantes :
sudo groupadd docker
sudo usermod -aG docker ${USER}
Afin que ces changements prennent effet, il faudra stopper votre terminal puis en relancer un autre.
Installer Airbyte
Pour installer Airbyte en local, il vous suffit de cloner le repo Github d’Airbyte, créer votre branche de dev et lancer le script run-ab-platform.sh (uniquement lors de l’installation) :
git clone https://github.com/airbytehq/airbyte.git
git switch -c <nom_de_votre_branche>
cd airbyte
./run-ab-platform.sh
Par la suite, il vous suffira de lancer les images d’Airbyte à l’aide d’un simple docker compose up (docker compose down pour les stopper).
L’interface utilisateur d’Airbyte sera alors accessible sur localhost:8000/. Par défaut, l’username est airbyte et le mot de passe est password mais ces paramètres peuvent être changés depuis le repo cloné.
Créer son connecteur
Avant d’entrer dans le vif du sujet, il faut savoir qu’Airbyte permet de créer son connecteur de différentes manières : avec différents langages de programmation, comme Python ou Java mais également en faisant du low-code. Dans cet article, nous créerons un connecteur en Python et avec comme source l’API HTTP de Semana.
Utilisé chez Ippon, Semana est un outil destiné à simplifier le travail hybride et qui permet de déclarer sa semaine au bureau et en télétravail, ainsi que de réserver sa place ou une salle de réunion. Les données proposées par son API et que nous devons ingérer à l’aide de notre connecteur sont donc les données relatives aux collaborateurs, aux différentes agences d’Ippon et enfin aux réservations (ci-après appelées “Bookings") réalisées via le logiciel.
Maintenant que cette mise en contexte a été faite, nous pouvons démarrer l’implémentation de notre connecteur custom.
Pour commencer, depuis la racine du repo Airbyte, il faut passer dans le dossier dédié à la génération de connecteurs puis lancer le script qui génère un template, en ayant autorisé son exécution au préalable :
cd airbyte-integrations/connector-templates/generator/
chmod u+x generate.sh
./generate.sh
Le script propose plusieurs templates. Nous sélectionnons celui indiquant :
Python HTTP API Source
Le script demande ensuite d’entrer un nom pour le connecteur, nous l’appellerons semana. Une fois ces deux étapes terminées, un dossier source-semana est censé être généré dans le dossier qui contient tous les connecteurs.
Ainsi, nous passons dans ce dossier et installons les dépendances nécessaires dans un environnement que nous activons par la suite :
cd ../../connectors/source-semana
python -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
En ouvrant l’éditeur de code dans ce dossier, nous pouvons observer l’arborescence suivante :
Afin de rester concis, nous allons maintenant nous attarder seulement sur les éléments permettant de créer un connecteur fonctionnel et nous ne traiterons pas la partie qui porte sur la PR et les tests d’intégrations à utiliser/modifier pour soumettre son connecteur à Airbyte.
Pour démarrer, nous allons brièvement voir les quatre concepts clés que vous aurez à implémenter (75% du code étant déjà implémenté par Airbyte) pour la création d’un connecteur pour une source :
- Spec : cette première action permet de décrire les informations requises par le connecteur. Par exemple, pour Semana, nous aurons obligatoirement besoin d’une clé API mais également la possibilité d’ajouter des paramètres comme les dates des données que l’on souhaite ingérer ou bien encore un id de collaborateur en particulier.
- Check : cette deuxième action permet de vérifier que le connecteur est capable de se connecter à la source et d’accéder aux données que l’on souhaite ingérer.
- Discover : cette troisième action permet de découvrir et décrire la structure des données à ingérer.
- Read : cette ultime action permet quant à elle d’extraire les données.
Regardons maintenant comment mettre en place chacune de ces actions.
Spec
Afin d’implémenter Spec, il faut remplir les informations sur les paramètres de la source dans le fichier spec.yml. Dans notre cas, ces informations se trouvent dans la documentation de l’API Semana. De plus, étant surtout intéressés par les bookings, nous n’utiliserons que les paramètres prévus pour cette sous-partie des données, à savoir : from, to et collaborator_id. Enfin, l’API Semana possède également un notion de documentation qui précise qu’il faut obligatoirement une clé API pour y accéder, ce qui sera donc notre 4ème et ultime paramètre.
Voici donc à quoi doit ressembler le fichier de spec :
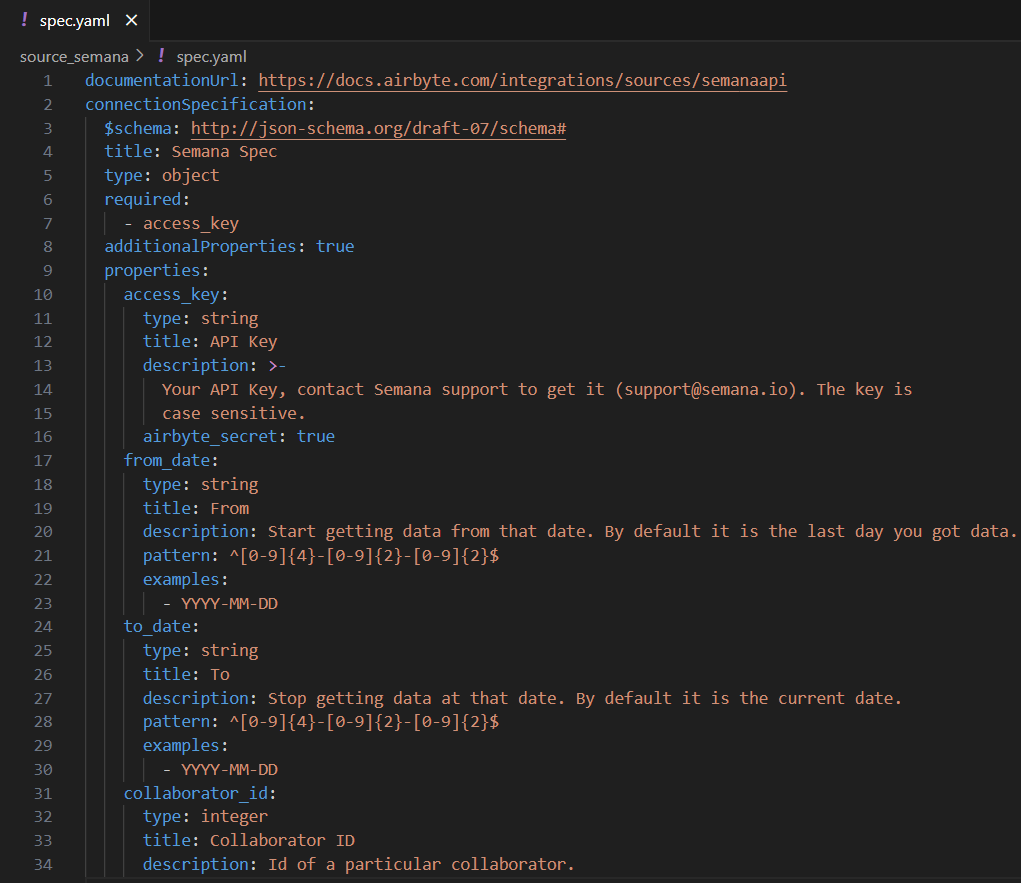
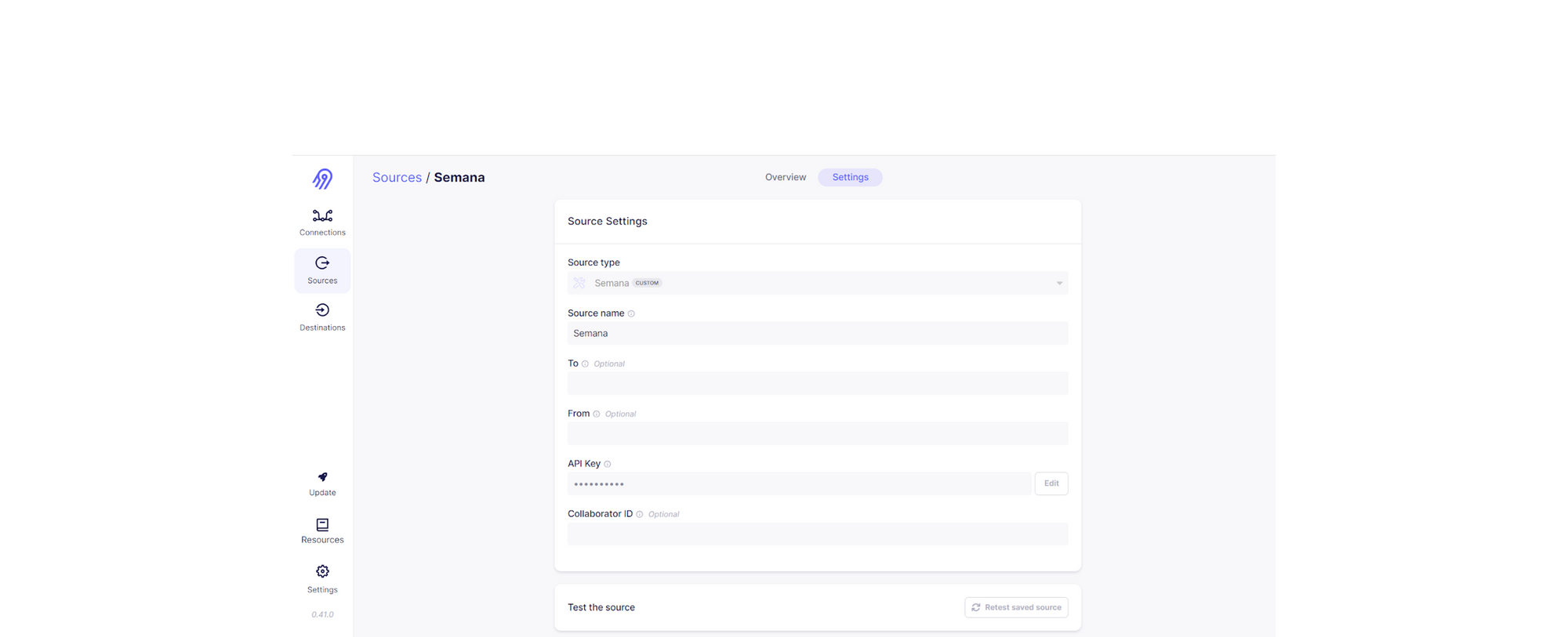
Ce qui donne, pour notre connecteur custom, l’interface donnée sur la figure 3 :
De plus, il est possible de tester le bon fonctionnement avec la ligne de commande :
python main.py spec
Check
Passons maintenant à la seconde action : check. Lors de la génération du dossier semana-source, un fichier source.py est créé et contient déjà quelques classes que nous devons compléter afin de développer notre connecteur. La classe principale se nomme SourceSemana et possède 2 méthodes : streams() et check_connection(), qui permettent respectivement de créer les différents streams (qui sont des subsets de données de la source, ici : Collaborators, Communities et Bookings) et tester la connexion avec la source. La méthode check_connection() n’est pas implémentée lors de la génération du dossier et c’est à nous de le faire comme sur la figure suivante :
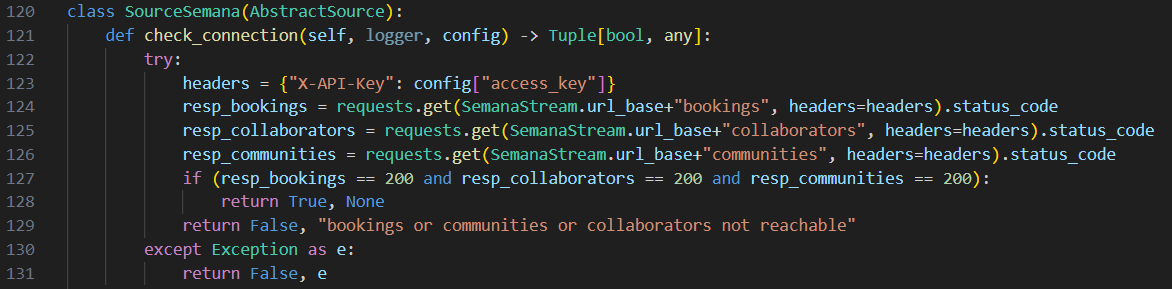
Ainsi, cette méthode récupère les paramètres fournis par l’utilisateur grâce à la variable config qui est créée via la spec définie plus tôt, puis tente de requêter chacun des streams afin de voir s’ils sont accessibles et de retourner une erreur dans le cas contraire.
Il est ainsi possible de tester la connexion avec la source en exécutant la ligne de commande suivante :
python main.py check --config secrets/config.json
Le fichier config.json est censé contenir les paramètres définis comme “obligatoires” en spec, ici la clé API.
Discover
Ayant maintenant réalisé la configuration et le test de connexion, nous pouvons passer à la 3ème étape : discover. Pour ce faire, nous allons d’abord rentrer plus en détail dans le fichier source.py en nous intéressant aux différentes classes qu’il contient ainsi qu’à leurs fonctions pour le connecteur. Lors de sa génération, ce fichier crée plusieurs classes non implémentées qui sont :
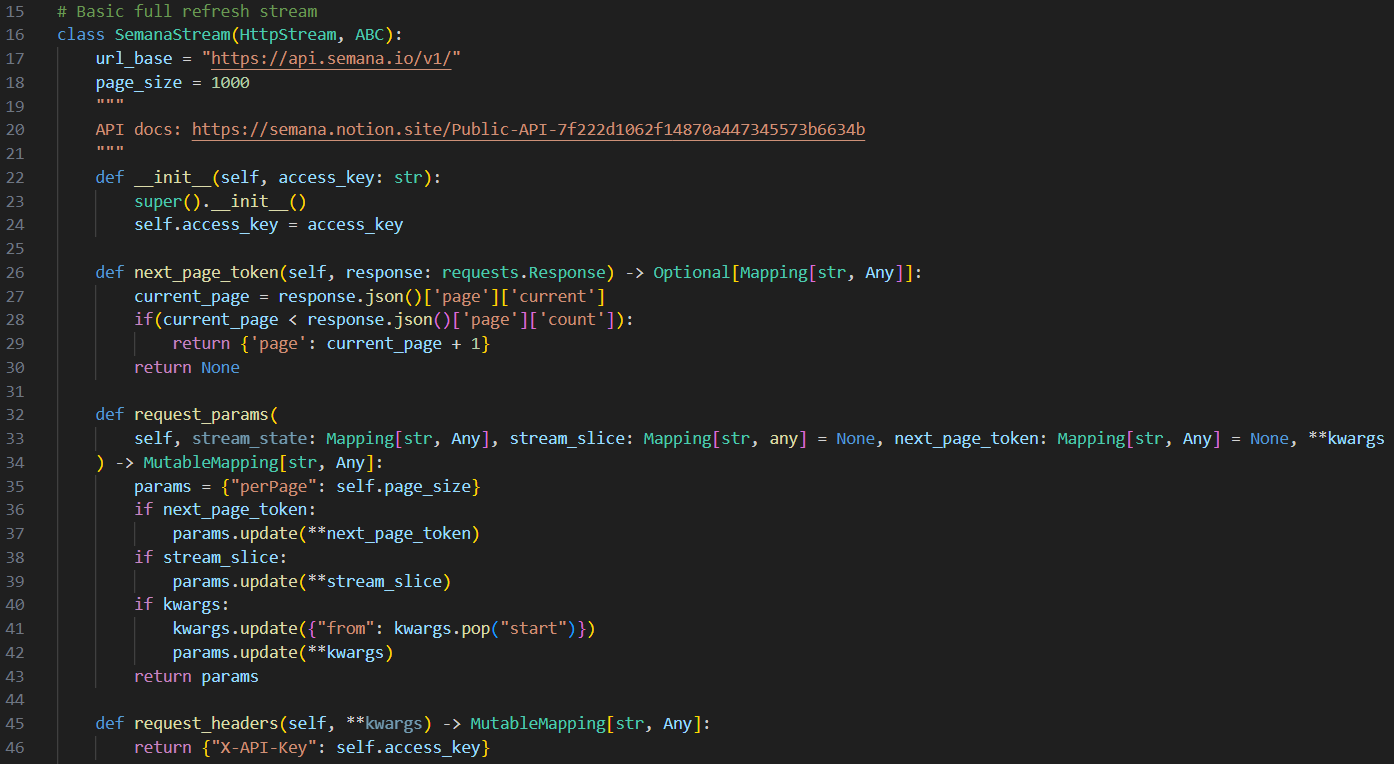
- SemanaStream, qui est une classe abstraite destinée à implémenter toutes les méthodes basiques concernant l’API (exemples en figure 5). Cette classe permet de réaliser exclusivement du full-refresh (ingestion de l’entièreté des données à chaque ingestion), ainsi, tous les streams que nous allons créer et qui n’auront besoin que d’ingestion full-refresh hériteront de cette classe.
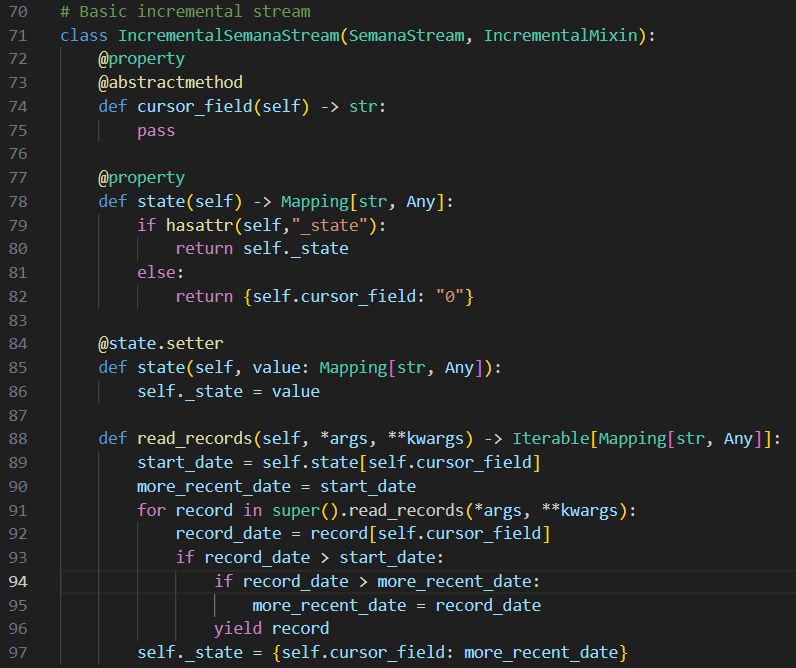
- IncrementalSemanaStream, qui est la classe fille de SemanaStream, dans laquelle nous implémentons la fonctionnalité d’ingestion incrémentale (ingestion seulement des données nouvellement arrivées depuis la dernière ingestion de la source). Le principe, comme visible sur la figure 6, est de définir (et actualiser à chaque ingestion) un champ dans la source servant de repère en termes de fraîcheur des données, puis de comparer ce champ entre les données pour ingérer seulement les “nouvelles” données. Les streams destinés à réaliser de l’ingestion incrémentale, en plus de full-refresh, hériteront de cette classe.
- SourceSemana, qui est la classe qui permet de tester la connexion à la source, comme vu précédemment, mais également de créer les streams en leur passant en argument les paramètres de spec renseignés par l’utilisateur.
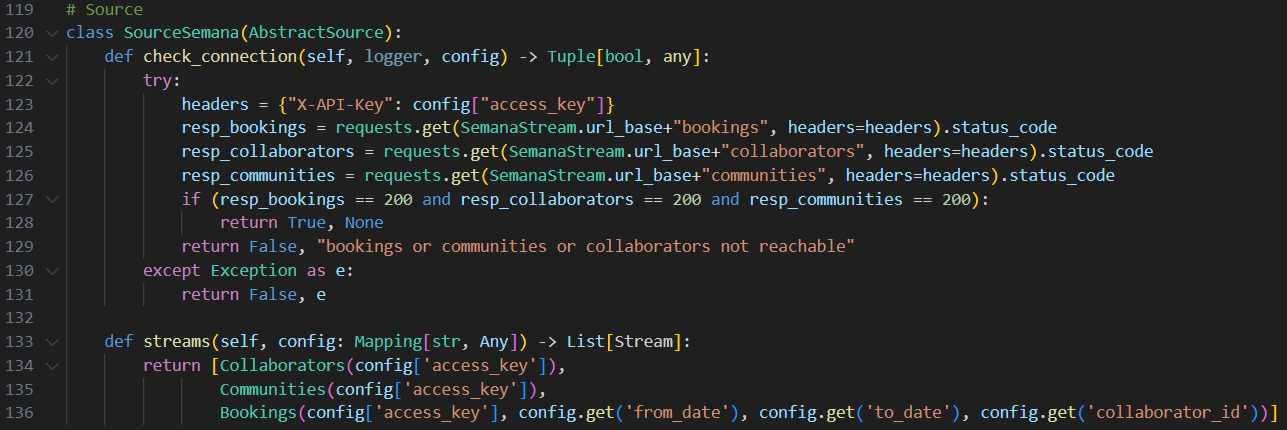
Comme visible sur la figure précédente, nous avons également créé une classe par stream : Collaborators et Communities, qui ont hérité de SemanaStream et Bookings, qui a hérité de IncrementalSemanaStream. Afin de réaliser l’étape discover, nous devons également créer un fichier de schéma JSON par stream, qui permet de déclarer le format des données sorties par celui-ci. A l’aide de la documentation de l’API, nous pouvons facilement créer les fichiers de schéma comme celui donné en exemple sur la figure suivante :
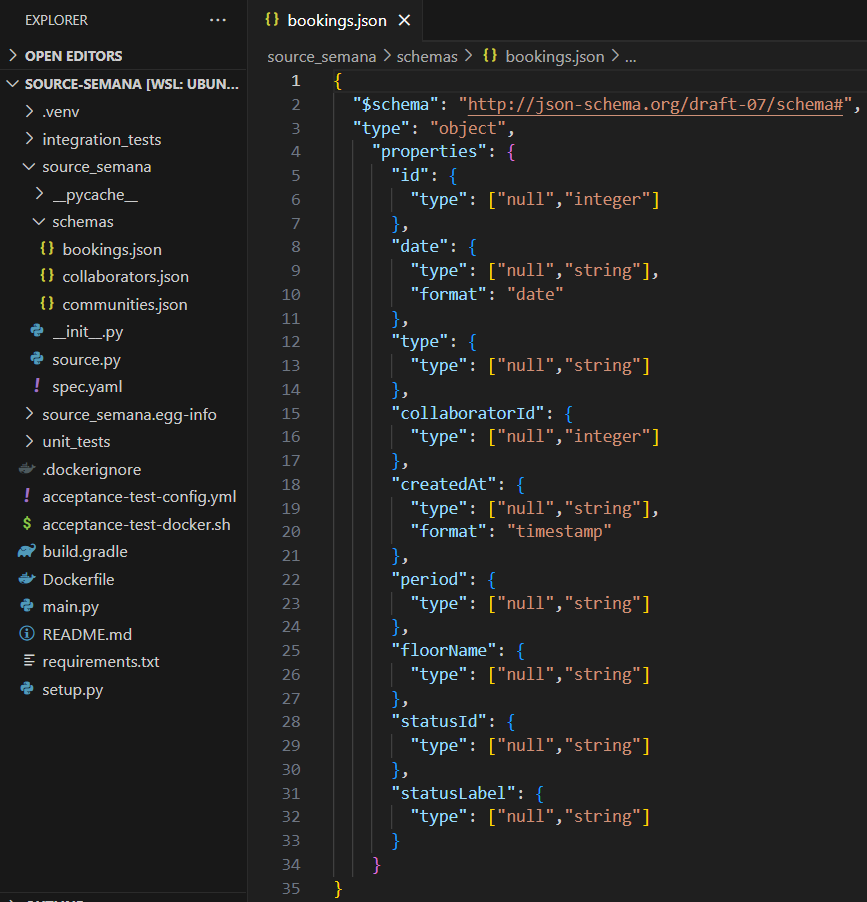
Comme pour les autres étapes, nous pouvons tester le bon fonctionnement de notre implémentation en exécutant la ligne commande suivante :
python main.py discover --config secrets/config.json
Read
Maintenant que la description des données est possible, passons à la lecture, grâce à l’implémentation de la dernière étape : read. Dans cette dernière partie de l’implémentation nous allons voir comment lire les données mais également comment gérer l’incrémentalité. Concernant la lecture des données, elle est en réalité déjà implémentée par Airbyte. Ainsi, notre tâche ne consiste finalement qu’à parser la réponse de l’API afin de structurer les données comme nous le souhaitons et comme nous l’avons déclaré dans nos schéma JSON. Pour ce faire, nous devons implémenter la méthode parse_json() de la classe SemanaStream :

Comme nous pouvons le voir sur la figure précédente, nous nous contentons seulement de transformer la réponse de l’API en JSON, puis de sélectionner la partie des données qui nous intéresse.
Afin de mettre en place la gestion de l’incrémentalité, nous devons réaliser l’implémentation de la méthode read_records() dans la classe IncrementalSemanaStream, ainsi qu’initialiser et gérer l’actualisation du champ gérant la fraîcheur des données.
Dans un premier temps, on définit le state de notre stream incrémental, qui est un dictionnaire stockant la valeur la plus récente du cursor_field, qui lui-même est le champ des données qui va permettre de déterminer lesquelles sont “nouvelles” (dans notre exemple : le champ createdAt de Bookings). Pour ce faire, nous implémentons le getter et le setter pour l’attribut state :
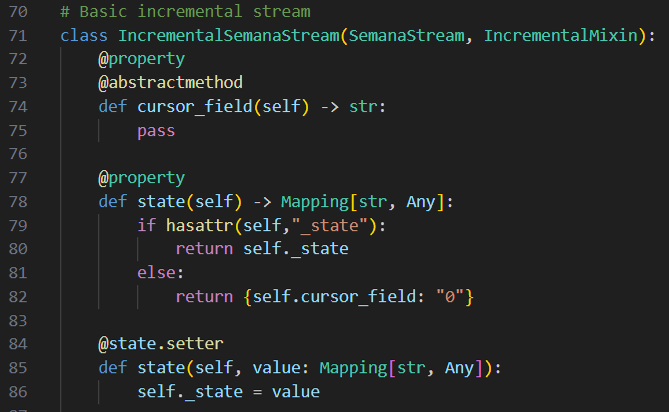
Si le state n’est pas encore défini (cas de la première ingestion de données), la valeur 0 est donnée au cursor_field afin de prendre toutes les données présentes dans la source.
Ainsi, nous pouvons ensuite implémenter la méthode qui va actualiser le state à chaque ingestion de données :
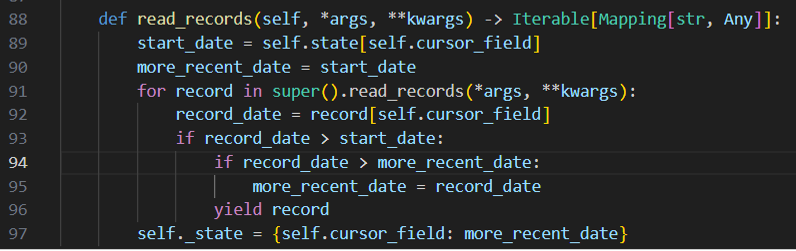
Bien que la méthode soit nommée read_records(), c’est Airbyte qui réalise la lecture des données à proprement parler. Nous ne faisons ici que lire les données plus récentes que la dernière ingestion, tout en actualisant le state pour la prochaine ingestion.
Comme pour chaque étape, nous pouvons tester la bonne implémentation en ligne de commande :
python main.py read --config secrets/config.json --catalog integration_tests/configured_catalog.json
Le fichier configured_catalog.json est censé contenir un catalogue configuré Airbyte, c'est-à-dire la déclaration de tous les streams du connecteur, ainsi que le schéma de leurs données dans la source et les types d’ingestions supportés par chacun. Le fichier ressemble donc à ceci dans notre cas d’usage :
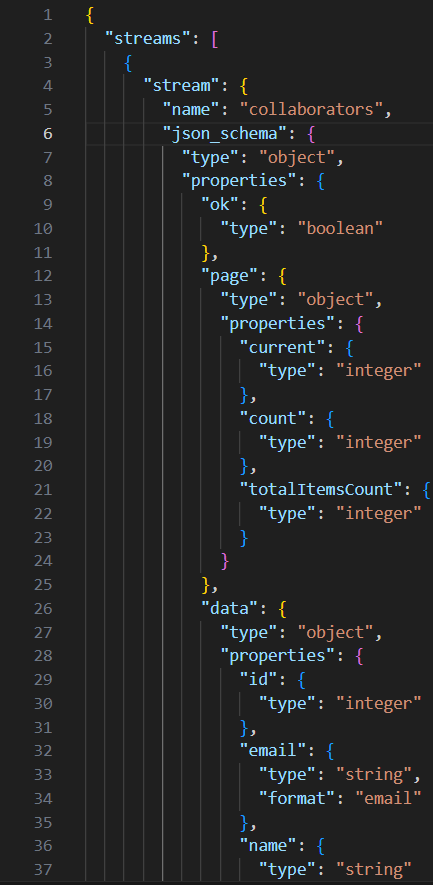
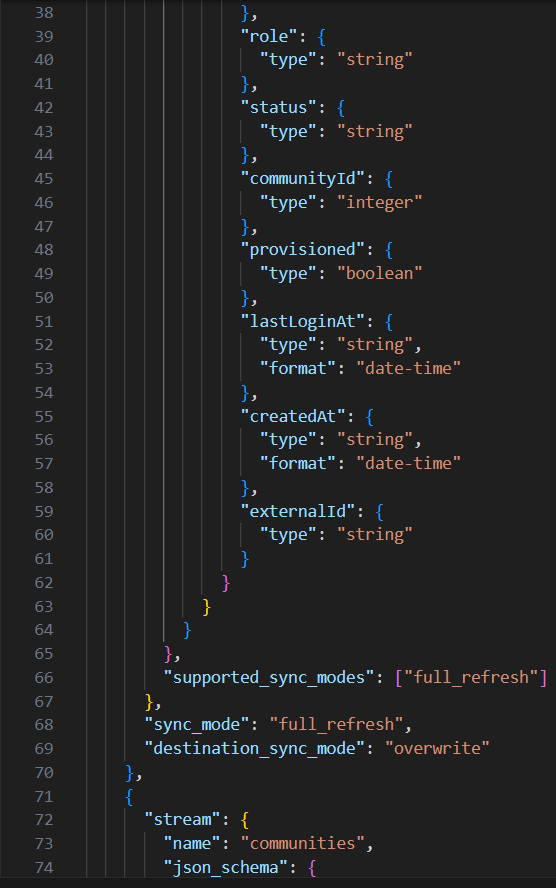
Figure 12 : Extrait du fichier configured_catalog.json
Maintenant que l’implémentation est terminée, nous pouvons build l’image docker de notre connecteur. A la génération du dossier source-semana, un fichier Dockerfile est également créé, ce qui permet de construire l’image en ayant qu’à exécuter la commande suivante :
docker build . -t airbyte/source-semana:dev
Nous pouvons ensuite tester les différentes étapes implémentées précédemment avec les commandes suivantes :
docker run --rm airbyte/source-semana:dev spec
docker run --rm -v $(pwd)/secrets:/secrets airbyte/source-semana:dev check --config secrets/config.json
docker run --rm -v $(pwd)/secrets:/secrets airbyte/source-semana:dev discover --config secrets/config.json
docker run --rm -v $(pwd)/secrets:/secrets -v $(pwd)/integration_tests:/integration_tests
airbyte/source-semana:dev read --config secrets/config.json --catalog /integration_tests/configured_catalog.json
Passons maintenant au déploiement de notre connecteur. Pour ce faire, il faut se rendre dans les réglages, puis dans la partie source et enfin appuyer sur le bouton “nouveau connecteur” en sélectionnant l’option “connecteur Docker” :
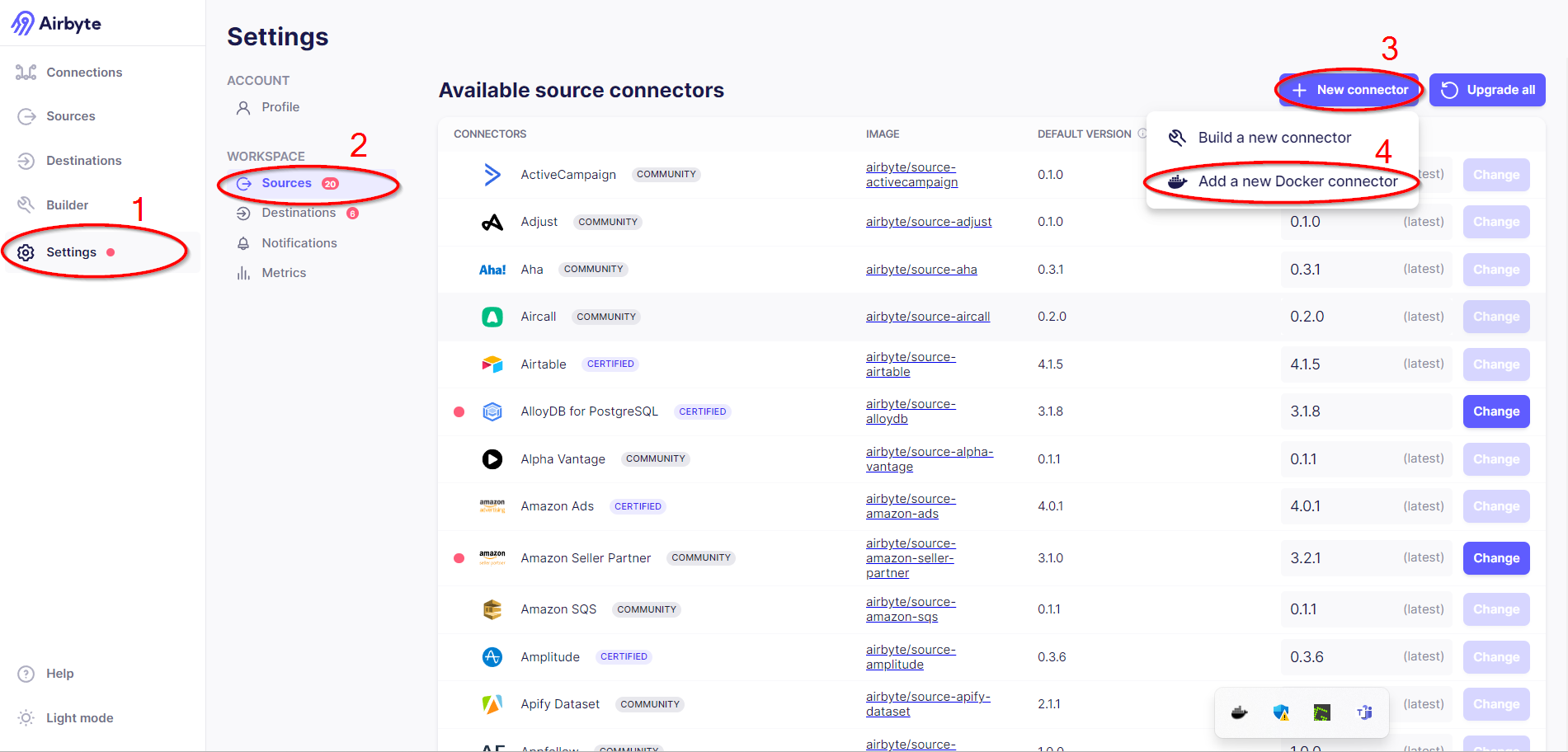
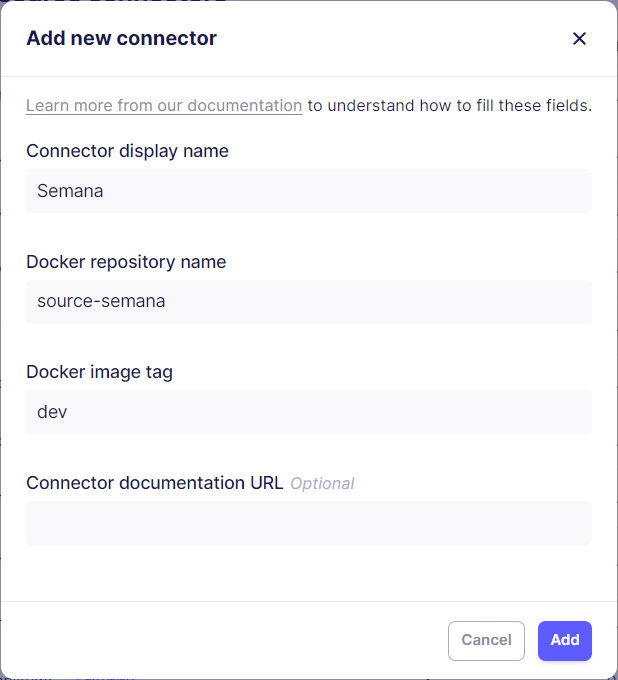
Une fois cette option choisie, une nouvelle fenêtre apparaît. Dans celle-ci, nous devons déclarer le nom du connecteur, le nom du dossier dans lequel il est implémenté et enfin le tag de son image Docker; comme visible en figure 14.
Le connecteur étant maintenant déployé, il est possible de créer une source en le sélectionnant dans celles-ci, puis en remplissant les différents champs présents en figure 3.
Conclusion
Airbyte se vante d’une construction facile et rapide de connecteurs customs et ne nous ment pas. En effet, avec une grande partie du code auto-générée et commentée avec des indications sur la démarche à suivre, la prise en main et l'implémentation sont grandement simplifiées. De plus, la documentation et les tutoriels sont très détaillés et permettent de comprendre en profondeur les notions clés du connecteur. À ceci s’ajoute l’existence de connecteurs d’exemple et l’accès au code de toutes les sources et destinations déjà créées, permettant de voir les différentes implémentations.
Pour conclure, créer son connecteur custom est un exercice que je recommande fortement car cela permet de travailler sur des notions importantes en ingestion de données comme l’incrémentalité, le full-refresh ou encore les schémas de données. Enfin, Airbyte étant un outil de plus en plus populaire, vous aurez peut-être à le mettre en place un jour et avoir développé un connecteur custom sera alors un avantage vous permettant d’être à l’aise sur toutes les notions clés de l’outil.
Dans cet article, nous avons vu comment générer un connecteur custom pour une source, les étapes clés de l’implémentation avec des illustrations en exemple et enfin comment déployer et utiliser son connecteur sur l’outil. Vous avez donc maintenant les connaissances pour créer votre propre connecteur custom Airbyte; à votre tour de vous lancer !
Pour aller plus loin
Si vous souhaitez en découvrir plus sur le sujet et/ou créer votre propre connecteur custom, je vous conseille les pages suivantes :
- le repo Airbyte : https://github.com/airbytehq/airbyte/
- la doc et les tutoriels d’Airbyte sur ses connecteurs : https://docs.airbyte.com/connector-development/
Si vous souhaitez en apprendre plus sur l’outil qu’est Airbyte, son écosystème ou encore son déploiement, je vous renvoie vers les articles suivants :
- Décrire vos ressources Airbyte as code avec Octavia CLI écrit par Baptiste Mansire.
- Déployer ses ressources Airbyte avec Terraform écrit par Meyan Oker.