

Cet article a été co-écrit par plusieurs consultants : Etienne GANDRILLE, Junior JOSEPH, Edouard DE BRYE et Arnaud COSPAIN
Nous voici maintenant au dernier jour de cette KubeCon. Nous sommes bien fatigués, mais l’ambiance survoltée de 12000 participants partageant cette même passion pour les applications cloud native est absolument unique ! Si vous ne l’avez pas encore fait, n’hésitez pas à consulter les compte-rendus de mercredi et de jeudi.
Au terme de cette KubeCon, les prochaines étapes sont déjà balisées. Tout d’abord, avec le dixième anniversaire de Kubernetes, la CNCF souhaite célébrer cet événement largement le 6 juin prochain. Nul doute que nous serons invité à organiser des événements dans nos communautés locales. Pour coordonner cet anniversaire, une page a vue le jour sur le site internet de la CNCF : https://kuberTENes.cncf.io
La CNCF souhaite également mettre en avant ses certifiés, et plus particulièrement ceux qui ont réussi le challenge d'obtenir les cinq certifications : CKA, CKAD, CKS, KCNA, KCSA. Et pour cela, elle lance le Kubestronaut program. A travers cette initiative, on sent la volonté de mettre en avant des experts, de faire émerger des leaders capables d’avoir de la hauteur de vue pour conduire Kubernetes vers son vingtième anniversaire.
Enfin, alors que cette édition se termine, les regards sont déjà tournés vers les prochaines éditions de la KubeCon qui auront lieu à Londres en Avril 2025, et à Amsterdam en Mars 2026.

Cloud Native in the next Decade
Difficile de prédire l’avenir, l’exercice étant toujours particulièrement risqué. Cependant, un panel s’est prêté à ce jeu et une présentation a permis de restituer les résultats.
De manière globale, on ne sera pas surpris de voir l’IA sur la plus haute marche du podium. Même si peu d’entreprises ont développé une expertise dans ce domaine, tous les regards se tournent vers ce spectre technologique présenté comme la prochaine révolution qui ne fait actuellement que commencer.
Sur la seconde marche du podium se trouve, également et sans grande surprise, la sécurité. Derrière cette thématique, on devine bien entendu la sécurité des infrastructures IT, et également la sécurité des données, que ce soit les données stratégiques comme les données personnelles. Plus que jamais, leur divulgation a un impact majeur sur la santé des entreprises, que ce soit au niveau réputationnel ou au niveau opérationnel.
Et sur la dernière marche, se trouve bien entendu la préoccupation écologique. Certaines conférences, cependant peu nombreuses, étaient d’ailleurs axées sur cette thématique. Tout le monde sait qu’il y a encore beaucoup à faire et que l’urgence de la prise en compte de la responsabilité de l’IT dans le réchauffement climatique ne peut pas être balayée d’un revers de la main en disant que le solutionnisme technologique viendra à bout de cette problématique… plus tard !
D’autres réponses se sont montrées parfois plus exotiques mais néanmoins intéressantes. Citons par exemple Chris Aniszczyk qui voit dans Wasm (dont nous avons parlé dans l’article d’hier) le runtime de demain pour exécuter les modèles d’AI/LLM. Ou encore John Howard (Istio TOC) dont la prédiction tient en un mot : “Simplicity”. Il est vrai que si cette prédiction devenait réalité, cela marquerait une rupture avec la situation actuelle tant l’écosystème technologique est aujourd’hui complexe et mouvant !
Du côté des déploiements, tous les intervenants s’accordaient pour dire que l’approche cloud native allait poursuivre son développement. Même si cela semble effectivement probable, il faut reconnaître qu’il y avait un certain biais au niveau de la sélection des membres du panel ! Cependant, au-delà de cette considération générale, certains voyaient dans l’approche multi cluster un axe de développement. Chris Aniszczyk entrevoit quant-à lui le développement d’une informatique cloud native ubiquitaire, avec des déploiements au niveau edge device, et même au-delà. Mais à travers ces spéculations, peut-être que le consensus était le suivant : de la même manière qu’au cours de la décennie qui vient de s’écouler, les machines virtuelles sont devenues une brique de base, une commodité que l’on utilise sans même y penser, l’approche cloud native pourrait être la nouvelle brique de base pour la décennie à venir !
Kubernetes Security Blind Spot: Misconfigured System Pods
Speaker: Shaul Ben Hai @Palo Alto Networks
Lors de cette conférence, ont été abordées les vulnérabilités de sécurité inhérentes à Kubernetes, en se concentrant sur les pods système qui, si mal configurés, peuvent être un blind spot critique. Les sujets abordés comprenaient les mécanismes d'évasion de conteneurs, les attaques de seconde phase de Kubernetes, le rôle important de ces pods, un exemple de mauvaises configurations rencontré dans le monde réel, et a conclu avec des recommandations pour atténuer les risques.
Pour commencer, concernant l’évasion de conteneurs et les attaques de seconde phase dans Kubernetes. Les conteneurs, bien qu'efficaces pour le déploiement de logiciels, présentent une sécurité faible, pouvant entraîner des vulnérabilités ou des configurations incorrectes (par exemple : conteneurs privilégiés, hôtes sous-jacent). Les attaques de seconde phase de Kubernetes exploitent ces vulnérabilités, avec des attaquants ciblant les Daemonsets et les permissions élevées plutôt que les déploiements et les faibles permissions pour se propager efficacement dans le cluster.
Il est donc important de comprendre les pods système : permissions et risques qui sont associés à leur utilisation. Les pods système possèdent des permissions élevées essentielles au bon fonctionnement du cluster, incluant la gestion du réseau, le contrôle d'accès et la surveillance. Cependant, ces privilèges augmentent la surface d'attaque, rendant ces pods des cibles attractives pour les acteurs malveillants. De cela, découle le paradoxe des pods système, qui réside dans la nécessité de ces pods privilégiés contre les risques qu'ils introduisent. La mise en œuvre du principe du Least Privilege, la minimisation des surfaces d'attaque, et une surveillance et une journalisation rigoureuses sont des stratégies clés pour atténuer ces risques.
Pour illustrer la portée de ces enjeux, l'exemple présenté durant l'exposé était une combinaison de mauvaises configurations, de FluentBit et du DaemonSet du CNI d'ASM, qui pouvaient être exploitées pour obtenir les permission Administrateur du Cluster (GCP-2023-047).
Ainsi, sécuriser un cluster Kubernetes est un processus continu nécessitant une attention particulière. Une attention minutieuse doit être accordée à chaque interaction, permission et configuration des pods système. Les pods système devraient être nettement séparés des pods d'application pour réduire les risques de sécurité.
En somme, la sécurité de Kubernetes est un domaine complexe et en constante évolution, qui nécessite une compréhension approfondie des risques et des vulnérabilités associés. L'accent mis sur les pods système mal configurés souligne l'importance d'une gestion de sécurité proactive. Adopter des mesures préventives, telles que la séparation stricte des pods applicatifs et systèmes, l'application du Principe de Moindre Privilège, et la mise en place d'une surveillance robuste, est crucial pour protéger les environnements Kubernetes contre les menaces émergentes. La sécurisation de ces systèmes est une responsabilité partagée qui exige vigilance, expertise, et une collaboration continue entre les équipes de développement et de sécurité.
Knative Functions Deep-Dive: Why You Should Use Knative Functions For Your Next Microservices Application
Speakers: Mauricio "Salaboy" Salatino, @Diagrid; Dave Protasowski, @Broadcom; Luke Kingland, @Red Hat
Knative est une solution opensource de Function as a Service (FaaS) qui est apparue en 2018. Cette solution fait partie des projets incubés de la Cloud Native Computing Foundation (CNCF) depuis 2022, et à ce titre est considérée comme un projet mature utilisable en production, et audité en terme de sécurité.
Knative propose plusieurs modes de déploiements : Serving pour déployer un service déclenché par des requêtes HTTP, ou Eventing pour déclencher le service via un bus d’événement.
En mode Serving, on peut scaler le pod à zéros replicas grâce à des Activator qui font tampon entre les requêtes HTTP entrantes et le pod contenant notre fonction. Ces Activator permettent également de faire tampon quand le pod est surchargé, et de laisser le temps de monter en charge à Knative en cas de pics de charge.
En mode Eventing, le middleware qui fait office d’Activator est un Broker, qui source ses événements depuis Kafka, GitHub, un peu ce que vous voulez.
Ça peut être un peu pénible de déployer toutes ces ressources soit même, et Knative met à disposition une CLI pour déployer ses fonctions en un rien de temps, à la manière d’AWS qui a créé la CLI SAM pour améliorer l’expérience développeur. Il suffit donc d'exécuter `func deploy` avec les bonnes configurations dans un fichier pour recompiler son code, le packager dans une images docker avec buildpacks, pousser cette image dans notre registry, et mettre à jour (ou créer) les manifestes Kubernetes spécifiques à Knative pour déployer notre function. À noter qu’un manifests pour déployer un service Knative est unique, ce qui réduit de beaucoup les manifestes boilerplate dont une application classique a besoin, à savoir les Déploiement, Ingress, Service, ServiceAccount et HorizontalPodAutoscaler. Et encore il peut y en avoir plus.
Knative apporte également des fonctionnalités de health check, management des révisions, management de la concurrence, gestion des cold start.
Knative peut être un gros morceau à installer sur son cluster car il faut installer un service mesh, de préférence Istio. Mais une fois que tout est configuré, il est très facile de développer et déployer ses fonctions d’un point de vue développeur. C’est une bonne alternative à Lambda ou Azure Function si vous avez un cluster Kubernetes et les moyens de le maintenir.
Cet article a attiré votre curiosité, nous vous invitons à lire celui-ci :

Saving the Planet One Cluster at a Time : Operationalising Sustainability in Kubernetes
Speakers: Gabi Beyers & Brendan Kamps @re:cinq
La première moitié de l’atelier a été une énième présentation des bases du green-it, appliqué à des concepts On-Premise, avec notamment :
- Le rappel que la quantité de carbone libérée dans l'atmosphère lors de la production de l’équipement est largement supérieure à celle émise pendant son utilisation. Aussi il faut allonger au maximum la durée de vie de l’équipement avant de remplacer les serveurs constituant son parc.
- Les présentateurs mettent en avant que Scaleway est un bon élève qui arrive à allonger d’avantage que ces concurrents la durée de vie de ses équipements.
- Faire tourner un serveur consomme de l’électricité, électricité qui en fonction de son origine géographique et du type de ressources permettant à la centrale électrique de fonctionner (charbon, nucléaire, renouvelable, etc.) permet d’associer une mesure en équivalent CO2 émis pour le fonctionnement de ce serveur. Pour référence : https://app.electricitymaps.com/map
- Il a été présenté une méthode pour recueillir le nombre de Joules consommés par un serveur avec https://github.com/powercap/raplcap et basé sur cette formule :
Energy Consumption (Joules / 10 sec = kWh) x Grid carbon intensity coefficient (grams/kWh) = grams CO2 eq
La seconde moitié de l’atelier se concentre sur une approche liée au Cloud puisqu’au travers de la virtualisation. Les données sont difficiles à exploiter car il est rappelé à quel point les CSP sont avares sur le partage des informations sur leurs serveurs. Les auteurs utilisent pour référence cette formule :
Operational Emissions = CPU emissions + memory emissions + storage emissions + networking emissions
Les auteurs ont mis en avant deux axes permettant de réduire son empreinte carbone en tant que client des Cloud Service Providers (CSP), démonstration à l'appui :
- L'application du concept de "Follow the Sun"
Ce graphique représente l’évolution des sources d’énergies en fonction des heures de la journée. On voit donc que l’énergie solaire (en orange, low-carbon) est importante en journée, mais que cette source d'énergie n'est significative qu'une courte partie de celles-ci.
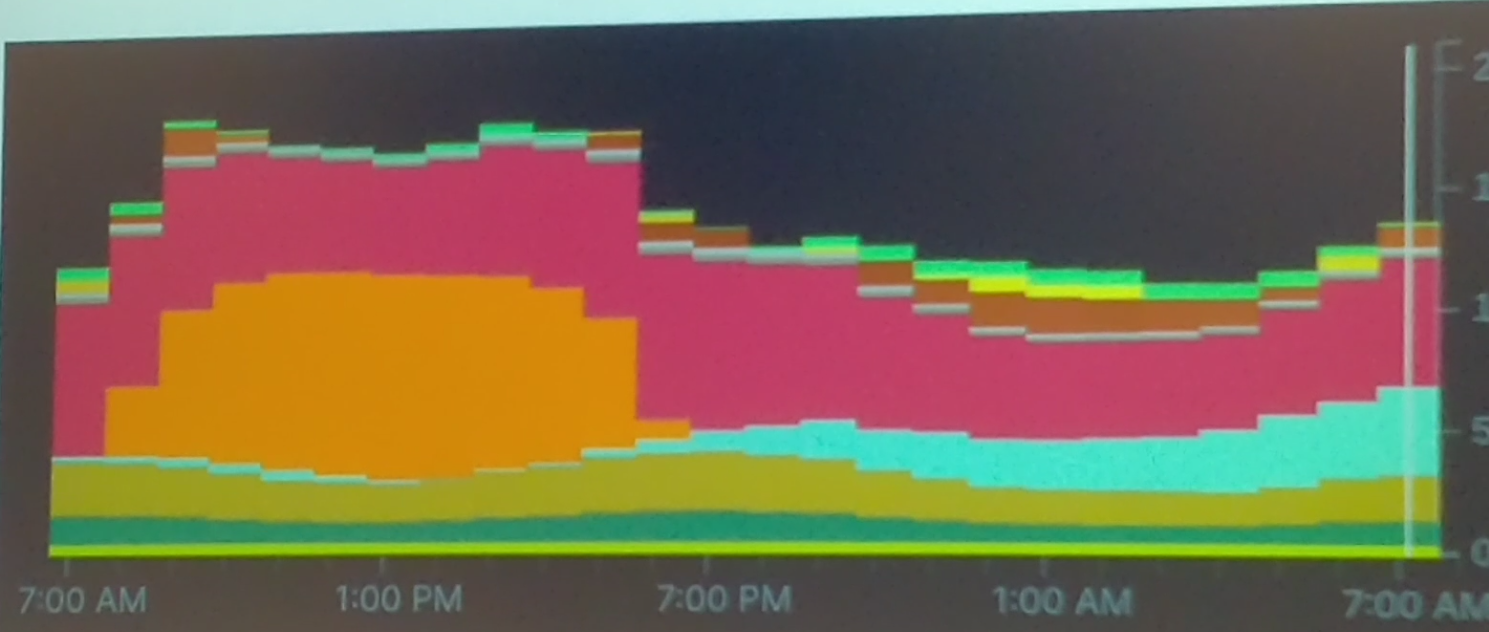
L’approche du “Follow the Sun” consite à exploiter au maximum la production électrique via l'énergie solaire et par conséquent à migrer les charges applicatives sur les clusters Kubernetes d’une région à en autre en fonction des heures de la journée. Les conférenciers invitent à rechercher des outils sur Google, il en existe apparemment beaucoup, y compris pour Kubernetes !
2. Charger au maximum les serveurs
La consommation d’électricité d’un serveur n’est pas linéaire avec son utilisation ! Il est important d'exécuter un maximum de charges applicatives sur les nœuds de son cluster Kubernetes, car la consommation des serveurs est asymptotique.
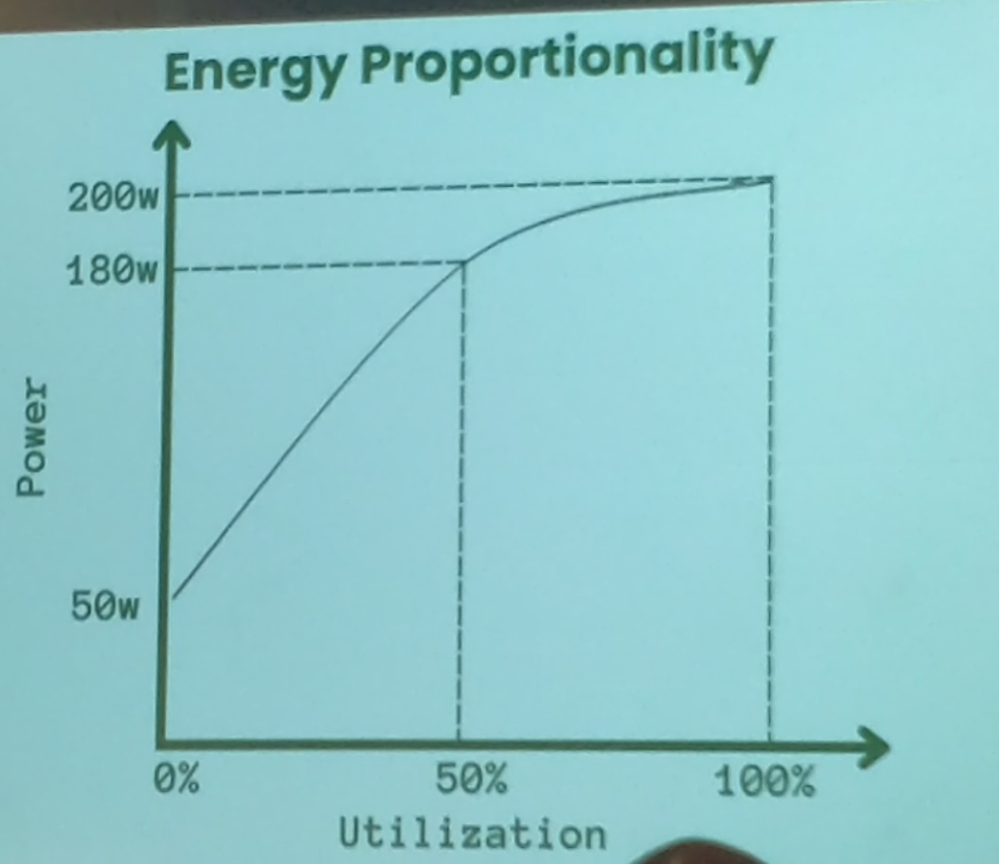
Dans la même logique : il est plus intéressant de choisir un nœud avec beaucoup de vCPU qui consommera moins d’énergie que plusieurs nœuds de puissances inférieures pour servir la même charge applicative.
En conclusion ⇒ “Fewer nodes = less carbon”
From Chaos to Control: Cloud Native Governance with Kyverno!
Speakers: Charles-Edouard Brétéché, @Nirmata; Mariam Fahmy, @Nirmata; Raúl Garcia Sanchez, @DE-CIX
Kyverno est un moteur de règles pour valider, modifier, créer ou nettoyer des ressources Kubernetes. Il fait partie des projets de la Cloud Native Computing Foundation (CNCF) depuis 2020, y est un projet incubé depuis 2022 et à ce titre est considéré comme un projet mature utilisable en production, et audité en terme de sécurité.
Kyverno est un projet natif à Kubernetes, on peut écrire nos règles comme une ressource Kubernetes et par conséquent les manager comme n’importe quelle autre ressources Kubernetes. Ces règles vont se déclencher lorsqu’une ressource Kubernetes est créée, par le biais d’un mécanisme inhérent à Kubernetes : les Admission Webhooks. Il y en a deux: le Mutating Webhook et le Validating Webhook. Certaines règles peuvent également être déclenchées via un cron.
Kyverno est particulièrement utile dans une structure qui a une équipe “plateforme” en charge du maintien de Kubernetes, et des équipes “projet”, qui doivent utiliser Kubernetes pour y déployer en toute autonomie des ressources. Ces équipes projet peuvent être autonomes tout en respectant les règles prescrites par l’équipe plateforme via Kyverno, afin de garantir sécurité et uniformisation au sein des ressources déployées.
Mais Kyverno peut également être utile à toute équipe pour uniformiser et sécuriser ses applications.
Kyverno va avoir plusieurs objectifs :
- Valider les ressources soumises, afin de respecter certaines normes de sécurité ou d’uniformisation des ressources. Par exemple, empêcher un Deployment dont le pod autorise l’escalation de privilèges, ou empêcher la création d’un Deployment qui n’a pas de label CostCenter.
- Modifier la configuration, afin de remplir des champs des manifestes soumis avec des valeurs par défaut. Par exemple ajouter un quota en CPU et Memory Requests à chaque namespace créé si celui-ci n’en précise pas, ou ajouter un champ NodeSelector au Deployment.
- Générer des ressources. Par exemple créer un Role et un RoleBinding pour chaque namespace créé, afin de donner à une équipe des droits sur son namespace.
- Supprimer des ressources, afin de nettoyer le cluster. Par exemple, supprimer tous les pods non contrôlés par un contrôleur.
Les règles de Kyverno permettent de réduire grandement la complexité comparativement à créer sa propre logique de validation, de mutation ou de nettoyage des ressources. On peut de plus utiliser l’outil en ligne de commande de Kyverno pour appliquer une règle de validation sur une ressource existante. Ça peut être utile pour tester qu’une règle que l’on développe fonctionne ou encore pour générer des rapports de conformité. Il y a également un site où le peut tester ses règles : https://playground.kyverno.io
La suite de la conférence parle du futur de Kyverno. Aujourd'hui Kyverno a l’avantage d’être no code pour les utilisateurs, simple d'utilisation, et nativement pensé pour Kubernetes. Mais ce dernier point est également son point faible, Kyverno est très couplé à Kubernetes, et n’a pas vraiment vocation à exister en dehors de cet écosystème, il manque de portabilité.
Les contributeurs de Kyverno veulent moderniser l’outil pour lui permettre de s’émanciper de Kubernetes tout en conservant son essence : un moteur de règles qui peut valider, modifier, créer.
Un projet a commencé pour valider des objets JSON. Le projet introduit quelques changements dans la structure des règles pour valider n’importe quel JSON, peu importe son origine. Ce travail a pour but de pouvoir, par exemple, valider un plan terraform avec Kyverno.



