

Cet article a été co-écrit par plusieurs consultants : Etienne GANDRILLE, Paul BOISSON, Pierrick ROBIC-BUTEZ, Yoan SIMIAND-COSSIN, Maxime SEH, Vivien MALEZE et Timothée AUFORT
Cette année, nous avons la chance de recevoir en France la KubeCon / CloudNativeCon, conférence annuelle de la CNCF (Cloud Native Computing Foundation). Cette conférence est également l'occasion de fêter un anniversaire : Kubernetes va avoir 10 ans en juin 2024.
Chaque jour, nous avons fait un compte rendu des conférences qui nous ont marqués. C’est parti pour le premier jour !
Keynotes

Cela ne surprendra personne, les keynotes étaient résolument tournées vers l’intelligence artificielle et les LLM. De manière générale, tous les intervenants s'accordent pour dire que nous sommes “au milieu du gué” : l’intelligence artificielle en général, et le machine learning en particulier attirent beaucoup d’attention et d’investissements, mais il reste encore beaucoup à faire pour structurer l’industrialisation des pratiques.
Tout d’abord, sur le plan de l’allocation des ressources. Le machine learning nécessite d’importantes ressources, et l’accès aux GPU est de plus en plus crucial. Pour cette raison, il est nécessaire d’améliorer la sélection des nodes sur lesquels tournent les pods, afin de bénéficier de l’accès au GPU. Cela passe également par de nouveaux mécanismes d’ordonnancement. Plutôt que d’ordonnancer plusieurs tâches sur plusieurs GPU, pourquoi ne pas donner un accès exclusif à chaque tâche sur un GPU ? On l’aura compris, les réflexions se poursuivent, et il faudra du temps avant que la standardisation s’impose !
Un autre champ de recherche est celui de l’outillage. A titre d’exemple, les pratiques de gestion des logs et de l’observabilité sont bien avancées hors du champ du machine learning. Mais il reste encore beaucoup à faire pour standardiser cette approche dans le cadre de l'entraînement et de l’exécution de modèles sur des clusters Kubernetes.
Enfin, le grand public a découvert les prouesses de l’intelligence artificielle grâce à des projets tels que chat GPT. En tant que développeurs, nous avons commencé à interagir avec des modèles au travers d’API. Mais pour que l’AI devienne une “commodité” à large échelle, il sera nécessaire de standardiser les API, en particulier dans le monde de l’open source. Et il est clair que nous en sommes encore loin. Pour en savoir plus sur cette thématique, n’hésitez pas à consulter le white paper de la CNCF.
A travers ces quelques remarques, on constate (sans vraiment être surpris, il est vrai !) que le monde de l’intelligence artificielle est en pleine ébullition mais nécessite encore beaucoup de structuration pour que l’ensemble des projets puisse être utilisé de manière plus standardisée, donc plus interchangeable et plus transparente. Le chemin est long, mais il est passionnant, et nous progressons un pas après l’autre !
Flux and the Wider Ecosystem Planning BoG
L’une des conférences a été animée par certains des principaux responsables du projet Open Source FluxCD, initié par des développeurs de l’entreprise Weaveworks, permettant de faire du GitOps. Dans cette conférence, non technique, un état des lieux du projet a été fait, en soulignant notamment l’importance de la contribution de la communauté Open Source dans le cadre d’un tel projet. Aujourd’hui, le projet FluxCD, c’est plus de 600 contributeurs avec 8 responsables identifiés (personnes qui sont chargées de gérer le projet au quotidien, d’articuler le travail des contributeurs etc). Le projet était activement soutenu par Weaveworks, mais la fermeture de l’entreprise en février 2024 a porté un coup dur au projet qui s’est vu amputé d’un soutien financier et humain important. Beaucoup de développeurs et de responsables étaient employés par Weaveworks et il est plus simple de contribuer à l’open source lorsque cela fait partie de notre travail. C’est pour cela que le projet lance un nouvel appel à contribution.
Comment devenir contributeur ?
- Commencer par suivre le Slack du projet, regarder le code, utiliser l’outil pour comprendre son fonctionnement ;
- Si on ne se sent pas à l’aise avec le développement, il est possible de contribuer en participant à l’amélioration de la documentation, en aidant les autres sur le Slack du projet ou sur les forums, remonter les bugs, apporter de nouveaux cas d’utilisation, apporter de nouvelles idées ;
- Lorsque vous vous sentez prêt, développez votre propre fonctionnalité et partagez la avec la communauté ;
- Les responsables aimeraient faire en sorte que de plus en plus de contributeurs deviennent les responsables de leurs fonctionnalités (ce qui demande plus d’investissement) ;
- Dans le cas où vous êtes une entreprise et que vos collaborateurs utilisent FluxCD au quotidien, contribuez au projet en leur permettant de contribuer à des projets open source en leur donnant du temps pour le faire. Vous pouvez même les récompenser pour cela.
Les contributeurs ont permis à différents projets annexes de voir le jour comme Flux-iac qui permet de mettre en place FluxCD par le biais d’outils d’Infrastructure as Code (Terraform, Pulumi, OpenTofu etc) ou encore le plugin flux-backstage qui permet aux ressources de FluxCD d’être visibles depuis Backstage.
Ce qui était surprenant lors de cette conférence (et en relisant mes notes), c’est à quel point l’équipe a insisté sur leur besoin de nouveaux contributeurs et surtout de nouveaux mainteneurs qui seraient responsables de gérer des pans entiers de l’outil. Si on aime le projet, il faut avouer que la fermeture de Weaveworks lui a porté un coup dur mais aussi qu’il a pris beaucoup de retard par rapport à ArgoCD. Ce dernier apporte davantage de fonctionnalités que FluxCD et est devenu aujourd’hui la référence des outils GitOps. Nous espérons que le projet pourra se sortir de cette mauvaise phase.
Is serverless powerfully powerless?
Speakers : Jose Gomez-Selles, Senior Product manager @RedHat et Kevin Dubois, Principal Developer Advocate @RedHat
“Si nous continuons sur notre trajectoire actuelle de consommation d’énergie de calcul, en 2040, nous atteindrons la capacité de production d’énergie du monde”. Cette citation de Bilge Yildiz, professeur au MIT, en dit long sur le travail que nous avons à faire dans l’informatique.
Le serverless est une belle promesse pour adapter la capacité de calcul à la demande des utilisateurs des applications. Mais est-ce réellement la solution magique ? Pour essayer de répondre à cette question, les 2 speakers ont décidé de mener une expérimentation sur Kubernetes en comparant le déploiement d’une application serverfull avec le proxy Istio, le déploiement de la même application en serverless avec KNative et également le déploiement de cette même application en mode dit “simple” sans fioriture. Ils ont utilisé un outil CNCF qui s’appelle Kepler pour mesurer la consommation d’énergie. Cet outil est au stade Sandbox en niveau de maturité CNCF. Il utilise eBPF pour collecter et exporter les statistiques d’un système relatives à l'énergie.
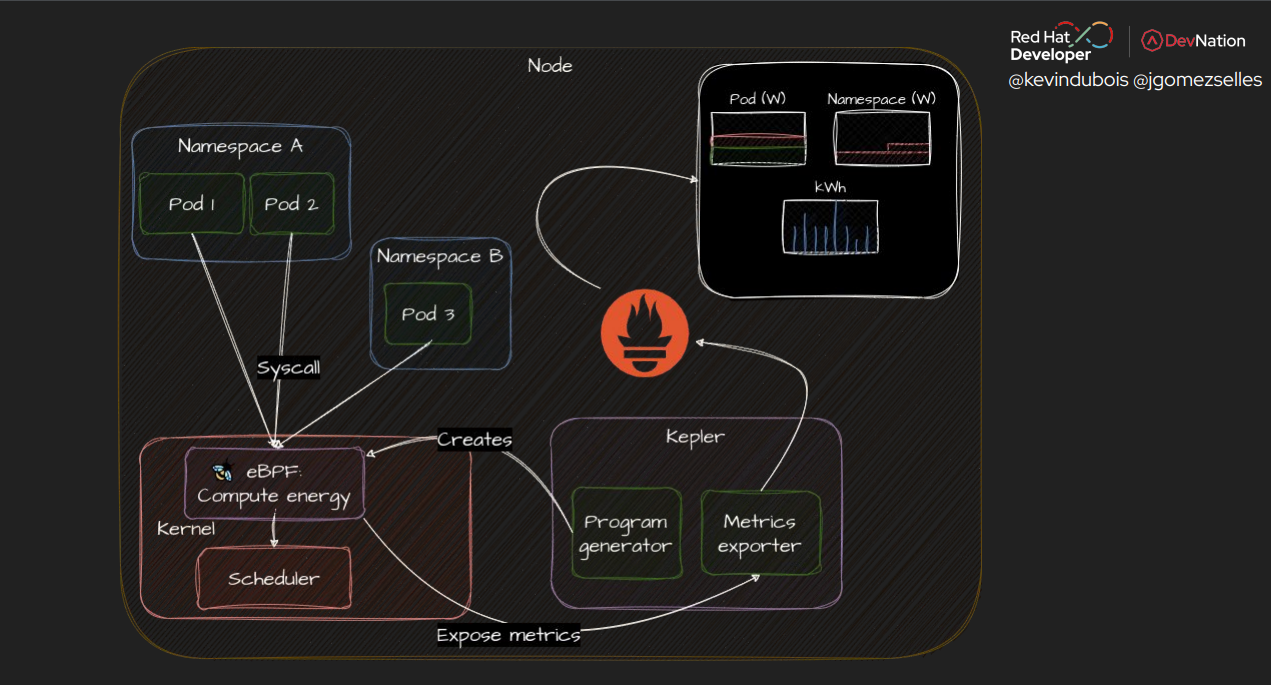
Dans les premiers scénarios, afin de comparer l’énergie consommée entre les 3 solutions, ils ont utilisé un serveur mocké (HTTP/2, 2000 RPS sur 1 connexion, 20 minutes de trafic généré sur chaque solution une fois par heure et 6 instances par solution), les résultats sont surprenants :
- La solution simple est la solution la moins énergivore. Elle permet de se rendre compte qu’un service mesh comme Istio augmente la consommation d’énergie d’un facteur x2,5.
- L’énergie consommée par les 2 solutions se résume comme suit : E(serverless) > E(serverfull) > E(simple) ;
- KNative augmente la consommation d’énergie quand il n’y a pas de trafic (en mode veille) ;
- La surcharge de la solution serverless provient principalement des ressources de KNative ;
- L’énergie consommée par les ressources KNative est équivalente à celle des ressources de la solution serverless.
Ils ont ensuite essayé de doubler la charge sur le serveur mocké (4000 RPS), d’augmenter la concurrence jusqu’à 8 instances pour éviter des erreurs ou encore de modifier la capacité de burst dans KNative mais le résultat était toujours le même.
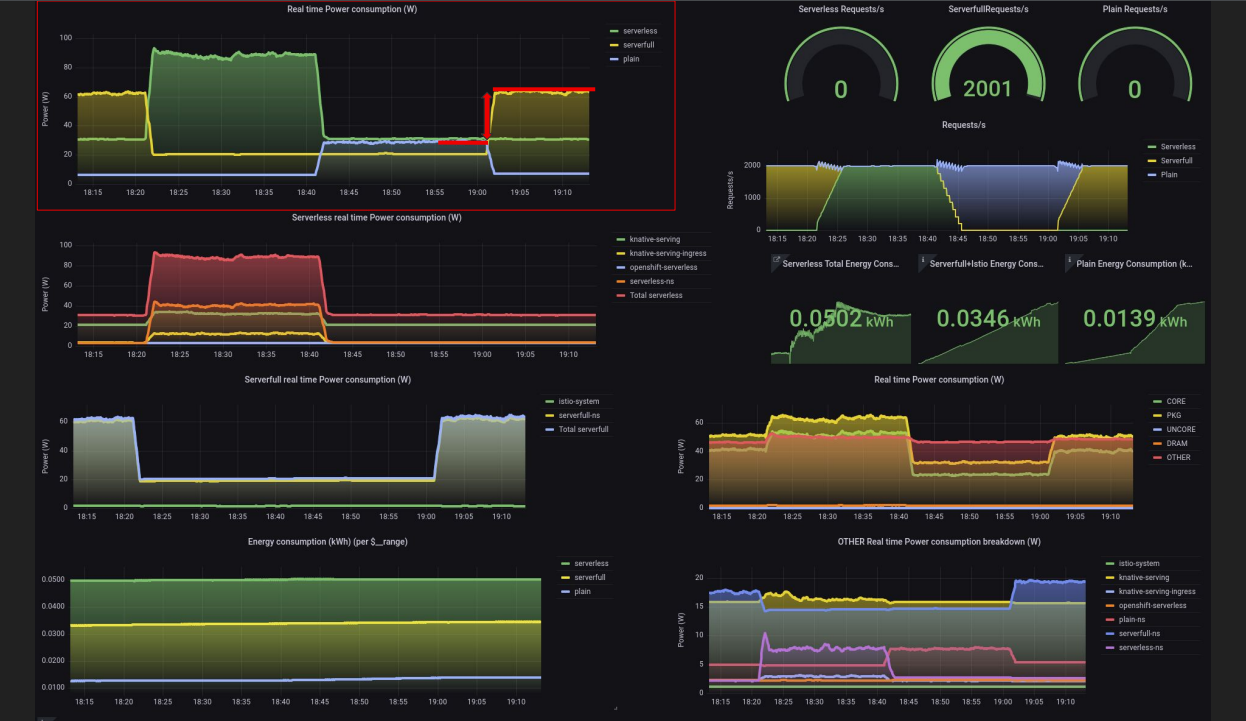
Pour la dernière expérimentation, ils ont remplacé le serveur mock par un serveur effectuant du vrai travail en Java avec Quarkus et ils sont passés à 6 RPS sur une seule connexion. Le résultat final est : E(serverless) = E(serverfull) > E(simple). Dans ce cas là spécifiquement, le serverless commence à devenir puissant.
Ajouter plus de fonctionnalités (comme Istio, KNative ou autres) a toujours un prix, des systèmes en arrière-plan comme KNative entraînent une surconsommation d’énergie. Par ailleurs, l’énergie consommée en fonction du trafic n’est pas linéaire. Une charge de travail de taille unique ne convient donc pas à toutes les situations, c’est pour cette raison qu’il est très important de mesurer, que ce soit dans une situation de charge ou au ralenti. Je n’avais personnellement pas encore entendu parler de Kepler, je vais définitivement y accorder du temps à l’avenir et le proposer à des clients qui veulent s’investir dans le GreenOps sur Kubernetes afin d’économiser de l’énergie, de l’argent ou les deux !
Dapr
Speakers : Josh Van Leeuwen, Software Engineer @Diagrid et Yaron Schneider, CTO, @Diagrid
Quand on déploie un cluster Kubernetes et que l’on commence à développer des applications, on se retrouve vite avec la nécessité d’interagir avec des services fournis par l’infrastructure. Par exemple, il peut être nécessaire :
- d’aller chercher un secret stocké dans Vault ou dans le Secret Manager d’AWS ;
- de publier un message sur un topic ou de se mettre en attente de messages publiés ;
- d’utiliser un verrou distribué (lock) ;
- d’utiliser un service de discovery ;
- etc…
Pour tous ces cas d’usage (et bien d’autres !), le développeur d’application devrait avoir besoin d'utiliser simplement une API standard, sans se soucier de l’implémentation sous-jacente. C’est précisément ce que propose Dapr (Distributed Application Runtime) avec un ensemble de SDK pour différents langages de programmation.
Du point de vue déploiement, Dapr doit être installé dans le control plane du cluster Kubernetes dont on souhaite gérer les applications. De là, il injecte des sidecars dans les pods et le SDK vient alors interagir avec ceux-ci.
Le projet a déjà quatre ans, et cette présentation a permis de nous présenter de nouvelles fonctionnalités parmi lesquelles :
- une nouvelle approche pour éviter le recours aux conteneurs en sidecar ;
- un tout nouveau service d’orchestration : Dapr Workflow ;
- une API de cron job distribuée : Cron binding spec ;
- une API pour programmer l’envoi différé de messages via l’API de pub/sub déjà présente.
Le projet Dapr poursuit donc sa route et nous rappelle également que l’expérience du développeur d’applications dans un cluster Kubernetes ne doit pas être négligée !
Simplifying multi-cluster and multi-cloud deployments with cilium
Speaker : Liz Rice @Isovalent
On ne présente plus Cilium qui s’impose comme un standard lorsque l’on parle de CNI (Container Network Interface) et d’observabilité. Basé sur la technologie eBPF, Cilium promet de meilleures performances que ses concurrents, tout en apportant une couche d’observabilité bas niveau avec un faible impact sur la consommation de ressources.
Un des nombreux avantages de Cilium est la simplicité de mise en place d’une connectivité entre plusieurs clusters, et donc potentiellement entre plusieurs cloud providers. Pour ce faire, l’outil utilise une connexion VPN entre les clusters, permettant de connecter les réseaux des différents clusters entre eux.
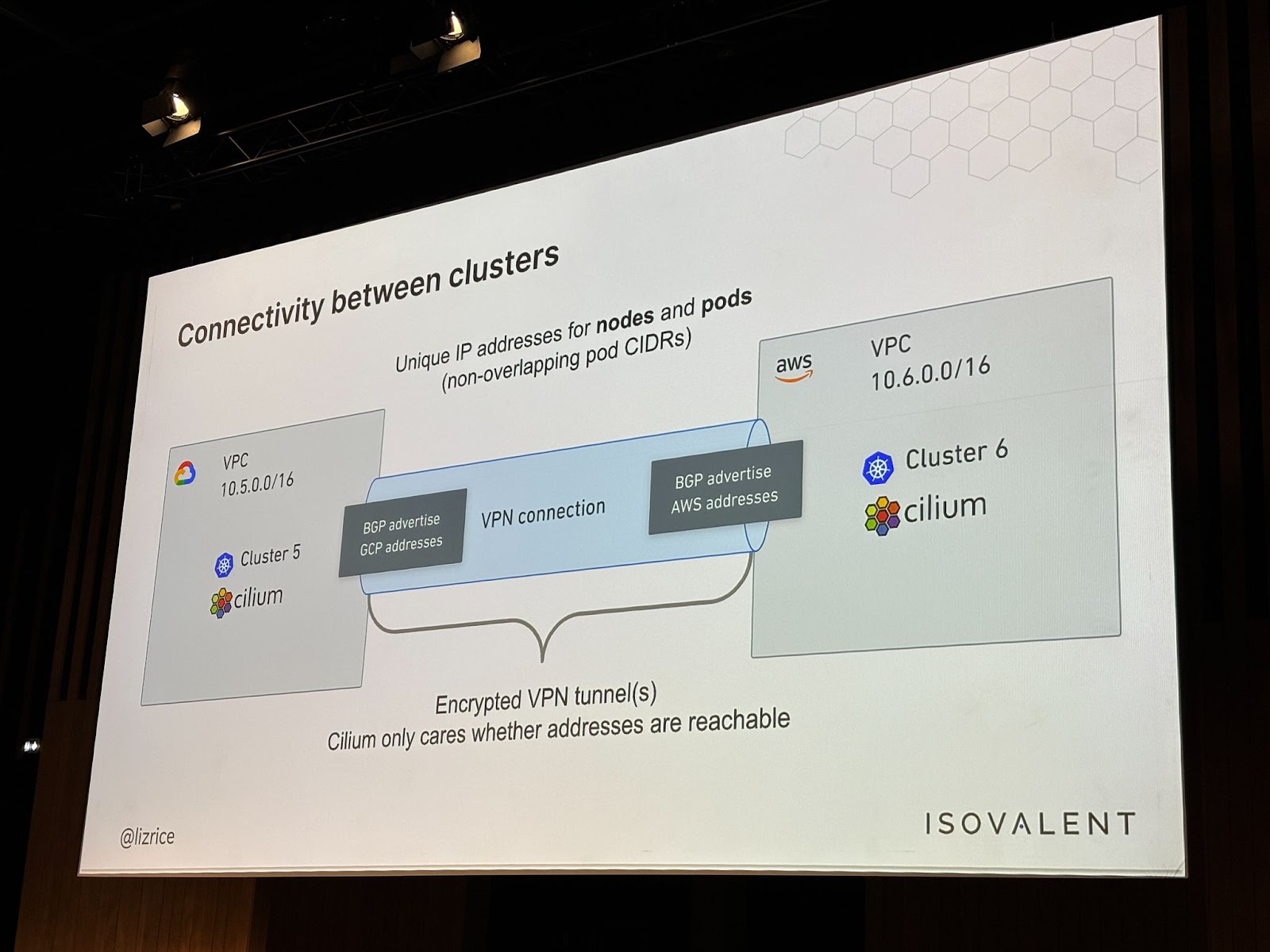
Afin de permettre aux composants Cilium des différents clusters de communiquer, un équilibreur de charge interne est déployé dans chaque cluster.
La mise en place d’une telle solution nécessite quelques prérequis :
- Les blocs CIDR des différents réseaux ne doivent pas se chevaucher ;
- Les clusters doivent avoir des id et nom uniques ;
- Les clusters doivent utiliser le même mode de routage Cilium ;
- L’option “cluster mesh” doit être activée lors de l’installation de Cilium.
Liz RICE a ensuite présenté, avec une démonstration en direct, quelques cas d’usages et fonctionnalités de déploiements multi clusters :
- La possibilité de créer des services globaux, permettant de répartir la charge entre plusieurs clusters, avec une simple annotation : service.cilium.io/global: true ;
- La possibilité de définir des règles d’affinité entre le cluster “local” et le “remote”, afin de préférer le local mais d’avoir un basculement en cas de problème ;
- La possibilité de mettre en place des network policies au niveau cluster, rendu possible grâce à l’ajout de labels implicites ajoutés pas Cilium aux pods afin de pouvoir identifier le cluster.
Bien que l’utilisation de multi-clusters à travers un ou plusieurs cloud providers ne soit pas un besoin très répandu, Isovalent réussit le défi d’une mise en place simplifiée, tout en apportant des fonctionnalités intéressantes dans un tel contexte, le tout sur fond d’eBPF rendant la solution extrêmement efficace et permettant d’ajouter une couche d’observabilité et de sécurité - notamment via leur projet Tetragon - à moindre coûts.
Au-delà de ce cas d’usage, nous sommes convaincus que Cilium est LE nouveau standard en termes de CNI, et qu’il constitue une réelle innovation d’un point de vue réseau et observabilité dans un contexte Kubernetes.
How to save millions over years using keda?
Speaker : Solene Butruille @BlackRock
Solene nous a présenté son cas d’usage sur leur projet “Aladdin”, ils créent des environnements à la volée pour leurs utilisateurs. Ces environnements ont tendance à rester en veille et à consommer des ressources alors qu’ils pourraient très bien être éteints en attendant une action de la part de l’utilisateur. Derrière tout ça se cache une envie de moins consommer et du coup de moins dépenser chez Azure, leur cloud provider.
L’équipe s’est donc penché sur la mise en place de la cible suivante : si un utilisateur n’utilise pas son environnement pendant un certain temps, son environnement est scale à 0. Dès qu’il souhaite faire une action, l’environnement est remis en marche.
Le composant natif de kubernetes pour gérer l’auto-scalabilité (HPA) ne permettant pas de scale à 0, il a fallu trouver une autre solution.
Ils se sont donc intéressés à Keda (Kubernetes event driven autoscaling). Keda est un projet open source qui permet de gérer l’auto-scalabilité dans kubernetes en se basant sur des “triggers”. Il permet notamment de scale un déploiement à 0. La liste des triggers compatibles avec Keda est disponible ici : https://keda.sh/docs/2.13/scalers/.
Avec Keda, c’est vraiment très simple. Il suffit d’installer l’opérateur sur votre cluster puis d’appliquer la configuration souhaitée.
Exemple :
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: my-env-scaledobject
spec:
minReplicaCount: 0
maxReplicaCount: 1
cooldown: 3600 #1
scaleTargetRef:
name: my-deployment #2
triggers:
- type: prometheus #3
metadata:
serverAddress: http://kube-prometheus-stack-prometheus.monitoring.svc
threshold: '1' #4
query: sum(rate(http_server_requests_seconds_count{app="my-app"}[1m])) #5
- Temps avant que le service soit scale-down ;
- Déploiement ciblé à scale-up ou scale-down ;
- Type de trigger sur lequel on se base pour gérer le scaling. Ici, on utilise Prometheus qui contient des metrics propres à nos services ;
- Le threshold à partir duquel on démarrera l’environnement ou bien il devra s’arrêter ;
- La requête exécutée sur Prometheus.
La configuration ci-dessus permet de scale l’environnement d’un utilisateur si il n’a aucun appel pendant au moins 1h.
En conclusion, combien BlackRock a-t-il pu économiser grâce à KEDA ? Actuellement, ZERO dollars ! En effet, avant de commencer ce chantier d’optimisation, ils avaient souscrit auprès d’Azure à des réservations de ressources avec une durée d’engagement de 3 ans. La facture est donc inchangée malgré une baisse des besoins réels de ressources. En revanche, cela leur permet de continuer à faire grandir le nombre d’utilisateurs sans faire augmenter leur facture, en attendant la fin de leur engagement de 3 ans pour reconsidérer une réservation de ressources revue à la baisse. A titre d’exercice, Solène a simulé en combien de temps ils auraient économisé 1M$ s’ils avaient été en Pay-As-You-Go : la réponse est 5 ans.
Devs demand UX for k8s
Speakers : Marin Duffy, UX Engineer @RedHat et Conor Cowman, Software Engineer, @RedHat
Les deux speakers de RedHat ont entrepris une étude sur l’utilisation de k8s par des devs et des platform engineers au sein de Redhat dans le contexte de la release de… Podman desktop. La population interrogée a un niveau hétérogène sur Kubernetes.
“K8s is beautiful when it works, but when it doesn’t, there are all these pieces lying on the ground. where do I start?”. Kubernetes est génial et puissant mais complexe surtout quand ça casse.
Le résultat de cette étude a servi de guide pour le développement de nouvelles fonctionnalités dans Podman desktop permettant de faciliter la vie des développeurs. L’étude a porté sur les thématiques suivantes : problématiques rencontrées, méthodes pour déboguer, workflow et l’architecture de l’instance k8s..
Les problématiques rencontrées et les réponses apportées sur Podman desktop sont :
- le debugging réseau d’une infrastructure k8s
- indentation des fichiers yaml de conf
→ besoin : meilleur intégration, détection des erreurs
- validation des fichiers YAML
→ besoin de disposer d’un outil intégré qui permet la validation qui inclut les principes GitOps et fonctionnent avec les CRD (Custom Ressources Definitions)
- export des fichiers YAML : souvent pollué par des tags, timestamp et libellé pas optimal.
→ besoin d’exporter des YAML propres sans tags compatibles avec git
- analyses de sécurités non adaptées qui génèrent de nombreux warning.
→ besoin : information en temps réel, affiner les alertes pour réduire le nombre de faux positif
- Crash de pods en boucle : frustration, difficulté de récupérer les logs et de résoudre le problème —> Un outil intégré est nécessaire
- CLI vs GUI : les deux sont importants mais complexes. Le CLI demande un apprentissage plus long, ce qui fait que la GUI est encore utilisée par certains. Cela devient surtout compliqué lorsqu’il faut assister quelqu’un sur la GUI sans partage d’écran. —> Podman desktop simplifie la GUI.
La conférence s’est terminée de manière soudaine par la présentation de la version 1.8 de Podman Desktop qui intègre de nouvelles fonctionnalités.
Globalement, on sort de cette conférence avec beaucoup d’idées pour améliorer les choses, mais sans avoir de réelles solutions tout en un. Podman Desktop est une première approche qui tente de solutionner de nombreux problèmes, mais il faudra encore du temps avant d’avoir une vrai UI qui facilite le travail des développeurs.





