

Cet article présente les nouveautés évoquées lors du Databricks DATA + AI World Tour Paris qui s’est tenu le 9 novembre 2023. J’étais accompagnée de Boris Perevalov qui m’a permis d’enrichir cet article.
L’année 2023,du côté de Databricks, est résolument tournée vers l’IA générative, qui était à l’honneur lors de ce sommet annuel. L’accent était également mis sur la démocratisation de l’accès au lakehouse.
Voici un résumé des conférences auxquelles nous avons assisté.
Séance plénière
Le service LakehouseIQ a été présenté. Il permet à une entreprise d’entraîner et de déployer son propre modèle génératif contextualisé à son propre environnement.
Il s’agit de Databricks Assistant, basé sur Unity Catalog. Il comprend le contexte de l’entreprise grâce au modèle basé sur les données privées de celle-ci. Cela implique de rendre disponible tout le corpus de documents de l’entreprise. Ce corpus fait autorité, mais il peut être également complété par un LLM (Large Language Model).
Les avantages sont les suivants :
- contrôle du modèle : possibilité de se différencier par rapport à d’autres,
- privatisation du modèle : les données restent privées,
- coût : les coûts d’entraînement et d’inférence sont moindres que pour l’utilisation d’un modèle LLM basé sur une quantité de données bien plus élevée.
Ce service est proposé suite au rachat par Databricks de MosaïcML, une entreprise leader sur le marché de l’IA générative. Elle a notamment développé le service autoML (automated Machine Learning) qui permet de tester et sélectionner facilement le meilleur modèle pour son cas d’usage. L’accès aux différentes sources de modèles est assuré par MLFlow AI Gateway. Il est également possible d'entraîner des modèles en quelques heures au lieu de quelques jours habituellement.
Les nouveautés du Delta Lake 3.0 ont également été présentées. Elles sont axées autour de la démocratisation du lakehouse.
Delta Lake with UniForm
Elle permet de lire dans le lakehouse les données dans les autres formats sans rien changer. Il est à noter que :
- les metadata sont gérées dans un format universel aussi bien pour Delta, Hudi et Iceberg,
- les données de base sont toutes au format parquet et compatibles avec tout type de connecteur.
Lakehouse Federation
Elle permet de faire un mount des différentes sources de données dans Unity Catalog (mySQL, Snowflake...).
Lakehouse monitoring
Une des nouveautés est le déploiement de l’IA pour détecter des _schema drift _par exemple.
Clean rooms
Il est possible de croiser ses données, analytics et IA avec celles d’autres entreprises sans les partager. Cela permet une collaboration efficace tout en garantissant la confidentialité des données.
Delta Sharing
Il s’agit d’un open protocol pour le partage de données cross-plateformes. Il inclut Databricks Marketplace, les lakehouse apps et Databricks Clean Rooms. Le marketplace met en relation les providers et les consumers de données, on peut y plugger directement des modèles d’IA. De plus, le partage se fait sans copier les données.
Simplifying lakehouse observability
L’observabilité est la capacité à comprendre ce qu’il se passe dans un système grâce aux données externes produites par ce système. L’observabilité est plus vaste que le monitoring, qui consiste seulement à tracer des métriques prédéfinies et ainsi détecter des phénomènes mis en avant par ces métriques.
L’observabilité apporte beaucoup de valeur car elle permet de prendre des décisions basées sur des preuves.
L’observabilité permet de résoudre les incidents opérationnels suivants :
- erreurs de workloads,
- workloads incontrôlables,
- incidents sur les données (exfiltration, pollution…).
L’observabilité chez Databricks se fait via les system tables. Il s’agit de tables qui collectent directement les données externes au système. Avant cela, ces données étaient plutôt stockées sous forme de fichiers CSV et JSON qui demandaient de la manipulation avant de pouvoir les exploiter. Ces fichiers étaient généralement générés dans un langage propriétaire du cloud provider.
Les system tables sont des bronze tables que l’on peut nous-même raffiner en gold tables. LakehouseIQ s’y applique :
- on peut utiliser du Python et du machine learning pour créer des insights,
- on peut utiliser SQL pour générer des rapports et dashboards,
- on peut également poser une question en anglais et elle est automatiquement traduite en SQL.
Des alertes statiques ou dynamiques peuvent également être générées.
Il est possible de croiser les tables. Par exemple, si on croise les tables lineage et billing, on peut voir ce qui est vraiment utilisé dans le workspace. Un autre cas d’usage est la prévision des coûts.
L’accès aux différentes tables peut être limité, de sorte que chaque utilisateur analyse les données qui lui sont propres.
Pour l’instant, ce service est gratuit en preview. Il s’active depuis le metastore : l’option à considérer est “operational data” à mettre en on / off. Les données se rafraîchissent toutes les heures et la cible finale est en rafraîchissement toutes les 5 minutes. Le TTL (Time To Live) des données est de 30 jours.
Le modèle de facturation qui s’appliquera dans le futur sera basé sur un coût récurrent car il est nécessaire de processer les données en continu.
Pour l’exploitation des coûts, une table list_price est mise à disposition pour permettre à l’utilisateur de compléter les données avec ses propres tarifs de cloud provider (inclure les discounts négociées).
A ce jour, les system tables sont générées à partir du billing, du lineage et des audit logs.
Dans le futur, elles concerneront l’ensemble des services, incluant le compute, workflow, etc…
Databricks SQL
Databricks SQL est disponible depuis 18 mois. C’est le service qui a eu l’adoption la plus rapide chez Databricks. Il s’agit d’un entrepôt de données serverless sur la plateforme lakehouse de Databricks. Il fait tourner :
- les applications BI et SQL de manière scalable,
- un modèle de gouvernance unifié,
- des formats ouverts et APIs,
- tout outil de son choix (aucune restriction) en utilisant des tokens OAuth ou PAT.
La concurrence des requêtes a été multipliée par 4 depuis l’année 2020.
Ce service est intégré à Unity Catalog.
Il permet de faire des dashboards en drag and drop en s’affranchissant de SQL. Il n’a pas vocation à être un acteur majeur de la visualisation mais propose une solution simple d’accès à la donnée du delta lake à n’importe quel type d’utilisateur (démocratisation du lakehouse).
Il est possible :
- d’y inclure des UDF python,
- d’écrire des requêtes SQL pour obtenir des insights sur de la donnée non structurée via l’interrogation de LLMs (exemple : lecture de commentaires pour en déduire les critères de décisions d’achats),
- d’utiliser Databricks Assistant.
Databricks Assistant est un assistant en IA qui comprend le contexte de nos propres données. Il permet notamment de générer et d’auto-compléter du code et des requêtes.
Il intègre LakehouseIQ et s’applique aux system tables.
Les vues matérialisées permettent d’accélérer les requêtes utilisateurs et de réduire les coûts d’infrastructure grâce à un compute efficace et incrémental.
L’orchestration de requêtes SQL, de dashboards, d’alertes… se fait via Workflows + Databricks SQL. Le management intelligent de workloads mixtes permet de réduire la latence des requêtes (3 fois moins de temps). Il optimise le stockage des requêtes en fonction des usages précédents.
Data sharing
De multiples possibilités existent pour le partage de données, dont :
- le partage de schémas de Unity Catalog,
- le partage de notebooks Databricks,
- le partage de volumes,
- le partage de modèles d’IA,
- les data cleanrooms,
- le marketplace.
Le partage de schémas permet de partager des datasets massifs à l’échelle. Il n’est plus nécessaire d’intervenir sur chaque objet individuellement. Le partage concerne automatiquement les futures données. Le management du partage reste donc facile même dans un contexte de datasets changeants.
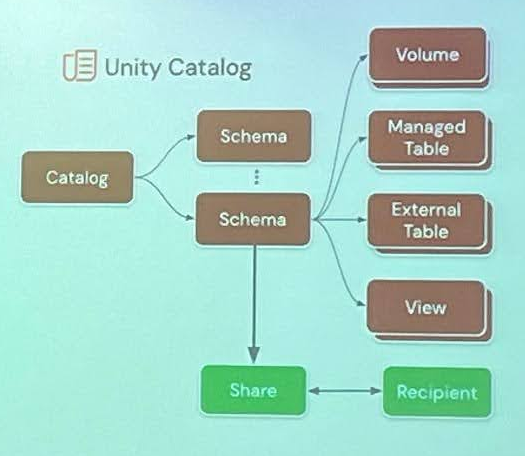
Le partage des notebooks permet de diffuser les insights relatifs à un jeu de données. Les recipients peuvent consommer et cloner les notebooks partagés. Le code du notebook permet un partage de la donnée avec un “guide d’exploitation”.
Le partage de volumes permet de collaborer sur n’importe quel format de données. Le Lakehouse stocke des données mais pas seulement : il stocke aussi des fichiers audio, video, PDF, etc… Les workloads IA/ML/DS sont donc facilités.
Le partage de modèles d’IA enregistrés sur Unity Catalog est possible entre les différents clouds, régions et plateformes. Exemple de cas d’usages : monétisation de ces modèles, déploiement inter-régions, innovation par collaboration.
Les data cleanrooms sont des environnements sécurisés qui permettent de croiser ses données, analytics et IA en toute confidentialité. Par exemple, deux entreprises peuvent effectuer un JOIN sur leur données sans les partager. Bien entendu, cela nécessite que les jobs Databricks qui en découlent soient mutuellement approuvés par les différentes parties. Seul le résultat est partagé.
La mise à l’échelle est possible entre des collaborateurs multiples avec n’importe quel type de données, n’importe quel cloud et dans n’importe quelles régions. Il n’y a aucune réplication de données présentes dans les tables de lakehouse existantes.
Ce service facilite donc la compliance au RGPD.
Les data cleanrooms s’appuient sur Delta Sharing.
Le marketplace partage directement des insights des données de plus de 75 providers (media, retail, santé, finance...).
Les partages suivants sont à venir prochainement :
- les user-defined functions,
- les vues matérialisées et les Delta Live Tables.
Des améliorations seront apportées aux outils de reporting et management, et des nouveaux schémas d’authentification sont attendus (OIDS / OAuth 2.0), ainsi que le partage vers des individus par email.
Conclusion
La plateforme Databricks est en perpétuelle évolution, les nouveautés sortent à un rythme soutenu. Cette conférence m’a permis d’en savoir plus sur les services proposés par Databricks et de comprendre leur vision du monde de la data. L’accent mis sur la démocratisation du Lakehouse laisse à penser qu’il occupera une place prépondérante dans les mois / années à venir. Le partage et la mise à disposition de données de qualité en sont le point de départ essentiel. Les possibilités d’exploitation sont infinies, en partant de simples visualisations, jusqu’à l’IA générative.
Pour aller plus loin, la documentation Databricks est disponible :
Delta sharing : https://docs.databricks.com/en/data-sharing/index.html
LakehouseIQ : https://www.databricks.com/blog/introducing-lakehouseiq-ai-powered-engine-uniquely-understands-your-business