

Cet article fait suite au précédent article que j'ai publié, sur les 3 conférences qui m'ont le plus marquées cette année.
AWS re:Invent 2023 - Simplifying modern data pipelines with zero-ETL architectures on AWS (PEX203)
Lien Youtube : ici
Lors d’une mission pour un client autour de la refonte de leur plateforme data (dans un contexte de migration sur AWS), j’avais été frappé par le décalage entre le monde “merveilleux des services” AWS et la dure réalité de mise en œuvre.
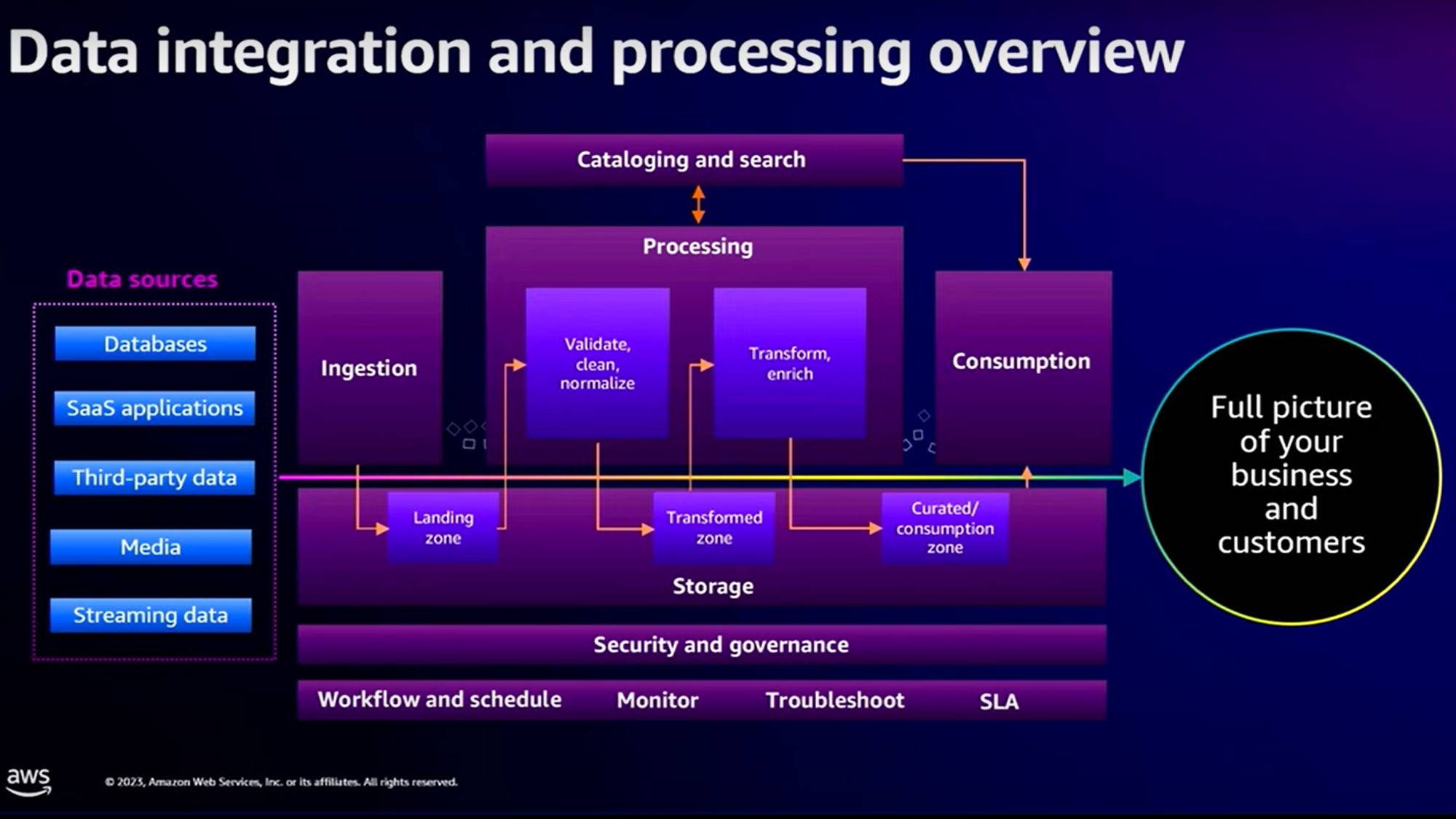
C’est exactement l’angle d’attaque qui introduit cette conférence : les difficultés de mise en œuvre.
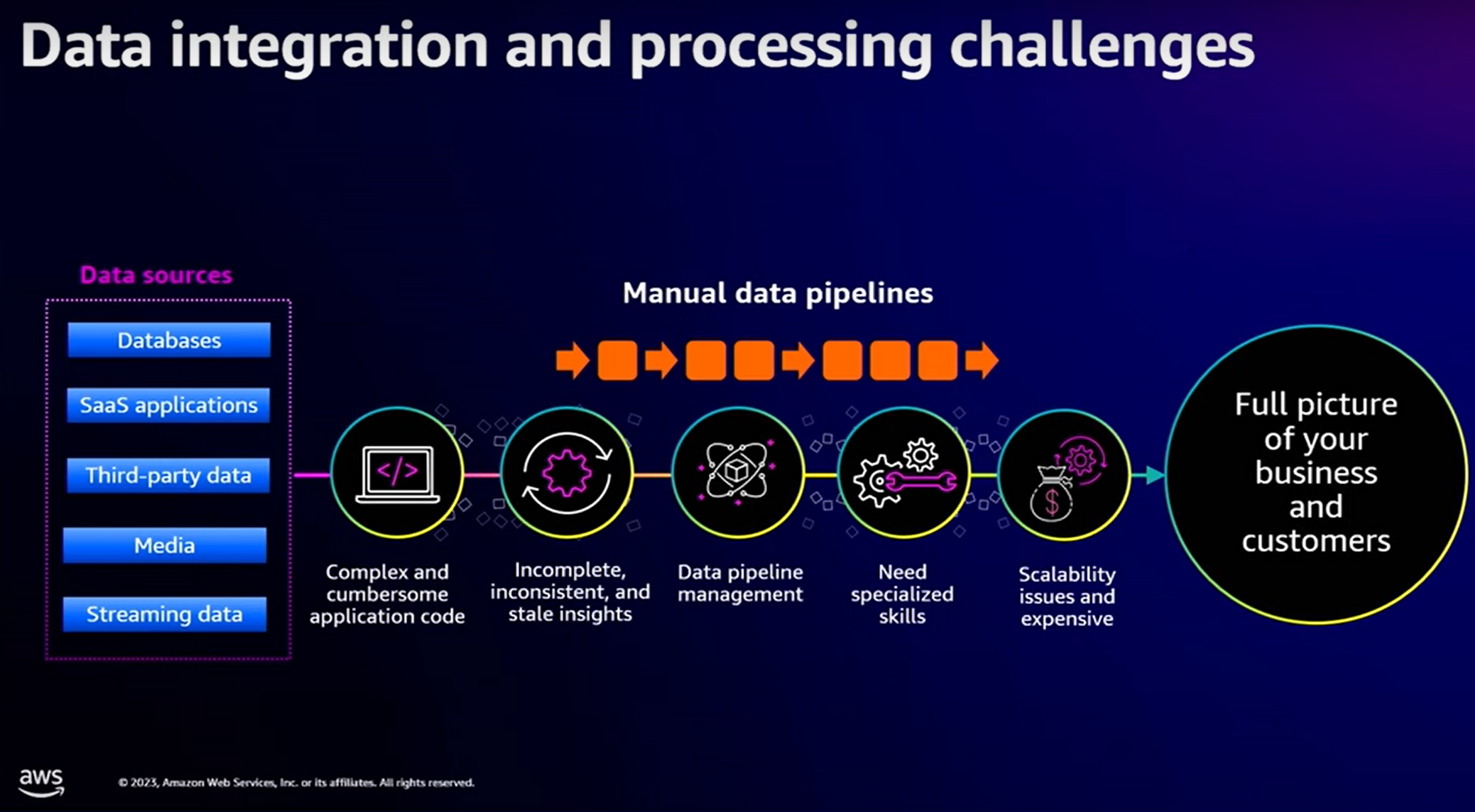
Effectivement, pour chaque source de données à intégrer, nous devons définir des “data pipelines”, chacun d’eux devant être codé, monitoré. En mixant les technologies, en introduisant des modèles de ML (Machine Learning), en passant à des datasets de plus en plus étendus, on se retrouve à la fin avec un système assez complexe à maintenir et à opérer.
C’est ici que le “Zero ETL Integration” se met en place : AWS nous fournit dorénavant des intégrations natives entre les principaux services de “Data” utilisés dans les plateformes Data :
- Aurora Zero-ETL Integration with Redshift
- Direct Streaming Ingestion
- Auto-copy from S3
- Native Integration for DataLake
- Data Sharing & AWS Data Exchange Integration
- Built-in ML Intégration
- Athena Federated Queries
Hmm, OK. Mais encore ? Chacun de ces points permet d’adresser et surtout de simplifier certains cas d’utilisation que vous pouvez rencontrer autour de l’implémentation des plateformes Data.
Jetons-y un œil.
Aurora Zero-ETL Integration with Redshift
Considérons le cas d’utilisation suivant (un des plus répandus) : vous avez des données dans des bases de données relationnelles type “RDS Aurora” et vous souhaitez les intégrer dans votre entrepôt de données Redshift.
Avant : cela était possible en déployant des AWS Glue Jobs permettant de synchroniser les données de vos bases relationnelles vers RedShift.
Avec Zero ETL-Intégration : plus besoin de développer les jobs. AWS nous propose une intégration native entre RDS Aurora & Redshift. Les données sont répliquées en continue entre les bases relationnelles et votre entrepôt de données :
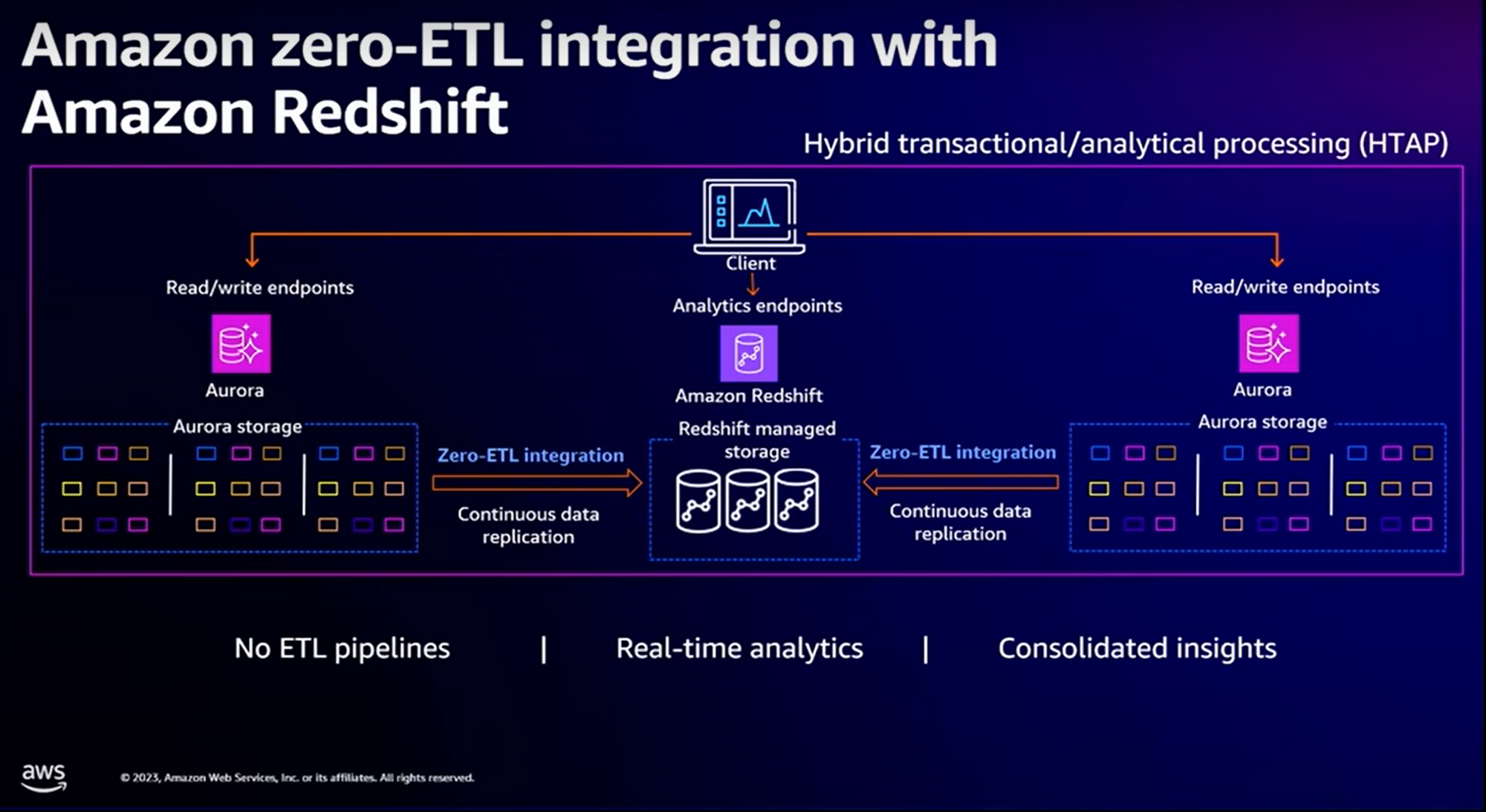
Note : le “Zero-ETL integration” est géré en mode serverless (ouf) donc pas de travail à la gestion du provisionnement de l'infrastructure nécessaire à la réplication. Il se base sur un système de “CDC” (Change Data Capture) pour répliquer les transactions faites sur les bases vers l’entrepôt de données “Redshift”.
Gardons néanmoins à l’esprit que tous les clients n’ont pas forcément des bases RDS Aurora et des clusters Redshift.
Amazon Redshift Streaming Ingestion Support
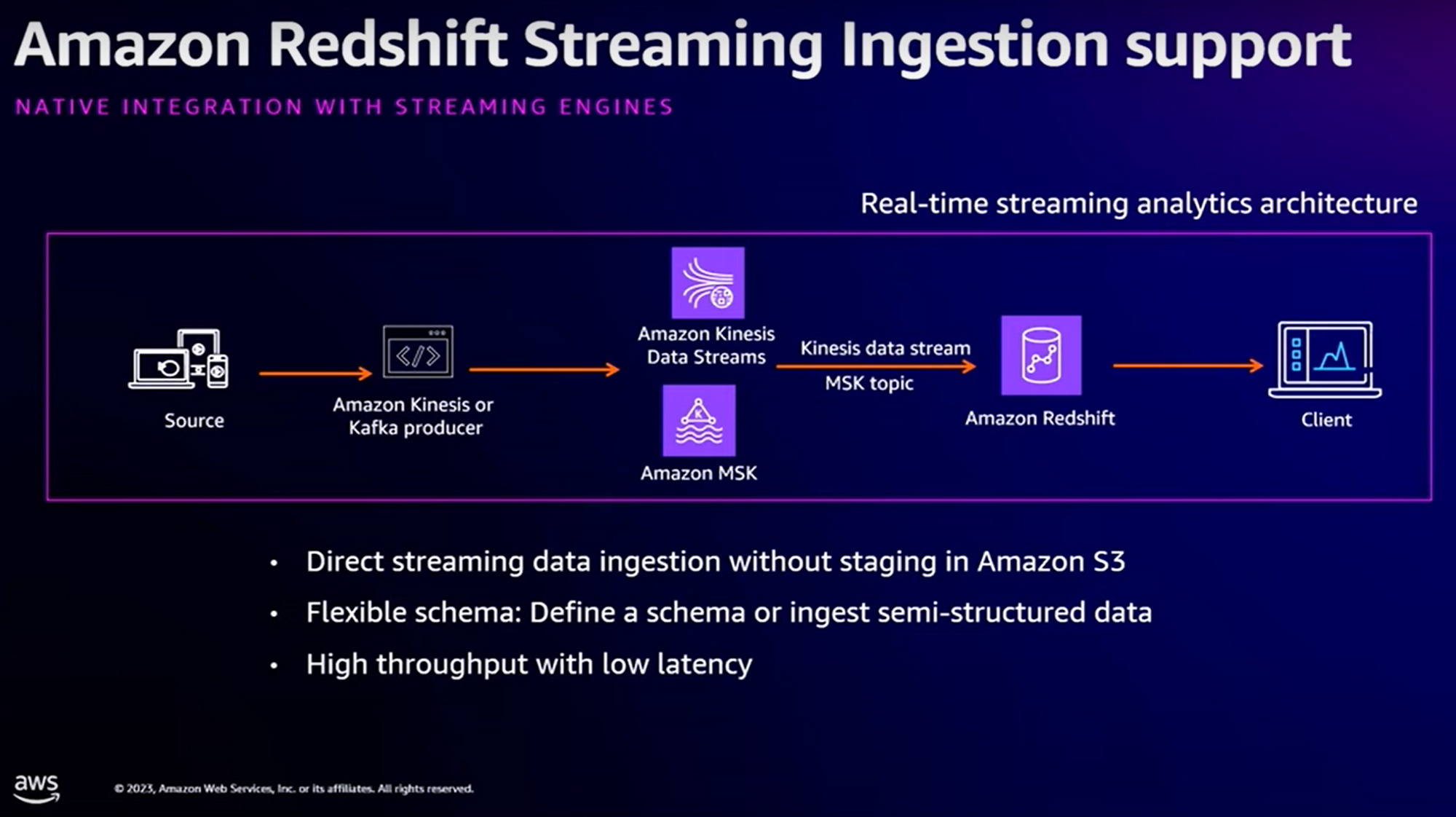
Considérons le cas d’utilisation suivant : depuis une “source”, nous captons des “streams” de modification que nous voulons déverser dans notre entrepôt de données Redshift. Nous utiliserons très certainement une stack “MSK” ou Kinesis Stream.
Avant : pour faire cela, nous étions obligés de passer par un stockage intermédiaire type S3 pour pouvoir ensuite processer les données et les injecter dans Redshift.
Avec Zero-ETL Integration, ce n’est plus nécessaire. Redshift offre désormais un système de “Real-time streaming” compatible avec MSK (Apache Kafka managé) ou Kinesis Stream.
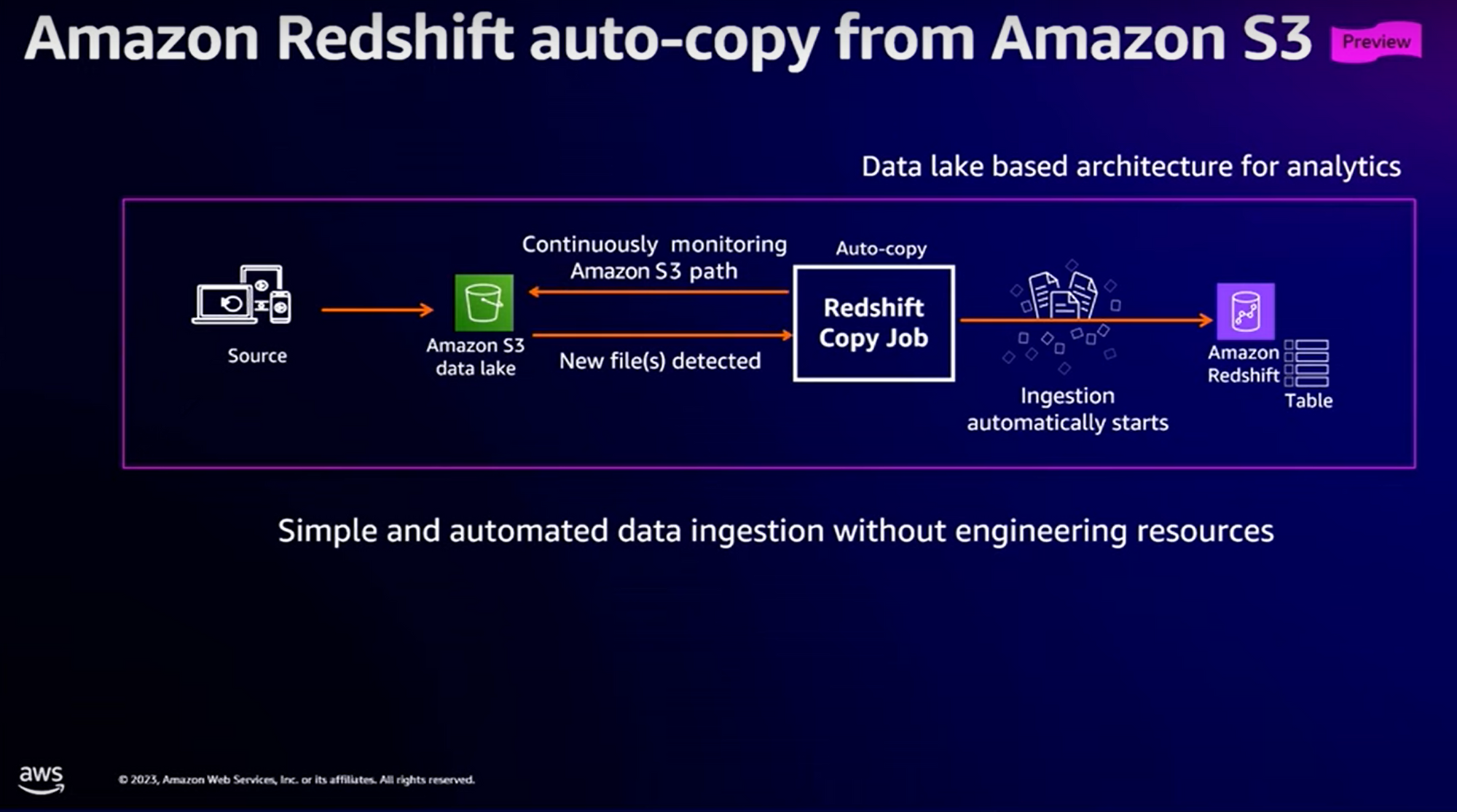
Amazon Redshift auto-copy from Amazon S3
Considérons le cas d’utilisation suivant : depuis le Data Lake (majoritairement implémenté sous la forme d’un bucket S3), nous souhaitons alimenter notre entrepôt de données Redshift.
Avant, il était nécessaire de mettre en œuvre “Redshift copy Job” et de gérer le déclenchement de ce Job de recopie des données du Data Lake vers Redshift.
Avec Zero-ETL Integration, AWS nous fournit un moyen de monitorer en temps réel l’arrivée de nouveaux fichiers sur le Data Lake et de les intégrer au fil de l’eau dans Redshift.
Amazon Redshift federated queries
Considérons le cas d’utilisation suivant : depuis votre entrepôt de données Redshift, vous souhaitez agréger des données provenant de sources diverses telles que des bases de données RDS MySQL, RDS PostgreSQL, RDS Aurora, ou même depuis votre Data Lake.
Avant, vous deviez mettre en place des “data pipeline”, en charge d’extraire les données, et les injecter dans votre Redshift. Evidemment, le déclenchement de ces jobs dépendait de la fraîcheur des données que vous souhaitiez avoir dans votre entrepôt de données.
Avec ETL-Zero Integration, AWS introduit un système de “federated queries” (pour les bases RDS) et un langage de requêtage au-dessus de votre Data lake, appelé “Amazon Redshift Spectrum”. Dans le 1er cas, les requêtes effectuées sur le Redshift sont traduites en requêtes sur vos bases RDS, et de même pour vos requêtes sur votre Data Lake.
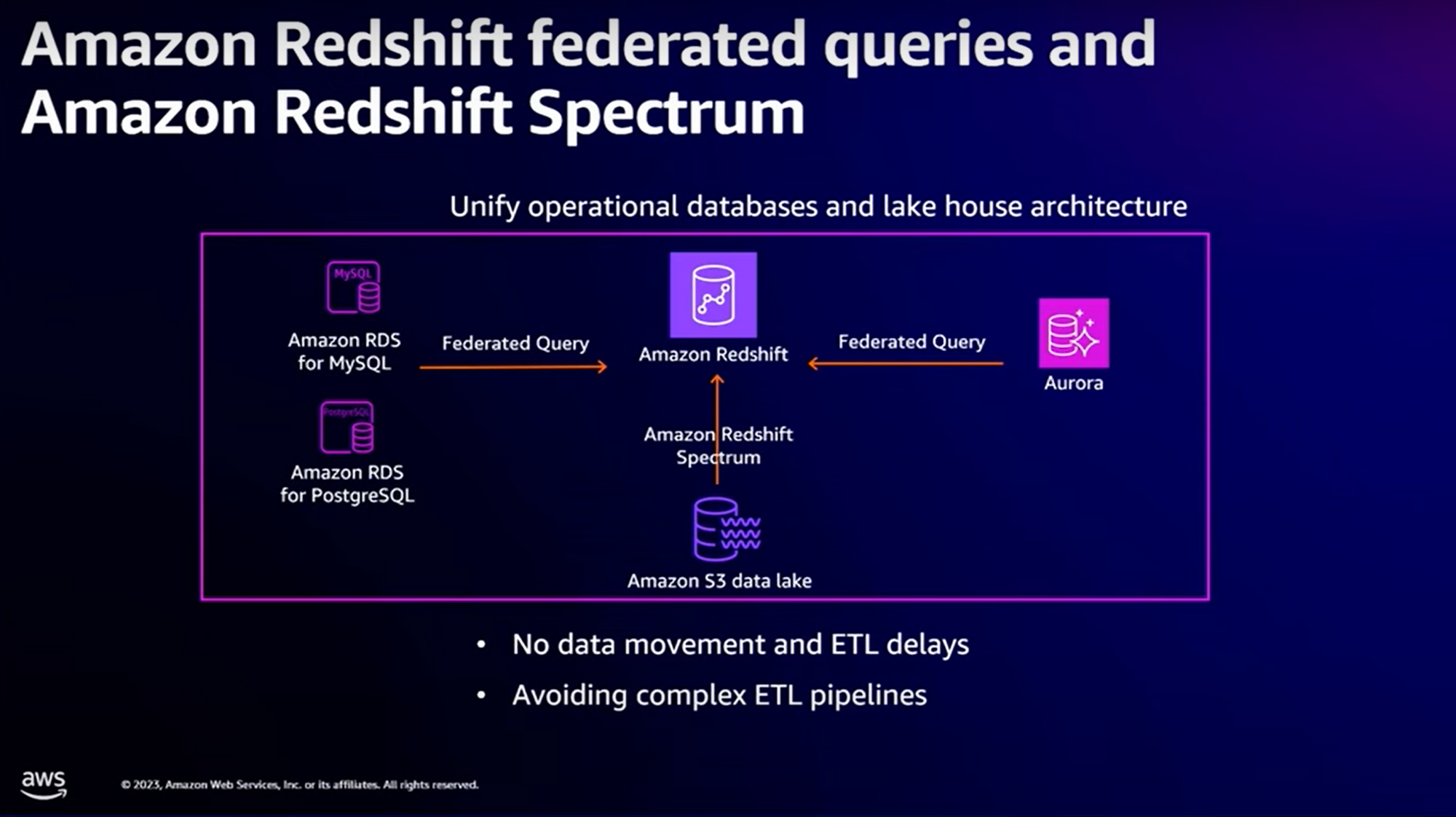
Whaoo, effectivement, ça inverse le paradigme : plus besoin de recopier les données dans l’entrepôt de données, le système de “federated queries” s’occupe de les récupérer directement depuis les bases sources.
Data Sharing
Considérons le cas d’utilisation suivant : dans une entreprise assez importante, vous avez une entité centrale et des filiales déployées dans différents pays à travers le monde. Une partie des données “analytiques” sont gérées de façon centrale. Mais pour laisser l’autonomie nécessaire à ces filiales, les données sont répliquées et enrichies par les filiales en fonction de leurs contextes propres. En plus des jobs de réplication des données, cela pose des problèmes en termes de “gouvernance”, de sécurité (accès à certaines infos) et d’homogénéité des traitements.
On se rend bien compte que la mise en œuvre d’un tel système est complexe et nécessite pas mal de travail.
Et bien avec Zero-ETL Intégration, c’est possible avec un effort moindre :
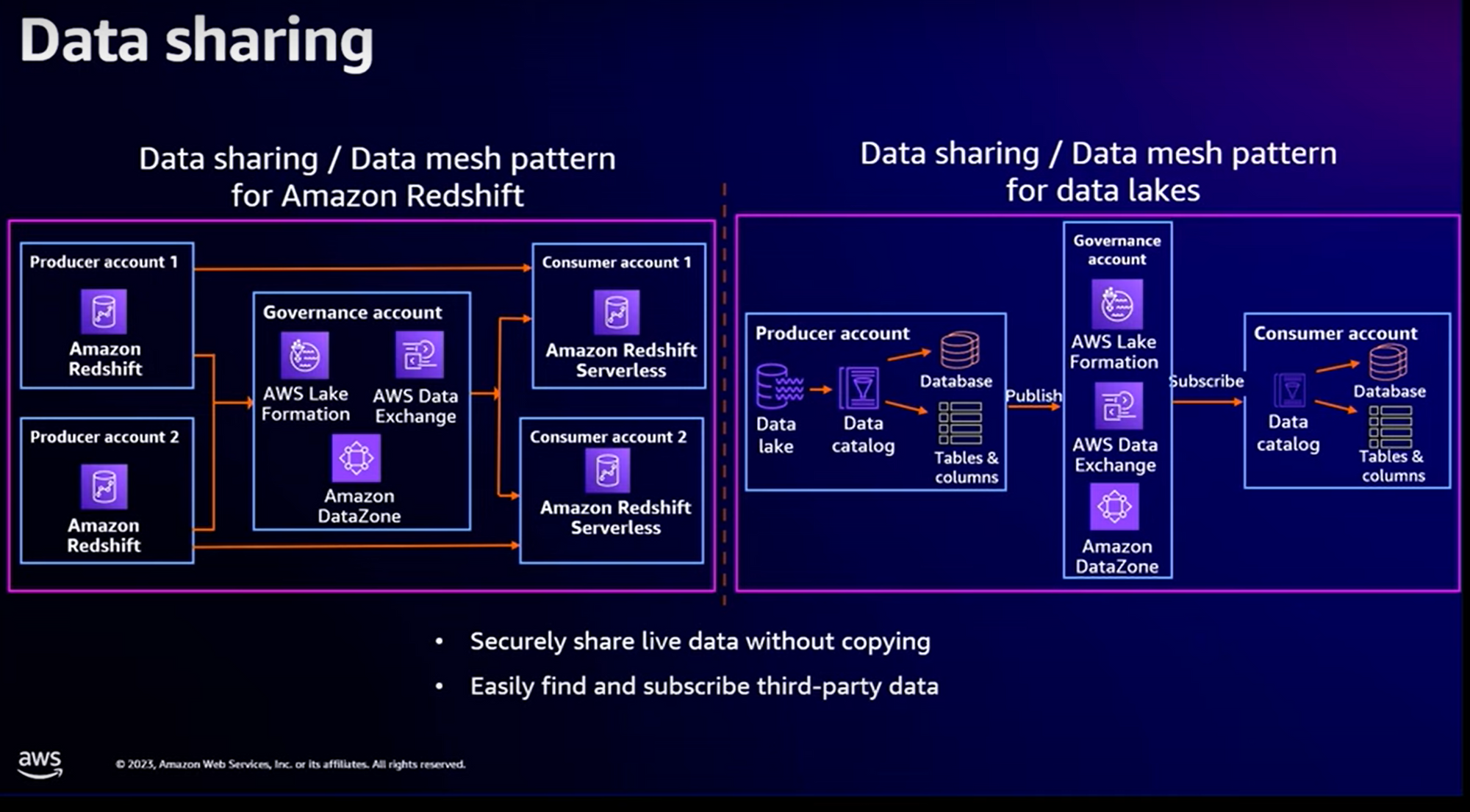
Le “Data Sharing / Data Mesh” Pattern est possible pour les entrepôts de données mais également sur les Data Lake.
A partir d’entrepôts de données (notés “Producer” sur le schéma), il est possible de partager tout ou partie des données avec d’autres entrepôts de données (notés “Consumer”) avec l’utilisation des services Amazon DataZone, AWS Data Exchange.
Pour les Data Lake, un système de publication est mis en place à travers les services Amazon DataZone et AWS Data Exchange. Les filiales n’ont plus qu’à souscrire au catalogue.
Avec la mise en place de cette gouvernance, il est possible de sécuriser l’accès à vos données d’entreprise mais également de réduire les efforts car les données ne sont plus répliquées.
Personnellement, c’est la fonctionnalité qui m’impressionne le plus.
Machine Learning (ML) Pipelines
Considérons le cas d’utilisation suivant : l'entraînement des modèles de Machine Learning se fait sur des données provenant des différentes sources. Afin de pouvoir améliorer les modèles ML, il est nécessaire de les entraîner régulièrement sur vos données.
Avant, il était nécessaire de développer des “data pipelines” depuis les sources des données et les mettre à disposition dans votre environnement de ML.
Avec Zero-ETL Intégration, vous commencez à vous en douter, plus besoin de déployer quoique ce soit. AWS nous fournit maintenant des intégrations natives avec bon nombre des sources de données utilisées dans les apprentissages des modèles ML.
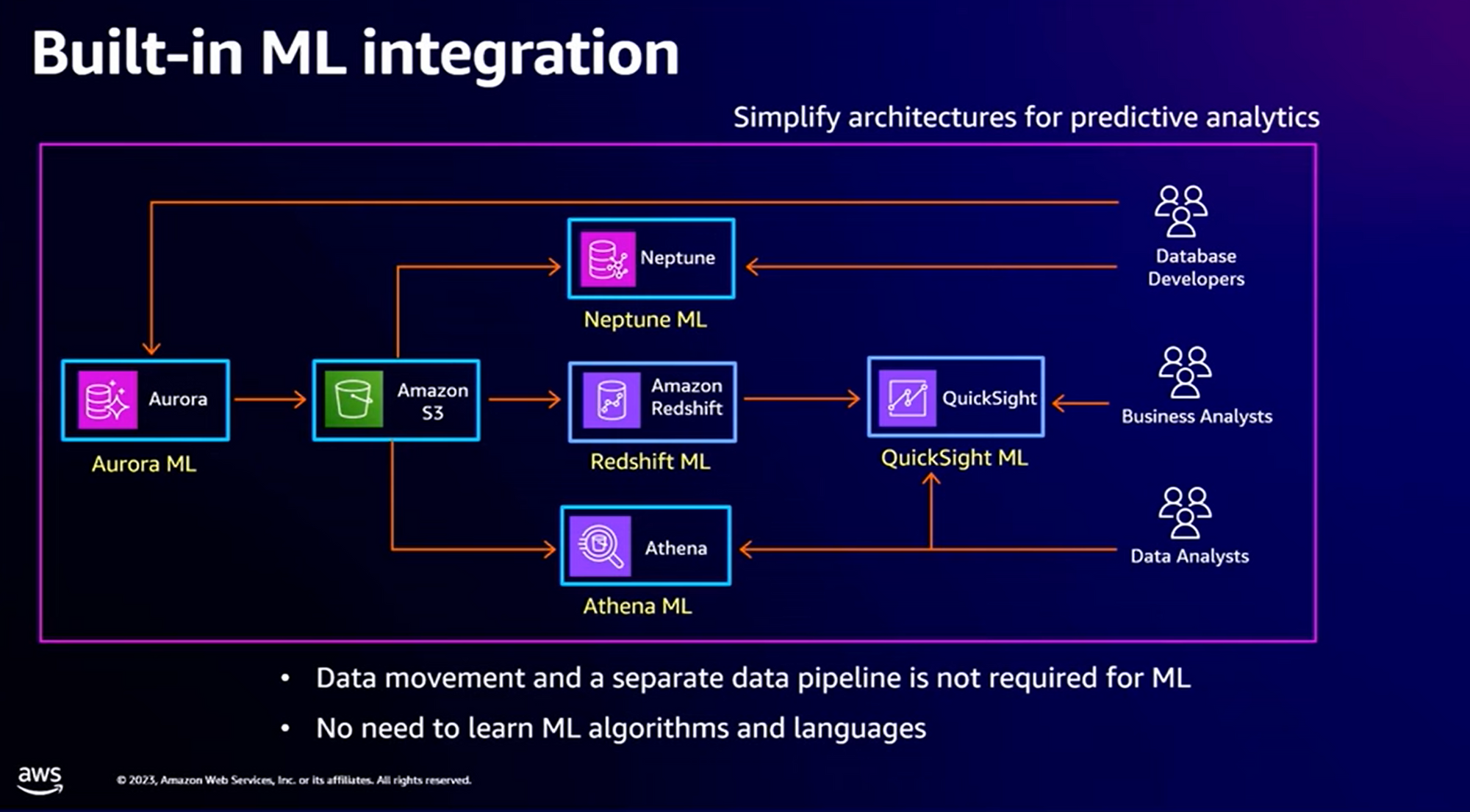
Avec les “Built-in ML”, il n’est plus nécessaire de recopier les données. Elles sont directement intégrées au niveau de la source dans laquelle elles se trouvent. D’autre part, pour les personnes qui ne sont pas expertes en ML, il est possible de pousser des “users function” dans QuickSight (qui auront donc un sens du point de vue fonctionnel) et de les intégrer dans les processus de ML. L’idée est d’ailleurs de simplifier le processus d’apprentissage des modèles ML et d’étendre la possibilité d’utilisation à des populations d’utilisateurs non spécialistes.
Unified Analysis : Athena Federated queries
Vous l’aurez noté, Zero ETL Integration simplifie de nombreux cas d’utilisation à la condition que vous soyez déjà sur AWS et que vous ayez déjà mis en place pas mal de services AWS. Dans la réalité, et particulièrement dans des cadres de “Move 2 Cloud”, on a souvent des sources hétérogènes de données, et certainement pas déjà en place sur AWS.
Et bien, Zero-ETL Integration vient avec de nouveaux types de connecteurs :
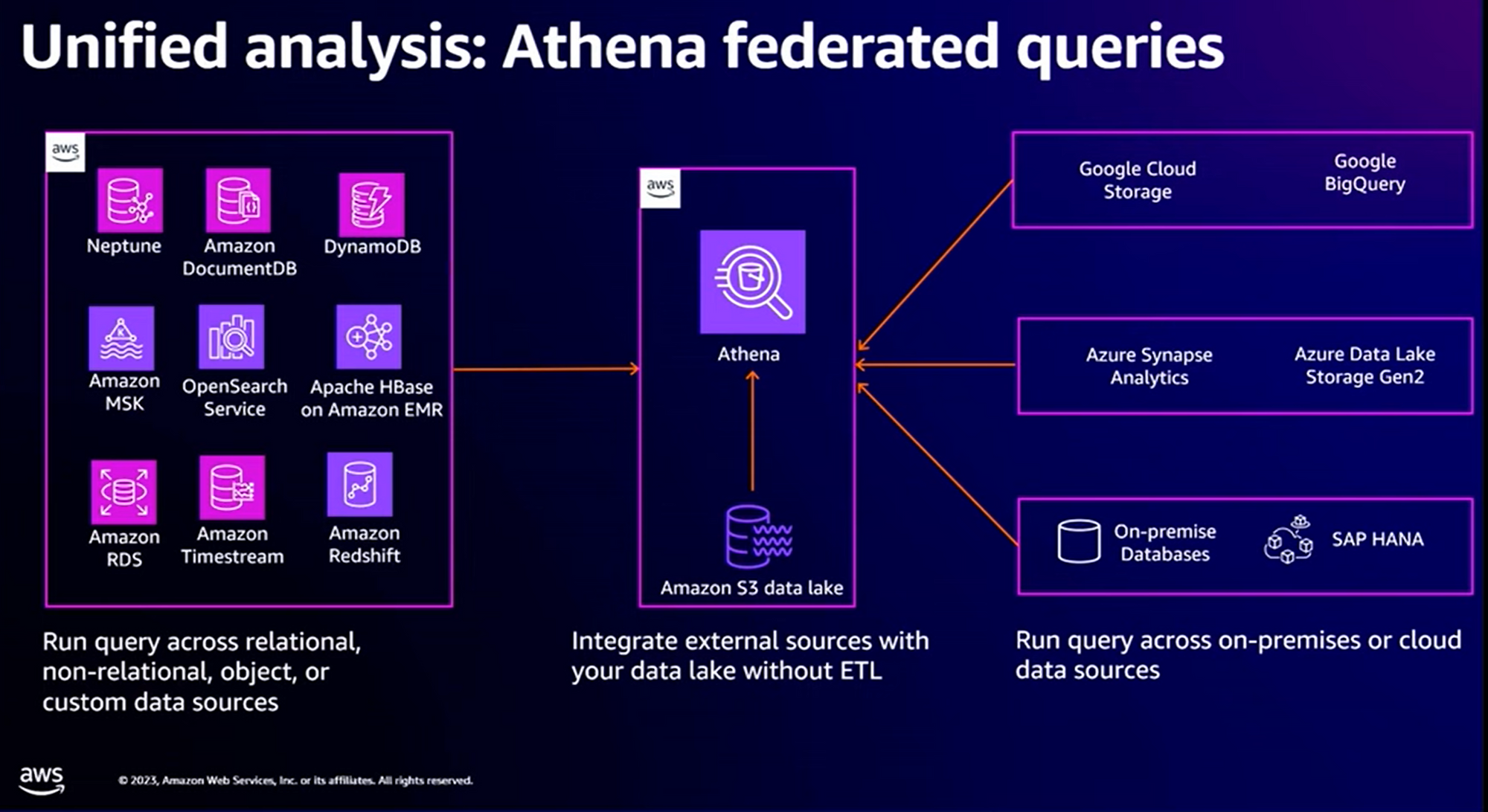
Le langage de requêtage (SQL Like) d’Athena s’enrichit dorénavant avec la possibilité d’interroger des services d’autres Cloud Providers mais, et surtout, d’interroger des bases de données on Premise.
Conclusion
Cette conférence est vraiment dense mais vaut vraiment le coup. On sent bien qu’AWS a compilé bon nombre de demandes de ses clients et à travailler à les résoudre une par une. Je vous ai mis en évidence les 7 apports du “Zero-ETL Integration”.
Notez qu’après plus d’une petite ½ heure de présentation théorique, la session continue sur des exemples d’implémentation et comment Zero ETL-Intégration simplifie l’implémentation. La dernière fait l’objet d’une démonstration en live. Chapeau aux conférenciers !
Personnellement, la partie “Data Sharing” et “Athena - Federated Queries” sont 2 des points que je vais travailler avec mon client.
L’AWS re:Invent 2023 est terminé. Cela me donne toujours l’impression d’avoir traversé une dimension parallèle où il existe une solution à tous les problèmes et dont la mise en œuvre se fait indépendamment de la notion de temps… Le retour à la réalité lundi va être dur !!
