

Le 19 septembre 2023, s’est tenue à la Cité de Congrès de Nantes, la 8ème édition du Salon de la Data (qui devient d’ailleurs cette année « Le salon de la data et de l’IA »). Au programme de cette journée : plus de 70 conférences et une dizaine d’ateliers sur divers thèmes du monde de la data tels que l’industrialisation de l’IA, la transformation et la gouvernance des données, le Data Mesh ou encore l’importance des données dans des domaines tels que la santé ou l’environnement. Ce salon gratuit, qui avait attiré pas moins de 1500 visiteurs l’année passée, s’annonçait donc comme un temps fort du secteur de la Data en France auquel Ippon participe cette année pour la première fois en tant qu’exposant.
C’est ainsi que, avec une équipe de 10 personnes remontées à bloc, nous nous sommes rendus à ce salon afin de représenter l’expertise data d’Ippon Technologies. Vous avez ainsi peut-être pu rencontrer sur notre stand ou au détour d’une conférence nos consultant.e.s data (Hector Basset, Léa Cavaree, Maxime Dublé, Nicolas Hong, Baptiste Mansire, et Hugo Vassard), nos commerciaux (Audrey Charrier et Ibrahima Sidibe-Jourdan, directeur de l’agence de Nantes), CTO (Willy Rouvre) ou recruteuse (Jennifer Huvier).
Nous vous proposons ici un résumé de quelques-unes des conférences nous ayant le plus marquées.
Marielle Graff, Mick Levy, Bastien Masse, Paul Peton, Olivier Senot : « Table ronde IAs génératives : 15+ secrets d'expert pour réussir son intégration dans l'entreprise »
Dans une table ronde animée par Mick Levy, Directeur de l'Innovation Business chez Business & Decision, 4 invités experts dans leur domaine sont conviés à partager leurs « secrets » pour une bonne intégration de l’IA générative à l’entreprise. Ont ainsi pris part à cette discussion sur ce sujet on ne peut plus actuel :
- Marielle Graff, Juriste Internet & Data chez Plasseraud IP ;
- Paul Peton, Artificial Intelligence Tech Lead chez Avanade ;
- Olivier Senot, Digital Innovation Officer chez Docaposte ;
- Bastien Masse, Philosophe et directeur général de Class’Code.
Selon un rapport du cabinet McKinsey, les IAG (IAs Génératives) devraient générer entre 2,6 et 4,4 milliers de milliards de dollars (pour comparaison, le PIB de la France s’élève en 2021 à 2,9 milliers de milliards de dollars), de quoi donner le vertige. C’est donc tout naturellement, que la discussion a démarré autour des nombreux cas d’usages possibles de l’IAG. Effectivement, que ce soit pour de l’aide au développement (à l’instar de Copilot, l’outil de Microsoft qui permet selon M. Senot aux developpeur.euses de gagner 20% de productivité), ou pour répondre à des questions sur un ensemble de documents (les données non structurées représentent en moyenne 70% des données d’une entreprise), les IAG ont leurs places toutes trouvées au sein des sociétés.
Mais elles sont également attendues sur d’autres secteurs comme l’enseignement, où elles pourrait permettre une individualisation des contenus (par exemple, la génération d’exercices personnalisés pour chaque élève selon ses difficultés). Mme Graff, juriste, souligne aussi l’aide que ces IAG pourraient apporter à toute structure manipulant des contrats. En effet, ces derniers, une fois signés, « vivent » : création d’avenants, échéances multiples, nouvelles signatures, etc., et cette forme d’intelligence artificielle pourrait tout à fait aider les professionnels à éviter de se retrouver au bout de plusieurs années avec des avenants entrant en contradictions les uns avec les autres, ou de pourquoi pas (enfin) réussir à comprendre les clauses d’un contrat d’assurance trop verbeux.

Figure 1 : Source : https://mes-reclamations.com/actualite-assurances/comprendre-contrat-assurance/
Si les cas d’usage sont légion et que selon M. Levy la majeure partie des entreprises souhaitent prendre ce virage technologique, il n’en reste pas moins que réussir à intégrer ces IAG à sa société n’est pas chose aisée. C’est le second thème abordé dans cet échange. « Mes données vont-elles être utilisées pour ré-entraîner les modèles ? » : cette simple crainte suffit à refroidir les entreprises les plus motivées. Sur ce point, M. Peton, Tech Lead IA, souligne l’importance de lire avec attention les conditions d’utilisation et qu’il existe des IAG, comme GPT sous Microsoft Azure, où il est possible de désactiver la relecture des données échangées avec l’IA.
Ce qui est sûr selon M. Senot, c’est que dans le cadre concurrentiel du monde de l’entreprise, « il faut y aller le plus vite possible, au risque de se faire distancer ». Mais il conseille toutefois de commencer petit (pour éviter le risque d’hallucinations) et avec des données non sensibles, le temps qu’un cadre législatif soit clairement défini. Il faut aussi selon lui former petit à petit toute l’entreprise. C’est ainsi que Docaposte a formé l’ensemble de ses collaborateurs.ices à poser correctement des questions à Chat GPT pour tirer pleinement partie de l’outil.
Du côté technique, pour le choix d’un modèle d’IAG dans le domaine du NLP (le fameux LLM, Large Language Model), Paul Peton conseille de privilégier un LLM raisonnablement précis mais surtout très « beau parleur ». Il met en avant faraday.dev, un outil permettant de tester différents LLM en local et invite à placer chaque LLM sur un plan pour faire le bon choix.
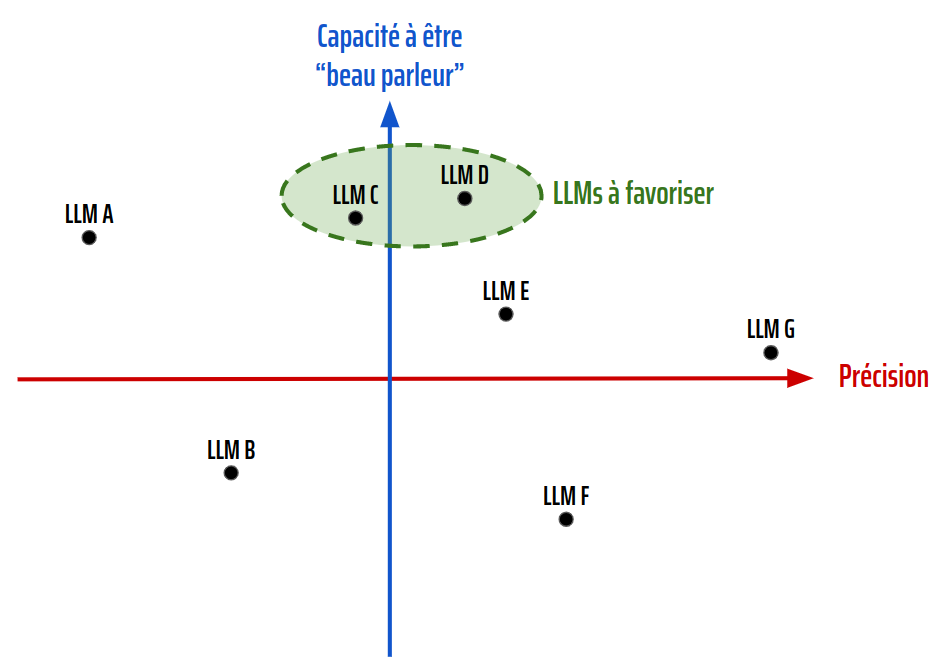
Figure 2: Proposition de représentation faite par Paul Peton, permettant de choisir les meilleurs LLMs selon leurs caractéristiques
La table ronde s’est achevée en abordant deux challenges à moyen et long termes pour l’IAG. Premièrement, en ce qui concerne le cadre légal, l’arrivée du fameux AI Act est prévue pour « les prochains mois ». Pour s’y préparer, Mme Graff, juriste, conseille de bien tout documenter, comme pour le RGPD. Enfin, sur un plan plus « politique », les modèles d’IAG d'aujourd’hui sont principalement américains : incompatibles donc pour les entreprises françaises souveraines. Pour ces sociétés, il faut donc se tourner vers les LLM Open Source et opter pour une architecture et un cloud souverain. Mais il est à noter que des concurrents européens dans la commercialisation de modèle d’IAG émergent, à l’image de Mistral AI ou de LightOn.
En conclusion : une table ronde très intéressante avec des discussions enrichissantes et qui ne peut qu’encourager Ippon à continuer à proposer des solutions utilisant l’IA générative.
Lionel Regis-Constant: « NaonedIA: Musique et IA - Les meilleurs ennemis »
Pour ce second résumé, je vous propose de rester à Nantes avec NaonedIA, une association nantaise qui a pour but de promouvoir une utilisation éthique et raisonnée de l’intelligence artificielle. Cette conférence fait un focus sur le domaine musical.
L’usage de l’intelligence artificielle dans le domaine de la musique n’est pas nouveau. En effet, les algorithmes de recommandation sont utilisés par les plateformes de streaming audio depuis un moment déjà. Il existe aussi des outils d’aide à la production de musique permettant entre autres de nombreux correctifs sonores.
Plus étonnant encore, il est possible de créer de nouveaux morceaux en copiant une voix et un style de musique. C’est comme cela qu’une IA a pu de nouveau faire chanter Kurt Cobain 29 ans après sa mort.
Depuis cette année, les cas d’usages autour de la génération de contenu dans les domaines du texte et de l’image ont explosé notamment grâce à l’arrivée des IA génératives telles que Chat GPT, Dall-E ou Midjourney. Quelques mois plus tard, c’est au tour du domaine de la musique d’être impacté.
Il y a seulement quelques semaines, le groupe Meta a annoncé le lancement d’Audio Craft : une IA générative de musique. Il suffit d’entrer un prompt en texte brut pour avoir une musique ou un son, selon une ambiance ou une rythmique donnée.

Figure 3: Image générée par Ideogram
Toutes ces nouvelles technologies et techniques amènent des problématiques inédites liées à l’éthique et à la propriété intellectuelle :
À qui appartient la voix générée avec l’IA ? Qui est rémunéré (si une rémunération est prévue) ?
Si je crée une musique : m’appartient-elle ? Appartient-elle à la société qui a développé l’IA ? Aux artistes dont l’IA s’est inspirée ?
Si tout le monde peut générer de la musique : que vont devenir les artistes ? Aurons-nous encore besoin de leur talent et de leur créativité ?
Il n’y a pas de réponse toute prête puisque aucune législation ne cadre l’explosion des usages de ces intelligences artificielles. La conférence nous amène plutôt à nous questionner sur ces problématiques.
Pour aiguiller notre réflexion, le président de l’association NaonedIA nous replonge dans le passé au moment de l’avènement de la photographie. A cette époque, de nombreux peintres ont vu leur métier menacé. Certains peintres ont effectivement disparu, d’autres ont su tirer profit des nouvelles technologies. Avec le recul que nous avons, nous voyons bien que le métier de peintre n’a pas disparu. Il a évolué.
En conclusion : Selon vous, l’IA est-elle une menace ou une opportunité pour le monde de la musique ? Je vous laisse méditer là-dessus.
Thomas Pocreau : « Fighting Fraud with Machine Learning at BlaBlaCar »
Lors de son interview, Thomas nous a présenté comment les équipes de BlaBlaCar ont été outillées pour lutter contre la fraude qui est malheureusement de plus en plus présente sur leur plateforme.
Le premier conseil qu'il nous a donné est de commencer simplement. Même s'ils étaient convaincus de l'efficacité d'un modèle de machine learning pour mettre en lumière les comportements relevant de la fraude, il y a certainement d'autres actions permettant de limiter la fraude qui sont moins coûteuses à mettre en place (par exemple, vérification des pièces d'identité des utilisateurs, 2FA). Celles-ci sont à prioriser pour la roadmap par rapport au machine learning qui, en plus d'être coûteux, demande un effort continu.
Ce premier principe mène au second, qui est de se reposer sur des experts métiers. En effet, ceux-ci ont l'habitude de traiter et repérer ces comportements de fraude. Thomas et son équipe ont donc commencé par implémenter des règles simples dictées par ces experts pour détecter la fraude.
Une fois que toutes les mesures simples à mettre en place ont été appliquées, ils ont pu commencer à faire du machine learning. Encore une fois, ils ont appliqué le premier principe en choisissant un modèle explicable plutôt qu'une boîte noire. Cela permettait d'expliquer les décisions de l'algorithme, renforçant ainsi la confiance des utilisateurs en leur outil. Une fois la confiance établie, ils ont pu passer sur un modèle XGBoost.
Même maintenant que leur modèle tourne sans accroc, il y a toujours des humains au cœur du processus de lutte antifraude. Ils continuent à traiter :
-
les cas où un utilisateur se plaint d'avoir été bloqué pour cause de fraude ;
-
les cas où la classification est mitigée.
De plus, les fraudeurs s'adaptent et de nouveaux comportements émergent. L'équipe de Thomas continue d'implémenter les règles dictées par les experts pour donner plus d'entrants au modèle.
Enfin, Thomas a terminé par nous partager ces conseils pour le développement ML :
- Entraîner ses données sur les données de production ;
- Ne pas utiliser de notebook ;
- Ne pas faire d'entrainement sur le poste du développeur, mais via une CI.
Antoine CHOFFEL & Charlotte MAILLARD : « Le green data by design, un atout pour accélérer la décarbonation des entreprises »
La data est-elle un accélérateur pour la décarbonation des entreprises ?
C’est la question qui a animé Antoine et Charlotte tout au long de leur présentation.
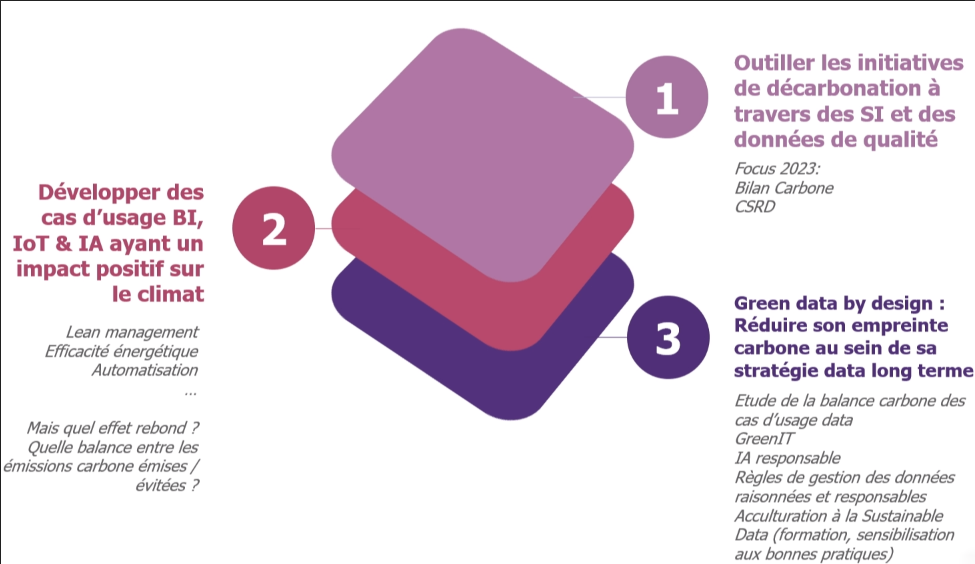
Figure 4: Les trois problématiques majeures des entreprises en matière de décarbonatio
La data peut intervenir sur plusieurs sujets en matière de décarbonation des entreprises. Reporting de bilan carbone, analyse de la quantité de déchets de l’entreprise, maintenance prédictive des équipements, optimisation de la consommation d’énergie, etc.
Avant de rentrer dans le vif du sujet, faisons un petit rappel du modèle des trois scopes permettant de classifier les différents types d'émission carbone.
Scopes d'émissions carbone et les cas d’usage data :
- scope 1 - Émissions directes : regroupe les émissions de gaz à effet de serre directement liées à la fabrication du produit. Par exemple, si la création d’un produit a nécessité la combustion de carburants ou l'émission de CO2, ces émissions font partie du scope n°1. Ce sont des émissions directes.
- scope 2 - Émissions indirectes : regroupe les émissions de gaz à effet de serre liées aux consommations d’énergie nécessaires à la fabrication du produit. Par exemple, pour fabriquer un produit, il faut alimenter l’usine en électricité. La production de cette électricité à émis des gaz à effet de serre qui sont comptabilisés dans le scope n°2. Ce sont des émissions indirectes.
Cas d’usage data : consommation d’électricité pour le fonctionnement du cas d’usage.
Ordre de grandeur : la quantité de CO2 émise par l’entraînement d’une IA de NLP est autant consommatrice que 5 voitures durant tout leur cycle de vie.
- scope 3 - Autres émissions indirectes : Regroupe toutes les autres émissions qui ne sont pas liées à la fabrication du produit, mais à d’autres étapes du cycle de vie du produit (approvisionnement, transport, utilisation, fin de vie, etc.). Par exemple, les émissions de gaz à effet de serre liés à l'extraction des matières premières, leur transformation, leur transport sont comptabilisées dans le scope n°3.
Pour information, depuis le 1er janvier 2023, la réglementation oblige les entreprises à prendre en compte le scope n°3 dans leur bilan carbone. Le scope n°3 représente une grand majorité des émissions carbone d’une entreprise (jusqu’à 70 - 90%).
Charlotte et Antoine ont été amenés à travailler sur un cas d’usage de ventilation intelligente pour un de leur client.
Objectif : renouvellement de l’air et rafraîchissement du bâtiment en s’adaptant en temps réel à la présence dans le bâtiment, à la pollution intérieure et extérieure et à la météo.
Ils sont allés plus loin que le développement de ce cas d’usage en analysant sa propre empreinte carbone sous trois axes :
1. Fabrication du matériel et développement de la solution
Fabrication : ordinateur, connectique réseaux, capteurs (scope n°3)
Développement : codage de l’algorithme, architecture, flux de données (scopes n°2 et n°3)
2. Usage
Fonctionnement des serveurs, génération/collecte/stockage/traitements des données (scope n°2)
3. Fin de vie
Matériel : recyclage, incinération, enfouissement
Données / code : archivage, transformation (scopes n°2 et n°3)
De la même manière que l’on essaye toujours d’estimer la rentabilité économique d’une solution (ROI), dans une démarche green on évalue également la rentabilité carbone.
Autrement dit, la dépense carbone liée à l’ensemble du cycle de vie de la solution est-elle moins importante que la dépense carbone économisée grâce à la solution ?
Pour répondre à cette question, il faut pouvoir se baser sur des scénarios de référence, calculer et comparer.
Afin de réduire l’empreinte carbone des cas d’usages sur le long terme, Charlotte et Antoine proposent la démarche « Green data by design ».
L’objectif est de donner une place systématique à la décarbonation dans les sujets data de l’entreprise dès le début et tout au long des projets.
Cela passe par définir les bonnes pratiques de sobriété dès la conception, systématiser la « balance carbone » dans les décisions, appliquer les règles de sobriété des données tout au long du cycle de vie du cas d’usage (dont la fin de vie en mettant notamment en place des règles de purge des données) et piloter l’empreinte carbone des cas d’usage au fil du temps.
On peut lister quelques astuces de sobriété :
- Unicité des données : ne pas dupliquer inutilement les données
- Minimiser la génération et la collecte des données en se focalisant sur les données à haute valeur ajoutée
- Privilégier des solutions de stockage froides quand la donnée est peu utilisée
- Optimiser le code pour limiter la consommation énergétique
- Gérer la fin de vie des données : purges, règles de rétention …
« 52 % des données mondiales stockées par les entreprises sont redondantes, obsolètes et inutiles. Ce qui équivaut à 6.4 millions de tonnes de CO2 émis en 2020 »
source : Veritas Technologies
Pour conclure, afin d’adresser correctement l’enjeu de décarbonation au sein de l’entreprise, il est important de mettre à jour des rôles au sein de son organisation en ajoutant le volet green. Par exemple, le data owner / steward devra tenir compte de l’impact carbone des produits data et modifier la gouvernance data en conséquence en ajoutant des règles et métriques de sobriété. \
Conclusion
Les conférences, exposants et échanges que nous avons eus sur notre stand nous ont permis de prendre le pouls du monde de la data en cette rentrée 2023. Les sujets abordés nous ont offert un véritable tour d’horizon, bien que nous aurions apprécié un plus grand nombre de conférences orientées « technique » que « haut niveau ».
Nous sommes toutefois ressortis enrichis de cette journée au Salon de la Data et de l’IA de Nantes, précédant de quelques semaines le salon Bigdata & AI Paris au Palais des congrès. Nous avons également été présents à cet événement, idéal afin de rester à l’écoute des nouveautés, puisqu’il s’agissait sans doute là du plus important rendez-vous data en France, celui-ci regroupant chaque année environ 15 000 participants.
[Lien vers notre résumé du salon de la data 2022]



