
Plongée dans l'Univers des Vecteurs Sans Se Noyer !
Le monde du Big Data et de l'analyse de données est en constante évolution, grâce à des innovations qui émergent sans cesse pour aider les entreprises et les chercheurs à gérer et analyser des volumes de données toujours plus importants. Parmi ces innovations, nous retrouvons les bases de données vectorielles qui ont récemment gagné en popularité. En effet, elles offrent de nouvelles possibilités ainsi que des avantages considérables pour ceux qui cherchent à exploiter la puissance des données.
Dans cette série de trois articles, nous allons plonger dans cet univers passionnant et d'actualité, en explorant les multiples facettes des bases de données vectorielles ainsi que leur impact sur différents domaines tels que les Large Language Models (LLM) et autres systèmes d'IA génératives.
Cet article est consacré à la présentation des fondements théoriques des bases de données vectorielles, leurs avantages, ainsi que différents cas d’usage.
Dans les articles suivants, nous découvrirons quelques exemples pratiques d'implémentations populaires. Nous examinerons également comment les bases de données vectorielles interagissent avec des modèles de langage tels que ChatGPT et Bard AI, et comment les systèmes IA génératives pourraient tirer parti de ces technologies pour améliorer leurs performances. Enfin, nous mettrons en lumière les avantages et les défis potentiels associés à ces bases de données, afin de vous donner une vision complète et équilibrée de leur potentiel.
Alors, sans plus attendre, entrons dans le vif du sujet et découvrons ensemble les secrets des bases de données vectorielles et leur rôle dans le futur de l'analyse de données et de l'intelligence artificielle.
Qu'est-ce qu'une base de données vectorielle ?
Une base de données vectorielle, également connue sous le nom de Vector-Based Database Management System (VBDBMS), est une solution de stockage et de gestion de données qui repose sur la représentation de données sous forme de vecteurs dans un espace multidimensionnel.
Cette approche diffère des bases de données relationnelles ou NoSQL traditionnelles, en ce qu'elle permet d'effectuer des recherches et des analyses basées sur la similarité et la proximité entre les éléments de données plutôt que sur des attributs spécifiques ou des valeurs clés.
Pour mieux comprendre ce concept, prenons l'exemple d'une application de recommandation de films. Dans une base de données relationnelle, les films seraient stockés avec des attributs tels que le titre, le genre, l'année de sortie et les acteurs.
Pour recommander des films similaires, il faudrait alors effectuer des requêtes complexes basées sur la combinaison de ces attributs.
SELECT
film2.titre
FROM
films film1
JOIN
films film2 ON film1.genre = film2.genre AND film1.annee_sortie = film2.annee_sortie
WHERE
film1.titre = 'Le titre du film' AND film1.titre <> film2.titre AND...? 🤔;
En revanche, dans une base de données vectorielle, chaque film serait représenté par un vecteur unique dans un espace multidimensionnel, où les dimensions pourraient correspondre à des caractéristiques telles que le genre, le style, les émotions ou les thèmes.
Exemple :
The Dark Knight:(0.01359, 0.00075997, 0.24608, …, -0.2524, 1.0048, 0.06259)
The Prestige:(0.01396, 0.11887, -0.48963, …, 0.033483, -0.10007, 0.1158)
Pulp Fiction:(-0.24776, -0.12359, 0.20986, …, 0.079717, 0.23865, -0.014213)
The Grand Budapest Hotel:(-0.35609, 0.21854, 0.080944, …, -0.35413, 0.38511, -0.070976)
Les films similaires se trouveraient alors à proximité les uns des autres dans cet espace, les requêtes par similarité pourraient être effectuées simplement en recherchant les vecteurs les plus proches.
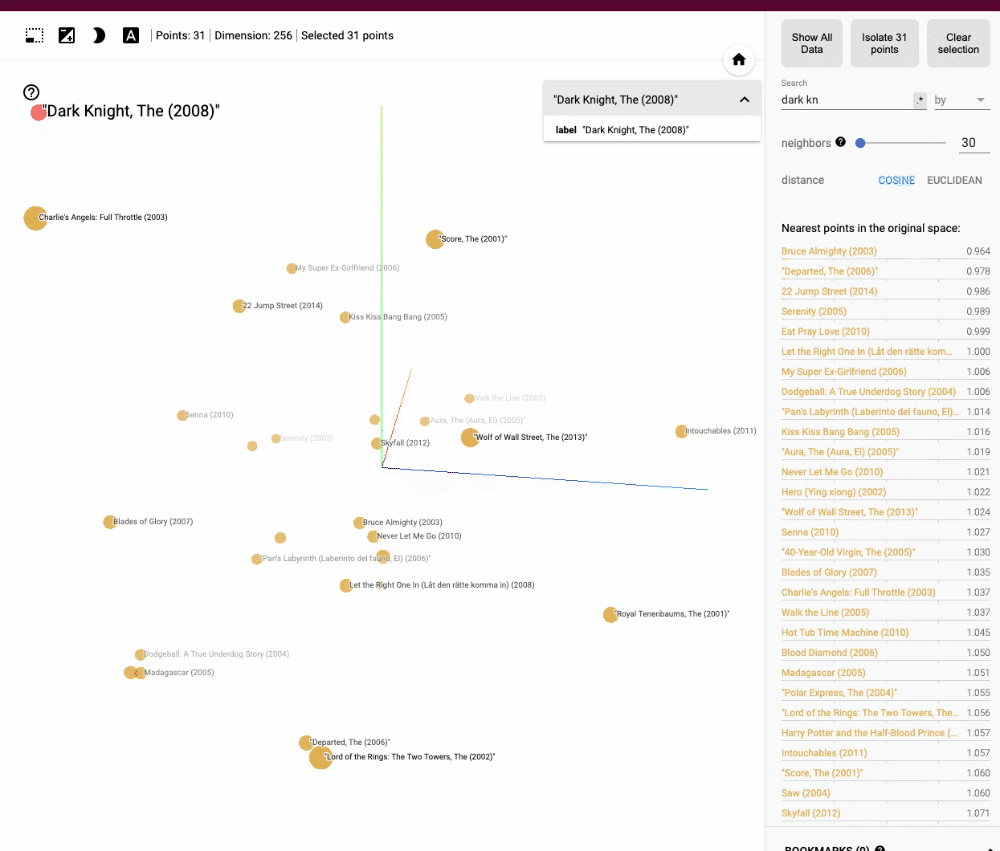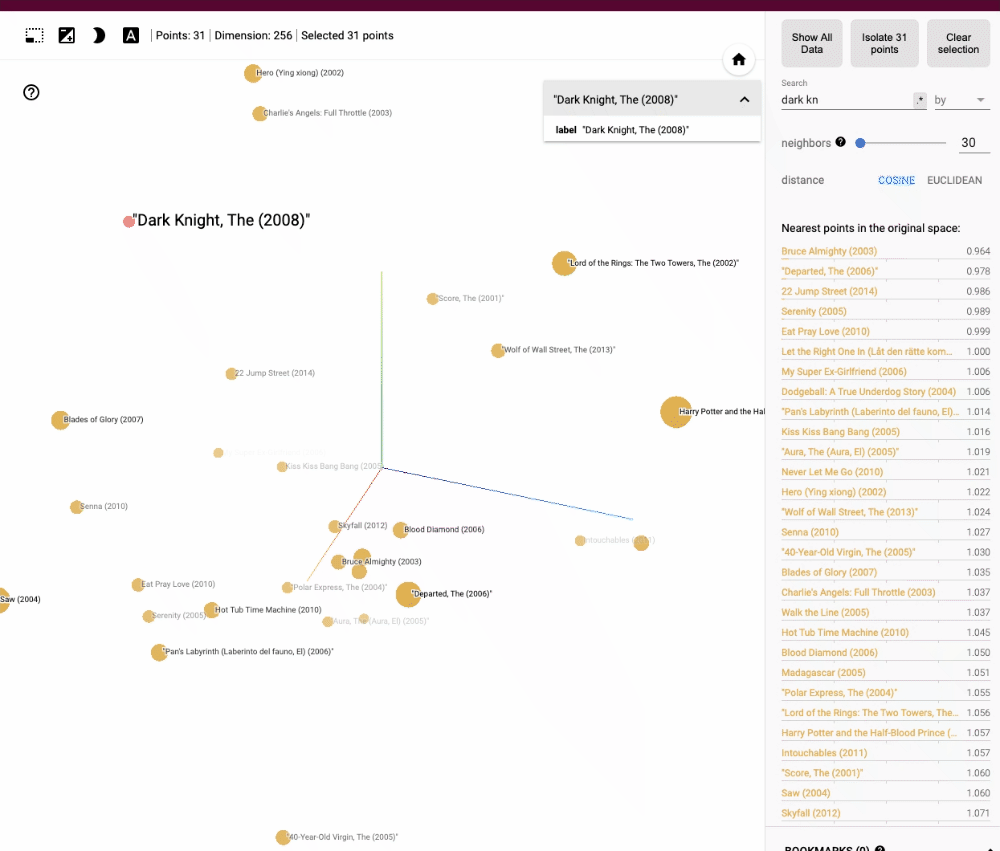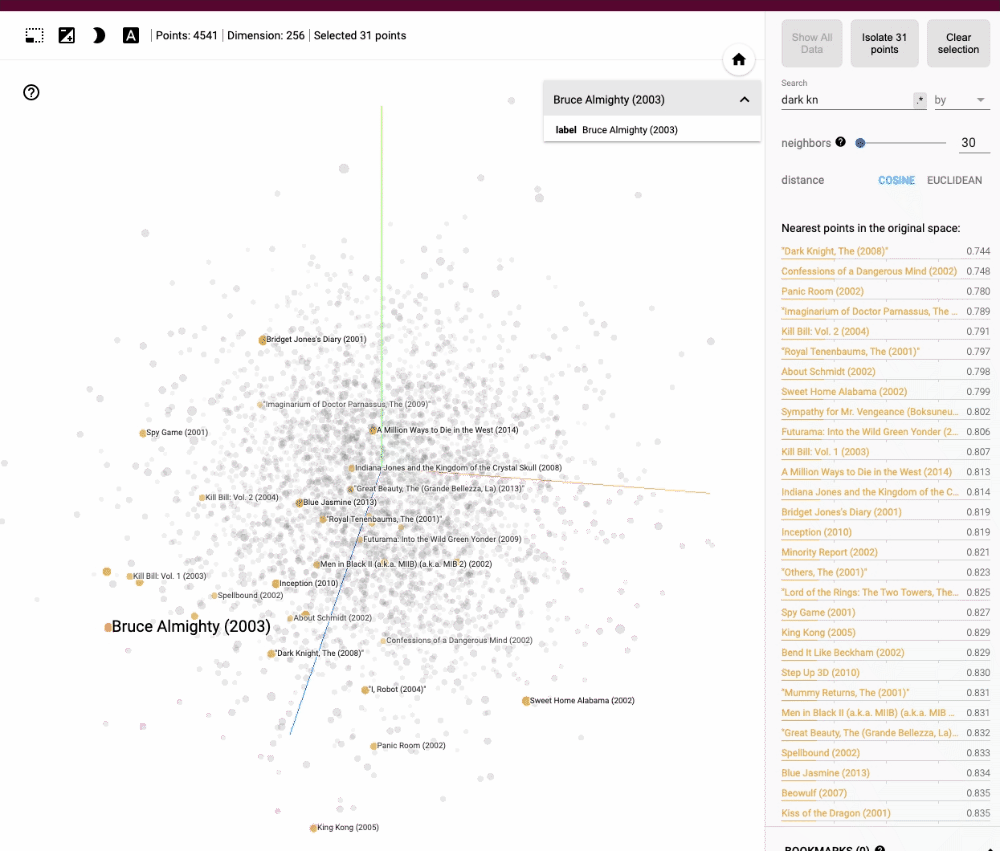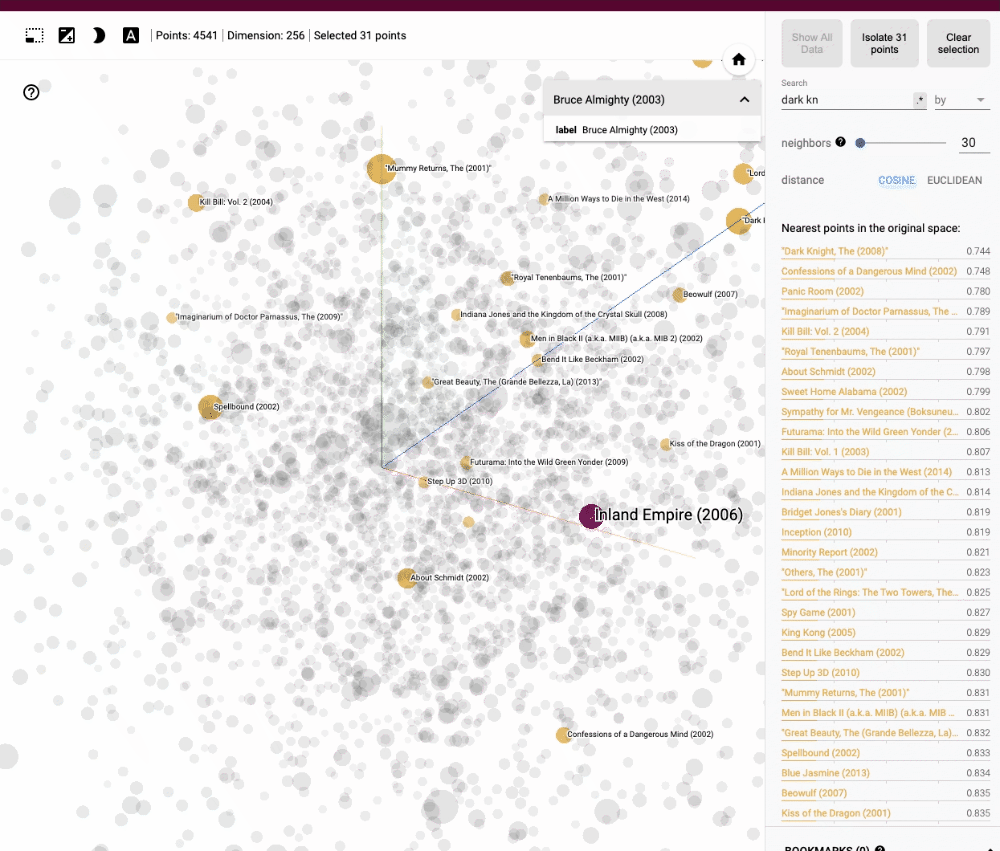
La représentation vectorielle des données permet de réaliser des opérations de recherche et d'analyse efficaces et rapides, même sur de très grands ensembles de données. Les bases de données vectorielles tirent parti de diverses techniques de recherche approximative des plus proches voisins (ANN), telles que les arbres k-d (que nous verrons plus en détail dans un prochain article), les forêts de hachage aléatoire ou les réseaux de neurones auto-organisateurs, pour accélérer les requêtes par similarité et les opérations d'analyse.
En résumé, une base de données vectorielle est une solution de stockage et de gestion de données innovante qui repose sur la représentation vectorielle des données dans un espace multidimensionnel. Comme nous allons le voir, cette approche offre de nombreux avantages, tels que des recherches par similarité rapides et efficaces, une meilleure gestion des données de grande dimension et une compatibilité naturelle avec diverses applications liées à l'intelligence artificielle et au traitement du langage naturel.
Pourquoi utiliser une base de données vectorielle ?
Les bases de données vectorielles présentent de nombreux avantages par rapport aux systèmes de gestion de base de données traditionnels, en particulier lorsqu'il s'agit de gérer des données complexes, de grande dimension et de recherche par similarité. Voici quelques-uns des principaux bénéfices des bases de données vectorielles :
Recherche par similarité efficace:
L'un des principaux atouts des bases de données vectorielles est leur capacité à effectuer des recherches basées sur la similarité et la proximité entre les éléments de données de manière rapide et efficace. Grâce à la représentation vectorielle des données et aux techniques de recherche approximative des plus proches voisins, les bases de données vectorielles peuvent identifier des éléments similaires en un temps réduit, même dans de très grands ensembles de données
Scalabilité :
Les bases de données vectorielles sont conçues pour gérer de grandes quantités de données et peuvent être facilement dimensionnées pour répondre aux besoins croissants en matière de stockage et de traitement. Elles sont particulièrement adaptées aux applications de Big Data et d'analyse de données, où la gestion de vastes ensembles de données est cruciale.
Flexibilité :
Les bases de données vectorielles offrent une grande flexibilité pour représenter et gérer des données complexes et de grande dimension. Elles permettent de stocker et d'interroger des données issues de diverses sources et formats, et sont capables de gérer des données non structurées, telles que des images, du texte ou des séquences génomiques.
Interopérabilité avec l'intelligence artificielle :
Les bases de données vectorielles sont naturellement compatibles avec les applications d'intelligence artificielle et de traitement du langage naturel, car elles utilisent des représentations vectorielles similaires à celles employées par les modèles de machine learning. Cette interopérabilité facilite l'intégration des bases de données vectorielles dans les pipelines de traitement et d'analyse des données basées sur l'IA.
Personnalisation des requêtes :
Les bases de données vectorielles permettent de personnaliser les requêtes en fonction des besoins spécifiques de l'utilisateur ou de l'application. Par exemple, il est possible de pondérer certaines dimensions pour accorder plus d'importance à certains aspects lors de la recherche par similarité, ou de définir des métriques de distance personnalisées pour mieux répondre aux exigences du domaine d'application.
Amélioration continue :
Les bases de données vectorielles peuvent bénéficier de l'évolution des algorithmes de recherche approximative des plus proches voisins et des techniques d'apprentissage automatique pour améliorer continuellement leur performance et leur précision. Cela permet aux bases de données vectorielles de s'adapter et de rester pertinentes face à l'évolution des besoins et des technologies.
En somme, les bases de données vectorielles offrent une série d'avantages considérables en matière de recherche par similarité, de scalabilité, de flexibilité, d'interopérabilité avec l'IA, de personnalisation des requêtes et d'amélioration continue. Ces bénéfices les rendent particulièrement attrayantes pour les applications liées à l'analyse de données, au Big Data et à l'intelligence artificielle, où la gestion et l'analyse de données complexes et de grande dimension sont cruciales.
Enfin, l'adoption croissante des bases de données vectorielles conduit à une amélioration constante des outils, des bibliothèques et des infrastructures associées, ce qui renforce encore leur pertinence et leur efficacité dans un large éventail de domaines et d'applications. À mesure que de nouvelles techniques et approches émergent, les bases de données vectorielles continueront à évoluer et à s'adapter pour offrir des solutions toujours plus performantes et adaptées aux besoins des entreprises et des chercheurs.
Quelques use cases des bases de données vectorielles
Maintenant que nous avons évoqué les bénéfices des bases de données vectorielles, il est temps de nous plonger dans les cas d’usage concrets de cette technologie. Je vais partager avec vous quelques exemples de domaines où les bases de données vectorielles sont particulièrement utiles, en mettant en lumière leur adaptabilité et leur pertinence dans de nombreuses applications.
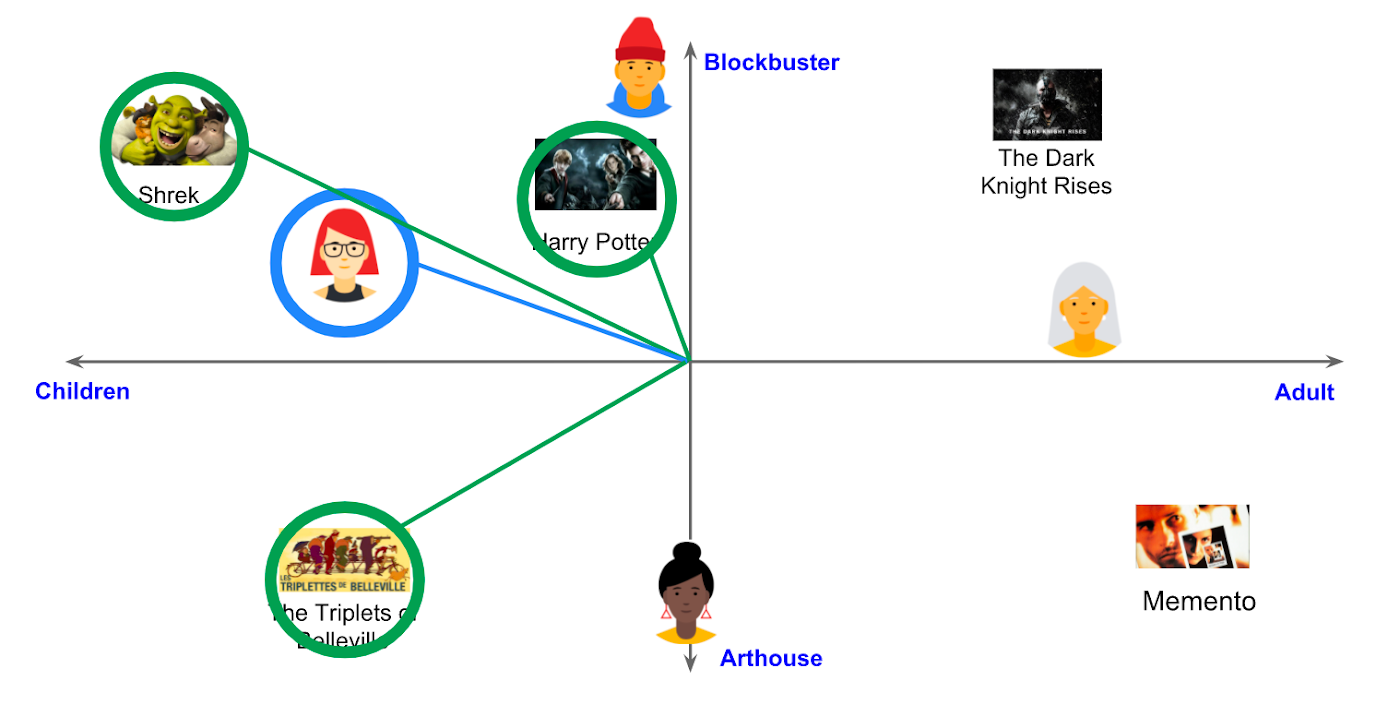
- Systèmes de recommandation : Vous avez sans doute déjà utilisé un système de recommandation, que ce soit pour découvrir de nouveaux films sur Netflix, des articles intéressants sur le blog Ippon, ou des produits sur Amazon. Comme nous l’avons vu précédemment, les bases de données vectorielles jouent un rôle clé dans ces systèmes en facilitant la recherche d'éléments similaires et en permettant la génération de recommandations personnalisées.
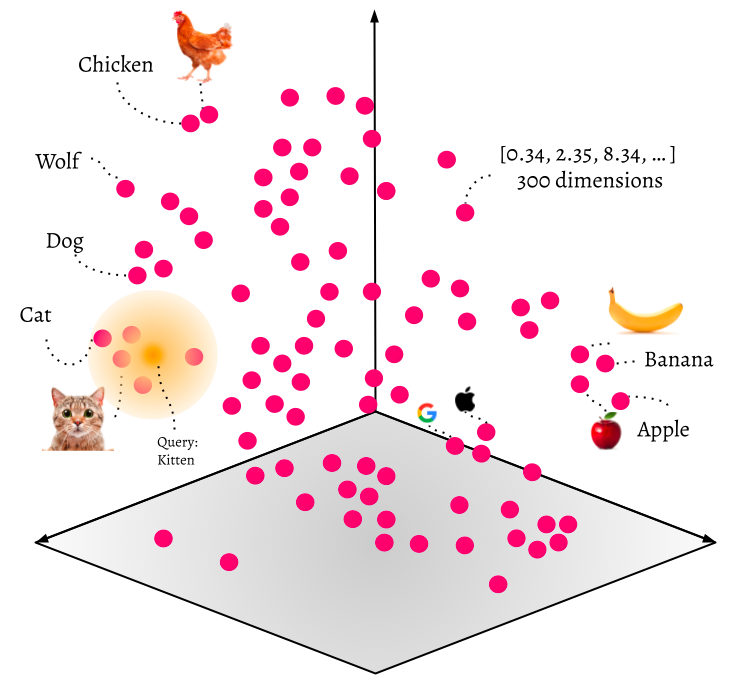
- Recherche d'images : Vous souvenez-vous de la dernière fois que vous avez utilisé la recherche inversée d'images sur Google ? Les bases de données vectorielles sont particulièrement efficaces pour gérer ce genre de tâches. Elles permettent de stocker et d'interroger des caractéristiques visuelles sous forme de vecteurs, facilitant ainsi la recherche d'images similaires en se basant sur la similarité visuelle.

- Traitement du langage naturel (NLP) : Les bases de données vectorielles sont également très utiles dans le domaine du traitement du langage naturel. Elles permettent de représenter des mots, des phrases ou des documents sous forme de vecteurs, ce qui facilite la recherche et l'analyse basées sur la similarité sémantique. Des applications telles que la classification de textes, l'analyse de sentiments et la détection d'anomalies peuvent grandement bénéficier de cette technologie.
- Bioinformatique : La bioinformatique est un autre domaine où les bases de données vectorielles ont beaucoup à offrir. En représentant les séquences génétiques ou les structures protéiques sous forme de vecteurs, elles permettent aux chercheurs d'identifier des similarités, des motifs et des relations fonctionnelles entre différentes molécules. Cela peut grandement aider dans la découverte de nouveaux biomarqueurs, la conception de médicaments ou l'analyse phylogénétique.
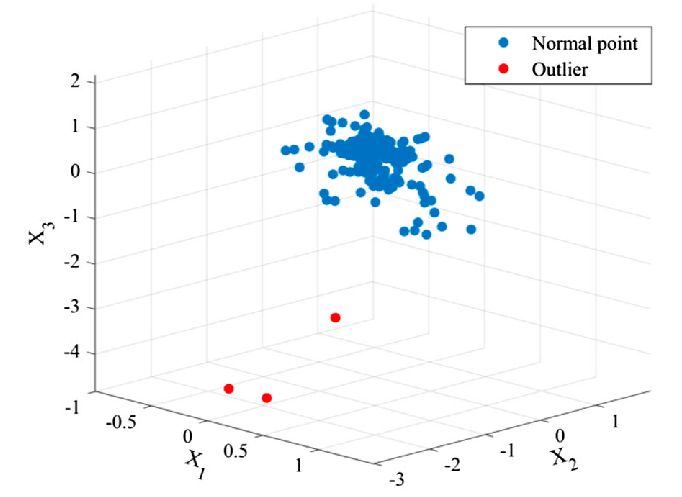
- Détection d'anomalies : Les bases de données vectorielles sont également très utiles pour détecter des anomalies ou des outliers dans des ensembles de données complexes. En représentant les données sous forme de vecteurs et en identifiant les points isolés ou éloignés des autres éléments, elles permettent de repérer des comportements inhabituels, des erreurs ou des fraudes dans des domaines tels que la cybersécurité, la finance ou la maintenance prédictive.
En résumé, les bases de données vectorielles sont incroyablement polyvalentes et offrent des solutions puissantes dans de nombreux domaines et applications. Leur capacité à gérer efficacement la recherche par similarité, la gestion de données complexes et de grande dimension les rend particulièrement adaptées aux systèmes de recommandation, à la recherche d'images, au traitement du langage naturel, à la bioinformatique, à la détection d'anomalies et à la réduction de dimension.
Au fur et à mesure que de nouvelles techniques et approches émergent, nous pouvons nous attendre à ce que les bases de données vectorielles continuent à évoluer et à s'adapter pour répondre aux besoins spécifiques de ces domaines, ainsi qu'à d'autres applications innovantes que nous n'avons peut-être pas encore imaginées.
À suivre…
C'est ici que s'achève notre première plongée dans l'univers des bases de données vectorielles. Si vous êtes intrigués par leur potentiel, vous n'avez encore rien vu. Dans les prochains articles, nous allons mettre les mains dans le cambouis avec des implémentations concrètes et explorer leurs interactions avec les LLMs (Large Language Models) comme ChatGPT. Nous aborderons aussi les défis à relever, pour ne rien vous cacher de cet univers. Alors accrochez-vous, notre exploration ne fait que commencer!
