

Introduction
Nous vous proposons une série d’articles, regroupés par thème, pour vous partager les conférences qui nous ont marqués.
Il y aura un article par thème:
- L’outillage, la CI/CD, et Devops en général
- L’architecture Cloud Native
- La sécurité (c’est l’article que vous êtes entrain de lire :) )
Table de matière
Confidential Containers Made Easy
Past Present and Future of eBPF in cloud Native observability
A Confidential Story of Well-Kept Secrets - Lukonde Mwila, AWSmake
The hacker’s guide to Kubernetes
Tutorial: Getting Familiar with Security Observability Using eBPF and Cilium Tetragon
Life of a CVE with Ingress-Nginx, understand the project release cycle: Securité
Malicious Compliance: Reflections on Trusting Container Scanners
Hacking and defending kubernetes cluster
Conslusion
Confidential Containers Made Easy
Présentateurs:
- Jens Freimann, Software Engineer Manager, Red Hat
- Fabiano Fidencio, Cloud Orchestration Software Engineer, Intel
Les confidential containers permettent d’avoir des conteneurs sécurisés pour exécuter des tâches sensibles. Le but est de protéger l’utilisation des données à chaud, donc en exécution. Le début de la conférence consistait à comparer les conteneurs classiques avec des conteneurs “Kata”, les conteneurs utilisés pour le projet confidentiel container.
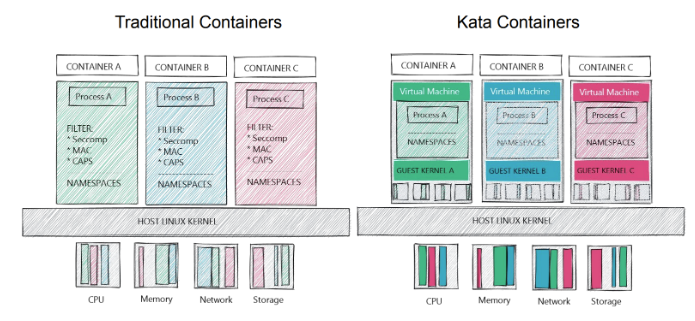
On remarque que les Kata contiennent des couches supplémentaires qui sont principalement une VM et un kernel par conteneur. Pour passer d’un Kata container à un confidentiel container, un firmware est ajouté dans la VM ainsi qu’un agent qui interagit avec un key broker pour utiliser les clés. De plus, il utilise de TEE (Trusted Execution Environment) au niveau hardware.
Ces conteneurs permettent d’apporter de la protection sur des infrastructures non fiables. Cependant, il est nécessaire que le processeur supporte TEE pour exécuter ces conteneurs.
Il est intéressant d’utiliser ces conteneurs pour protéger certaines parties d’une application sans les utiliser pour tous les conteneurs car de l’overhead peut apparaître.
Past Present and Future of eBPF in cloud Native observability
Présentateurs:
- Natalie Serrino, Principal Engineer, New Relic
- Frederic Branczyk, Software Engineer & Founder, Polar Signals
eBPF est une extension du noyau linux qui permet d’attacher certains comportements, avec plus de dynamisme qu’un module du noyau, on peut agir sur le noyau à plusieurs niveaux :
- Syscalls
- Kernel functions
- Network events
- Code personnalisé (dans les limites de ce qu’autorise eBPF pour des raisons de sécurité)
Il y a une fausse idée reçue dans la compréhension d’eBPF qui considère que c’est purement réservé à la pile réseau … C’est faux car le scope est beaucoup plus large que ça. La conférence a été organisée en trois parties: le passé, le présent et le futur.
Le premier usecase de BPF (l’ancêtre de eBPF) date des années 80 et avait pour objectif de diagnostiquer et corriger les problèmes réseau via du filtrage de paquets réseaux. Ceci permettrait aux programmes exécutés en userspace de définir des règles afin d’interagir avec les paquets bruts. L’inconvénient était que BPF était très lent, les performances n'étaient pas au rendez-vous.
En 2014, BPF devient eBPF et s’ajoute au noyau linux. Les programmes sont écrits en utilisant un sous-ensemble du langage C (pas de boucles, le code doit être 100% déterministe et sans ambiguïté sur les conditions d’arrêt du programme) et permettent énormément de choses, y compris de lire et écrire dans la mémoire du kernel. Écrire des programmes eBPF est toujours compliqué mais il existe des libs pour le rendre plus accessible comme libbpf, bpftrace et bcc.
Aujourd'hui, eBPF est utilisé par de nombreuses solutions assez connu comme kubearmor falco ou trace. Il est encore difficile à faire fonctionner avec les langages interprétés, car cela nécessite d'aller un cran plus loin en lisant la mémoire du processus en ayant la connaissance de la manière dont l’interpréteur utilise celle-ci (la gestion de la mémoire est différente entre python, php et Java, etc.), cependant, des Proof-of-concept prouvent que cela est possible (https://github.com/javierhonduco/rbperf).
Même si les stacks des programmes compilés peuvent en théorie être tracés par eBPF, cela nécessite tout de même d’avoir les symboles applicatifs d’accessible, qui sont souvent enlevés dans les binaires de releases. Il est tout de même possible d’avoir ces informations en utilisant un outil comme debuginfod, qui va chercher ces symboles pour les binaires existants (https://wiki.archlinux.org/title/Debuginfod)
eBPF répond dès aujourd’hui à plusieurs use cases:
- Networking (LoadBalancing, firewalling, routing ..)
- Security (Syscall filtering, access control …)
- Observability (application profiling, performance monitoring ..)
Dans le futur, eBPF sera plus accessible grâce aux fournisseurs de Cloud. Toutefois, eBPF a encore des challenges à relever:
- Performance: efficacité à supporter un grand nombre de probes pour lire de grands volumes de données
- Accessibilité: définir quoi ? quand ? et comment instrumenter ?
- Analyse: interpréter l’abondance d’informations brutes
A Confidential Story of Well-Kept Secrets - Lukonde Mwila, AWSmake
Présentateur: Lukonde Mwila, Senior Developer Advocate, AWS
La gestion des secrets dans Kubernetes est un sujet crucial pour la sécurité de l'environnement. Lors d'une session à la conférence KubeCon, les bonnes pratiques pour gérer les secrets dans Kubernetes ont été présentées dans le contexte de GitOps avec ArgoCD.
Tout d'abord, un secret dans Kubernetes peut inclure des mots de passe, des certificats TLS, des tokens OAuth et des clés SSH. Les risques associés à la gestion des secrets incluent le stockage non chiffré (par défaut) dans la base de données etcd, la possibilité de les inclure dans Git, et la récupération facile par un utilisateur root sur le node.
Pour améliorer la sécurité des secrets dans Kubernetes, il est important de ne jamais stocker les secrets dans Git et de les synchroniser depuis un gestionnaire de secrets externe. L'External Secrets Operator (ESO) est une solution recommandée pour récupérer les secrets depuis des sources externes et les exposer en tant que secrets dans Kubernetes. Il possède de nombreux connecteurs vers des sources de secrets telles que AWS SecretManager. Pour accéder au secret store, l'utilisation d'IAM Roles for Service Account (IRSA) est recommandée (si on est sur AWS EKS)
En ce qui concerne la protection des secrets, il est recommandé de passer par l'interface utilisateur ArgoCD pour les dévleoppeurs. De plus, chaque workload doit tourner dans son propre namespace, qui doit avoir ses propres secrets. Pour appliquer des politiques sur les manifestes appliqués, l'utilisation d'un admission controller est recommandée.
En somme, il est crucial de prendre en compte la gestion des secrets dans la sécurité de l'environnement Kubernetes. En utilisant les bonnes pratiques et les outils recommandés tels que l'ESO et l'IRSA, il est possible de réduire les risques liés à la gestion des secrets dans Kubernetes.
Ref : https://external-secrets.io/v0.8.1/
The hacker’s guide to Kubernetes

Cette présentation nous a démontré par l’exemple des failles Kubernetes décritent par l’OWASP, qui depuis l’année dernière, a un OWASP top 10 des projets Kubernetes (https://owasp.org/www-project-kubernetes-top-ten/)
Démo 1
La faille explorée ici se base sur la configuration par défaut de kubelet, qui autorise les connexions anonymes (il est à noter que les connexions anonymes sont désactivées si vous utilisez kubeadm ou un service managé comme eks) -https://kubernetes.io/docs/reference/command-line-tools-reference/kubelet/, par défaut --anonymous-auth est à “true”)
Cela signifie que l’accès à un pod qui a accès à un sous-réseau sur lequel une API kubelet est accessible permet l’accès à un pod existant pour pouvoir faire une escalade de privilège.
Les outils qui ont été utilisés pour réaliser cette démonstration sont:
kubeletctl (https://github.com/cyberark/kubeletctl): permet de scanner un masque de sous-réseau pour trouver une API kubelet, pouvoir lister les pods, et détecter les pods qui permettent une exécution de type shell
la création d’un reverse shell avec netcat
l’installation de paquets supplémentaires dans un container qui était monté en écriture
l’utilisation de tcpdump pour sniffer le bearer token d’une application au moment de son authentification, et ainsi faire de l’usurpation d’identité
Démo 2
La seconde démonstration part d’une faille présente dans une application php mal conçue, qui tourne dans un pod, où la segmentation réseau n’a pas été activée.
Cela a permis de scanner le sous-réseau accessible par le container, et d’y trouver une base de données redis, qui a été configurée sans authentification. Il a ensuite été possible d’utiliser netcat pour requêter la base redis, et récupérer le contenu de celle-ci, notamment les Bearer tokens des utilisateurs connectés à l’application
Conclusion
Ces démonstrations ne sont que la face visible de l’iceberg, et ne nous a présenté que 2 exemples inspirés de cet OWASP 10.
Les exemples présentés sont évitables en respectant les bonnes pratiques, comme:
- L’utilisation d’images qui contiennent plus d’outils que nécessaire (comme /bin/sh par exemple)
- L’exécution des containers avec l’utilisateur root
- Faire de la microsegmentation :
- déclarer explicitement les flux accessibles d’un pod à un autre, pour éviter l’accès à l’api kubelet
- la base de données redis n’aurait pas été accessible depuis un pod qui n’en a pas besoin.
- interdire l’accès des pods à l’extérieur du cluster (désactiver l’egress vers internet)
Tutorial: Getting Familiar with Security Observability Using eBPF and Cilium Tetragon
Présentateurs:
- Duffie COOLEY : Field CTO chez Isovalent, CNCF Ambassador
- Raphaël PINSON: Architecte solution chez Isovalent
Cette longue session d’une heure et demie se composait d’une partie théorique, expliquant ce qu’est eBPF, comment Tetragon utilise ces fonctionnalités, et une partie hands-on où l’on a pu utiliser en pratique Tetragon.
Présentation théorique
L’analogie faite par Duffie sur le fonctionnement d’eBPF m’a paru plutôt bonne:
eBPF est pour le noyau linux ce que Javascript est au navigateur:
le langage utilisé est restreint “by design” pour éviter des actions non autorisées
tout ce qui est lu par le noyau est du bytecode vérifié, et refusé en cas d’actions non autorisées
A la différence de seccomp qui nécessite de se lancer dans un contexte restreint au préalable, eBPF peut sécuriser un processus déjà lancé, à chaud, et sans modification des exécutables, ni des conteneurs.
De plus, avec d’excellentes performances, car il est exécuté en code natif directement par le noyau.
Tetragon est le dernier projet de Cilium, connu pour sa CNI basé sur eBPF.
L’objectif de Tetragon est de faire de la sécurité à l’exécution, en utilisant la richesse de ce que permet eBPF.
En utilisant Tetragon, on peut, après un “helm install”, surveiller, alerter et/ou interrompre tout appel système Linux, que ce soit au niveau des nœuds Kubernetes ou au niveau des hôtes.
Tetragon peut être configuré pour surveiller l’ensemble des syscalls sur un node kubernetes, et son contexte (depuis quel pod, quel namespace, etc.).
Un cas d’usage proposé par le présentateur est le suivant :
“vous arrivez lundi matin, et vous vous êtes fait hacker samedi, le DSI vient en catastrophe dans votre bureau et vous demande quels sont les fichiers qui ont fuité, et à quelle heure”: Tetragon permet de répondre à cette question.
Hands-on
Nous avons fait le lab disponible ici: https://isovalent.com/labs/getting-started-with-ebpf/ avec le support des deux présentateurs. Pendant que Raphaël faisait le lab sur grand écran au rythme des participants, Duffie passait entre les tables pour nous débloquer si besoin, et répondre à nos questions.
Nous avons déployé Tetragon, puis deux ressources TracingPolicy, qui est le CRD permettant de déclarer les syscalls à surveiller, et les actions à faire en conséquence : logger, arrêter le programme appelant ou alerter.
Nous avons entre autre pu :
- tracer les accès au dossiers /etc/kubernetes/manifests
- les appels équivalent à ce que ferait un sudo (setuid 0)
- les appels pour échapper d’un conteneur avec des accès privilégiés (avec par exemple nsenter -t 1)
Cette partie pratique permet de toucher du doigt la puissance de Tetragon et d’eBPF, j’aurais personnellement aimé avoir une demi-heure de plus pour pousser les cas (tuer ou freezer les processus menant des actions non autorisées)
Life of a CVE with Ingress-Nginx, understand the project release cycle: Securité
Présentateurs:
- Dylen Turnbull, Developer Advocate, NGINX
- James Strong, Solutions Architect, Chainguard
L’ingress Nginx est très complexe. Il est possible de saisir jusqu’à 118 annotations et 186 options de configuration. Il permet d’exposer les clusters kubernetes vers l’extérieur.
En juillet, HackerOne a envoyé un rapport privé à Nginx pour signaler une vulnérabilité majeure. Via les annotations de l’ingress, il était possible d’avoir accès à tous les secrets du cluster, donc d’avoir les droits admin sur celui-ci.
A partir d’Août, ils avaient réussi à reproduire la vulnérabilité pour vérifier la véracité du rapport.
Le travail en interne est terminé, maintenant il faut le communiquer à l’extérieur pour que la vulnérabilité soit corrigée le plus rapidement possible.
- Le 15 Septembre, la vulnérabilité est communiquée aux maintainers du projet.
- Le 17 Septembre, la pull request a été faite sur le projet.
- Le 22 Septembre, la release a été faite.
La vulnérabilité a été corrigée en 1 semaine. Maintenant, il faut rédiger le rapport qui concerne la CVE avec des détails sur la vulnérabilité suivi d’un rapport de sécurité sur l’ingress nginx.
Le problème venait du fait que l’OWASP recommande de tester tous les inputs utilisateur alors que Nginx ne le fait pas ou pas assez.
Ensuite, les speakers nous on parlé des processus théoriques pour corriger une CVE et faire une release sur le projet. Voici le processus pour corriger une CVE :
- Day 0 : Réception d’un message qui indique l’existence de la CVE puis reproduction de la vulnérabilité pour en vérifier l’existence. Ils décident ensuite sur les informations qu’ils peuvent communiquer ou pas.
- Week 1 : Vérification de la faisabilité du correctif et définir les menaces actuelles
- Week 2 : Fix la vulnérabilité
- 30 jours : Préparation de la release qui sera faite 2 semaines plus tard
- 90 jours : Temps moyen pour fixer une CVE mais la durée est souvent raccourci pour le projet Nginx
Une partie sur le process de release a été détaillé :
Les points importants sont qu’il y a 4 pull requests lors d’une release :
1- Update du tag et build du projet (environ 4h)
2- Promotion du code juste après le build
3- Modification de la helm chart
4- Tag et release officiel sur le repo git
Cette conférence nous a fourni un aperçu assez complet sur les processus de résolution d’une CVE et de release d’un projet open source.
Malicious Compliance: Reflections on Trusting Container Scanners
Présentateurs:
- Brad Geesaman, Staff Security Engineer, Ghost Security
- Ian Coldwater, Security Researcher, Independent
- Rory McCune, Senior Security Advocate, Datadog
- Duffie Cooley, Field CTO, Isovalent

Cette présentation fait la part belle à la démonstration, et nous montre comment on peut berner les 4 scanners d’images principaux pour leur faire croire qu’il n’y a pas de faille de sécurité dans nos images, sans changer un octet des binaires présents dans une image contenant des vulnérabilités.
Les scanners qui sont utilisés lors des démonstrations sont:
- trivy
- grype
- docker scan (qui utilise Snyk)
- docker scout
les 4 scanners utilisent les mécanismes suivants:
- détection de l’os de l’image
- détection des paquets installés par le package manager (apt-get, apk, yum, etc.)
- les dépendances applicatives (package.json…)
- les metadata des binaires
les détails de la présentations sont disponibles ici: https://github.com/bgeesaman/malicious-compliance/tree/main/demo
Détections liées à la version de l’OS dans l’image
Réécrire le contenu du fichier /etc/os-release suffit à ce que le scanner ne puisse plus déterminer la version et le type d’OS, par exemple en exécutant cette commande dans le
Dockerfile:
RUN echo -e 'PRETTY_NAME="Linux"\nNAME="Linux"\nVERSION_ID="99"\nVERSION="99 (honk)"\nID=Linux' > /etc/os-release
Détection des paquets installés par le package manager
Les scanners utilisent la base de données interne des gestionnaires de paquets pour en déduire la version des paquets installés, si l’on supprime cette base de données, il ne peut plus déterminer les versions installées dans l’image, par exemple en exécutant dans le Dockerfile d’une image alpine
RUN rm -rf /lib/apk
RUN rm -rf /etc/apk
Cacher les dépendances applicatives
Les scanners n’arrivent pas à suivre les liens symboliques, ainsi, renommer les dépendances applicatives, et mettre à la place un lien symbolique se nommant comme le fichier original vers le fichier renommé suffit à berner les scanners.
exemple ici: https://github.com/bgeesaman/malicious-compliance/blob/main/docker/Dockerfile-3-lang#L15
Changer les metadatas des binaires
Des outils comme upx (https://upx.github.io/)), qui ont pour objectif de réduire la taille des binaires, ont comme effet secondaire de supprimer les metadatas des binaires, rendant impossible pour le scanner de se rendre compte que le binaire contient une faille.
Exemple ici: https://github.com/bgeesaman/malicious-compliance/blob/main/docker/Dockerfile-4-bin#L45
Conclusion
Les scanners sont des outils intéressants pour s’assurer de la conformité des images docker mais ne sont pas suffisants (des outils comme Falso, Tetragon ou tracee, qui fonctionnent au runtime sont également nécessaires). Savoir comment fonctionnent ces outils permet de s’assurer de leur bonne utilisation, et également de ne pas empêcher la détection de certaines failles sans même s’en rendre compte
Hacking and defending kubernetes cluster
Présentateurs:
- James Cleverley-Prance, Security Engineer, ControlPlane
- Fabian Kammel, ControlPlane
Cette conférence portait sur l’exploitation de certaines vulnérabilités d’un cluster kubernetes avec des problèmes de configuration. La conférence comportait plusieurs démos avec des environnements différents.
L’intro portait sur une définition du threat modelling qui consiste en la recherche des menaces de l’environnement et trouver des failles de sécurités avec toutes les personnes concernées (développeurs, SRE, product owner…)
Le 1er scénario avait pour but de découvrir les accès au cluster et de donner un 1er accès à l’attaquant. Le cluster comporte une application Jupyter Hub avec les credentials par défaut. L’attaquant commence par scanner le cluster avec l’outil “nmap” et il trouve un NodePort. Le port trouvé est le port par défaut de Jupyter Hub qui est accessible depuis l’extérieur. Ensuite, il utilise les identifiants par défaut et il obtient l’accès à l’application. Il peut ensuite ouvrir un terminal dans Jupyter pour avoir l’accès au pod.
Solutions :
- Désactiver les NodePort
- Changer les credentials
- Activer la double authentification
La 2ème attaque consiste à utiliser un token dans un repo github qui permet de se connecter au cluster. L’attaquant a pu lister les permissions du token et observer qu’il avait des permissions trop importantes. Avec ce token, il a pu créer des déploiements.
Solutions :
- Restreindre l’api server
- Restreindre les permissions des tokens
- Ne pas mettre de token dans des repos Github
Le 3ème scénario consistait à exploiter une élévation de privilège. L’attaquant a un accès à un conteneur du cluster. Le conteneur est exécuté avec des droits root, donc l’attaquant obtient les droits root. Il remarque qu’un filesystem est monté dans le conteneur depuis la VM hôte. Cela lui permet de mettre des fichiers infectés dans la VM hôte. Ensuite il arrive à avoir un accès ssh à l’hôte et donc de passer à travers le conteneur pour avoir accès à la VM.
Solutions :
- Ne pas exécuter le conteneur avec des droits élevés
- Utiliser des pod security standards
- Mettre en place les moindre privilèges
Le 4ème scénario consistait à lister tous les secrets d’un cluster. Tout d’abord, l’attaquant peut créer un pod dans le cluster. Il fait un “exec” dans le pod. Ensuite il a le secret du service account associé au pod car l’auto bound est activé sur le cluster. Avec ce service account, on peut créer un service account avec un rôle qui permet de lister tous les secrets. On monte le secret dans le pod et on a accès à tous les secrets du cluster.
Solutions :
- Désactiver l’auto mount service account dans les pods
- Utiliser le principe du moindre privilège
Le 5ème scénario consiste à modifier une image sans malware pour l’intégrer dans le déploiement. Il suffit de modifier le Dockerfile en introduisant du code malveillant. Ensuite on build et push l’image avec le tag “latest” sur le registry où les credentials ont possiblement fuités. Les déploiements qui utilisent le tag “latest” vont pull la nouvelle image avec le malware.
Solutions :
- Protéger les dépendances du projet
- Faire des rotations des credentials du registry
- Mettre un tag spécifique avec un hash
- Signer les images
En conclusion, on remarque qu’avec quelques petites erreurs de configurations, les conséquences peuvent être importantes lorsqu’un attaquant réussit à s’introduire dans un cluster.
Conclusion
Ces conférences abordent la sécurité sous différents angles complémentaires:
- “The hacker’s guide to Kubernetes” et “Hacking and defending kubernetes cluster” nous a montré comment hacker un cluster kubernetes mal configuré, nous rappelant ainsi l’importance du respect des bonnes pratiques, notamment en suivant les recommandations de l’OWASP
- “Life of a CVE with Ingress-Nginx, understand the project release cycle” nous a permis de comprendre le cycle de vie d’une CVE, du point de vue des maintainers
- “A Confidential Story of Well-Kept Secrets - Lukonde Mwila, AWS” nous a rappelé les bonnes pratiques de la gestion des secrets dans un cluster kubernetes, et présenté des outils permettant le respect de ces bonnes pratiques
- “Past Present and Future of eBPF in cloud Native observability” et “Tutorial: Getting Familiar with Security Observability Using eBPF and Cilium Tetragon” nous ont expliqué ce qu’est eBPF et comment l’utiliser concrètement dès aujourd’hui
- “Malicious Compliance: Reflections on Trusting Container Scanners” nous a rappelé qu’un outil ne fait pas la sécurité, et que comprendre comment celui-ci fonctionne est indispensable pour l’utiliser correctement
- “Confidential Containers Made Easy”: nous a montré que les confidential containers sont déjà une réalité, et nous a présenté les outils permettant sa mise en place
Cela conclut notre série d’article sur la Kubecon 2023, nous espérons que cela vous a appris des choses, et vous a donné envie de tester plein de nouveaux outils!


