

Introduction
Nous vous proposons une série d’articles, regroupés par thème, pour vous partager les conférences qui nous ont marqués à la Kubecon 2023.
Il y aura un article par thème:
- L’outillage, la CI/CD, et Devops en général
- L’architecture Cloud Native (c’est l’article que vous êtes entrain de lire :) )
- La sécurité
Table de matière
Jaeger: The Future with OpenTelemetry and Metrics
How to make your k8s survive when is has no internet access: Airgap reflexion in a cloud native world
How to Blow up a Kubernetes Cluster
Processing of Amsterdam City Data with vendor Agnostic serverless functions
Recovering from regional failures at cloud native speeds
Conslusion
Jaeger: The Future with OpenTelemetry and Metrics
Présentateurs:
- Pavol Loffay, Principal Software Engineer, Red Hat
- Jonah Kowall, VP Product Management, Aiven
Cette session nous a permis de présenter le projet OpenTelemetry, et comment il s’intègre à l’écosystème permettant de faire du tracing distribué au sein de nos applications.

Les présentateurs ont abordé le projet OpenTelemetry, qui offre une solution pour générer des données de télémétrie de manière uniforme, quelle que soit la technologie ou la plateforme utilisée. L'un des avantages clés d'OpenTelemetry est qu'il permet de choisir le backend de son choix, ce qui évite le vendor lock-in et offre une grande flexibilité. Les présentateurs ont également souligné que la communauté OpenTelemetry est en croissance rapide et qu'elle a reçu le soutien de grandes entreprises telles que AWS, Google, Microsoft et Datadog.
Tout d’abord le Distributed tracing c’est quoi?
Essayer d’apporter des réponses aux problèmes de performances dans les architectures distribuées type microservices. Il permet de détecter les problèmes, mais surtout d’identifier les sources, les goulots d'étranglement.
Pour cela toute une panoplie d'outils est utilisée : Instrumentation, Data Collection, Analyse, et visualisation.
Quelques mots et rappels de vocabulaire.
Trace : requête end to end, contient un ensemble de “Spans”
Span : requête au niveau d’un seul service, celui-ci est enrichi avec des métadonnées : tags (pour contextualiser le span)
Pour l’instrumentation, le projet Jaeger fournissait autrefois un standard : OpenTracing qui est maintenant déprécié (https://opentelemetry.io/docs/migration/opentracing/). Il est maintenant recommandé de passer par des agents OTLP, qui s’intègre directement dans vos frameworks/ Langage préféré
Instrumentation : Automatique sur Java, Python; .NET, NodeJS,
Nécessite une adaptation de la CI/CD: : go, ruby, c++, php, rust
Exemple pour java : https://github.com/open-telemetry/opentelemetry-java
Les données sont ensuite transférées à des exporters qui envoient les données à un backend. On peut même utiliser kafka pour bufferiser.Le backend opensource le plus connu est Jaeger. Sa responsabilité est de stocker les données et de s’occuper de la partie Visualisation. Pour la partie stockage des données on peut utiliser ElasticSearch ou Cassandra avec Jaeger.
L’opérateur Jaeger dans kubernetes https://www.jaegertracing.io/docs/1.44/operator/
permet de déployer un cluster jaeger, et permet l’instrumentation par Injection de sidecar agent jaeger.
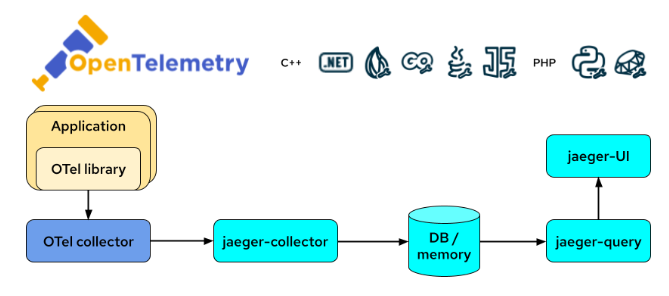
Si on veut envoyer des métriques dans prometheus pour un suivi de certaines requêtes dans grafana, on peut utiliser Span Metrics Connector.
Pour finir, on peut dire que le monde de la télémétrie et de l’APM “ouvert” est encore en phase de structuration, on s’y perd un peu dans les outils, les standards, les spécifications (opentracing, OLTP, Jaeger…). Mais ne vous inquiétez pas, un article viendra bientôt clarifier tout ça!
How to make your k8s survive when is has no internet access: Airgap reflexion in a cloud native world
Présentateur: Christophe Jauffret, Staff Solutions Architect Cloud Native, Nutanix

Quand on fait du kubernetes dans un contexte d’entreprise, il y aura toujours des contraintes liées au network et à la sécurité. Le speaker a identifié 3 use cases:
Limited Network: un réseau assez limité avec des restrictions classiques qu’on retrouve dans un contexte d’entreprise (DMZ, proxy, authentification, règles de sécurité, pare-feu …). Dans ce contexte, il est recommandé de:
- Faire des ouvertures de flux correctes et sécurisés
- Utiliser une bonne configuration proxy
- Utiliser une configuration automatique des pods via des policies avec Kyverno
Isolated network: un réseau sans accès internet avec accès aux clusters via des bastions. Pour faire survivre un cluster, il est recommandé de:
- Utiliser des images registry locaux. Beaucoup d’outils existent aujourd’hui avec des fonctionnalités intéressantes: réplication, security signing, proxy cache
- Utiliser des outils comme skopeo (https://github.com/containers/skopeo), couteau suisse pour migrer les images et repos
- Répliquer les registries dynamiquement
Constrained network: un réseau avec une bande passante très limité, ou avec une très grande latence. C’est un réseau avec les mêmes contraintes qu’un Isolated network mais avec plus d'inconvénients. Une nouvelle image prendra du temps à se répliquer et les nouvelles applications prendront du temps à démarrer. Par conséquent, il est recommandé de:
- Utiliser des outils comme Stargz (https://github.com/containerd/stargz-snapshotter) pour streamer les layers depuis la registry jusqu’au runtime. Le conteneur peut démarrer même avant la fin du download des layers
How to Blow up a Kubernetes Cluster
Présentateur: Felix Hoffmann, Software Engineer, iteratec
Il existe 2 ressources à mesurer et dimensionner lorsque l’on maintient un cluster Kubernetes : CPU et Mémoire.
Il existe 2 paramètres pour ces ressources qui sont :
Requests : ressources minimum que le conteneur disposera
Limits : ressources qui ne seront jamais dépassées par le conteneur
Au niveau des unités, le milli CPU (mCPU) où 1000m = 1 CPU. Pour la mémoire, toutes les unités sont utilisables : Ei, Pi, Ti, Gi, Mi, Ki.
Il est important de savoir comment le scheduler déploie un pod sur un nœud. Le scheduler choisit le nœud qui permet de satisfaire la quantité de ressources demandée dans le paramètre request tout en essayant de répartir la charge sur plusieurs nœuds.
Avec cette méthode, il est impossible de dépasser la quantité de ressources d’un nœud avec les requests des pods. Cependant, il est possible que la somme des limits dépassent les capacités du nœud.
Au niveau des pods, si la mémoire n’est pas suffisante, le pod s'arrêtera car la mémoire est une ressource incompressible. Mais si le pod atteint la limite de CPU, du thottling se mettra en place et le conteneur aura un temps de réponse plus important.
Ensuite, comme les limits peuvent dépasser la mémoire du nœud, si le nœud est à court de mémoire, il terminera les pods qui dépassent leur requests.
Comment un cluster peut exploser ?
Imaginons un cluster avec 3 nœuds où kafka est installé sur les 3 nœuds.
Les pods du noeud 1 demandent trop de mémoire, cela implique la suppression du pod kafka sur le noeud 1. Tout le trafic est redirigé vers le nœud 2 et 3. Or le nombre de messages reçus ne diminue pas, donc les pods sur les pods sur les nœuds 2 puis 3 tombent également car ils doivent gérer une charge normalement répartie sur 3 nœuds. Pour éviter au node d’être en “out of memory”, il est préférable de paramétrer (memory limit = memory requests) pour être sûr de ne jamais excéder la mémoire maximum du nœud.
Pour le CPU, c’est différent. La valeur du requests permet d’avoir la puissance garantie minimale du CPU.
Est-ce qu’il est intéressant de saisir une limite de CPU ?
Non. En effet, ce n’est pas un problème si tout le CPU du nœud est pris par un pod, car si l’on crée un autre pod sur ce même nœud, les ressources CPU vont automatiquement être réduites pour le 1er pod pour satisfaire la request sur nouveau pod.
Cela indique qu’il est plus intéressant de mettre une request sans limit pour ne pas laisser des ressources inutilisées qui pourront être récupérées lorsqu’un autre pod en aura besoin.
Voici un schéma qui récapitule les différents cas :
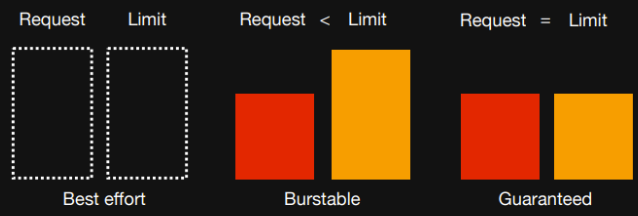
Nous retiendrons que le 2ème cas est le plus optimisé.
Cependant, il existe une exception si une application nécessite des ressources CPU constantes où il sera préférable de paramétrer une limite.
Processing of Amsterdam City Data with vendor Agnostic serverless functions
Présentateurs:
- Mohit Suman, Senior Product Manager, Red Hat
- Zbynek Roubalik, Principal Software Engineer, Red Hat
Quelle est la différence entre le Serverless et le FaaS ?
Le Serverless est un modèle de déploiement alors que le FaaS est plus défini comme un modèle de programmation qui peut aussi servir en tant que liaison entre différents composants
les workloads idéaux pour le serverless sont:
- Stateless
- Short running
- Http ou event driven
Le retour d'expérience présenté était basé sur une plateforme Kubernetes avec Knative (avec tous ses composants: serving, eventing et fonctions …) … un écosystème assez complet pour développer des architectures cloud agnostic sur Kubernetes.
Pour la partie CI, la démo a été faite via tekton pipelines afin d’avoir un build sur le cluster et se passer d’une plateforme de conteneurisation locale. Il est très recommandé d’utiliser les extensions Knative sur vscode ou IntelliJ pour améliorer l'expérience développeur.
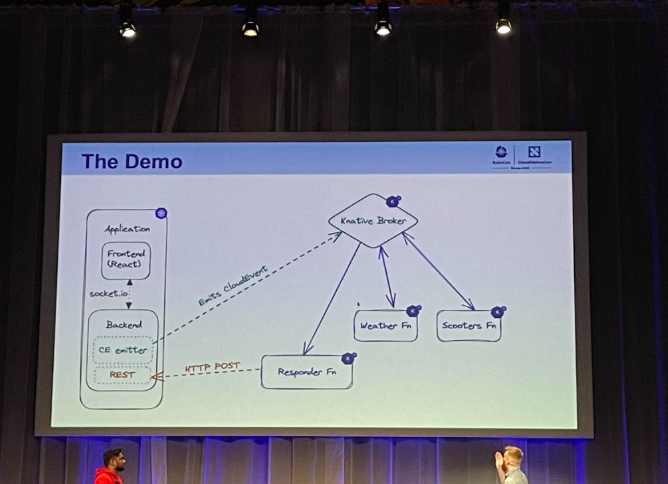
La démo présentée est une architecture serverless event-driven pour traiter l’open data de la ville d'Amsterdam. A partir d’un portail, le client lance un événement qui est traité ensuite par une fonction Knative et qui déclenche d’autres fonctions Knative pour les scooters et la météo.
Recovering from regional failures at cloud native speeds
Présentateurs:
- Yury Tsarev, Principal Solutions Architect, Upbound
- Nuno Guedes, Cloud Compute Lead, Millennium bcp
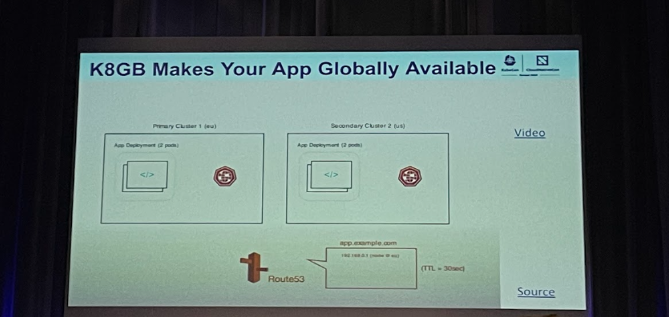
K8GB est un projet CNCF pour la gestion globale du trafic réseau, c’est un load balancer multi région et multi clusters. Les principales caractéristiques de K8GB sont:
- K8S native
- CRD ingress unique
- Pas de control cluster
- basé sur DNS
- Environment agnostic
- Même syntax que Ingress
K8GB permet de gérer plusieurs stratégies de load balancing:
- Round Robin
- Weighted round robin
- Failover
- Geoip
K8GB supporte n’importe que ingress controller sur K8S … De plus, le projet supporte aussi d’autres fournisseurs DNS externes tel que: infoblox, route 53, Azure public DNS.
Pour la partie observability, K8GB exporte de manière native des metrics prometheus et des traces compatible avec le standard open telemetry.
C’est un projet CNCF encore jeune et il y a une communauté très active autour du projet. Vous pouvez l’essayer sur votre cluster K8S et créer des Issues/PR sur Github
Conclusion
Ces conférences abordent tous des briques indispensable de l’écosystème de kubernetes, sur des thèmes et des angles complètement différents, mais tous nécessaires à prendre en compte pour avoir un cluster Kubernetes qui tourne correctement en production:
- Avec “Jaeger: The Future with OpenTelemetry and Metrics”: nous avons abordé l’état de l’art sur la manière et les outils pour s’assurer à travers des métriques applicatives que nos workloads s’exécutent correctement
- Avec “How to make your k8s survive when is has no internet access: Airgap reflexion in a cloud native world”, nous avons abordé les problématiques réseau que l’on rencontre dans le monde réel, et des pistes pour les prendre en compte
- Avec “How to Blow up a Kubernetes Cluster”: nous avons eu une explication détaillé du fonctionnement du scheduler kubernetes, qui, si mal compris peut provoquer des interruptions en production
- Avec “Processing of Amsterdam City Data with vendor Agnostic serverless functions”: nous avons vu qu’il est possible d’utiliser son cluster Kube également pour faire du Serverless, et ce, de manière agnostique
- Avec “Recovering from regional failures at cloud native speeds”: nous avons pu découvrir une approche pour avoir de la haute disponibilité inter région
Pour rappel, cet article n’aborde qu’un seul des nombreux thèmes abordés lors de la kubecon. Suivez notre blog pour ne pas rater le prochain!


