

Introduction
Ippon a participé à la Kubecon 2023. Il y avait des centaines de conférences, toutes plus intéressantes les unes que les autres. Nous vous proposons donc une série d’articles, regroupés par thème, pour vous partager les conférences qui nous ont marqués.
Il y aura un article par thème:
- L’outillage, la CI/CD, et Devops en général (c’est l’article que vous êtes entrain de lire :) )
- L’architecture Cloud Native
- La sécurité
Table de matière
A CICD platform in the palm of your hand
Building a Platform Engineering Fabric with the Kube API at Autodesk
Let’s go backstage IDP security for platform engineers
Automating Configuration and Permissions testing for gitops with opa conftest
Breakpoints in Your Pod: Interactively Debugging Kubernetes
Conslusion
A CICD platform in the palm of your hand
Présentateur: Claudia Beresfort, Senior Software Engineer chez Weaveworks

Une petite session d’une demi heure, qui a permis de présenter un cas d’usage des MicroVMs avec des runners de CI Github.
L’idée est d’utiliser les outils d’AWS qui propulsent Lambda et Fargate tels que Firecracker (VM Monitor). Les micro VMs ont plusieurs avantages:
Offrir un meilleure segmentation/isolation par rapport aux conteneurs classiques
Elles permettent de faire des tests en espace noyau (notamment si on veut tester EBPF)
Par rapport aux VMs classiques, elles démarrent en moins de 125 ms en userspace, leur surface d’émulation matérielle est minimaliste (par rapport à qemu/kvm) et nécessite moins de 5 miB de RAM noyau démarré. L’outillage utilisé est LiquidMetal de chez Weavworks pour monter des nœuds kube sur des microvm et Flintlock. Ce dernier gère le noyau et les images OS via containerd comme des images OCI.
La session s’est terminée par une démo à partir d’un portable dell qui faisait tourner le kubernetes master et un cluster raspberry pi qui faisait fonctionner les runners dans des micro VMs.
Pour résumer, une petite conférence très rythmée, mais qui nous a laissé sur notre faim, car nous aurions aimé en savoir plus sur les mécanismes sous-jacent des micro VMs, et comment les implémenter chez nos clients.
Références :
https://github.com/weaveworks-liquidmetal
https://firecracker-microvm.github.io/
Building a Platform Engineering Fabric with the Kube API at Autodesk
Présentateurs:
- Jesse Sanford, Senior Principal Engineer, Autodesk
- Greg Haynes, Software Architect, Autodesk

Cette présentation parlait de l’utilisation de Kubernetes chez Autodesk comme socle de leur nouvelle architecture de déploiement.
Ce socle est basé sur les composants suivants:
- Backstage
- Crossplane
- Kubevela
- Développement d’opérateurs personnalisés pour les cas spécifiques non traités directement par crossplane et Kubevela
Backstage
Backstage (https://backstage.io/) est un projet CNCF en incubating, qui permet de créer son propre portail de déploiement, qui supporte kubernetes nativement.
Il permet à Autodesk d’uniformiser la création de microservice et la stratégie de déploiement dans Kubernetes.
Crossplane
Qu’est-ce que Crossplane?
Crossplane (https://www.crossplane.io/) est un projet CNCF en incubating, qui permet d’étendre l’API de Kubernetes. Il permet entre autres, à travers des providers, de gérer des ressources externes à Kubernetes depuis Kubernetes (bucket S3, queue SQS, etc.).
Séparer le besoin du développeur de son implémentation
Autodesk utilise Crossplane comme un moyen d’abstraire les spécificités du déploiement que les développeurs ont besoin de créer.
Prenons l’exemple d’une queue SQS, dans Crossplane, le provider AWS permet de créer des queues SQS avec la ressource sqs.aws.crossplane.io/v1beta1:sqs, cette ressource nécessite, entre autres de définir la région de déploiement, les credentials à utiliser pour le déploiement etc.
Pour éviter aux développeurs de devoir gérer des éléments spécifiques à l’infrastructure:
Création d’un CRD ,par exemple sqs.autodesk/v1:sqs, contenant uniquement les éléments à la charge du développeur.
Ce CRD est géré par Crossplane, et celui-ci s’occupe de synchroniser ce CRD pour créer un sqs.aws.crossplane.io/v1beta1:sqs, qui aura été enrichi des éléments spécifiques à l’infrastructure.
Kubevela
Au-dessus des CRDs géré par Crossplane, Autodesk utilise Kubevela (https://kubevela.io/, projet CNCF en incubating) pour agréger un ensemble de ressources qui travaille ensemble, et également pouvoir avoir de l’intelligence sur la création des ressources (conditions et boucles, qui jusqu’à une version très récente de crossplane, n’était pas possible)
Opérateurs
Pour ce qui n’était pas possible d’être fait uniquement avec Crossplane, Autodesk a développé ses propres opérateurs
Conclusion
Cette refonte a permis à Autodesk de réduire drastiquement leurs développements internes spécifiques dédiés à la fabrique logicielle et au déploiement.
L’architecture de Kubernetes correspond parfaitement à la logique de plateforme vers laquelle va Autodesk.
L’api de Kubernetes a permis:
- d’avoir une API fortement structurée grâce aux conventions et la gestion des versions
- L’utilisation des namespaces
- le RBAC
- L’uniformisation de la gouvernance
- De la CMDB sans effort
L’utilisation des CRDs et des opérateurs a permis:
- la réconciliation en continue
- des patterns pour l’intégration
- une séparation claire des responsabilités
- l’inner sourcing
Let’s go backstage IDP security for platform engineers
Présentateurs:
- Suzanne Daniels, Developer Relations, Backstage, Spotify
- Rotem Refael, Director of Engineering, ARMO

Aujourd’hui, selon la présentatrice, on retrouve beaucoup de métiers qui se ressemblent un peu, et qui sont des buzzwords: DevOps, SRE, platform engineer
Backstage (https://backstage.io/) est une solution open source pour construire des portails développeurs… L’outil dispose d’un choix assez large de plugins déjà disponibles et open source afin d’améliorer l’expérience développeur. Si l’outil n’est pas disponible, développer un plugin Backstage est assez simple.
Kubescape (https://github.com/kubescape/kubescape) est un outil CNCF qui permet de détecter les failles de sécurité sur un cluster Kubernetes et détecter les problèmes de configuration au niveau des manifests (vis à vis des standards de sécurité CIS, NSA, MITRE)
L’idée développée chez ARMO était de créer un plugin kubescape pour Backstage. ARMO est la version SaaS de kubescape. Il a fallu 2j de travail des équipes afin de développer le plugin pendant un hackathon
Dans la perspective du platform engineering, les portails développeur sont les nouveaux meilleurs amis et la sécurité c'est la responsabilité de tout le monde. Comme le disait les speakers: “Developers are shifting right, security is shifting left”
Automating Configuration and Permissions testing for gitops with opa conftest
Présentateurs:
- Eve Ben Ezra: Software engineer @New York Times
- Michael HUME: Senior Software engineer @New York Times
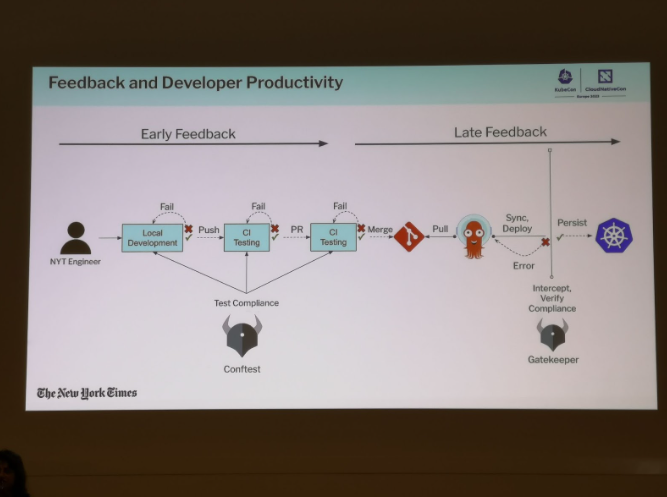
Qu’est que c’est OPA?
OPA (https://www.openpolicyagent.org/, projet incubating de la CNCF) est un moteur destiné à unifier la vérification de la conformité de configuration. Il permet de s’assurer le respect de règles de manifestes kubernetes, mais également de Dockerfile, de fichiers Terraform, Kustomize, Typescript, Jsonnet, XML, etc.
Ces règles sont écrites dans un langage spécifique à OPA, qui se nomme Rego.
Selon l’aveu de Eve, il y a une phase d’apprentissage à prendre en compte avant de comprendre la logique de fonctionnement de Rego.
Kubernetes comme cible de déploiement
Au New York Times, l’utilisation de cluster kubernetes comme cible de déploiement a fortement contribué à l’uniformisation des pratiques de déploiement dans le cloud.
OPA Gatekeeper pour s’assurer de la conformité de ce qui est déployé
OPA Gatekeeper va permettre de s’assurer que les ressources déployées dans Kubernetes se conforment aux règles de conformité écrite en Rego.
Cela permet d’avoir une uniformité des ressources déployées, mais arrivent tard dans le cycle de développement, ce qui peut amener de la frustration chez les développeurs.
Conftest pour une boucle de feedback plus rapide
Etant donné qu’OPA Gatekeeper n’agit qu’au moment du déploiement effectif des ressources, il est complémentaire avec conftest, qui permet de vérifier que les ressources kubernetes que l’on souhaite déployer sont conformes:
au moment des merges request
on peut également installer conftest pour vérifier ces règles depuis le poste du développeur
Il est possible de faire des paquets de règles que l’on peut facilement distribuer avec une api (OPA Bundles: https://www.openpolicyagent.org/docs/latest/management-bundles): un développeur peut utiliser conftest pull git://[chemin vers le bundle] pour ensuite pouvoir vérifier la conformité de ses ressources localement.
Le respect du format des ressources avec kubeconform
conftest permet de vérifier que les règles de conformité spécifiques à votre organisation sont respectées, mais cela n’assure pas que les ressources respectent le bon format, et seront compatibles sur votre cluster kubernetes cible. Pour cela, on peut utiliser kubeconform (https://github.com/yannh/kubeconform)
Pour les extensions à Kubernetes, il existe un catalogue de ressources populaires, que l’on peut utiliser avec kubeconform, qui référence plus de 300 schemas de CRDs https://github.com/datreeio/CRDs-catalog
Conclusion:
conftest et kubeconform permettent d’améliorer l’expérience du développeur en lui permettant de se rendre compte plus facilement et rapidement si son déploiement se fera sans soucis sur kubernetes, tout en utilisant le même langage que celui qui sera utilisé par OPA Gatekeeper.
Breakpoints in Your Pod: Interactively Debugging Kubernetes
Présentateur: Daniel Lipovetsky, D2IQ

La démonstration a montré comment mettre des breakpoints dans trois pods différents et comment résoudre les différents défis rencontrés lors de cette opération. La démarche de cette session était originale. Daniel nous a fait la démo, et ensuite nous a montré comment il avait fait. Il a utilisé comme support pour sa démo, ClusterAPI sur lequel il travaille en ce moment.
Le premier défi était de trouver un moyen d'exécuter le debugger dans le namespace du processus. Pour ce faire, une image contenant le debugger Go (dlv) a été utilisée. Cependant, cette image n'était pas présente dans le pod d'origine, ce qui a nécessité l'utilisation de la commande kubectl debug avec l'option --image pour démarrer un nouveau container avec l'image du debugger.
Le deuxième défi était d'autoriser l'attachement du debugger, qui nécessitait la capacité SYS_PTRACE. Pour cela, le container du debugger devait être démarré en tant que root et le pod devait être patché avec kubectl patch pour ajouter les privilèges SYS_PTRACE.
Le troisième défi était de copier les informations de débogage dans le container éphémère du debugger. Les informations de débogage sont nécessaires pour que le debugger puisse fonctionner correctement. Pour copier ces informations, la commande eu-strip a été utilisée pour supprimer toutes les sections du binaire qui ne sont pas nécessaires pour le débogage. Ensuite, la commande objcopy /proc/1/root a été utilisée pour lier les informations de débogage à l'exécutable.
Le quatrième défi était d'atteindre le serveur du debugger. Comme le container éphémère du debugger ne peut pas exposer de port, la commande kubectl port-forward a été utilisée pour transférer les ports.
Le cinquième défi était de faire correspondre le code source sur le poste de travail avec celui du serveur. Pour résoudre ce problème, une "map" de chemins locaux du code source vers celui des informations de débogage a été créée. Cette map permet au debugger de localiser les fichiers sources sur le poste de travail.
D'autres défis ont été abordés, tels que la sonde de durée de vie et la distribution d'informations de débogage dans les images Docker.
En conclusion, la méthode présentée lors de la conférence KubeCon permet d'effectuer une session de débogage à distance avec des breakpoints dans plusieurs pods en surmontant les défis rencontrés à l'aide de différentes technologies.
Conclusion
En conclusion, ces conférences ont mis en avant l'importance des outils, de la CI/CD et du DevOps en général pour une utilisation agréable pour les utilisateurs de Kubernetes, notamment les développeurs.
La présentation de Weaveworks sur les MicroVMs a présenté un cas d'utilisation intéressant, donnant une approche prometteuse pour allier le meilleur des deux mondes: les machines virtuel et les conteneurs.
Tandis que la présentation d'Autodesk a mis en avant l'utilisation de Kubernetes comme base pour leur nouvelle architecture de déploiement. Backstage, Crossplane et Kubevela ont été présentés comme des composants clés de cette architecture pour avoir une expérience développeur agréable et productive.
Pour rappel, cet article n’aborde qu’un seul des nombreux thèmes abordés lors de la kubecon. Suivez notre blog pour ne pas rater les prochains!


