

Introduction
Dans cet article, je vais parler de Matillion, de comment tirer profit de ses variables pour développer des composants réutilisables et construire une architecture facile à maintenir. Dans la première partie je présente d’abord le besoin que nous avons eu chez un client et l’architecture mise en place. La seconde partie entre dans le détail de l’utilisation des variables et prend la forme d’un tutoriel.
Pour présenter l’outil à ceux ne le connaissant pas, Matillion est un outil ELT (Extract, Load and Transform) ‘Low Code’ que l’on couple à un entrepôt de données dans le Cloud (Redshift, Google Cloud ou Snowflake). L’ELT possède de nombreux avantages sur l’ETL (moins de déplacement de données, utilisation de la puissance de l’entrepôt de données…) mais entraîne à première vue certaines contraintes auxquelles Matillion apporte une réponse, l’ensemble étant très bien expliqué dans un précédent article Découverte de l’ELT et de la solution Matillion de Jean-Baptiste LEBLANC.
Matillion permet le développement et l’orchestration de transformations très visuelles et simples à mettre en place. Celles-ci sont ensuite assez facile à relire et comprendre par des personnes nouvelles sur le sujet ou peu techniques.
Matillion est tout de même suffisamment souple grâce à ses composants et variables pour que l’on développe des orchestrations et transformations génériques. On peut éviter avec un peu d’expérience le copier coller massif de composant qui amène de la confusion et de grandes difficultés de maintenabilité. Ce risque peut malheureusement être relativement important lorsque Matillion est utilisé pour un besoin initial restreint, apprécié pour son côté convivial et utilisé pour des traitements ensuite de plus en plus nombreux.
Il me semble donc important de partir dès le début avec une bonne compréhension des variables et des composants offerts, qui seront souvent les bases du développement d’une architecture cohérente et maintenable.
Table des Matières
Architecture Générique sous MatillionMatillion et ses Variables
- Manipulation des Variables dans un Script Python
- Itération sur une Grid Variable
- Variables Partagées
- Export de Variables
Architecture Générique sous Matillion
Nous allons nous appuyer sur le besoin rencontré sur une mission : construire un job d’orchestration ‘générique’, qui va pouvoir être utilisé pour différents besoins grâce à un mécanisme de paramétrage.
Sur cette mission, nous avons mis en place un job d’orchestration, dont le principe est classique :
- Faire la mise à jour des données brutes dans la couche Bronze de notre data warehouse
- Procéder à différents traitements pour construire la couche Silver
- Préparer les données dans la couche Gold, prêtes à être exploitées pour la réalisation de dashboards et d’exports
La particularité plutôt intéressante est la présence de plusieurs consommateurs différents :
- utilisants la même application (donc même structure des sources de données brutes dans notre cas)
- Pour qui nous pouvons mettre à disposition les mêmes rapports/exports finaux, mais qui n’auront pas forcément besoin des mêmes rapports
- Qui vont souhaiter que ces rapports soient mis à jour à des fréquences différentes, sur des plages horaires différentes, sur des zones horaires différentes
L’objectif est bien évidemment d’en faire le moins possible, c'est-à-dire de ne mettre à jour que les données brutes nécessaires pour chaque client, de même pour le raffinement des données dans les couches Silver et Gold.
Nous avons donc mis en place une architecture générique sous Matillion, dont une version simplifiée est représentée ci-dessous :
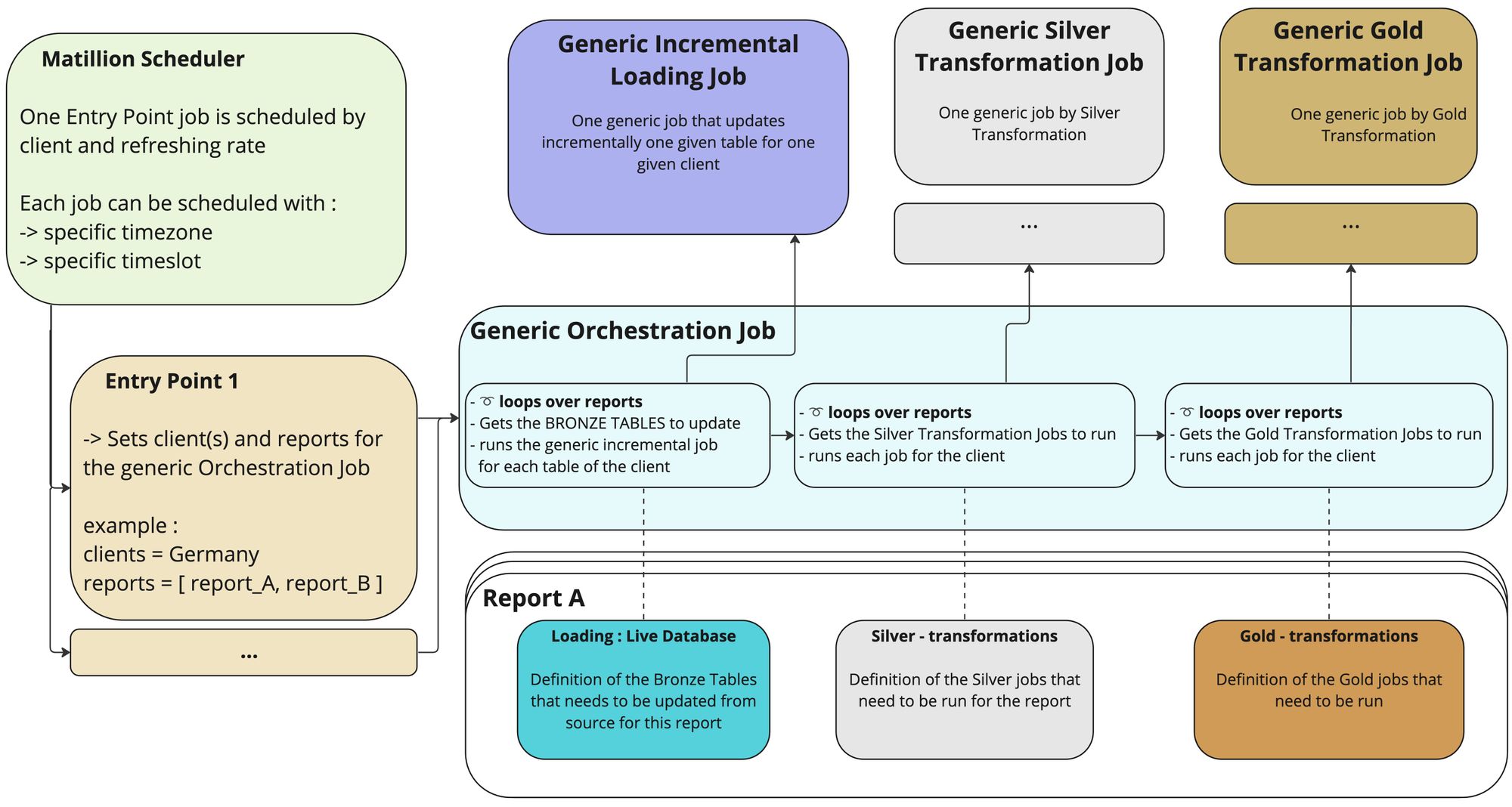
Cette architecture est basée sur le concept de rapports, chaque rapport décrivant un besoin (un dashboard, un export…). Un rapport va définir :
- quelles sont les données brutes à mettre à jour
- quelles transformations sont nécessaires au niveau de la couche silver
- De même les transformations nécessaires au niveau de la couche gold
Les jobs permettant de charger les données et d’effectuer les transformations sont développés de manière générique : il prennent comme variable d’entrée le client concerné et peuvent faire leur travail sur tous les clients
La brique principale est le job d’orchestration, qui prend comme variable d’entrée le ou les clients concernés et une liste de rapports à produire. Il va alors parcourir chaque rapport, déterminer de manière unique les sources à mettre à jour et les transformations à effectuer, puis appeler les jobs génériques de chargements et de transformations.
La dernière pièce du puzzle est la planification de ce job d’orchestration générique et la manière de lui fournir ses variables d’entrée. Sur le diagramme, j’ai représenté une solution, qui consiste à créer des points d’entrée. Ils prennent la forme de jobs Matillion, qui lancent l’orchestration générique en lui fournissant les variables (le client et les rapports à produire). Chaque point d’entrée est alors planifié dans Matillion. Une autre possibilité est d’utiliser l’API de Matillion pour lancer directement le job d’orchestration générique en définissant les variables.
Comme nous pouvons le voir, l’architecture déployée fait un usage intensif de variables, dont nous allons explorer le fonctionnement dans Matillion, en décrivant sur des cas simples divers mécanismes qui nous ont été bien utiles lors de l’orchestration.
Matillion et ses Variables
Nous allons par étape créer un job d’orchestration qui construit une liste de tables à mettre à jour, filtre cette liste et l’utilise afin d'appeler pour chaque entrée un job fils qui sera chargé de mettre à jour cette table.
Nous allons au fil de l’eau parler :
- de l’utilisation des variables dans les scripts Python
- de comment itérer sur une Grid Variable pour définir les paramètres d’un composant
- au détour de ces itérations, de l’optimisation des exécutions
- du concept de comportement d’une variable au sein d’un job
- du passage d’une variable d’un job père à un job fils, puis de sa récupération dans le job père
Nous partons du principe que l’utilisation de base des deux types de variables est connue (Scalar Variables et Grid Variables), dans le cas contraire, la documentation de Matillion sur le sujet pourra être utile.
Manipulation des Variables dans un Script Python
Les scripts python font partie des composants importants de Matillion, ils permettent d’étendre les fonctionnalités des composants standards. Nous allons prendre l’exemple d’un besoin tout simple pour parler de l’utilisation des variables dans un script python : la suppression de doublons de ligne dans une Grid Variable.
Nous commençons par créer un job d’orchestration nommé ‘parent_job’ et créer une Grid Variable ‘p_tables_to_update’ avec deux colonnes de type text et les valeurs suivantes :
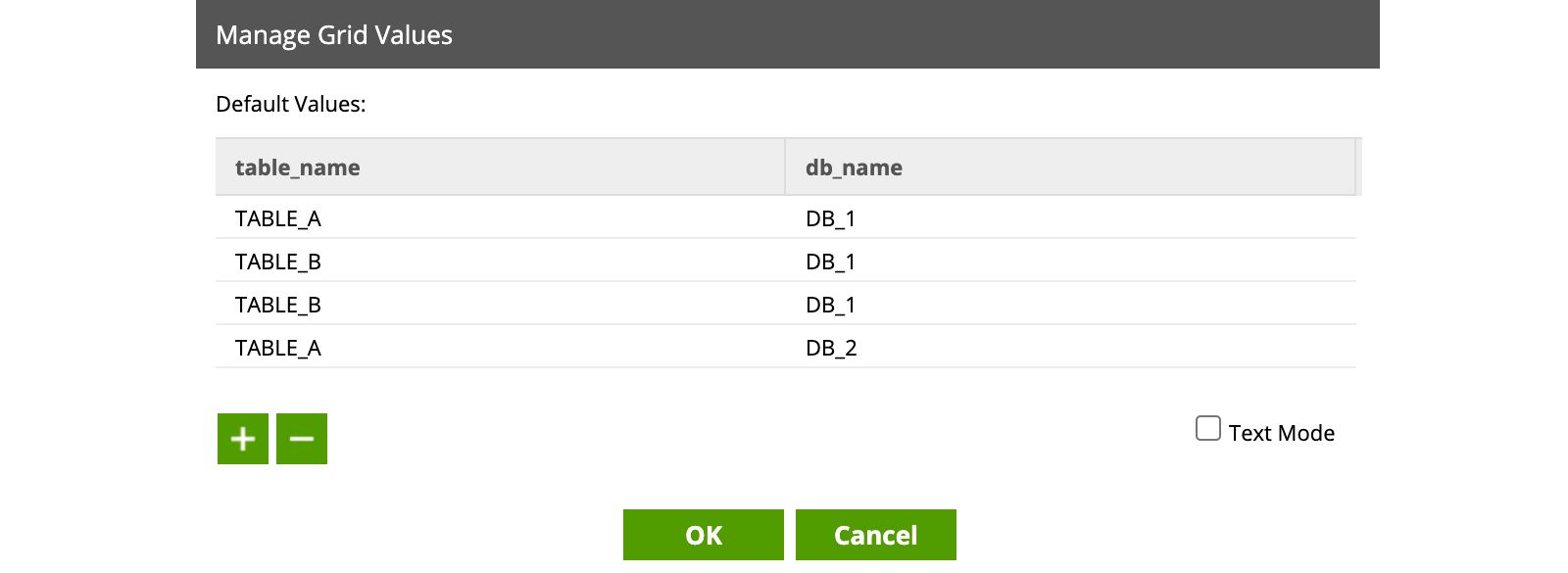
(pour créer une Grid Variable : click droit -> Manage Grid Variables -> ‘+’.)
Nous avons rentré ici manuellement les valeurs de la Grid Variable mais supposons pour l’instant que cette variable est alimentée en amont et que certaines valeurs peuvent être insérées plusieurs fois. Nous souhaitons donc supprimer les doublons.
Créons un script python. Par défaut, un bloc de commentaire donne quelques informations sur la manière d’accéder et mettre à jour les variables. Dans notre cas, nous allons utiliser la méthode getGridVariable('var_name') pour récupérer la Grid variable sous la forme d’une liste de listes (liste de lignes), puis du code python standard pour modifier notre objet python. Enfin la mise à jour de la Grid Variable se fait grâce à la méthode updateGridVariable('var_name',list_of_rows)
Créons un script python. Par défaut, un bloc de commentaire donne quelques informations sur la manière d’accéder et mettre à jour les variables. Dans notre cas, nous allons utiliser la méthode getGridVariable('var_name') pour récupérer la Grid variable sous la forme d’une liste de listes (liste de lignes), puis du code python standard pour modifier notre objet python. Enfin la mise à jour de la Grid Variable se fait grâce à la méthode updateGridVariable('var_name',list_of_rows)
import itertools
tables_to_update = context.getGridVariable('p_tables_to_update')
if tables_to_update:
tables_to_update.sort(key=lambda x: x[1])
tables_to_update = [ r for r,_ in itertools.groupby(tables_to_update) ]
context.updateGridVariable('p_table_to_updates', tables_to_update)
En ce qui concerne les scalar variables, au lancement du script, un ensemble de variables python est créé, variables de même noms, même types et même valeurs que celles dans Matillion. Comprenez que ce n’est qu’une copie, modifier une variable dans le script ne la met pas à jour dans Matillion, pour ça on utilise context.updateVariable('var_name',new_value). Bon à savoir, context.updateVariable() met à jour la variable Matillion, mais aussi la copie de celle-ci dans Python.
Vous trouverez plus d’information sur les scripts dans la documentation Matillion ici (installation de packages, accès au data warehouse notamment).
Itération sur une Grid Variable
Continuons sur le même job d’orchestration précédent avec la Grid Variable 'tables_to_update' qui, après notre script python, contient une liste unique de tables à mettre à jour. Nous voulons maintenant lancer un job fils qui pour chaque ligne dans 'tables_to_update' mettra à jour cette table.
Nous allons itérer sur cette Grid Variable, lancer un job fils en lui fournissant comme variable d’entrée le nom de la table et le nom de la base de données.
Décrivons le fonctionnement :
- Nous voulons fournir au job fils deux scalar variables que nous appellerons dans celui-ci 'c_table_name' et 'c_db_name' (ici prefixé ‘c’ pour ‘child’ afin de rappeler que ce sont les variables du job fils)
- Dans le job père, le composant Grid Iterator va itérer sur chaque ligne de la Grid Variable 'tables_to_update', mapper la valeur de la colonne 'table_name' avec la scalar variable 'p_table_name' et la colonne 'db_name' avec la variable 'p_db_name' du job courant (le job père)
- Le composant relié au Grid Iterator sera de type Run Orchestration, il lancera le job fils, définira respectivement ses deux scalar variables 'c_table_name' et 'c_db_name' depuis la valeur des deux variables 'p_table_name' et 'p_db_name'
La petite subtilité est l’utilisation de scalar variable dans le job père comme intermédiaire.
Créons le job fils ‘child_job’ :
Définissons les deux scalar_variables 'c_table_name' et 'c_db_name' de type text, précisons des valeurs par défaut. Même si la valeur de ces variables sera transmise par le job père, nous définissons des valeurs par défaut, qui seront les valeurs pour nos tests lors de l’implémentation du job :
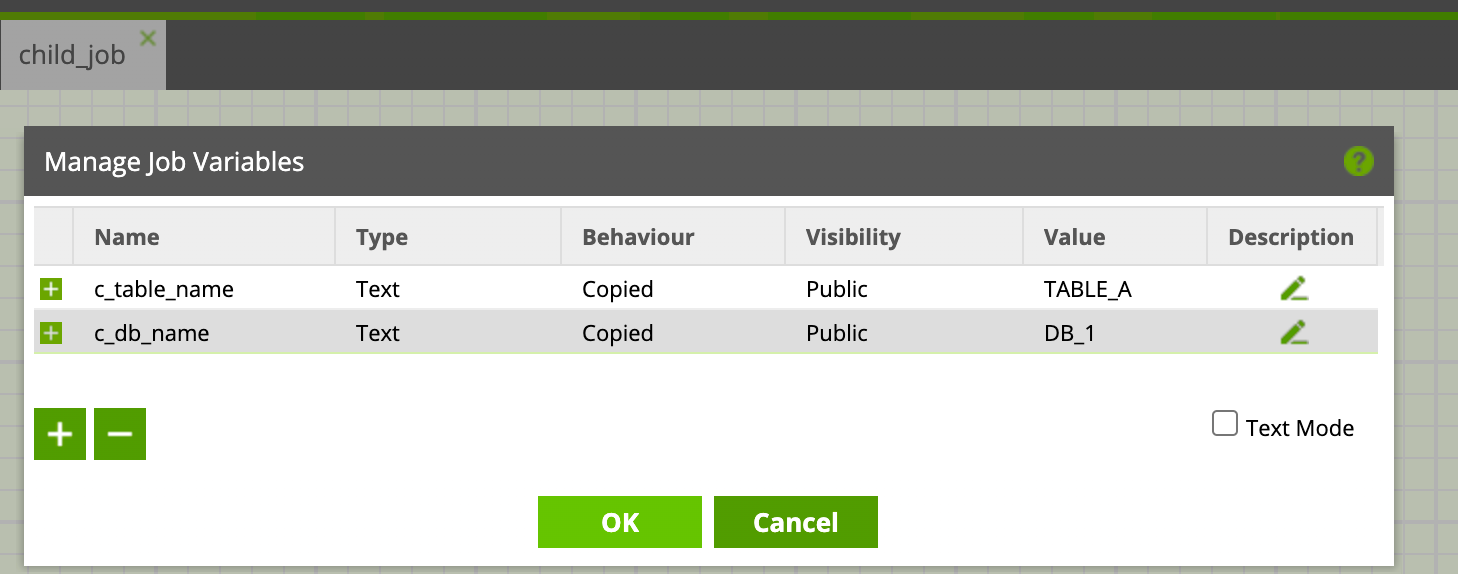
Nous n’implémentons rien dans ce job, vous pouvez par exemple mettre un script python qui imprime la valeur des variables (on retrouvera alors la valeur des variables en message de sortie du composant dans le détail de la tâche).
Retournons au job père déjà créé précédemment :
Nous allons maintenant le modifier pour atteindre l’état de l’image ci-dessous :
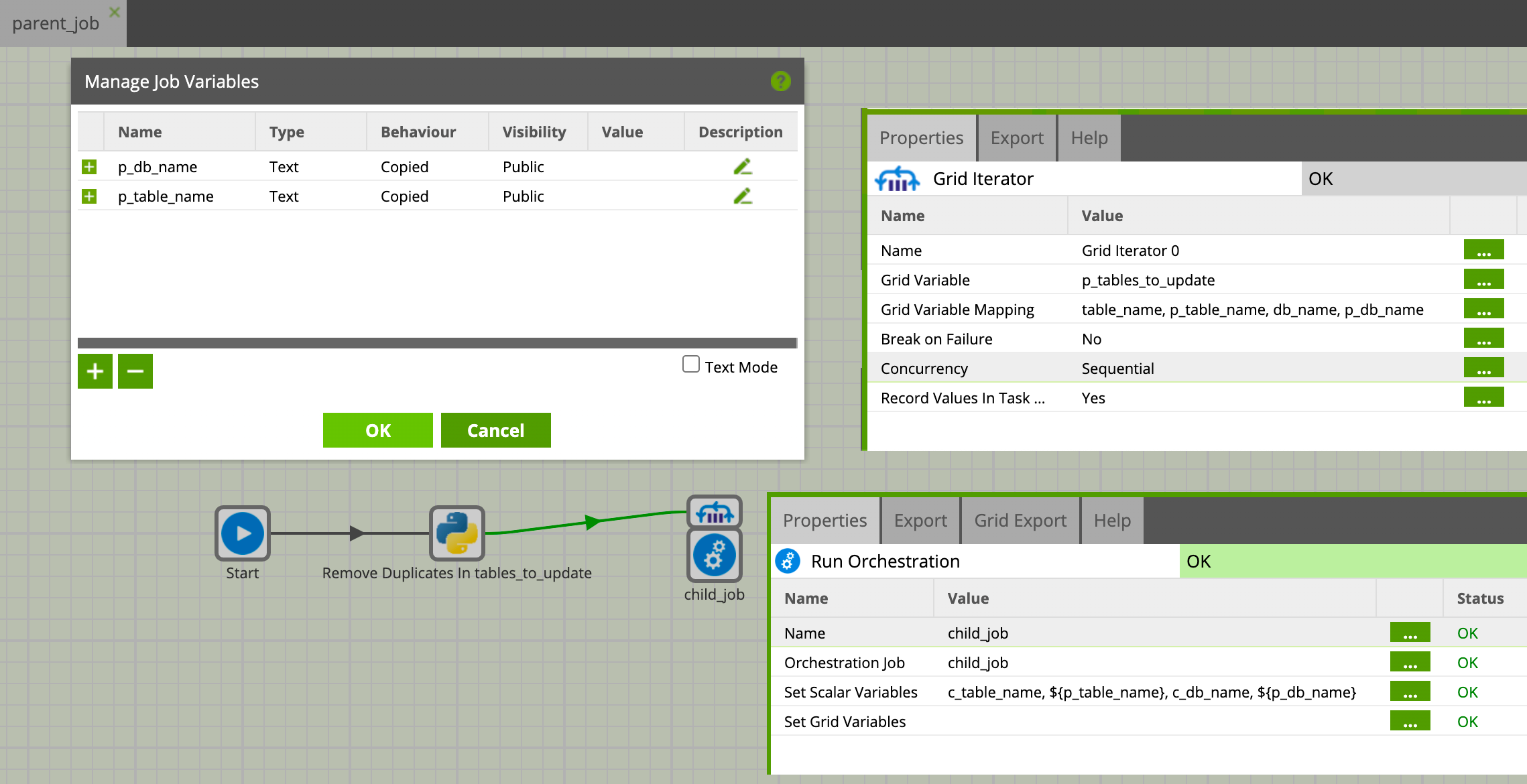
- De manière similaire à ce que nous avons fait pour le job fils, nous définissons les deux scalar variables 'p_table_name' et 'p_db_name' (elles n’ont pas besoin de valeur par défaut, elle ne sont pas réellement utilisées mais servent d’intermédiaires)
- Nous ajoutons le composant Grid Iterator et le paramétrons :
- il itère sur sur la variable 'p_tables_to_updates'
- il mappe la colonne 'table_name' vers la variable 'p_table_name'
- Il mappe la colonne 'db_name' vers la variable 'p_db_name'
- Nous ajoutons le composant Run Orchestration, le relions au Grid Iterator et le paramétrons comme ci-dessus (à noter la syntaxe '${var}' dans le champ Value du ‘Set Scalar Variables’)
Une fois cela fait, nous avons maintenant ‘child_job’ qui est appelé pour chaque ligne de notre Grid Variable avec ses variables d’entrée définies à partir des valeurs de chaque ligne.
Grid Operator et Concurrency :
Supposons que le job sur lequel nous itérons met à jour une table bronze (dont nous lui fournissons le nom) depuis sa source. Deux itérations différentes vont mettre à jour deux tables différentes et peuvent être considérées comme indépendantes. Nous pouvons donc paramétrer le Grid Iterator pour qu’il lance les jobs soit en parallèle (concurrency = Concurrent), soit de manière séquentielle (concurrency = Sequential). Lorsque le mode parallèle est choisi En parallèle :
- nous optimisons la vitesse d'exécution
- nous perdons la possibilité d’arrêter les itérations si l’une d’elle est un échec (paramètre Break on Failure). Toutes les itérations seront donc effectuées même si l’une d’elle échoue en cours de route.
- Nous n’avons pas la possibilité d’exporter vers les jobs fils des variables partagées (behaviour = ‘shared’, nous expliquons ce point par la suite)
Concernant la vitesse d'exécution, plusieurs facteurs entrent en compte, notamment :
- le nombre de threads que Matillion peut lancer, qui dépend du nombre de vCPU de la machine virtuelle de Matillion
- Le nombre de connexions concurrentes au Datawarehouse cible
- Les capacités du Datawarehouse
Plus de détails sur l’analyse et l’amélioration des performances de Matillion sur leur Blog ici et là.
Variables Partagées
La différence entre une variable partagée (behaviour = ‘shared’) et une variable copiée (behaviour = ‘copied’) peut paraître obscure au premier abord mais sera claire je l’espère avec un petit exemple. Ce paramètre définit le comportement de la variable dans les différentes branches du job :
- Lorsque la variable est de comportement ‘copied’, celle-ci est copiée dans les différentes branches, les différentes branches ne partagent donc pas la même valeur
- Lorsque la variable est de comportement shared, celle-ci reste commune aux différentes branches, qui modifient donc la même variable
Créons donc comme l’image ci-dessous :
- Un job avec deux scalar variables ‘copied_string’ et ‘shared_string’, respectivement de comportement copié et partagé, les deux ayant pour valeur ‘Initial Value’
- Une première branche (LOWER) qui met à jour les deux variables
- Une seconde branche (UPPER) dont le premier composant attend quelques secondes, le temps que la première branche s’exécute puis lit l’état des variables dans un second composant
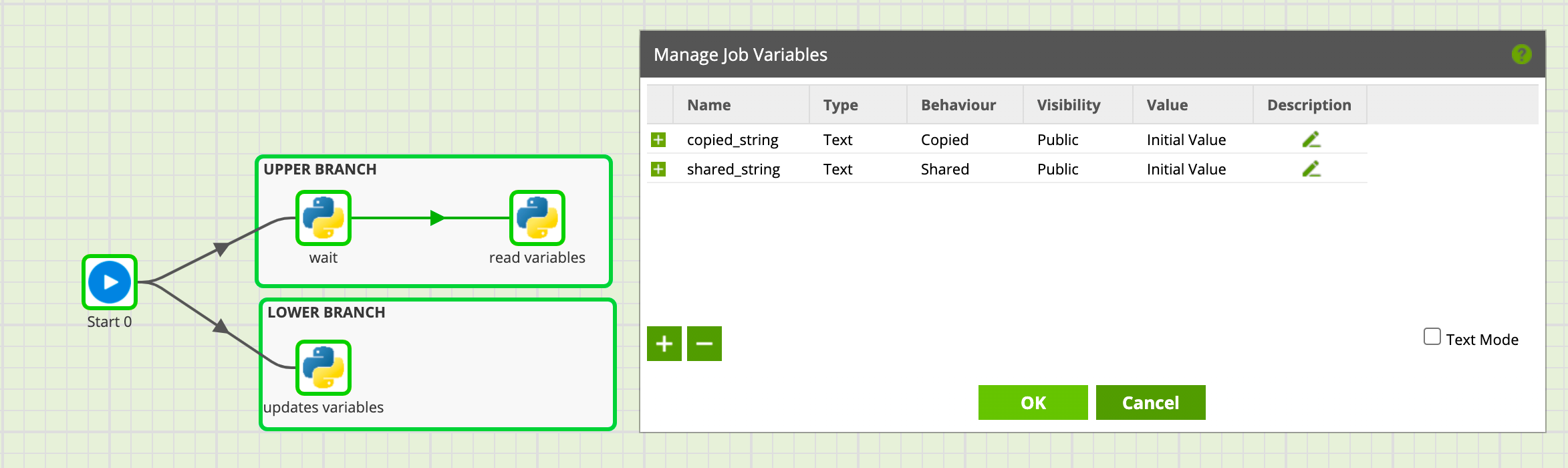
Le contenu des trois scripts est le suivants :
# LOWER BRANCH : update variables
context.updateVariable('copied_string','Value set in LOWER BRANCH')
context.updateVariable('shared_string','Value set in LOWER BRANCH')
# UPPER BRANCH : wait
import time
time.sleep(2)
# UPPER BRANCH : read variables
print("VALUES IN UPPER BRANCH :")
print(f"- copied_string : {copied_string}")
print(f"- shared_string : {shared_string}")
Lorsque nous exécutons le job, nous avons en message de sortie du composant ‘read variables’ le retour suivant :
VALUES IN UPPER BRANCH :
- copied_string : Initial Value
- shared_string : Value set in LOWER BRANCH
Comme attendu :
- La variable au comportement copié n’est pas modifiée dans la branche supérieure bien que modifiée dans la branche inférieure, ce sont dans chaque branche deux variables différentes.
- La variable au comportement partagé est bien la même dans les deux branches, la modification faite dans la branche inférieure se retrouve dans la branche supérieure.
Ce comportement est donc bien interne au job en question et n’a rien à voir avec une variable dont la valeur serait partagée entre ce job (le parent) et un autre job fils. Peut-on alors facilement envoyer une variable à un job fils et en récupérer la version modifiée ? Oui, grâce à la possibilité d’exporter les variables en sortie de composant.
Export de Variables
Dernier cas d’école abordé dans cet article, fournir une Grid variable depuis un job père à un job fils, la modifier et la récupérer dans le job père.
Reprenons le job développé précédemment dans l’état où nous l’avions laissé à la fin de la partie ‘Iteration sur une Grid Variable’ :
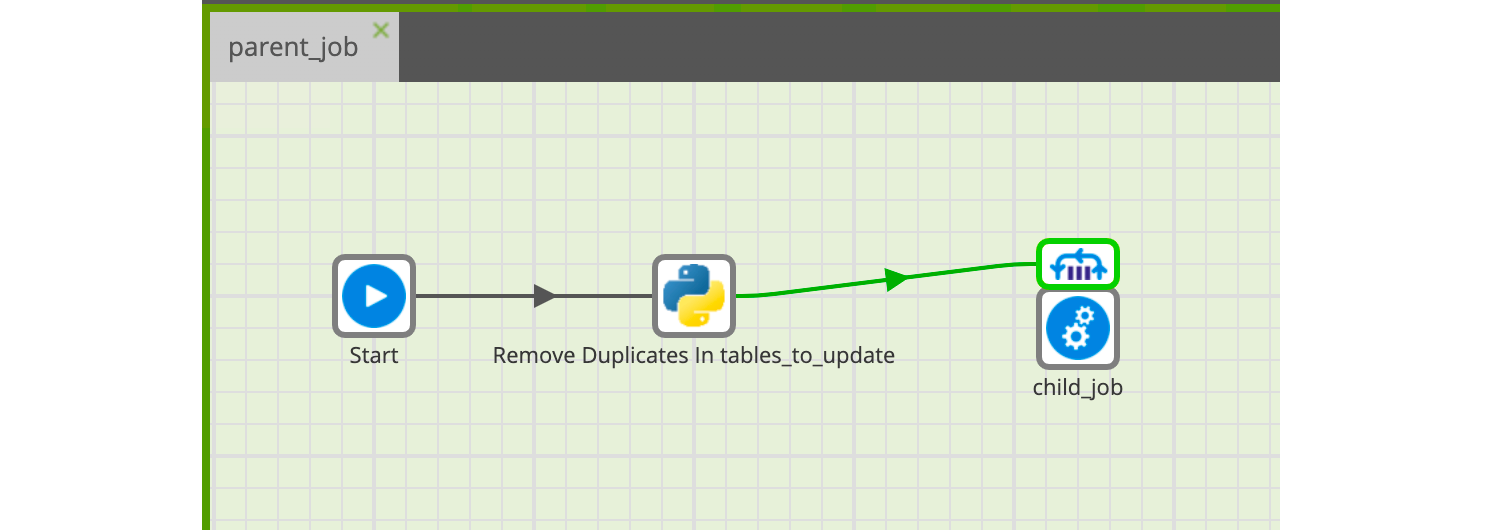
Pour rappel, celui-ci :
- Part de la Grid Variable ``tables_to_update`` pour laquelle nous avons renseigné des valeurs par défaut
- Supprime les doublons éventuels dans cette Grid Variable
- Itère sur chaque ligne de cette Grid Variable et lance le job fils 'child_job' avec des paramètres extraits de la ligne
Nous allons faire appel à un nouveau job fils juste après le démarrage. Nous allons fournir à celui-ci la Grid Variable ‘p_tables_to_update’, ce job se chargera d’y ajouter quelques entrées, puis nous allons récupérer cette Grid Variable en sortie avant d’attaquer comme précédemment le composant ‘Remove duplicates’.
Commençons par créer le job d’orchestration ‘append_to_tables_gv’ :
- Avec une Grid Variable nommé ‘tables_to_update’, de même structure que dans le job père, mais cette fois vide, et de comportement ‘shared’ et non pas ‘copied’
- Avec un unique composant Append to Grid qui ajoute une valeur à la variable et qui est paramétré comme ci-dessous
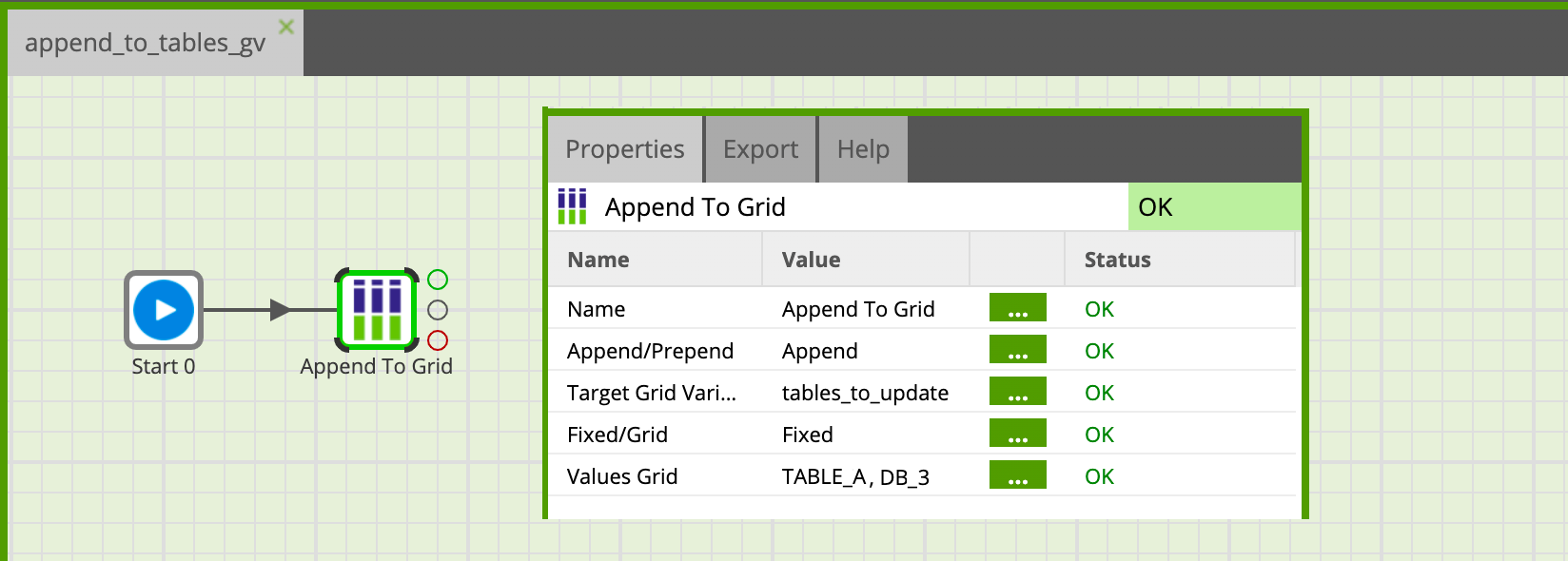
Pourquoi notre Grid Variable doit-elle être de comportement Shared ? Si vous avez bien suivi la partie précédente, nous n’avons dans ce job qu’une branche donc à priori pas d’intérêt à choisir shared plutôt que copied… Il se trouve que nous allons exporter cette variable, si son comportement est ‘copied’, cela implique que plusieurs versions de cette variable peuvent exister dans le job… et nous ne pourrons pas l’exporter.
Ne reste plus qu’à ajouter ce composant au job père et de paramétrer dans ses propriétés ‘set Grid Variables’ comme suit :
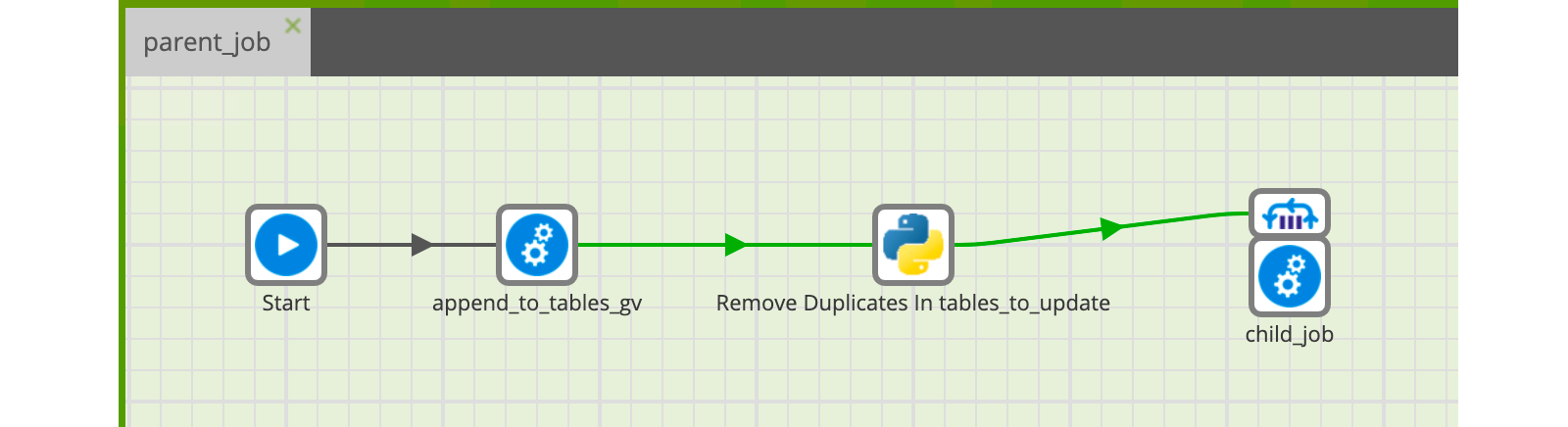
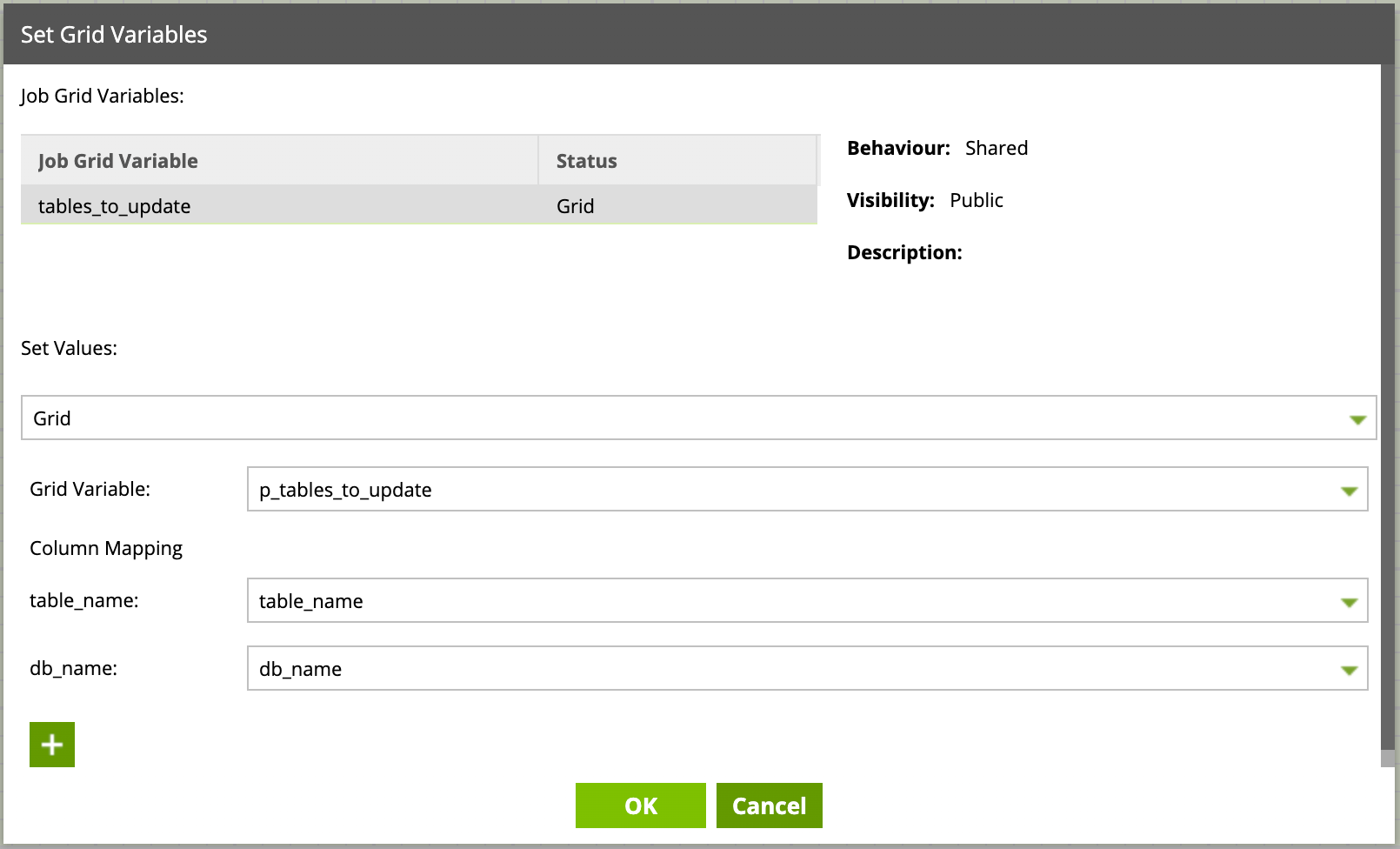
Puis de récupérer sa Grid Variable en sortie de composant, depuis l’onglet ‘Grid export’ du composant, on ajoute un export (‘+’) que l’on paramètre comme suit :
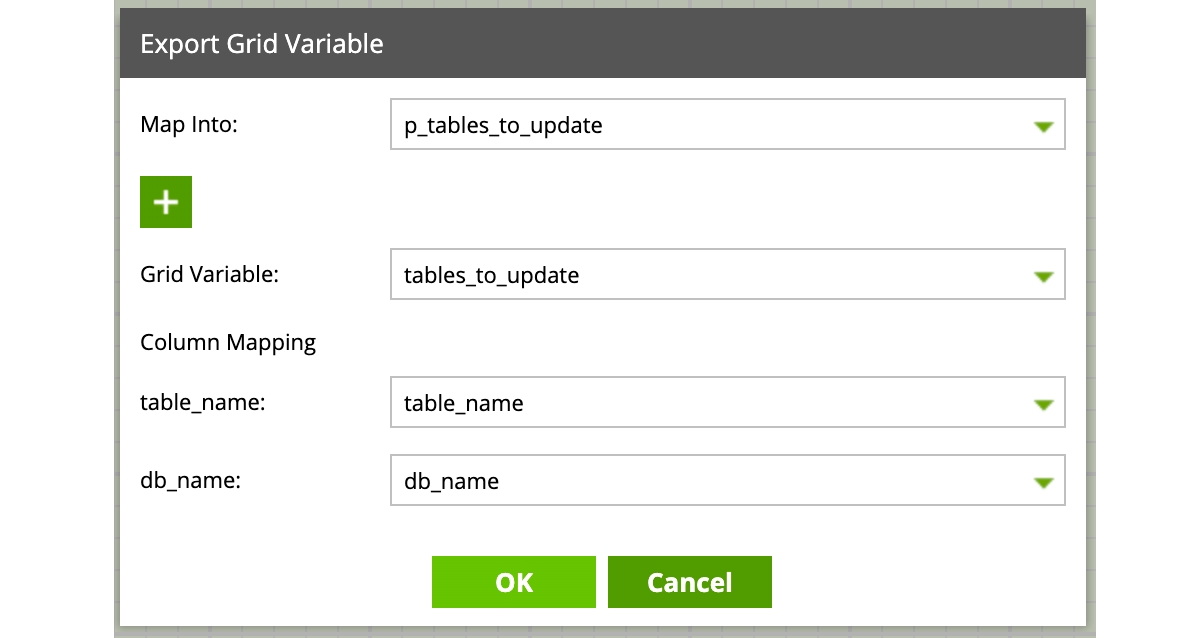
Conclusion
Avec une maîtrise maintenant plus complète des variables sous Matillion et de leurs utilisations dans divers composants, il est plus aisé de penser l’architecture dès le début du développement et de développer quand nécessaire des jobs paramétrables qui éviteront les doublons et faciliteront grandement la maintenance et les améliorations.
Pour aller plus loin, le blog de Matillion explique dans un article en deux parties l’utilisation des Jobs partagés, qui ont l’avantage de définir clairement les paramètres d’entrée et de gérer les versions (partie 1, partie 2).
