

Vous êtes intéressés par le deep learning, la vitesse et la compétition ? Alors suivez-moi dans la découverte du service AWS Deepracer pour apprendre les bases et essayer de rentrer en piste.
1/ Le commencement
Tout d’abord, qu’est-ce que AWS Deepracer ? AWS Deepracer est une compétition organisée par AWS où l’on entraîne des voitures sur différents circuits dans le but de faire les meilleurs temps. Le but étant d’apprendre et de s'entraîner au machine learning dans un environnement simplifié. Ainsi je lance ma propre écurie, accompagnée de mes meilleurs assistants, Google et Udemy, dans le but de prouver à Thomas, CE2 classe B, que j’étais effectivement le prochain meilleur pilote du millénaire.
Premier objectif de l’écurie, trouver une voiture. AWS propose un modèle à l’échelle 1/18ème, capable d’embarquer un algorithme d’apprentissage ainsi que des capteurs pour éviter de filer droit dans les virages (spoilers : ça va arriver).
Information qui va vous surprendre, ce modèle pour AWS est disponible sur… Amazon. Le temps de se remettre de cette information, un deuxième coup de massue vient nous étourdir, le prix, 400$.
Sans aucune corrélation avec cette information, l’écurie prend la décision stratégique de favoriser les courses virtuelles pour le moment.
Pour autant, avant de se lancer, il est important de comprendre certaines terminologies pour partir sur de bonnes bases.
Agent : Le système qui interagit avec l'environnement.
Politique : Une politique définit comment un agent va se comporter dans un état spécifique.
Épisode : La séquence entière d'état et d'action jusqu'à l'état terminal.
Ensuite, le point crucial, comment fonctionne l’apprentissage par renforcement. L'apprentissage par renforcement consiste à apprendre les actions à mener, à partir d'expériences, de façon à optimiser une récompense quantitative au cours du temps.
L'agent (notre voiture) est plongé au sein d'un environnement (circuit) et prend ses décisions (tourner/accélérer) en fonction de son état courant. En retour, l'environnement procure à l'agent une récompense, qui peut être positive ou négative. Cette récompense, nous la définissons dans notre algorithme selon différents critères.
En résumé, l'agent cherche, au travers d'expériences itérées, un comportement décisionnel optimal (politique), en ce sens qu'il maximise la somme des récompenses au cours du temps.
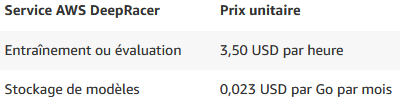
Après la technique, une bonne nouvelle pour le comptable, moi-même, les dix premières heures d'entraînement ainsi que cinq giga de stockage pour les modèles sont gratuits. Après, les tarifs sont acceptables, même si tenir à l'œil les temps d'apprentissage me paraît une bonne idée pour éviter l’explosion des coûts et la fermeture prématurée de mon écurie.
2/ La mise en place
Il est maintenant temps de mettre les mains dans la mécanique, virtuelle bien sûr, mais mécanique quand même. Rendez-vous sur la région us-east-1, unique région où le service est disponible pour l’instant. C’est le moment de créer notre premier modèle, on choisit un nom et un circuit.
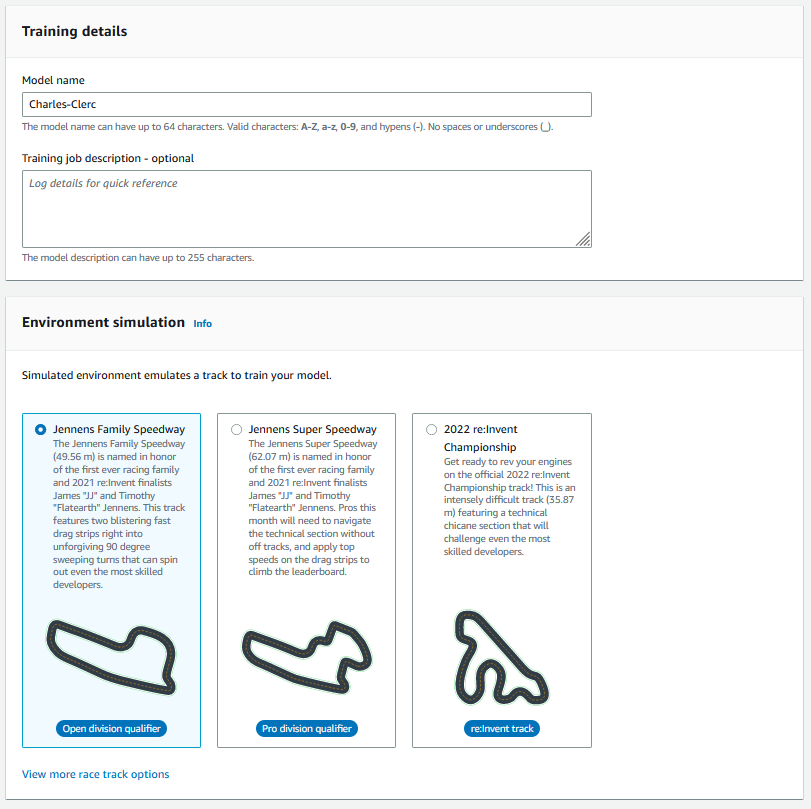
Pour mon premier circuit, j'ai choisi la facilité avec le “Jennens Family Speedway”, ensuite trois types de courses existent :
- Time trial : faire le tour du circuit le plus rapidement possible
- Object avoidance : faire un tour tout en évitant des objets positionnés sur la piste
- Head-to-head racing : une course contre des bots sur le circuit
Même si le dernier est excitant, on va d’abord se familiariser avec la piste et notre nouveau pilote dans le time trial.
Ensuite il reste trois choses assez importantes à configurer pour commencer :
- La configuration des hyperparamètres
- Le champ d'action de la voiture
- La fonction de récompense
A - La configuration des hyperparamètres
Tout d’abord, que sont les hyperparamètres ? Ce sont tous les paramètres qui permettent de contrôler l'apprentissage du modèle. Ils dépendent du type d'algorithme choisi. Pour l'apprentissage de notre modèle, AWS nous donne deux choix PPO (Proximal Policy Optimization) ou SAC (Soft Actor-Critic).
Le PPO utilise l'apprentissage sur les politiques, ce qui signifie qu'il apprend à partir des observations faites par la politique actuelle explorant l'environnement.
Le SAC utilise un apprentissage hors politique. Ainsi il peut utiliser les observations faites lors de l'exploration de l'environnement dans le cadre des politiques précédentes.
Pour synthétiser le choix de l'un plutôt que de l'autre, le SAC étant hors politique fait qu'il est de façon générale plus efficace et nécessite peu de données. À l'inverse du PPO, étant conforme à la politique, plus gourmand mais plus stable qui permet un apprentissage potentiellement plus rapide.
Pour cette raison, nous allons partir sur le PPO. Il nous reste les différents hyperparamètres à renseigner.
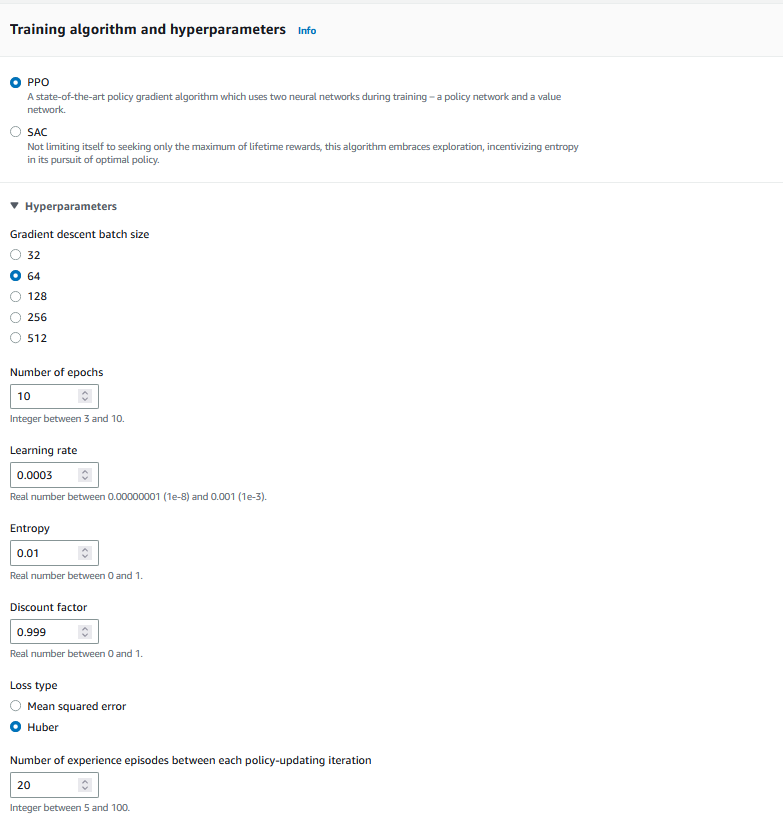
Pour une explication détaillée des différents paramètres, cette doc AWS est parfaite.
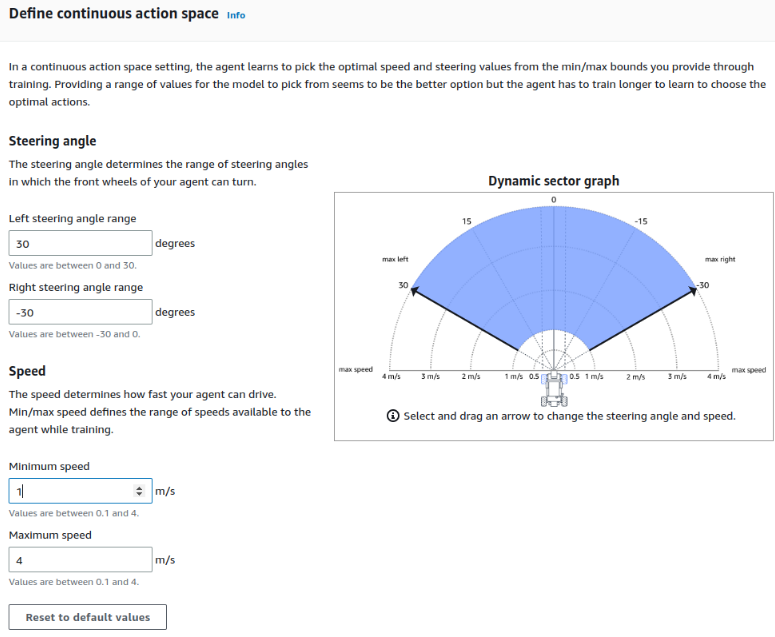
B - Le champ d'action de la voiture
Vient ensuite la partie un peu plus concrète, concernant les limites d'actions qu'on autorise pour la voiture. Bien évidemment, on peut se dire qu'on peut lui laisser apprendre ses propres limites.
Mais lorsqu'on se remémore les 3,5$ de l'heure, le guider un peu à ce niveau-là, pour éviter de perdre 4h et 14$ semble une bonne idée. Surtout s'il fonce à 4m/s dans une suite de virage.
Pour le premier tour et étant donné que le circuit est plutôt simple, j'ai décidé de tout mettre aux maxima et interdit de ralentir en dessous d'un mètre par seconde.
C - La fonction de récompense
On va commencer avec une fonction assez simple, mais qui essaye de maximiser la tenue de route. Le but étant, avant de faire le record en piste, d’au moins finir un tour.
def reward_function(params):
'''
Example of rewarding the agent to follow center line
'''
# Read input parameters
track_width = params['track_width']
distance_from_center = params['distance_from_center']
# Calculate 3 markers that are at varying distances away from the center line
marker_1 = 0.1 * track_width
marker_2 = 0.25 * track_width
marker_3 = 0.5 * track_width
# Give higher reward if the car is closer to center line and vice versa
if distance_from_center <= marker_1:
reward = 1.0
elif distance_from_center <= marker_2:
reward = 0.5
elif distance_from_center <= marker_3:
reward = 0.1
else:
reward = 1e-3 # likely crashed/ close to off track
return float(reward)
3/ L’entrée en piste
Tout est prêt, la piste, le pilote, la voiture. Le grand moment est enfin arrivé. L’excitation de voir s’allumer le moteur, les pneus filés sur l'asphalte. Une seule phrase me vient en tête au moment de démarrer :
Une route c’est le meilleur endroit pour réfléchir, te rappeler d’où tu viens, savoir où tu vas. (Dom. Fast and Furious 7)
Et j'espère vraiment que mon modèle arrivera aux bonnes conclusions avant le premier virage.
Je pense que personne n'est vraiment surpris du résultat mais les virages ne sont clairement pas le point fort de mon modèle. D'ailleurs, on est assez proche de ce qu'on pourrait attendre du pilotage d'un enfant de quatre ans. Surprenant ? Non.
Quelle suite donner à cette première expérience ? Tout d'abord, il est clair que pour arriver à un meilleur résultat, il faudra plus que cinq minutes d'entraînement à mon modèle. Ensuite, AWS nous fournit bon nombre d'informations pour essayer de corriger le tir et de fournir une meilleure éducation à notre agent.
- Tout d'abord à travers des logs d'entraînement :

- Ensuite du graphique des récompenses lors de l'entraînement :
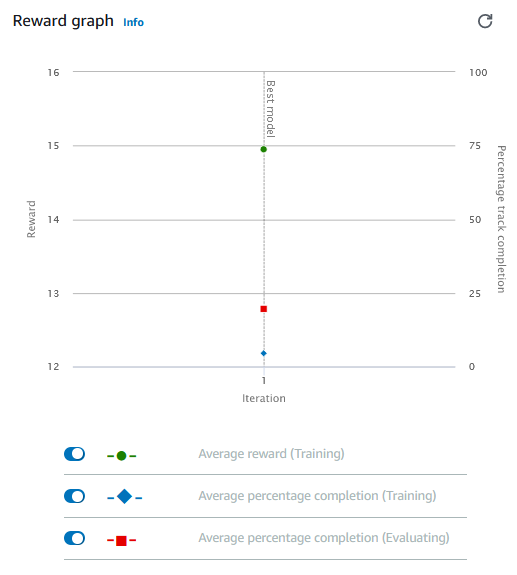
Enfin, le modèle n'est pas le seul à devoir continuer son apprentissage. Approfondir ses propres connaissances, tester différents paramétrages, différents champs d'action pour notre agent, voilà la base pour atteindre de meilleurs résultats et qui sait, peut-être toucher la récompense suprême.
Conclusion
Que retenir ? Pour moi, AWS Deepracer est un bon outil pour se familiariser avec certains concepts-clés du machine learning. Le principal avantage venant du fait que l’on aille droit à l’essentiel. Pas besoin de devoir apprendre à utiliser différents outils mais on se concentre uniquement sur le paramétrage des algorithmes et la fonction de récompense. Avec une visualisation concrète de ce que notre agent est en train de faire via AWS RoboMaker rendant l’apprentissage plus ludique. D’ailleurs, personnellement, ça a été une porte d’entrée dans ce domaine. Et si comme moi, vous souhaitez aller plus loin, il y a deux très bons livres que je suis en train d’étudier et que je vous conseille. Le premier, Doing data science, straight talk from the frontline (de Cathy O’Neil et Rachel Schutt) est un très bon livre pour avoir une vision globale du domaine, extrêmement complet. Et Data science for the layman (de Annalyn Ng et Kenneth Soo) qui m’a été conseillé pour sa clarté et ses exemples intuitifs, pour mieux comprendre les différents algorithmes utilisés.
Sur ces dernières recommandations, je retourne à mon apprentissage, proche de la piste, mais là-haut dans les nuages, rêvant un jour de podium.