

Le 20 septembre 2022 s’est tenue à la Cité de Congrès de Nantes la 7ème édition du Salon de la Data. Au programme de cette journée : 75 conférences sur divers thèmes du monde de la data tels que l’IA, la transformation et la gouvernance des données, le Data Mesh ou encore le MLOps. Ce salon gratuit, qui avait attiré pas moins de 1300 visiteurs et une trentaine d’entreprises l’année passée s’annonçait donc comme un temps fort du secteur de la data en France. C’est à quatre que nous avons décidé de nous y rendre, afin de représenter la Practice Data d’Ippon Technologies (Hector Basset, Léa Cavaree, Baptiste Mansire et Hugo Vassard). Nous vous proposons ici un résumé de quelques-unes des présentations nous ayant le plus marqués.
Maëlle Fouquenet : « Données et genre, quel intérêt pour le secteur public de travailler cette question ? »
C’est un fait, il y a en France plus de femmes que d’hommes : 51,6% de femmes en 2019. Si Maëlle Fouquenet, membre de Datactivist, nous rappelle cette proportion en guise d’introduction, son propos principal est de nous informer (voire nous alerter) sur l’importance de posséder dans le secteur public des données genrées, c'est-à-dire des données parmi lesquelles figure une variable “sexe” ou “genre”.

Source : https://www.cic-epargnesalariale.fr/fr/epargnants/actualites-et-publications/dossiers/2021-02-19_index-egalite-homme-femme/index.html
Cette absence de données genrées peut effectivement, dans de nombreux cas, être problématique et peut même être à l’origine de problèmes sanitaires ou économiques. Par exemple, parmi plus d’une centaine d’études scientifiques publiées en 2018 sur les effets de divers médicaments, 72% ne faisaient pas de distinctions entre hommes et femmes. De la même façon, alors que les femmes ont 47% de risque de plus qu’un homme d’être blessées dans un accident de voiture (et 17% de plus de mourir), il aura fallu attendre 2011 pour voir apparaître des mannequins crash-test femmes.
Quand les données genrées existent et sont analysées, c’est alors parfois un manque d’actions qui est à déplorer. Mme Fouquenet donne l’exemple de MELD, un algorithme de priorisation de patient attendant une greffe de foie aux USA. Ce dernier utilise comme critère le taux de créatinine (substance produite entre autres par le foie), la priorité étant donnée aux patients présentant un taux plus élevé. Cette substance est pourtant connue pour être produite en plus grande quantité par les hommes que par les femmes (car ils ont généralement plus de muscles). Malgré cela, il aura fallu attendre plus de 10 ans avant qu’une action soit prise pour supprimer ce biais de l'algorithme.
Et lorsque des actions sont prises, comme la mise en place de l’arrêt à la demande dans les transports en commun de certaines métropoles pour rassurer et limiter les problèmes d’agression, il ne faut pas oublier de mettre en place une évaluation de ces actions. Ce n’est que grâce à des évaluations montrant des améliorations que la boucle est bouclée et que les données genrées auront réellement servi.
En conclusion : une conférence très intéressante, riche en exemples et qui fait ouvrir les yeux sur un problème parfois insoupçonné. Le replay est disponible ici.
Sylvain Ferrec et Guillaume Rodriguez : « Pôle emploi : optimiser le remplissage du profil utilisateur grâce aux pouvoirs de l’IA »
À leur arrivée à Pôle emploi, tous les nouveaux candidats passent par une étape de remplissage de leur dossier via le portail Pôle emploi. Les demandeurs d’emplois disposent cependant bien souvent déjà d’un CV contenant toutes les informations nécessaires, mais ils se voient contraints de saisir à nouveau ces informations.
Afin donc de diviser ce temps de remplissage par deux et au passage d’augmenter le nombre d’informations présentes sur les profils des utilisateurs, Sylvain Ferrec (Data Scientist à la DSI Pôle emploi) et Guillaume Rodriguez (consultant Sopra Steria Next) ont mis en place une chaîne IA composée de six étapes permettant de remplir automatiquement le dossier d’un candidat à partir de son CV. Cette chaîne est composée de six briques :
- Vérification du format du CV (accepte seulement les PDF)
- Conversion du PDF en PNG
- Détection des zones dans le CV (contact, compétences, expériences, …)
- Extraction du texte dans chaque zone
- Formatage du texte extrait
- Matching entre les compétences du CV et le référentiel de compétences de Pôle emploi

Source : https://emploi-conseils.com/comment-faire-un-cv-efficace/
Pour détecter les quatre types de zones d’un CV (étape 3), M. Ferrec et M. Rodriguez ont utilisé un réseau de neurones du type Faster RCNN entraîné par transfer learning sur un dataset composé de 14 000 CV annotés manuellement. Du côté du matching de compétences (étape 6), c’est un word embedding fastText qui a été utilisé (technique de NLP permettant de représenter des mots sous forme de vecteurs).
Si les résultats obtenus ont bel et bien permis de diviser le temps de remplissage des dossiers par deux et que 100 000 CV ont déjà été traités par leur solution mise en production en 2021, nos speakers pointent du doigt deux problèmes d’une telle solution basée sur une chaîne IA.
- Tout d’abord un constat assez évident : si une brique tombe, tout tombe. Il faut donc prévoir des mécanismes de retry pour chaque étape.
- Mais il faut également faire attention à la dérive des performances : puisque la sortie d’une brique est l’entrée de la suivante, il faut que chaque maillon ait individuellement d’excellentes performances pour que toute la chaîne ait de bonnes performances. Par exemple, si chaque étape est performante à 90%, la performance finale de la chaîne sera, elle, bien inférieure à 90% (car 0.9 x 0.9 x 0.9 x … tend vers 0).
En somme un excellent REX d’une solution basée sur de l’IA mise en production. Le replay est disponible ici.
Jacques Priol : « Données publiques, données privées : comment mettre la data au service de l’intérêt général ? »
L’entendre n’est plus une surprise : le volume de données créé, échangé et stocké est grandissant. Il en est de même pour les données générées et utilisées par les collectivités territoriales. Des acteurs publics produisent eux aussi des données d’intérêt général (État, INSEE). À cela s’ajoutent les données d’intérêt territorial générées par des entreprises privées (Waze, Airbnb, Yuka).
L’exploitation de ces données peut être d’une grande utilité pour les territoires (compréhension des dynamiques, gains à réaliser sur l’utilisation de l’eau ou amélioration de services rendus à la population). Se poser la question de l’utilisation de ces données pour l’intérêt général est donc légitime.
De nombreuses parties prenantes sont concernées et doivent être impliquées dans ce projet. De ce fait, des problématiques émergent. Qui peut ou doit partager ses données ? Quelles données ? Qui peut y accéder, qui peut les utiliser, dans quel but et à quelles conditions ? Comment résoudre les problématiques de stockage et de coût ? Comment empêcher que les données soient utilisées à l’encontre de l’intérêt général ?
La solution exposée par Jacques Priol, et c’est aussi le sujet que porte l’organisation Observatoire Data Publica qu’il préside, c’est la création de cadres de confiance. Ce dernier inclut tous les acteurs concernés (collectivités territoriales, services publics, entreprises privées, parfois même les citoyens). C’est un cadre qui définit des règles, des principes, des objectifs et des méthodes autour de l’aspect éthique, juridique et économique de la collecte et de l’utilisation des données.

Source : https://acteurs.tourismebretagne.bzh/mieux-accompagner-demain-porteurs-de-projet-touristique-bretagne/
Des solutions existent déjà. Par exemple, Nantes est la première métropole française à créer une charte éthique de l’usage de la donnée à l’échelle de son territoire. Elle décrit 13 principes qui ont pour but de cadrer l’utilisation de ces données d’intérêt général. En Occitanie, un label de respect de leur charte de partage de la donnée indique la confiance que l’on peut accorder à tel ou tel acteur. En Centre-Val de Loire, la région entreprend la création du “Climate Data hub”, une plateforme de données pour permettre le partage des données servant à la lutte contre le réchauffement climatique dans un cercle de confiance.
Tous ces exemples nous prouvent que des solutions sont possibles. Cependant, ils nous montrent aussi qu’il n’existe pas une solution unique, mais plutôt autant de solutions que de cadres de confiance.
Il est donc nécessaire de construire ce cadre avec tous les acteurs afin que chaque cas particulier puisse être pris en compte. Il faut aussi que chaque acteur se sente impliqué pour qu’il soit le plus à même de s’approprier et donc de respecter la charte d’utilisation et de partage.
Pour plus d'informations sur le sujet, je vous conseille de lire le cahier n°1 de l’observatoire que vous pouvez retrouver sur leur site internet. Le replay de la conférence est disponible ici.
Benjamin Cohen-Lhyver & Adrien Toullier : « XAI et intelligibilité des modèles de Machine Learning »
Le Machine Learning commence à s’implanter dans l’ensemble des secteurs d’activité, et est même déjà omniprésent dans certains. Son adoption se retrouve cependant freinée dans de nombreux secteurs ou entreprises à cause d’un de ses plus gros défauts : le manque d’explicabilité et d'interprétabilité. Ces manques peuvent alors être à l’origine d’une défiance envers le Machine Learning, ainsi que d’un refus ou d’une mauvaise interprétation de ses résultats. Rendre un modèle de Machine Learning explicable et intelligible est donc capital afin de faciliter son acceptation et utiliser ses résultats de façon pertinente.
Tous les algorithmes ne sont pas égaux en ce qui concerne leur explicabilité. Si certains sont explicables assez naturellement (comme la Régression Linéaire) ou même partiellement (comme les Random Forest avec l’importance des variables), d’autres en revanche ne le sont que très difficilement et peuvent s’apparenter à de véritables boîtes noires (c’est souvent le cas en Deep Learning). Il existe heureusement des approches agnostiques de l’algorithme utilisé, comme la XAI (eXplainable Artificial Intelligence) et la MLI (Machine Learning Intelligibility), qui permettent de mieux comprendre les performances et les résultats d’un modèle.
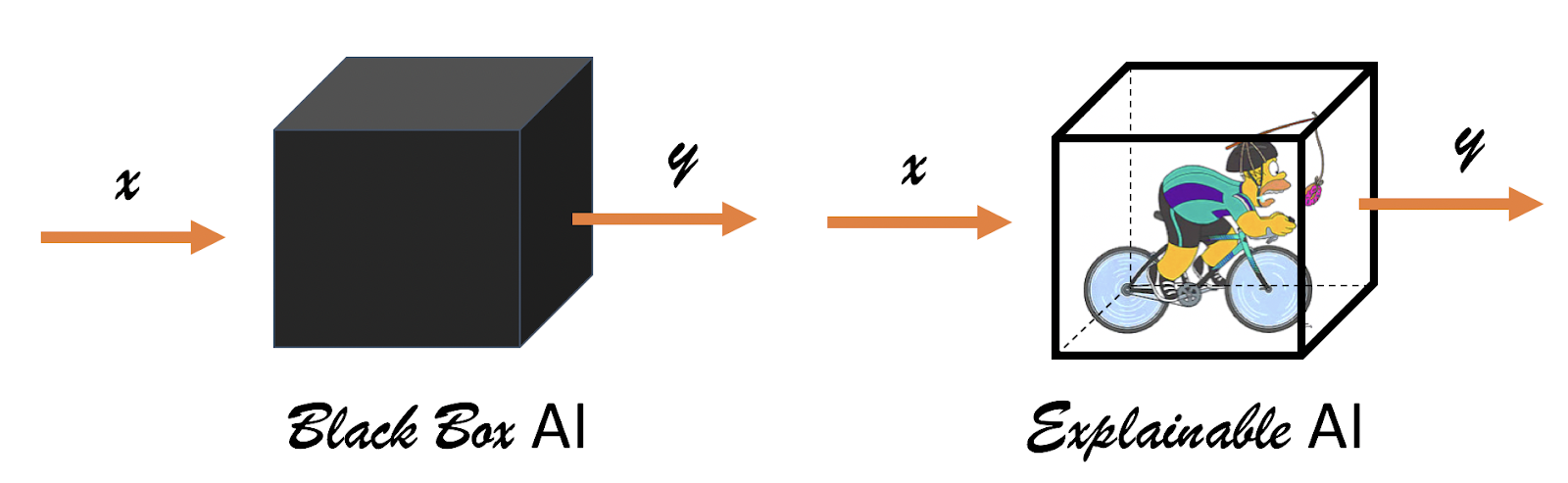
Source : https://github.com/venergiac/xai?files=1
Il existe 4 grandes familles d’indicateurs permettant d’améliorer l’explicabilité d'un modèle, elles-même rassemblées en 2 sous-familles :
- l’explicabilité globale, dont le but est d’expliquer le comportement général du modèle sur l’ensemble du dataset
- l’étude de dépendance (Partial Dependence Plot, Accumulated Local Effects)
- l’importance des variables (Permutation Feature Importance)
- l’explicabilité locale, dont le but est d’expliquer le comportement du modèle sur une observation en particulier
- la détection de valeurs aberrantes (Shapley Values)
- l’explication par l’exemple (Protodash)
Afin de pouvoir détecter les clients susceptibles de se désabonner et de mettre en place des actions préventives, Canal+ International utilise un algorithme de Machine Learning permettant de prédire le risque de churn. Cependant, le résultat donné n’était initialement qu’un pourcentage de risque, sans autre détail, ce qui ne permettait pas de mettre en place les solutions pertinentes et a pu amener à une incompréhension, voire une défiance à l'égard de ce résultat.
La mise en place de la XAI autour de ce modèle de churn a permis d’affiner grandement la compréhension des résultats et même de confirmer des comportements du modèle avec ce que le métier connaissait déjà de causes potentielles de perte de clients. Ainsi, avec la méthode des valeurs de Shapley il est désormais possible de savoir exactement quelles sont les variables qui ont amené le modèle à prédire un risque de churn, et dans quelles proportions. Un exemple qui a été cité est celui d’une cliente avec un risque de churn important, dont 13% du score est expliqué par le simple fait qu’elle possède un décodeur trop ancien. Une action simple et rapide de remplacement du décodeur peut alors être mise en place.
Ce cas d’utilisation et cet exemple montre bien l’intérêt de la XAI pour une utilisation pertinente des modèles de Machine Learning qui sont de plus en plus omniprésents dans nos vies. Sans oublier que d’autres aspects fondamentaux, voire légaux, peuvent être couverts par celle-ci, comme détecter dans un modèle un biais basé sur des critères interdits (par exemple l’origine ethnique), ou devoir être en mesure d’expliquer à un client la raison d’une décision (par exemple pourquoi un prêt lui a été refusé).
Le replay est disponible ici.
Paul Peton : « MLOoops : comment faire échouer la mise en production du ML? »
Aujourd’hui, 85% des projets de Machine Learning n'atteignent pas le stade de la mise en production. Une partie importante de ces échecs peut s’expliquer par un manque de bonnes pratiques dans le développement des modèles, ainsi que par le fait que le sujet de leur industrialisation, pourtant capital, n’est que trop peu souvent pris en compte dès les premières étapes d’un projet. Le MLOps, dont on entend de plus en plus parler et qui pourrait être très rapidement résumé en l’application des pratiques du DevOps appliquées au monde du ML, permet de réduire les risques d’échecs tout en réduisant le time to market.
Schéma du workflow MLOps
Source : https://blent.ai/le-metier-de-machine-learning-engineer/
Bien que la mise en production d’un modèle de Machine Learning puisse être comparée à celle d’autres solutions informatiques comme un logiciel ou un site web, il y a quelques spécificités à ce domaine qui amènent une complexité supplémentaire :
- la reproductibilité des résultats : que ça soit pour la compréhension du modèle, le suivi de sa performance, ou même pour des raisons légales, il est capital d’être en mesure de pouvoir reproduire un résultat. Seulement, celui-ci ne va pas uniquement dépendre du code et des versions des dépendances, mais également des hyper-paramètres et des données qui ont été utilisées pour l'entraîner. Ainsi, il faut pouvoir versionner les datasets et établir un Model Registry.
- la dérive des modèles : contrairement à une solution logicielle, les performances d’un modèle de Machine Learning ne sont pas forcément constantes dans le temps. Ainsi, s’il n’est pas réentraîné et mis à jour régulièrement, il risque fortement de finir par dériver et de ne plus être pertinent. Ceci nécessite de mettre en place un système de monitoring et de réapprentissage.
Parmi les erreurs le plus souvent commises et pouvant impacter négativement un projet de ML, on trouve notamment :
- la non refactorisation du code, laisser chaque Data Scientist avoir ses propres fonctions dans son Notebook.
- ne pas avoir des environnements séparés (typiquement dev, Q&A, prod), tout en sachant que si l’on met cela en place il faut alors être certain que les modèles de dev ont bien été entraînés sur les données propres de prod, avec les problèmes de réplication des données et de RGPD que cela apporte,
- ne pas assurer la reproductibilité (fixation du code, des dépendances, des hyper-paramètres d’entraînement, des datasets),
- ne pas versionner les modèles et faire des réentraînements inutiles, ou stocker un trop grand nombre d’images Docker (augmentation du coût et du risque de failles de sécurité),
- ne penser qu’à une approche Near Real Time (souvent via un endpoint HTTP permettant d’appeler un modèle, ce qui apporte alors une problématique autour de l’authentification) et ignorer les scénarios de batch,
- ne pas monitorer les performances du modèle, ce qui amène un risque de non détection d’une potentielle dérive (Data Drift ou Concept Drift).
Ainsi, la mise en place des pratiques MLOps va principalement permettre les choses suivantes :
- diminuer les coûts (moins d’opérations manuelles qui sont sources d’erreurs et coûteuses en temps, optimisation des ressources, etc.),
- augmenter la qualité (opérations et tests automatisés et systématiques, pipeline de CI/CD ML, versioning des modèles, monitoring de la pertinence des modèles, etc.),
- diminuer le temps de mise en production ou de mise à jour des modèles
Tous ces éléments, qui peuvent chacuns être résolus grâce au MLOps, montrent l’importance de cette approche et d’importer dans les projets de Data Science les bonnes pratiques du monde du développement logiciel.
Le replay est disponible ici.
Mick Levy: « Data Mesh: Comment Spiderman établit les concepts clé du data management ? »
Buzz word ou véritable nouveau système de pensée ? Ce qui est certain c’est que le data mesh est en vogue et plein de promesses.
Pensé en 2018 par Zhamak Dehghani, puis exposé en détails dans son livre Data Mesh: Delivering Data-Driven Value at Scale (2022) le data mesh est une nouvelle façon de penser la data dans une entreprise.
Définition : “A decentralized socio-technical approach in managing and accessing analytical data at scale”.
Quatre mot clés à retenir de la définition de Zhamak Dehghani :
- Socio-technical : Le data mesh n’est pas une technologie, c’est une approche globale qui embarque le volet technique mais également organisationnel.
- Decentralized : Une vision décentralisée qui marque une rupture majeure avec les précédentes approches de data management plus data centric (data warehouse, data lake)
- Analytical data : On s'intéresse aux données analytiques
- At scale : L’enjeu est aussi le passage à l'échelle.
Revenons un peu sur l’historique du data management :
- Data Chaos (il y a une quarantaine d'années) : C’est l’ère de l’infocentre. Beaucoup de flux se croisent entre les différents services, très peu de maîtrise et de gouvernance et une grande complexité du SI.
- Data Centric : Bien que différentes, les approches data warehouse et data lake avaient une ambition commune de centralisation de la donnée. Le data warehouse est une approche notamment très adaptée pour des usages BI, faire des tableaux de bord ou mettre en place des indicateurs avec une forte cohérence des données. Cette approche possède néanmoins des limites concernant la qualité des données et de sa durabilité au sein de l’entreprise. Difficile également d’aller vers les nouveaux usages de la data en les passant à l'échelle (data science / MLOPS, temps réel…).
Le data mesh propose de résoudre les limites des approches data centric en décentralisant les équipes data en domaines et en les rapprochant encore plus des équipes métiers.
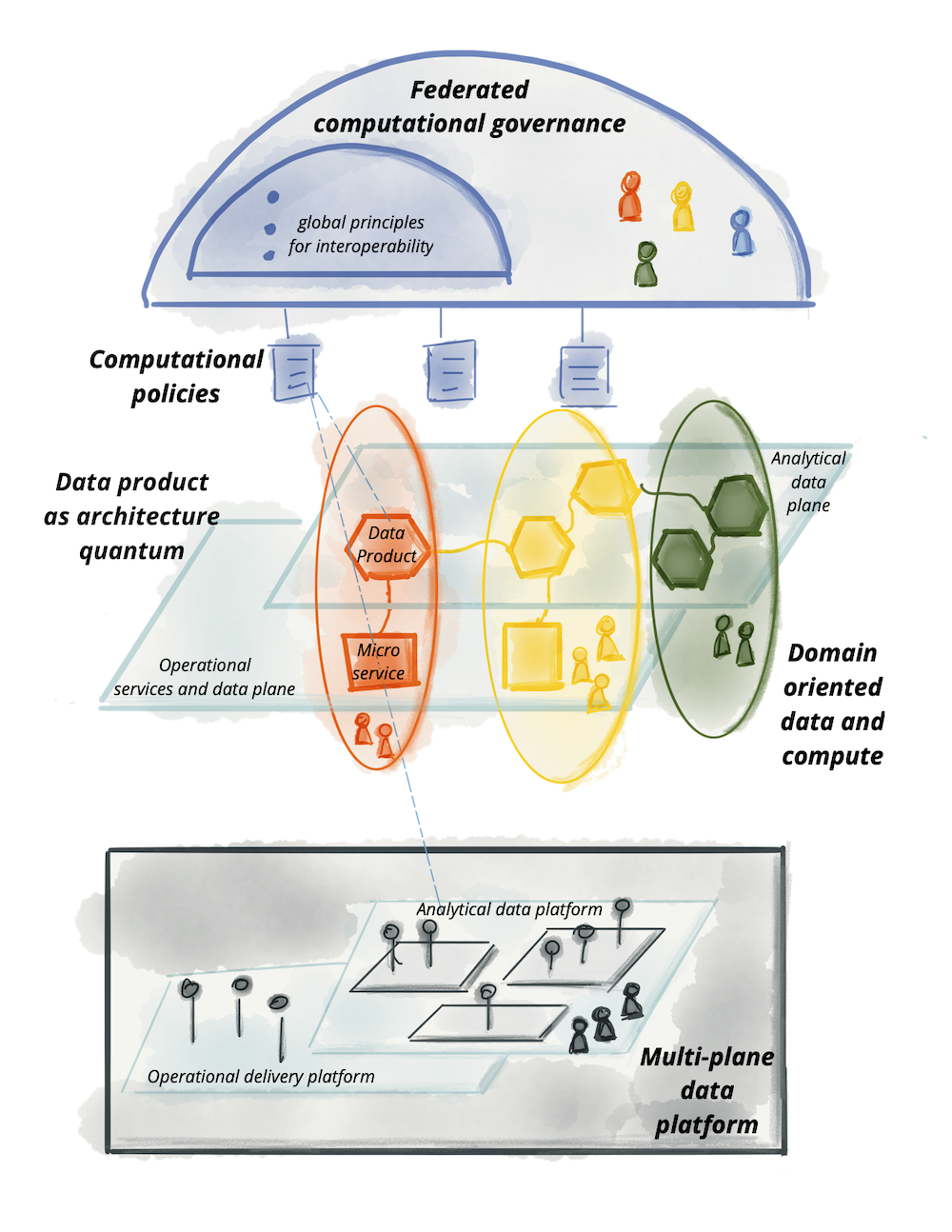
Schéma représentant le courant de pensée Data Mesh
Source : https://martinfowler.com/articles/data-mesh-principles.html
Le Data Mesh repose sur quatre piliers :
- Domain Oriented : Le data mesh propose un découpage métier. L’idée est de permettre à chaque métier de réaliser ses initiatives data de bout en bout. Les métiers travaillent avec des équipes data dédiées, sont responsables de leurs data, autonomes et indépendantes des autres domaines.
A contrario, dans une approche centralisée, l’équipe data s’occupe d’une multitude de données avec des équipes métier différentes ayant des usages différents. L’équipe data a donc des difficultés à maîtriser et comprendre les données d’un point de vue métier ce qui rend la qualité et la gouvernance de la donnée compliquée. Il est également difficile d’embarquer les métiers dans la data avec cette approche centralisée. - Data as a product: Les données deviennent le produit. Les produits sont découvrables, adressables, documentés, fiables, interopérables et sécurisés.
- Self-service data infrastructure as a platform : L’idée est de définir une infrastructure commune aux différents domaines de données. On mutualise des frameworks et modèles réplicables pour les différents domaines (API management, Data catalog, qualité, sécurité et partage de la donnée)
- Federated Governance: Garantir l'interopérabilité de domaines par la gouvernance des données. Mise en place de data catalog, de normes communes pour documenter l’ensemble des données.
Pour conclure, le data mesh est une approche globale qui s’articule sur 4 piliers interconnectés. Ce n’est pas un concept technique mais plus organisationnel, il invite à voir la donnée comme un produit créé par et pour des équipes métier en autonomie et permet aux entreprises data driven de tirer la pleine puissance du leurs données en se rapprochant des besoins et usages métiers.
“Le data mesh est une boussole, l’étoile du nord des entreprises data driven”
Le replay est disponible ici.
Conclusion
Ces conférences nous ont offert un véritable panorama du monde de la data à travers ses enjeux, ses problématiques, ses progrès, mais aussi les freins qui existent. C’est donc forcément enrichis que nous sommes tous les 4 ressortis de cette journée au Salon de la Data, synonyme en quelque sorte de rentrée 2022.
C’est aussi lors de la rentrée, en septembre, qu'a eu lieu cette année le salon Bigdata & AI Paris, sans doute le plus important rendez-vous data en France, regroupant chaque année 15 000 participants. L'opportunité de prendre à nouveau le pouls des problématiques actuelles et à venir dans le monde de la Data, et d'en reparler, pourquoi pas, à l'occasion d'un nouvel article. Stay tuned!


