
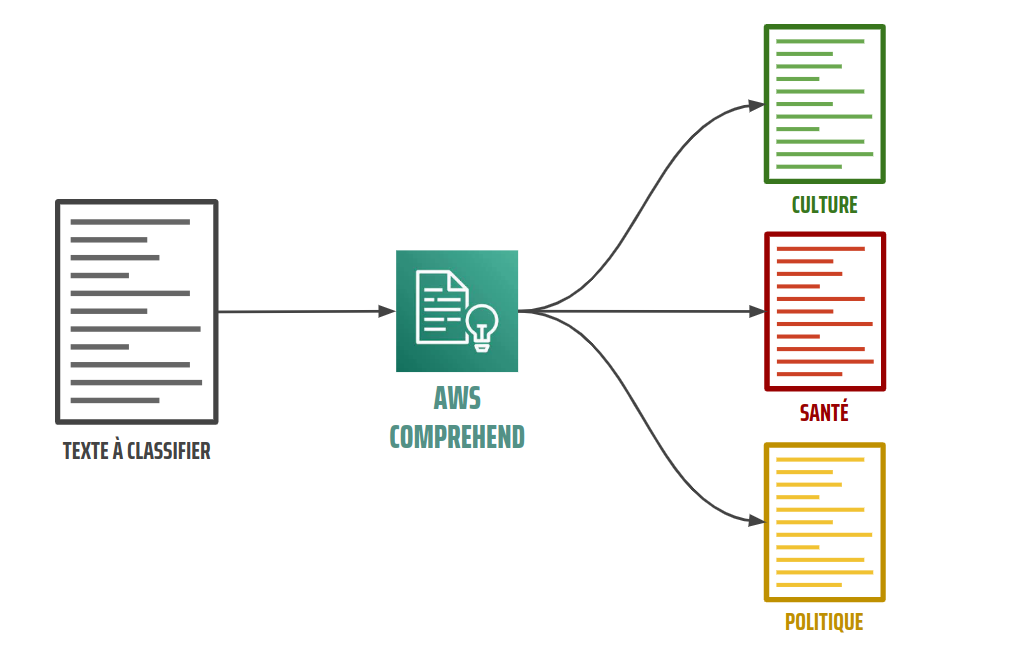
Ce n’est un secret pour personne : la quantité de données produites augmente chaque année. Elle atteindra même selon certaines estimations (Statista, Silicon) 180 zettaoctets en 2025 (soit 180 000 milliards de Go). Parmi ces données se trouvent des vidéos, du son, des images, mais également du texte. Bien qu’il ne soit pas simple de quantifier la proportion de ces données textuelles, il est en revanche relativement facile de se convaincre grâce à la multitude de sources de données existantes que cette part n’est pas négligeable (réseaux sociaux, services de communication, sources d’informations, etc.).
Pour tirer parti de ces données et les valoriser, il n’est pas rare de vouloir implémenter une classification automatique de texte (tri automatique de mails : cf. figure 1, indexation d’articles, analyse de tweets ou d’avis, etc.). Pour ma part, j’ai été confronté à cette tâche sur un projet consistant à créer un chatbot. Celui-ci était destiné à répondre à des questions concernant les compétences des collaborateurs d’Ippon. Afin de fournir des réponses adéquates, il était nécessaire de savoir quel type de question était posé. L’idée de classifier ces questions a donc rapidement été adoptée.
Dans cet article, je vous propose de découvrir AWS Comprehend, un service de NLP (Natural Language Processing) permettant, entre autres, de classifier automatiquement du texte en temps réel. Je vous présenterai d’abord de façon générale Comprehend. Puis, je vous détaillerai comment j’ai utilisé ce service pour implémenter un service de classification automatique de texte en temps réel sur mon projet de chatbot.
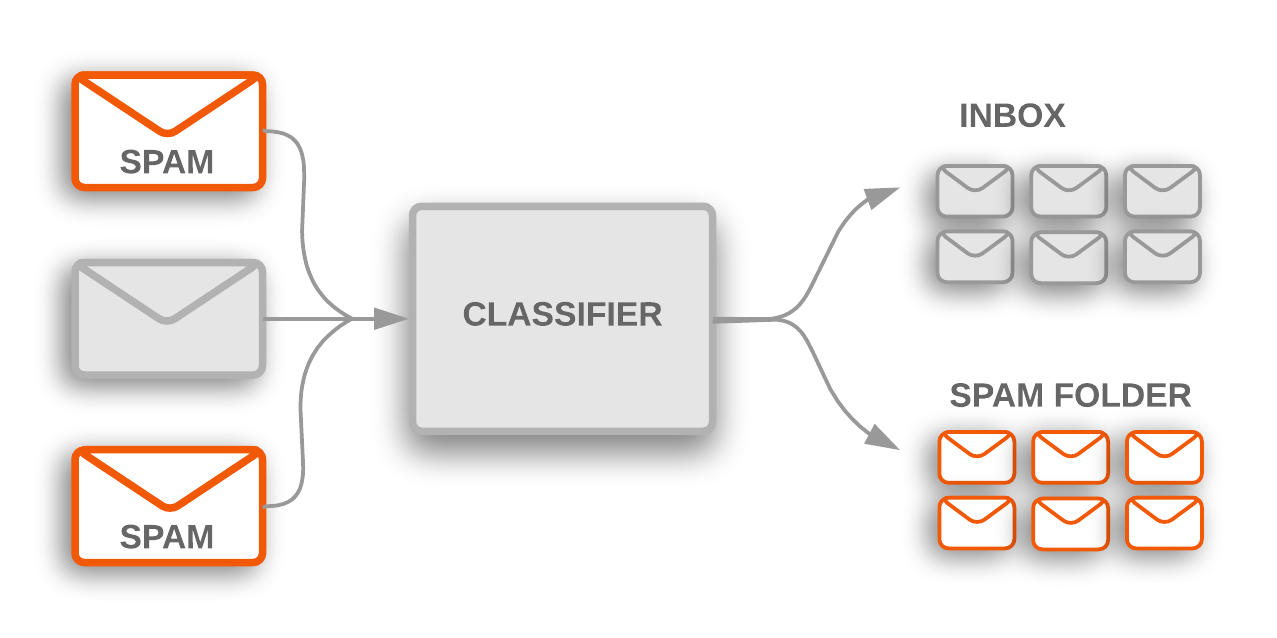
Figure 1 : Illustration de la classification de mails en catégorie “spam” / “non-spam”
Source : Google developer text classification guide
Présentation d’AWS Comprehend
Comprehend est un service d’AWS de NLP permettant d’extraire des informations et des relations dans des documents. Le terme “document” est très général et désigne tout texte (une phrase, un commentaire de plusieurs lignes, un article entier, etc.) dans un format brut (fichier .txt) ou plus riche (PDF, Word).
![]()
Figure 2 : Logo d'AWS Comprehend
Il est à noter qu’il existe un autre service appelé Comprehend Medical qui, comme son nom l’indique, permet de faire du NLP sur des données de santé afin d’extraire différentes informations et relations à caractère médical dans du texte (e.g. les entités “organes”, “posologie” ou “symptôme”). Dans cet article, je ne parlerai cependant pas de ce variant destiné au monde de la santé, mais du service plus générique Comprehend.
Organisation du service
Comprehend est composé de 3 sections différentes : “Built-in insights”, “Custom” et “Topic Modeling”, permettant chacune de répondre à différents besoins.
La partie Built-in Insights regroupe différents modèles de Machine Learning déjà entrainés (donc prêts à être utilisés, d’où le nom “built-in”) permettant chacun de fournir des informations (ou “insights”) différentes. Il est ainsi possible d’interroger ces modèles afin d’obtenir :
- Les entités d’un texte (noms, lieux, dates, organisations, etc.)
- La langue dominante d’un texte
- Le sentiment général d’un texte (positif, négatif, neutre ou partagé)
- Des informations syntaxiques (verbes, sujets, ponctuation, etc.)
- …
La partie Custom du service permet, elle, d'entraîner des modèles sur un dataset personnel afin d’obtenir des prédictions en accord avec son domaine métier. Il est ainsi possible d’entraîner des modèles de classification de documents ou de reconnaissance d’entités personnalisées retournant respectivement des classes et des entités parmi une liste que vous aurez préalablement définie en fonction de votre besoin métier.
Mise en situation : disons que nous souhaitons reconnaître automatiquement des références de produits dans des mails de réclamation client afin de rediriger les demandes vers les équipes appropriées. La reconnaissance d’entités personnalisées est alors exactement ce qu’il nous faut, puisque nous pourrons entraîner un modèle à reconnaître l’entité “référence produit” dans le contenu des mails.
Enfin, la troisième et dernière section de Comprehend, Topic Modeling, permet de regrouper des documents similaires en “topic”. Les topics sont déterminés automatiquement et les documents n’ont pas besoin d’être annotés (classification non supervisée). Ils doivent cependant y avoir un nombre suffisant de documents (au moins 1000) et chaque document doit être composé au minimum de 3 phrases.
Les modèles des 3 parties sont utilisables de façon synchrone ou asynchrone, à l’exception de la partie “Topic Modeling” pour laquelle le mode synchrone n’est pas disponible. Le mode synchrone permet d’obtenir des prédictions en temps réel pour 1 à 25 documents simultanément. Pour des batchs de plus de 25 documents, il faut utiliser le mode asynchrone : les prédictions sont alors déposées dans un bucket S3, mais un temps de latence est observé (au moins environ 5 minutes).
Facturation
La tarification de chacune des 3 parties est différente. Pour les modèles de la section “Built-in Insights”, la facturation se fait au nombre de caractères envoyés, par tranche de 100 caractères (appelée une unité) au prix de 0.0001$ / unité.
Pour le Topic Modeling, la règle est la suivante : 1$/tâche pour les 100 premiers Mo de données puis 0.004$/Mo au-delà de ces 100 premiers Mo.
Pour la section Custom le système est un peu plus complexe. Il y a tout d’abord des frais liés à la création de chaque modèle : 3$/heure d’entraînement et 0.5$/mois de frais de gestion. Enfin, il faut rajouter à cela les frais liés à l’utilisation des modèles qui diffèrent selon le mode d’utilisation (synchrone/asynchrone) :
- Pour des prédictions asynchrones, le tarif est de 0.0005$/unité envoyée. À titre d’exemple, si l’on souhaitait obtenir des prédictions sur un roman entier (environ 65 000 mots, soit approximativement 400 000 caractères, espaces inclus), le coût serait de 2$.
- Pour le mode synchrone, un endpoint doit vous être alloué (ressource permettant de traiter en temps réel les demandes de prédictions). Ainsi le prix dépend de la durée de fonctionnement de l’endpoint (à la seconde près) et de la performance souhaitée pour l’endpoint. Cette performance correspond au nombre d’unités par seconde que l’endpoint peut traiter et se compte en nombre “d’Unité d’Inférence” (UI). On peut donc au minimum attribuer 1 UI à l’endpoint ce qui correspondrait à un débit de 100 caractères par seconde. Le tarif appliqué est alors de 0.0005$/UI/seconde et est indépendant du nombre de requêtes effectuées. Ainsi, si l’on souhaitait par exemple mettre en place un système de classification de tweet (280 caractères) en temps réel fonctionnant de 8h à 18h du lundi au vendredi pour une charge à traiter d’environ 6 tweets par minute (soit 0,1 tweet/seconde ou 28 caractères/seconde), 1 UI suffirait largement. Le coût serait alors de 90$/semaine (0.0005$ * 1UI * 3600s * 10h * 5j).
Pour d'autres exemples concrets de projets utilisant Comprehend avec un calcul du coût total détaillé étape par étape, je vous conseille cette page d’AWS relative à la tarification de Comprehend.
Comment utiliser Comprehend pour classifier du texte
Le chatbot que j’avais à réaliser devait être capable de répondre en temps réel à 3 types de questions :
- “Qui est + [nom d’une personne] ?” (classe “WHO_IS”),
- “Qui s’y connaît en + [nom d’une technologie] ?” (classe “WHO_KNOWS_ABOUT”),
- “Comment ça va ?” (classe “HOW_ARE_YOU”).
La classification personnalisée de document de façon synchrone était donc exactement ce qu’il me fallait (dans le cadre du projet un document sera une question posée au chatbot).
Laissez-moi maintenant vous décrire les étapes permettant de parvenir à mettre en place cette classification.
Création d’un dataset
Pour entraîner un modèle de Machine Learning, il faut des données annotées. En temps normal lorsque l’on entraîne un modèle “from scratch”, il faut un très gros dataset avec beaucoup de données. Heureusement, avec Comprehend il ne suffit que de quelques exemples. Il est demandé d’avoir au minimum 10 exemples par classes, mais il est fortement conseillé d’en avoir plus de 50 afin d’obtenir de meilleures performances.
Le dataset peut prendre la forme d’un fichier CSV ou d’un Augmented Manifest File (fichier de sortie de SageMaker Ground Truth, un outil d’annotation de données d’AWS). J’ai personnellement utilisé le format CSV. Ce dernier doit alors respecter le format montré sur la figure 3. Notez que Comprehend ne supporte pas uniquement la classification multi-classe (aussi appelé single-label : chaque document est associé à une classe et une seule), mais aussi la classification multi-label (chaque document est associé à une classe ou plus).

Figure 3 : Format à utiliser pour le dataset au format CSV
Le dataset que j’ai constitué contenait en tout 390 documents. La figure 4 représente la répartition de ces documents sur les 3 classes. Pour information, il n’est pas nécessaire que ce dataset soit mélangé, Comprehend mélangera les données automatiquement avant l’entraînement. Aussi, sachez qu’il est possible, mais pas nécessaire, de fournir à Comprehend 2 datasets (un pour l’entraînement et un pour le test) afin d’avoir le contrôle sur les données qui servent à évaluer les performances du modèle. Si aucun dataset de test n’est précisé, Comprehend le créera lui-même aléatoirement à partir du dataset fourni. Il sera alors uniquement possible de savoir combien de documents ont été utilisés pour la phase de test, mais pas lesquels.
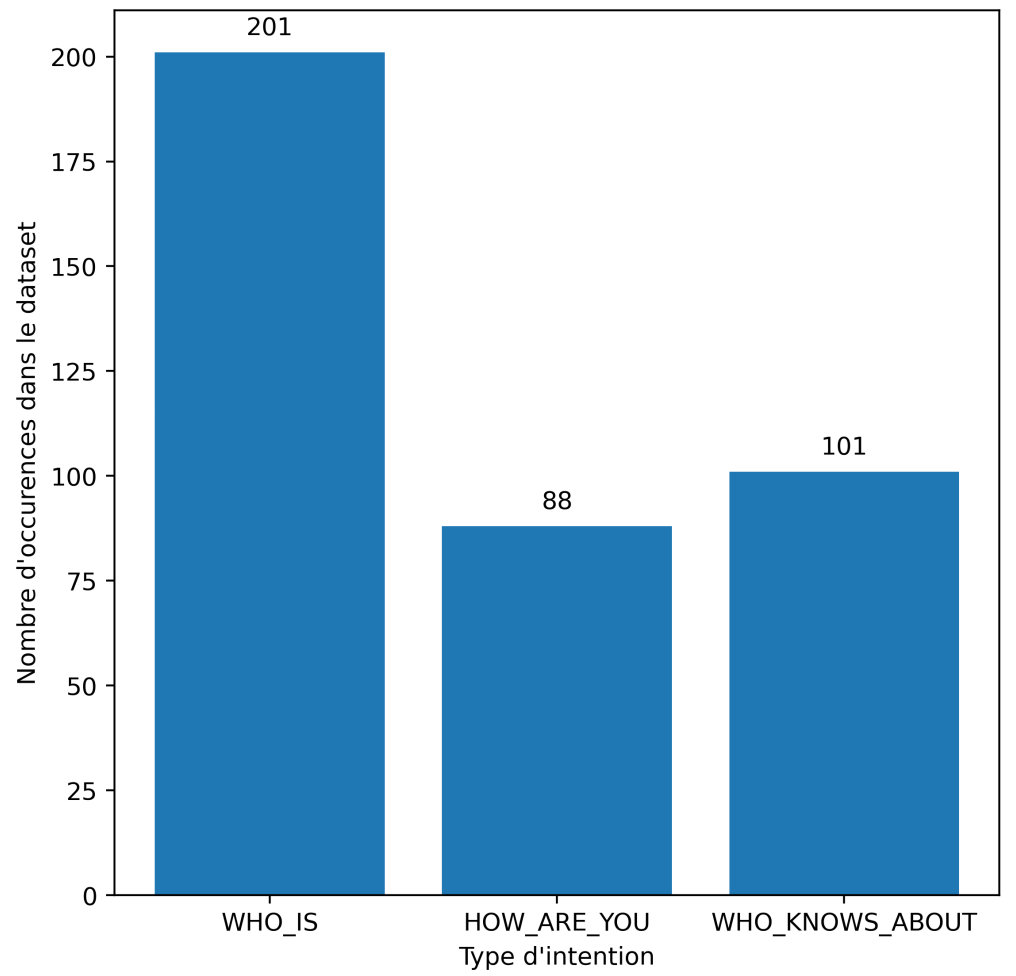
Figure 4 : Taxonomie du dataset utilisé pour la classification des questions
Lancement d’un entraînement
Une fois le dataset constitué et déposé dans un bucket S3, il est possible de créer un modèle en lançant un entraînement. Cela peut se faire depuis la console AWS (cf. figure 5) ou grâce à un appel API (cf. snippet 1).
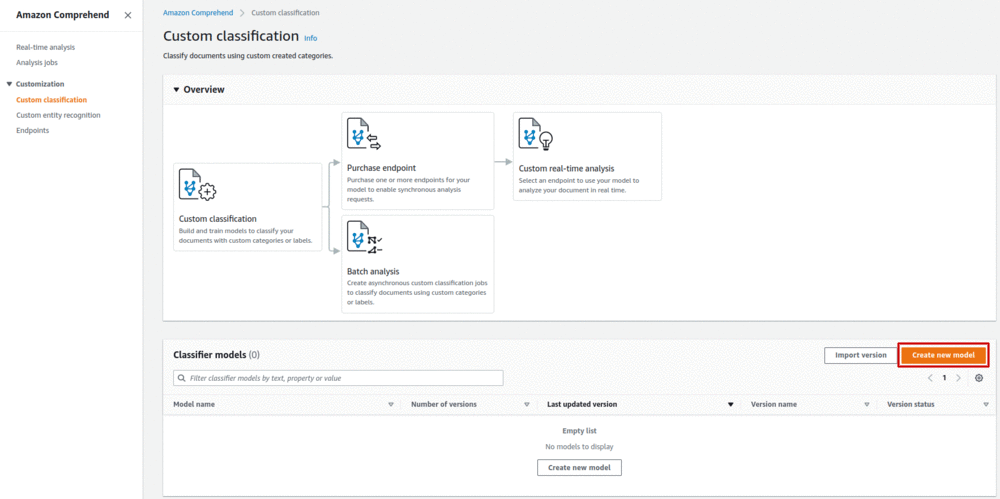
Figure 5 : Interface permettant de lancer un entraînement (bouton “Create new model”)
import boto3
comprehend_client = boto3.client('comprehend', region_name='eu-west-1')
response = comprehend_client.create_document_classifier(
DocumentClassifierName = <how to name your model>,
VersionName = <how to name the version of your model>,
DataAccessRoleArn = <role arn that allows Comprehend to read and write data in S3>,
InputDataConfig = {
'DataFormat': 'COMPREHEND_CSV',
'S3Uri': <s3 uri where the csv dataset is located>,
},
OutputDataConfig = {
'S3Uri': <s3 uri where to write confusion matrix>
},
LanguageCode = 'fr',
Mode = 'MULTI_CLASS'
)
document_classifier_arn = response['DocumentClassifierArn']
Snippet 1 : Code Python permettant de lancer un entraînement
À l’issue de l’entraînement (qui a dans mon cas duré une vingtaine de minutes), un modèle de classification (ou “document classifier” dans le jargon Comprehend) a été créé. Le modèle est alors visible dans l’onglet “Custom classification” et il est possible de visualiser différentes métriques permettant d’évaluer les performances du modèle (cf. figure 6). La matrice de confusion est, elle, disponible dans le bucket S3 spécifié au moment du lancement de l’entraînement.
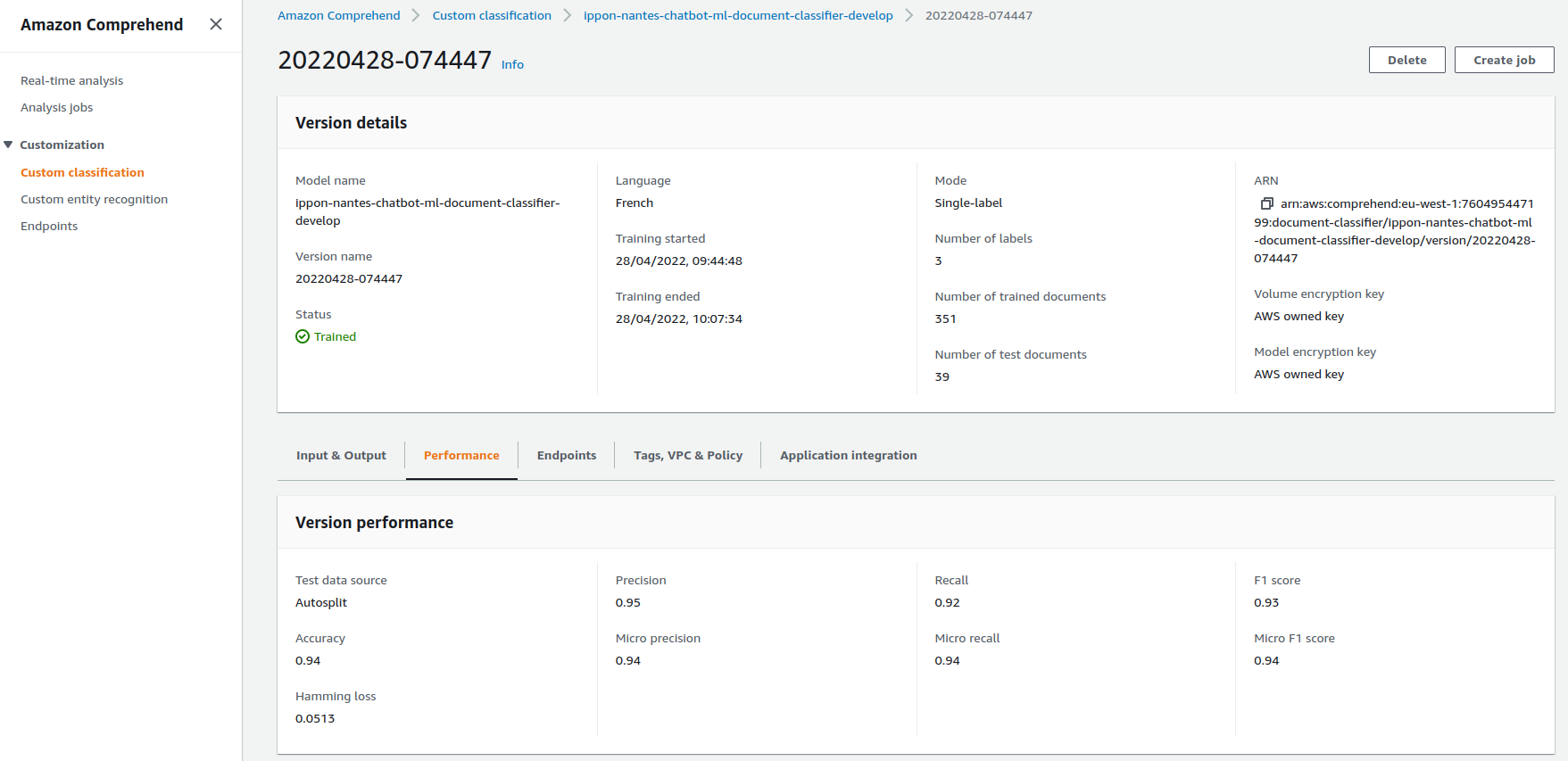
Figure 6 : Interface de visualisation des métriques du modèle créé
Création d’un endpoint
Une fois le modèle entraîné, il faut créer l’endpoint qui sera chargé de traiter nos demandes de prédictions en temps réel. Cela peut une nouvelle fois se faire via la console (onglet Endpoints > Create endpoint) ou grâce à un appel API (cf. snippet 2).
response = comprehend_client.create_endpoint(
EndpointName = <how to name the endpoint>,
ModelArn = document_classifier_arn,
DesiredInferenceUnits = <how many IU to use for this endpoint>
)
endpoint_arn = response['EndpointArn']
Snippet 2 : Code Python permettant de créer un endpoint
En une petite vingtaine de minutes l’endpoint est actif : la facturation commence alors (0.0005$/UI/seconde, soit 1.8$/UI/heure ou 43.2$/UI/jour). Notez qu’il est possible de modifier un endpoint existant pour changer le nombre d’UI attribué ou pour utiliser un autre modèle (cf. snippet 3).
response = comprehend_client.update_endpoint(
EndpointArn = document_endpoint_arn,
DesiredModelArn = <another document classifier arn>,
DesiredInferenceUnits = <how many IU to use for this endpoint>
)
Snippet 3 : Code Python permettant de modifier un endpoint
Obtention des prédictions
Une fois l’endpoint créé, il ne reste plus qu’à obtenir des prédictions. Il est possible de faire cela depuis l’onglet “Real time analysis” de la console, mais traditionnellement cela se fait plutôt sous la forme d’un appel API (cf. snippet 4). La réponse (cf. figure 7) est obtenue en environ 100ms.
response_document = comprehend_client.classify_document(
Text = "Qui est-ce qui fait du nodejs ?",
EndpointArn = endpoint_arn
)
Snippet 4 : Code Python permettant d’obtenir une prédiction en temps réel
{
'Classes': [
{'Name': 'HOW_ARE_YOU', 'Score': 0.010065868496894836},
{'Name': 'WHO_IS', 'Score': 0.00743631087243557},
{'Name': 'WHO_KNOWS_ABOUT', 'Score': 0.9824978709220886}
]
'ResponseMetadata': {
# RequestId, HTTPStatusCode, ...
}
}
Figure 7 : Réponse retournée par l’endpoint
Conclusion
Comprehend est donc un service de NLP relativement complet, proposant à la fois d’utiliser des modèles déjà entraînés pour des tâches communes (détection de la langue, analyse de sentiment, etc.), mais aussi d’entraîner ses propres modèles personnalisés de classification et de reconnaissance d’entités avec peu de données. Certaines tâches de NLP ne sont toutefois pas couvertes par ce service, comme la détection de paraphrases ou le question answering.
L’utilisation de Comprehend pour créer un modèle de classification personnalisée est simple, la documentation claire et les performances du modèle obtenu sur le projet chatbot sont bonnes (accuracy de 94 % sur 3 classes avec un dataset de 390 phrases). Ces résultats dépendent bien évidemment de la qualité des données ainsi que de la difficulté du problème. De plus, le mode synchrone a bien permis d'obtenir des prédictions en temps réel (~100ms). L’intégration d’une solution NLP est donc facilement réalisable, d’autant plus que tous les langages couverts par les SDK AWS sont utilisables pour interagir avec Comprehend.
En revanche, le coût de l’utilisation en temps réel de ce genre de modèle “custom” peut rapidement devenir très important. Si votre cas d’utilisation nécessite comme pour le projet chatbot de pouvoir obtenir des prédictions 24h/24 et 7j/7, il vous en coûtera environ 1300$/mois (prix correspondant à un endpoint possédant 1 unité d’inférence, c’est à dire capable de traiter 100 caractères par seconde, le minimum possible). Cette somme trop conséquente m’a poussé à mettre de côté le service Comprehend et à créer mon propre modèle de classification. La création de ce nouveau modèle (obtenu grâce au mécanisme de transfer learning) et son déploiement (via SageMaker, le service phare d’AWS pour l’industrialisation de modèles) fera l’objet de deux autres articles, à paraître bientôt.
En définitive, compte tenu de ces coûts de disponibilité très conséquents, la partie “Custom” de Comprehend semble plutôt adaptée à des besoins de prédictions asynchrones ou synchrones sur des plages de temps restreintes.
Voir les 2 autres articles de cette série :
