

Le besoin
Actuellement, je travaille sur une application architecturée en CQRS. Le CQRS (Command Query Responsability Segregation) est un pattern qui permet de séparer au sein d’une application le traitement pur métier (command) et la lecture (query).
Ainsi nous avons côté COMMAND une base PostgreSQL traditionnelle. Côté QUERY nous profitons de la recherche et des outils que propose Elastic Search. La réplication entre ces deux bases est faite grâce à Kafka. De plus, certaines données venant d’autres systèmes sont agrégées et jointes grâce à un composant Kafka Stream.
Voici un schéma simplifié pour mieux comprendre l’architecture de l’application :
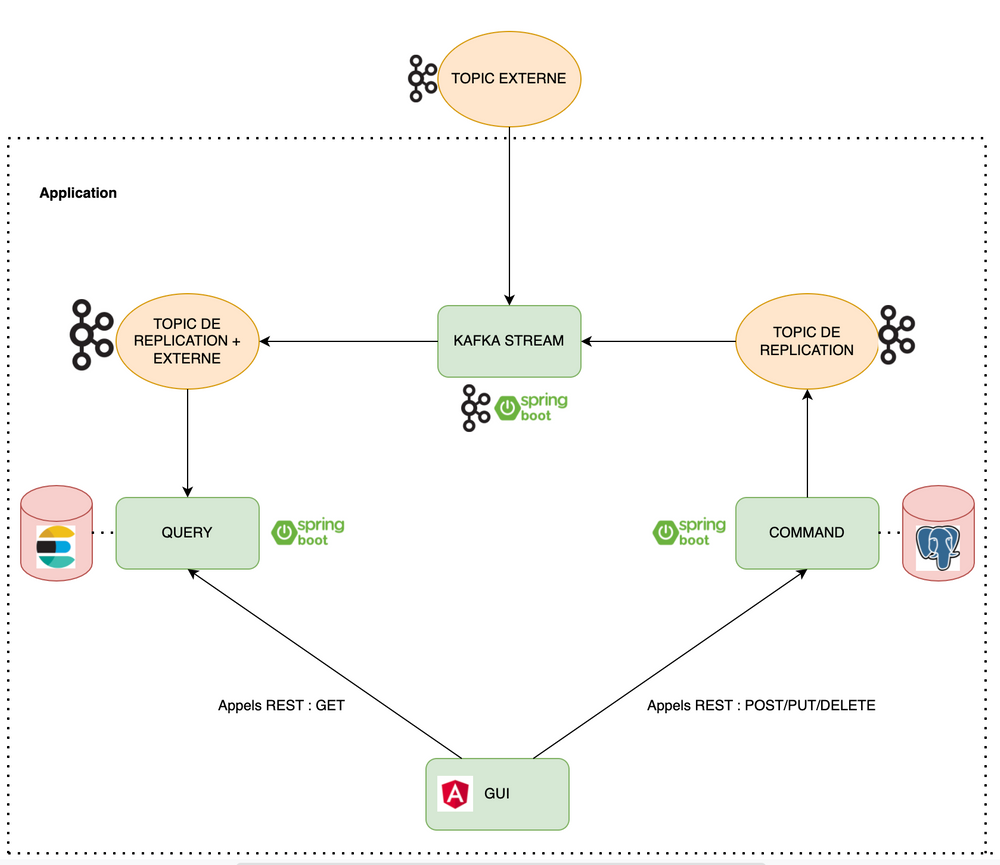
Schéma d'architecture
Le projet est déployé sur un namespace dans un Kubernetes, dans le cloud IBM. LogDna récolte toutes les logs et les déverse dans Splunk.
Notre besoin est le suivant : comment retrouver et identifier rapidement et de bout en bout une action utilisateur dans Splunk pour pouvoir facilement identifier et tracer les problèmes. L’idée serait donc d’avoir un identifiant de trace unique souvent appelé correlationId dans les logs pour suivre dans toute l'application les actions utilisateurs.
Spring Sleuth
Plutôt que de partir sur une solution “maison” en essayant de passer des ids dans nos méthodes, nous avons commencé nos recherches pour trouver une solution qui correspondait à notre besoin.
Nous nous sommes donc penchés sur Spring Cloud Sleuth. Sleuth permet d’améliorer les logs, spécialement dans les architectures micro-services. Cette libraire est une surcouche de la librairie de tracing Brave. Sleuth permet d’identifier facilement des jobs, threads ou requêtes. Sleuth utilise les librairies de logging telles que Logback ou SLF4J.
Elle donne la possibilité d’ajouter des identifiants uniques qui permettent de suivre et de diagnostiquer des problèmes dans les logs. Parmi ces identifiants uniques nous retrouvons le traceId et le spanId.
Trace & Span Ids
Le Trace Id est l’identifiant unique pour une request. Il ne changera pas jusqu’à la fin de l’opération. Cet identifiant est clairement celui dont on se servira pour notre application.
Le span Id correspond à une unité de travail ou une étape dans la progression de l’action. Lorsque le premier service reçoit une requête, le trace Id et le span Id sont identiques. Pour clarifier ces notions, voici un schéma venant de la documentation officielle :
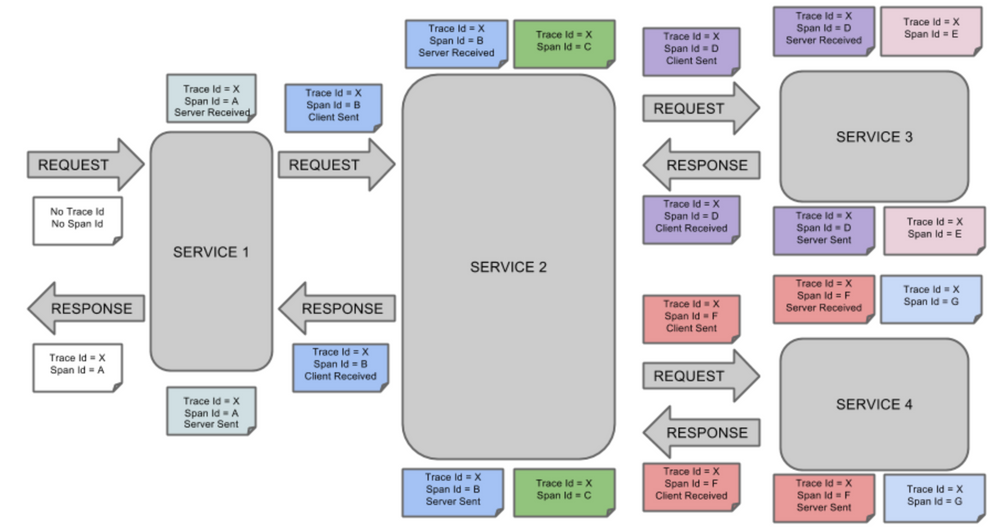
Représentation du fonctionnement de Spring Sleuth
Spring Sleuth permet de propager d’autres champs à votre main localement ou dans tous vos services. C’est la notion de Baggage.
Installation
Rien de plus simple. Il faut ajouter ces dépendances dans votre POM maven :
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud-dependencies.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
</dependencies>
Ensuite, n’oubliez pas de mettre à jour votre configuration de log, comme ci-dessous avec Logback :
<!-- Json console appender -->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<layout class="ch.qos.logback.classic.PatternLayout">
<Pattern>
%gray(%d{HH:mm:ss}) %highlight(%-5level) %cyan(%logger{36}) %yellow([%X{traceId}/%X{spanId}]) - %msg%n
</Pattern>
</layout>
</appender>
Kafka
Par défaut les ids transitent via Kafka, il faut juste s’assurer que vos Producers et vos Consumers soient des beans Spring.
Pour désactiver cette feature, rien de plus simple, il faut ajouter la propriété suivante :
spring.sleuth.kafka.enabled : false
Kafka Stream
Comme Sleuth utilise Brave, vous pouvez utiliser l’API Brave ou l’API Sleuth. Pour que les ids soient visibles dans les logs kafka stream, j’ai utilisé la classe KafkaStreamTracing qui est disponible dans la librairie brave.
Voici comment j’ai réussi à logger mes ids dans les logs dans ma topologie Kafka Stream :
kafkaStreamsTracing.peek(contratTopic,
(key, eventOnContrat) -> logger.info("EventOnContrat received : key = {} value = {} topic = {}", key, eventOnContrat, contratTopic))
En plus
En plus de Splunk nous souhaitions pouvoir retrouver les messages Kafka correspondant au traceId dans AKHQ. AKHQ est une GUI pour Kafka. Pour ce faire, il faut récupérer le traceId au moment de l’envoi du message. Spring fournit un Tracer qui permet de récupérer le TraceId courant :
import org.springframework.cloud.sleuth.Tracer;
import org.springframework.stereotype.Service;
@Service
public class TraceService {
private final Tracer tracer;
public TraceService(Tracer tracer) {
this.tracer = tracer;
}
public String getCorrelationId() {
return tracer.currentSpan().context().traceId();
}
}
Une fois le traceId récupéré vous pouvez l’injecter dans les metadatas de vos messages Kafka par exemple.
Conclusion
Une fois installé, Sleuth permet de suivre les actions utilisateurs de bout en bout de l’application. Splunk nous permet de faire une recherche sur ces traceId et spanId pour avoir une trace complète et ce, à travers tous nos microservices.
Cela facilite grandement notre tâche pour pouvoir débugger, investiguer sur les erreurs que nous pouvons rencontrer dans l’application. Si vous utilisez ce genre d’infrastructure avec des composants Spring, je vous recommande fortement d'utiliser Spring Sleuth.
