
La mise en place de tests automatisés dans le développement est une pratique courante et essentielle pour assurer la qualité du code produit.
Cette pratique est-elle uniquement réservée au monde du développement ? Qu'en est-il pour la data ?
Heureusement Great Expectations a pensé aux data engineers et data scientists soucieux de la qualité de leurs données.Great Expectations est une librairie Python open source conçue pour effectuer des tests sur des données. Il est ainsi possible de valider des jeux de données selon des règles définies ou de détecter des anomalies dans les données.
Installation
Great Expectations étant une librairie Python, nous allons pouvoir l’installer grâce au gestionnaire de paquets Python : pip.
Avant toute chose, je vous recommande de créer un environnement virtuel Python. Cet environnement virtuel permet d'isoler l'installation des dépendances Python et d'éviter ainsi tout conflit potentiel relatif à différentes versions de dépendances utilisées par plusieurs projets Python sur votre machine.
Assurez-vous d'avoir Python 3 installé sur votre machine.
La création de cet environnement virtuel peut se faire grâce au module venv. La commande suivante permet ainsi de créer un environnement virtuel nommé MyEnv.
python -m venv MyEnv
Afin d’indiquer à votre machine que l'exécution de Python se fera maintenant via l’environnement MyEnv, il suffit de l’activer :
- (Windows)
. MyEnv\Scripts\activate
- (Unix)
. MyEnv/bin/activate
On peut maintenant installer Great Expectations via le module pip :
pip install great_expectations
À l'heure où cet article est écrit, Great Expectations est en train de changer de version d'API (V2 (Batch Kwargs) -> V3 (Batch Request API), cette dernière version d’API sera l’API par défaut de Great Expectations pour la future version 0.14 (ma version actuelle de Great Expectations étant 0.13.49). En attendant l’arrivée de la version 0.14, il est possible et recommandé d’utiliser la dernière version de l’API en ajoutant le flag --v3-api à chaque commande Great Expectations.
Great Expectations est maintenant installé, nous allons pouvoir initier un projet :
great_expectations --v3-api init
Great Expectations crée alors une arborescence de fichiers dans laquelle il faudra placer nos fichiers de configuration et de test.
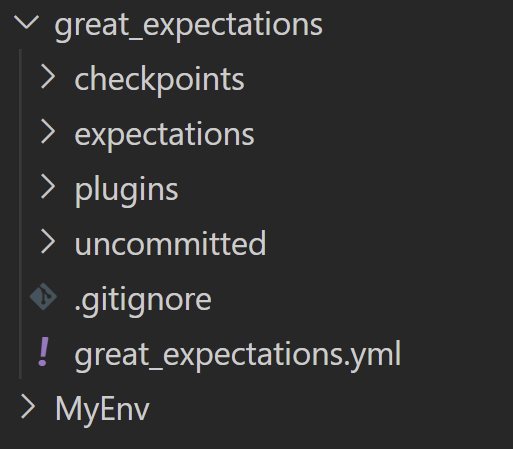
Généralités
Fichiers de configuration
Pour fonctionner, Great Expectations repose sur un ensemble de fichiers de configuration au format json et yaml.
Afin d'aider à la création de ces fichiers, Great Expectations propose une forme d’interface via des Jupyter notebooks préremplis qu’il suffit d’éditer et d'exécuter afin de générer ces fichiers.
Le fichier great_expectations.yml est le fichier de configuration global du projet, situé à la racine du projet.
CLI
L'ensemble des commandes great_expectations suit la syntaxe suivante :
great_expectations --v3-api <NOM> <VERBE>
Exemples de NOM :
- checkpoint : Opérations sur les Checkpoints
- datasource : Opérations sur les Datasources
- docs : Opérations sur la Data Doc
- init : Initialise un nouveau projet great_expectations
- suite : Opérations sur les suites d'Expectations
Exemples de VERBE :
- new
- list
- edit
- delete
- run
Concepts
4 briques fondamentales de Great Expectations sont présentées dans cette partie : Datasources, Expectations Suite, Checkpoint et la Data Doc.
Nous allons prendre la casquette d'une personne de la team data souhaitant tester ses données. Pour l’exercice nous allons nous baser sur un jeu de données mis à disposition par Nantes métropole fournissant des informations sur les restaurants de Loire-Atlantique.
Ces données ont été importées dans une base de données postgreSQL en local sur laquelle Great Expectations se connectera pour effectuer les tests.
Datasources
Une Datasource est un objet permettant de configurer une connexion à une source de données.
Les Datasources sont configurées dans le fichier great_expectations.yml.
La création d'un Datasource peut se faire via la commande :
great_expectations --v3-api datasource new
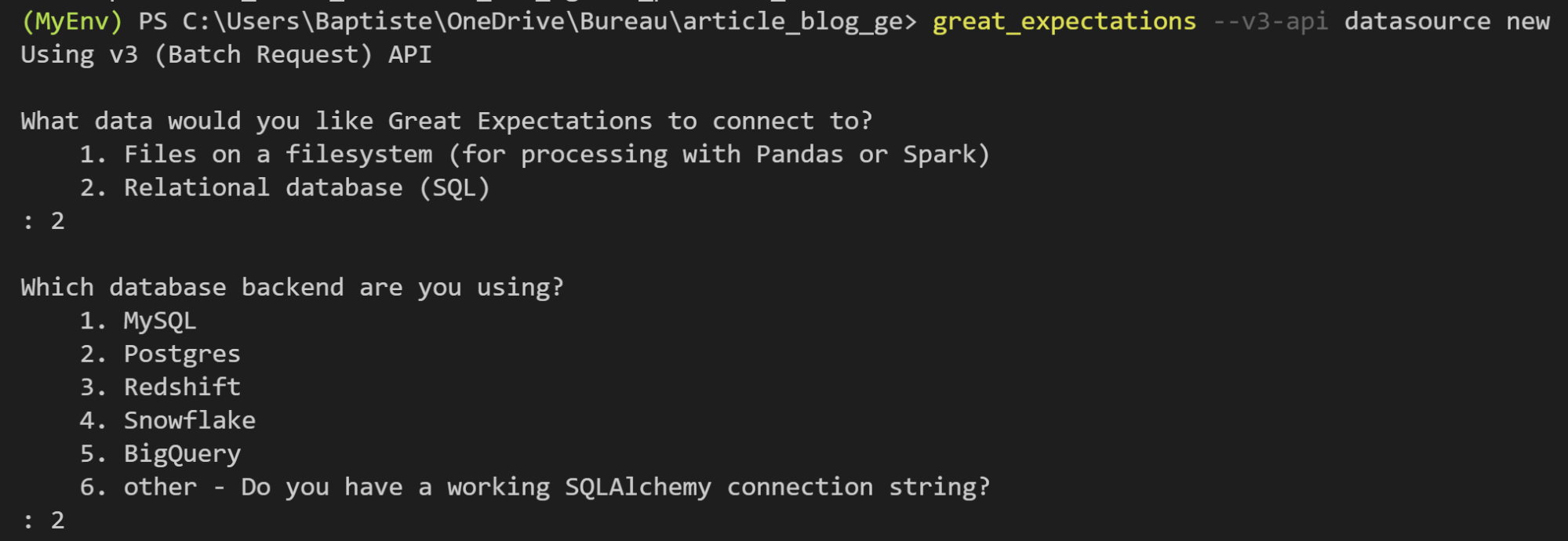
Après avoir renseigné le type de connexion, Great Expectations ouvre un notebook qu'il suffit d'éditer et d'exécuter.
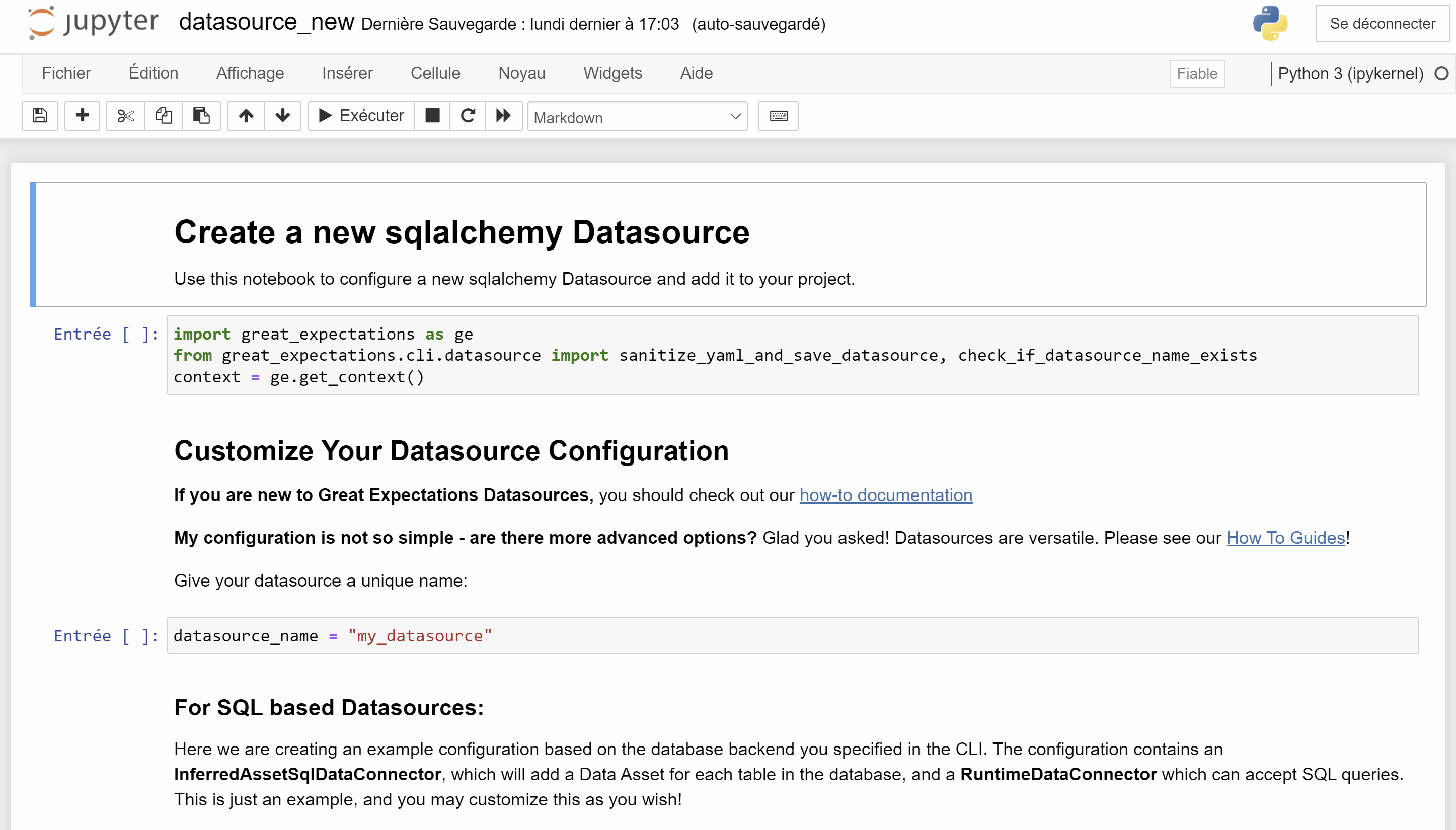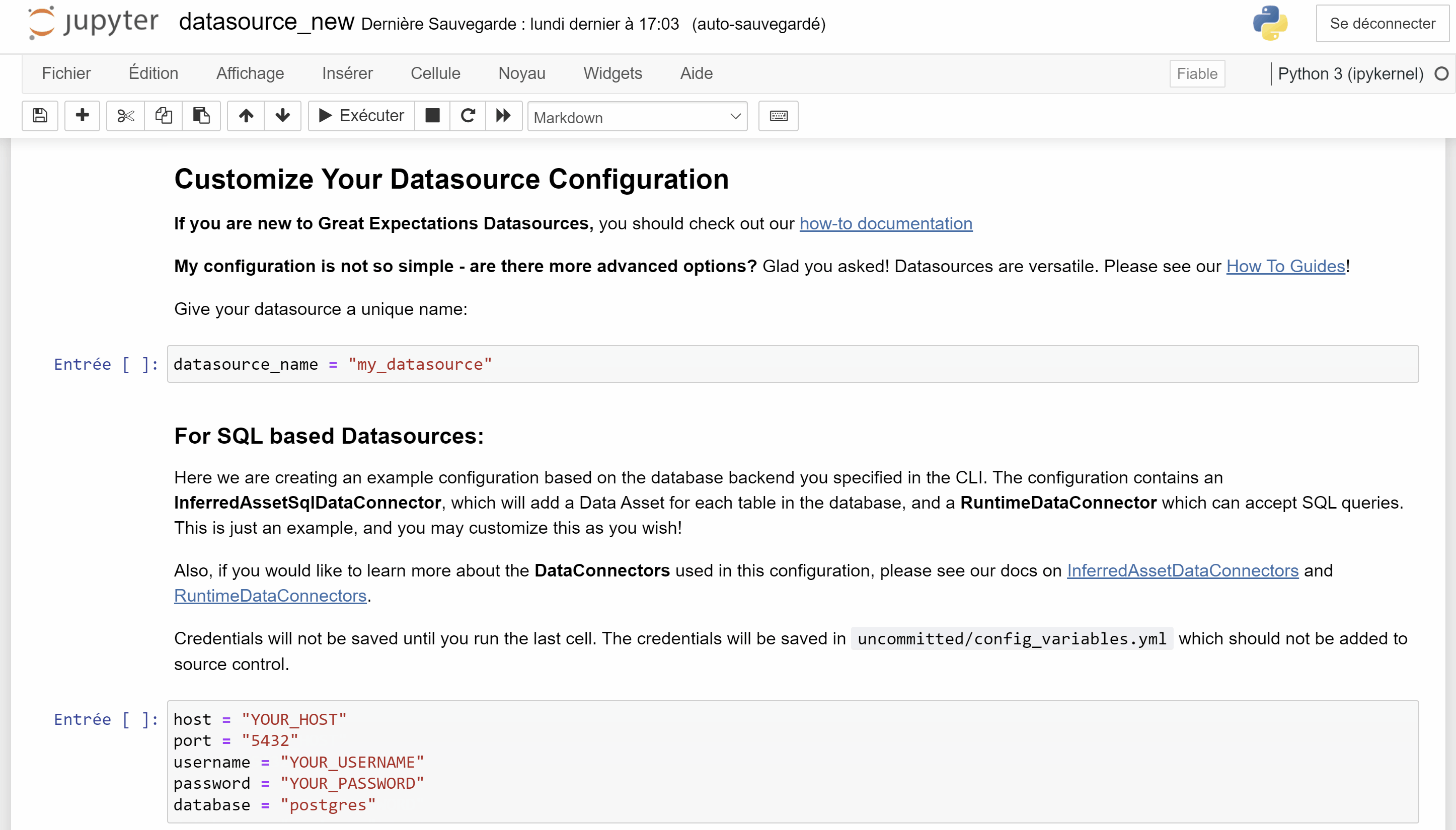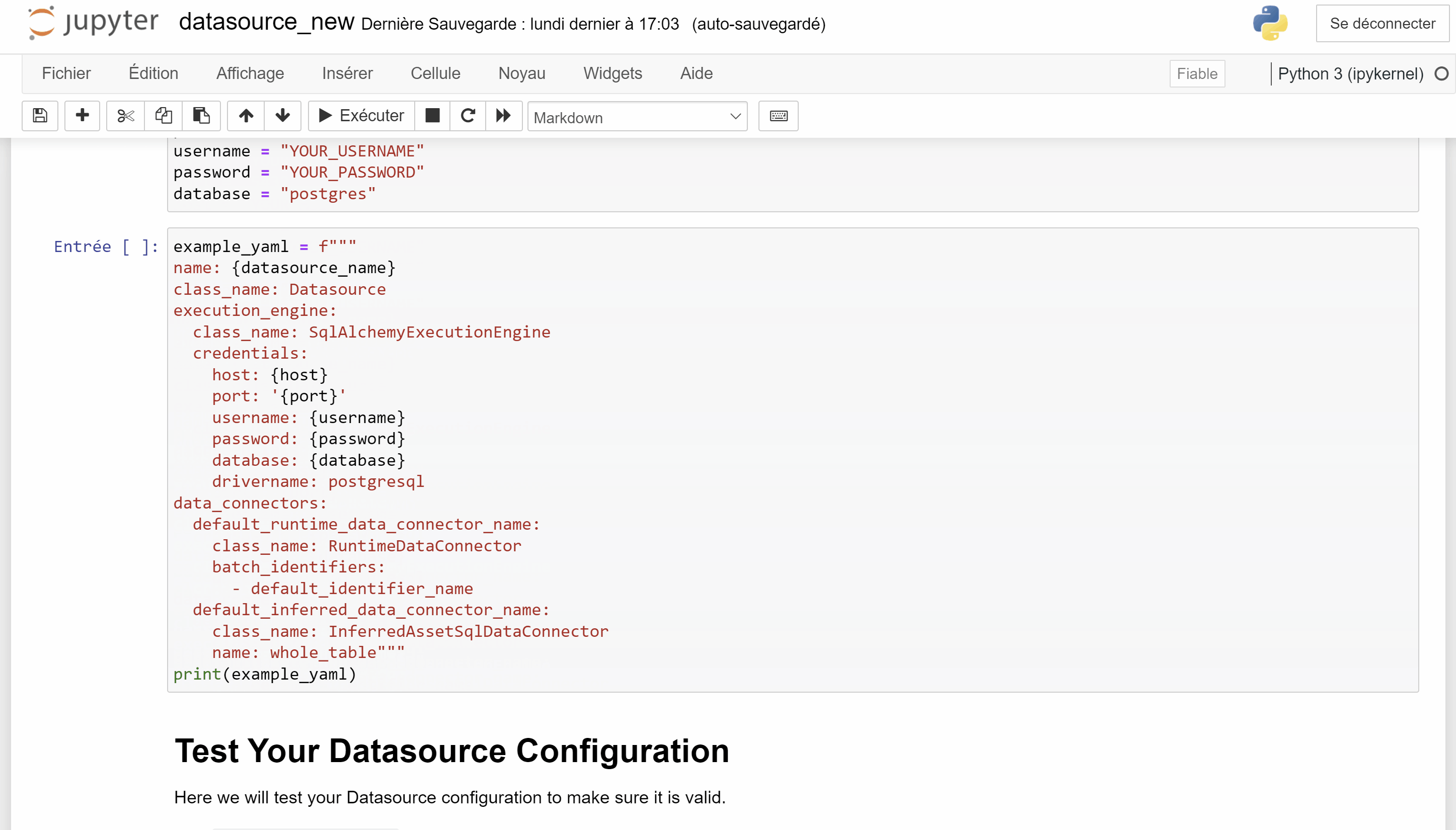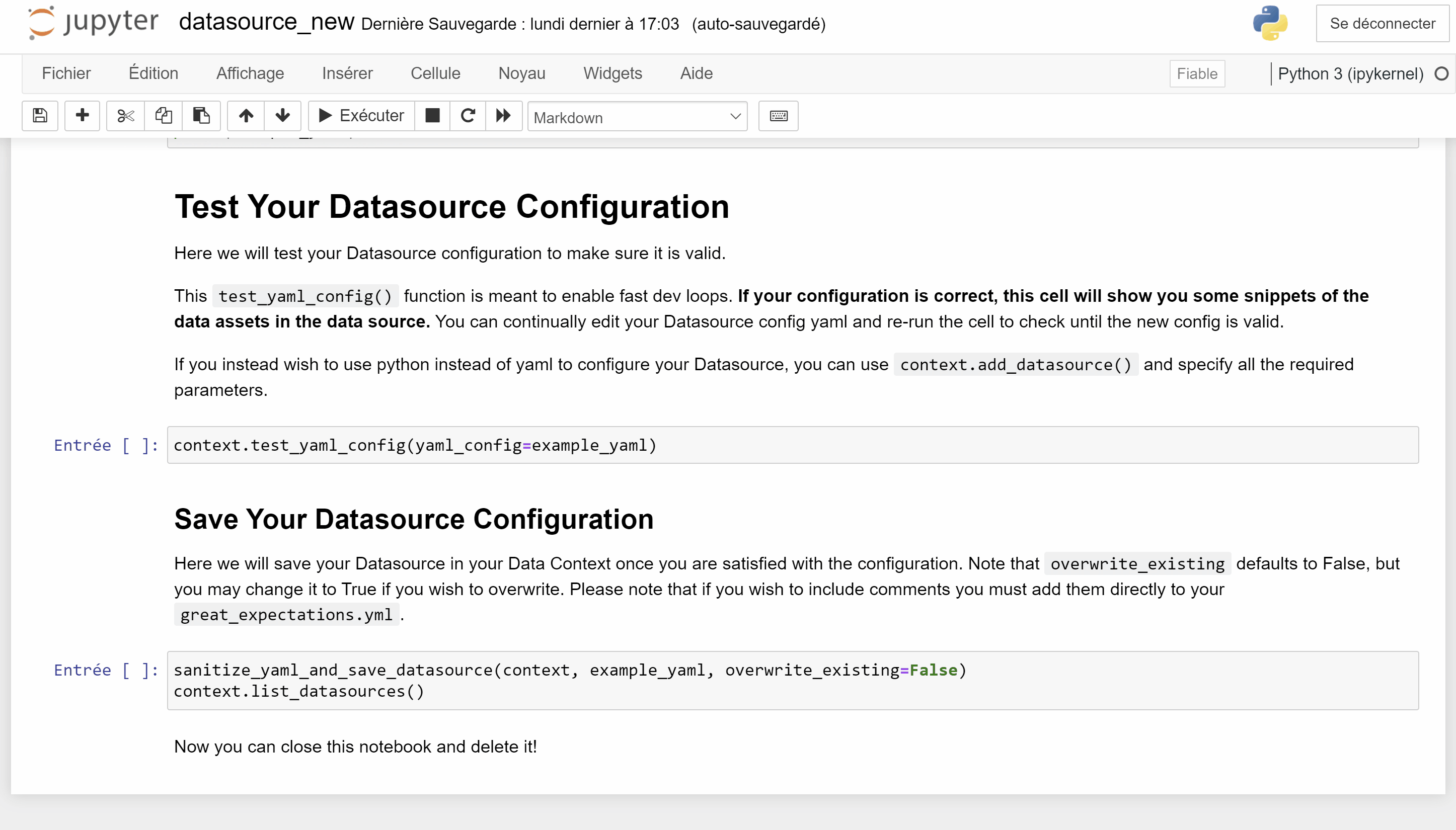
Ci-dessous, une partie du fichier fichier de configuration great_expectations.yml. Ce code à été généré par le notebook précédent et permet de decrire une Datasource.
datasources:
postgres_db:
class_name: Datasource
data_connectors:
default_runtime_data_connector_name:
batch_identifiers:
- default_identifier_name
class_name: RuntimeDataConnector
module_name: great_expectations.datasource.data_connector
default_inferred_data_connector_name:
class_name: InferredAssetSqlDataConnector
module_name: great_expectations.datasource.data_connector
execution_engine:
class_name: SqlAlchemyExecutionEngine
credentials:
host: localhost
port: '5432'
username: ${PG_USERNAME}
password: ${PG_PASSWORD}
database: demo_great_expectations
drivername: postgresql
module_name: great_expectations.execution_engine
module_name: great_expectations.datasource
Comme on peut le voir, il est possible de passer des variables afin d'éviter d’écrire des informations sensibles en clair dans le code.
La syntaxe est ${maVariable}. maVariable peut être une variable d'environnement de la machine ou une variable définie dans un fichier dont l'emplacement est à indiquer en valeur de la clé config_variables_file_path (par défaut : uncommitted/config_variables.yml qui est un fichier non commité et a donc vocation à rester en local sur la machine).
Expectations Suite
Une Expectation est une déclaration décrivant le comportement attendu de la donnée. On peut faire un parallèle avec les assertions en Python.
Exemple : (Glossaire d'Expectations)
- expect_column_values_to_not_be_null
- expect_column_values_to_match_regex
- expect_column_values_to_be_unique
- expect_column_values_to_match_strftime_format
- expect_table_row_count_to_be_between
- expect_column_median_to_be_between
Pour un même sous-ensemble de données, une succession d'Expectations forme une Expectation Suite. Les suites sont définies dans des fichiers json dans le dossier expectations.
Notre équipe a défini un certain nombre de règles qu’il faut respecter pour valider les données :
- tel_fixe doit être renseigné dans au moins 90% des cas
- tel_fixe lorsqu’il est renseigné doit être au format suivant : 0y x1x2 x3x4 x5x6 x7x8 avec xi entiers entre 0 et 9, y entier entre 1 et 9 différent de 6 et 7 (réservé au téléphone mobile)
- tel_mobile lorsqu’il est renseigné doit être au format suivant : 0y x1x2 x3x4 x5x6 x7x8 avec xi entiers entre 0 et 9 et y valant 6 ou 7
- site_web doit être renseigné dans au moins 50% des cas
Ci-dessous, le fichier de tests correspondant aux règles définies par l’équipe.
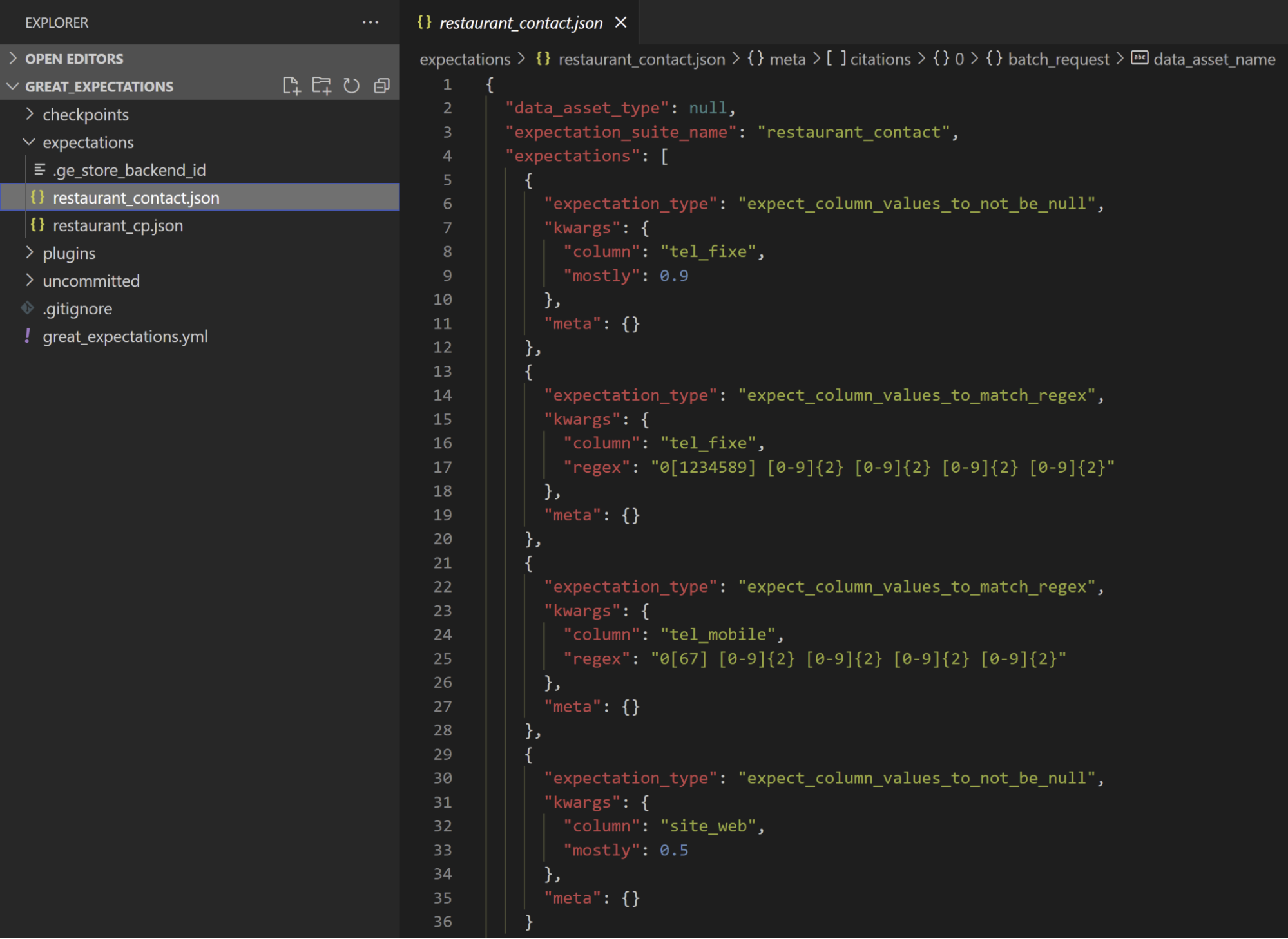
Great Expectations nous aide à générer ce fichier en tapant la commande
great_expectations --v3-api suite new
qui a pour effet d’ouvrir un notebook pré-rempli qu’il faut éditer et exécuter pour ajouter nos Expectations.
Checkpoints
Un checkpoint permet de valider un ensemble de suites d'expectations.
Il est important de noter qu'une suite d’expectations est indépendante du jeu de données sur lequel est exécutée la suite, elle est générique.
C'est au niveau du checkpoint que l'on va pouvoir spécifier le jeu de données sur lequel exécuter la suite.
Il est ainsi possible au sein d’un même checkpoint d'exécuter une même suite sur plusieurs jeux de données différents, ce qui peut être intéressant selon nos besoins.
Configuration
Ci-dessous le fichier de configuration du checkpoint :
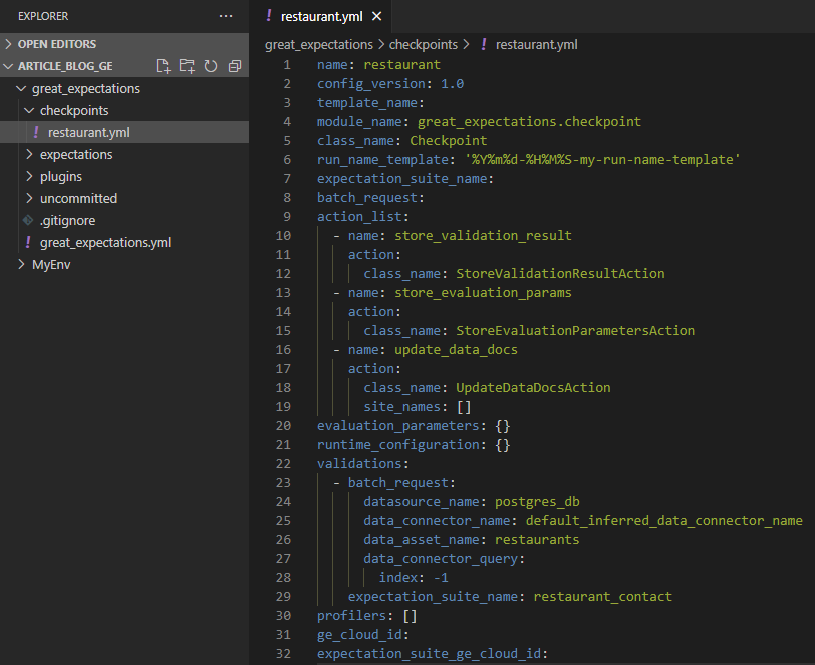
Ici encore, le fichier a été généré par un notebook Jupyter après avoir lancé la commande
great_expectations --v3-api checkpoint new restaurant
Les suites d'Expectations à valider par le Checkpoint sont listées dans la liste yaml validations (ligne 22). Il n'y a ici qu’une suite à valider (restaurant_contact) mais il est possible d’en ajouter d'autres à la suite.
Configuration de notre unique batch_request :
- datasource_name : le nom de notre Datasource (connexion à notre base postgres)
- data_connector_name : nom du connecteur à utiliser. Les différents connecteurs sont configurés au niveau du Datasource
- data_asset_name : nom du jeu de données à utiliser. Dans le cas de notre connecteur, il s’agit du nom de la table dans notre base de données.
- expectation_suite_name : nom de la suite d’Expectations.
Exécution
Il est possible d'exécuter le Checkpoint via la CLI :

Il est également possible d'exécuter le Checkpoint en Python :
import great_expectations as ge
context = ge.get_context()
result = context.run_checkpoint(checkpoint_name='restaurant')
La variable result contient un objet json détaillant le résultat de la requête. Il est ainsi possible de voir quelle suite a échoué, quelle Expectation a échoué et pourquoi.
Data Doc
La Data Doc est un site web statique permettant de visualiser les résultats des différentes exécutions de manière plus commode qu'un grand document json.
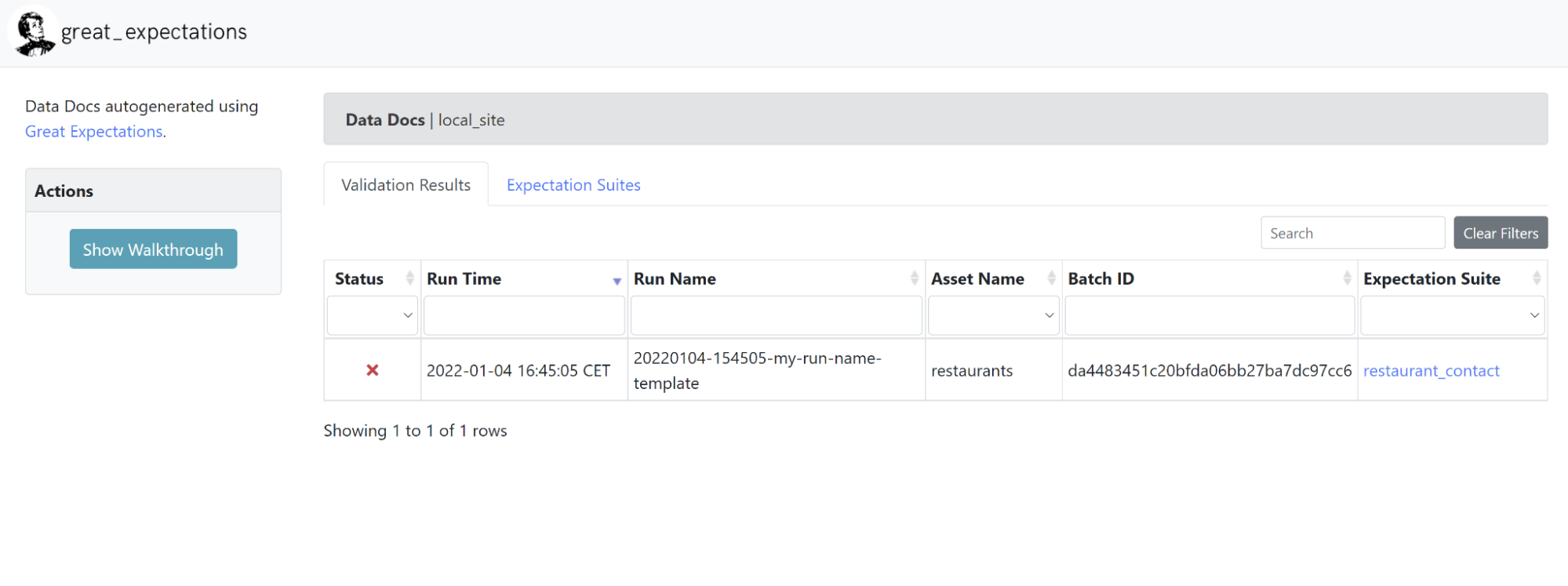
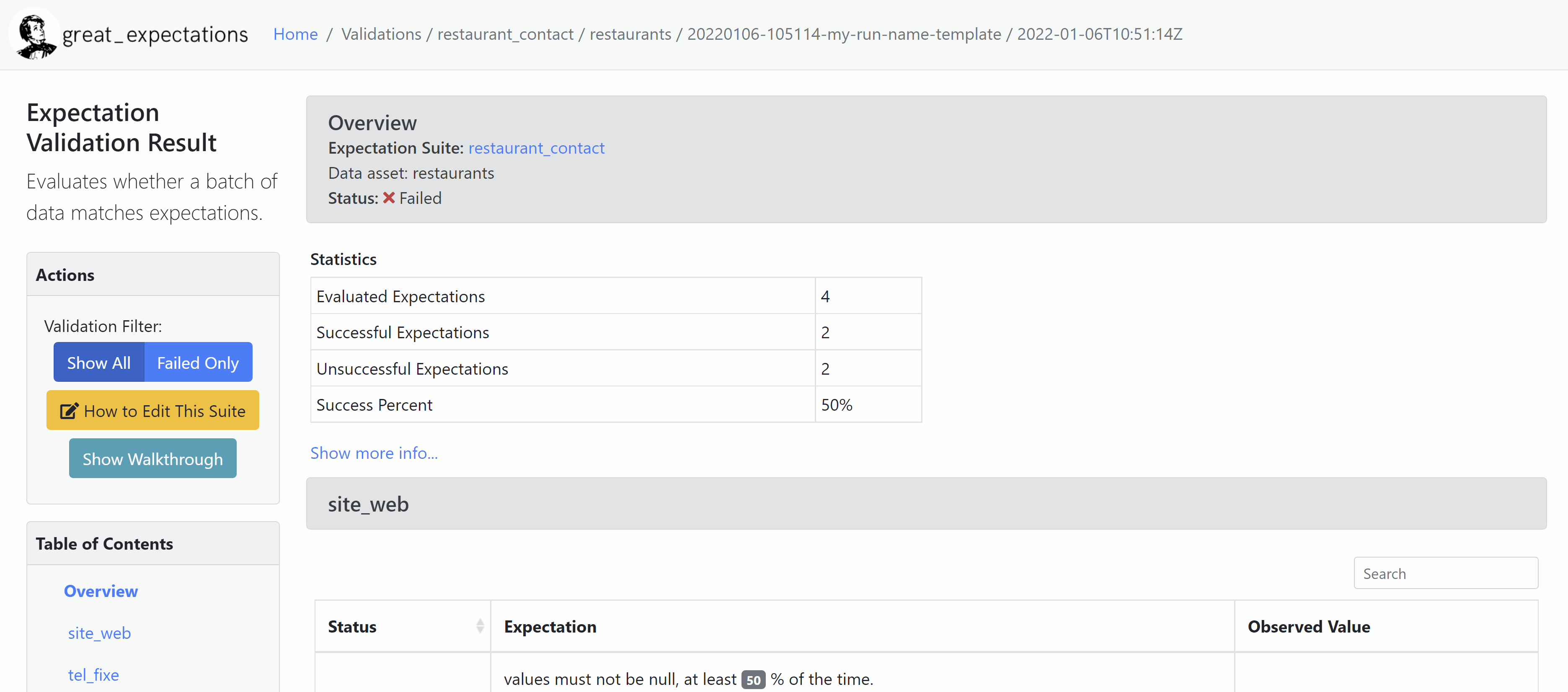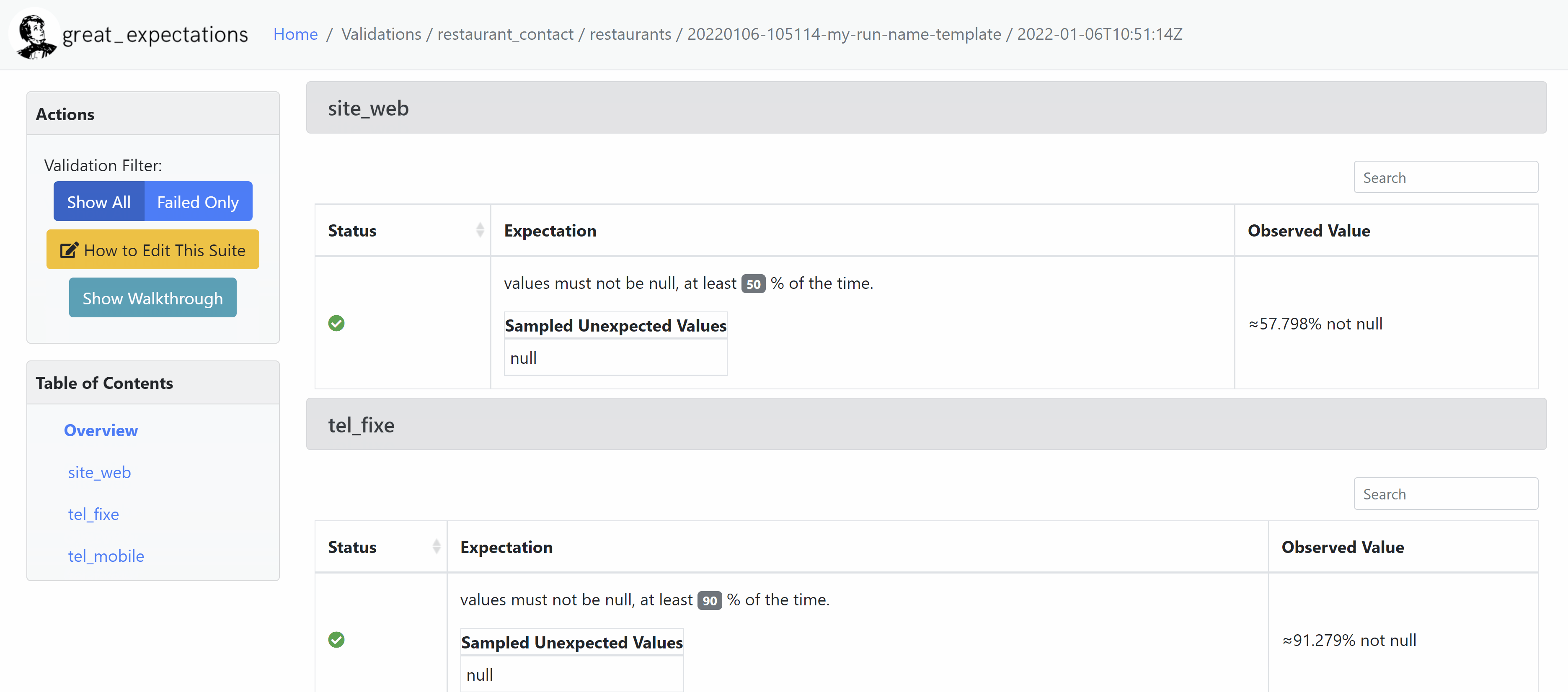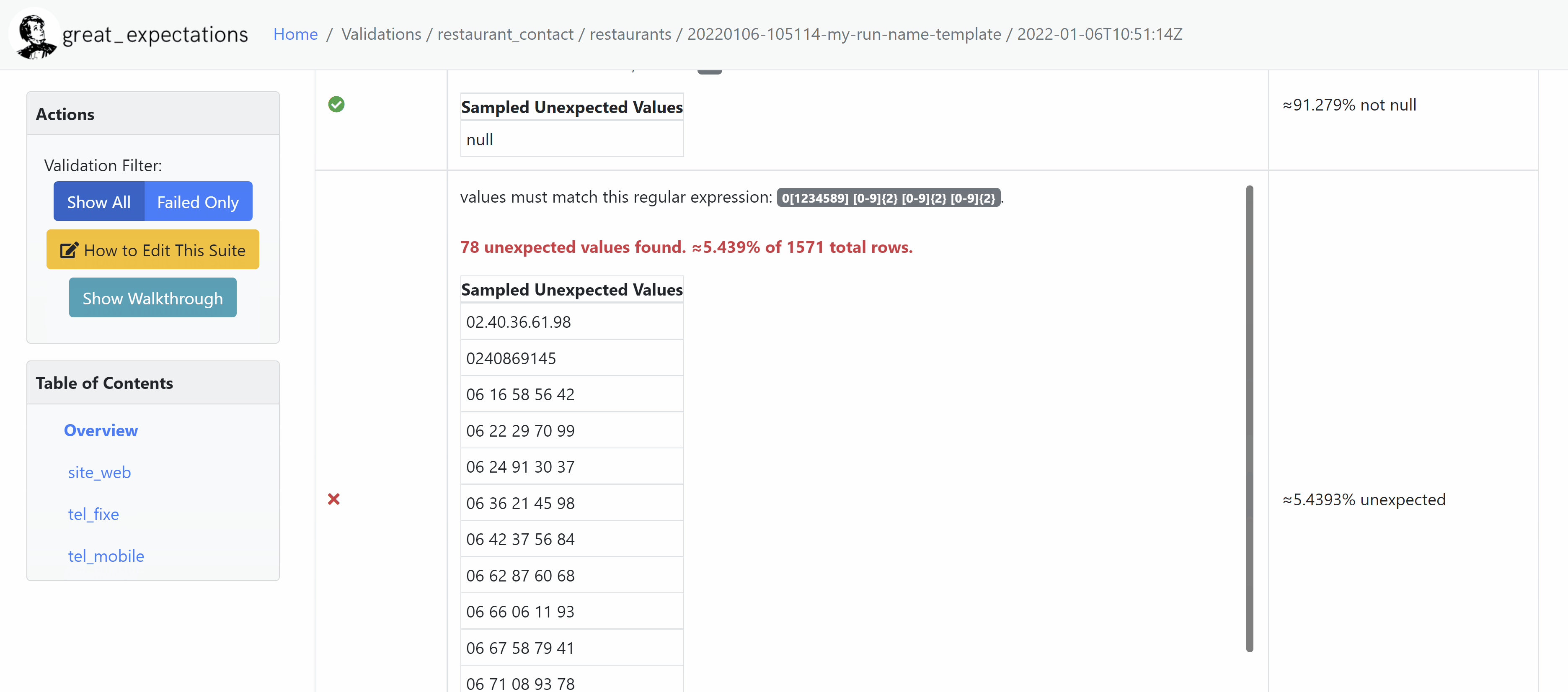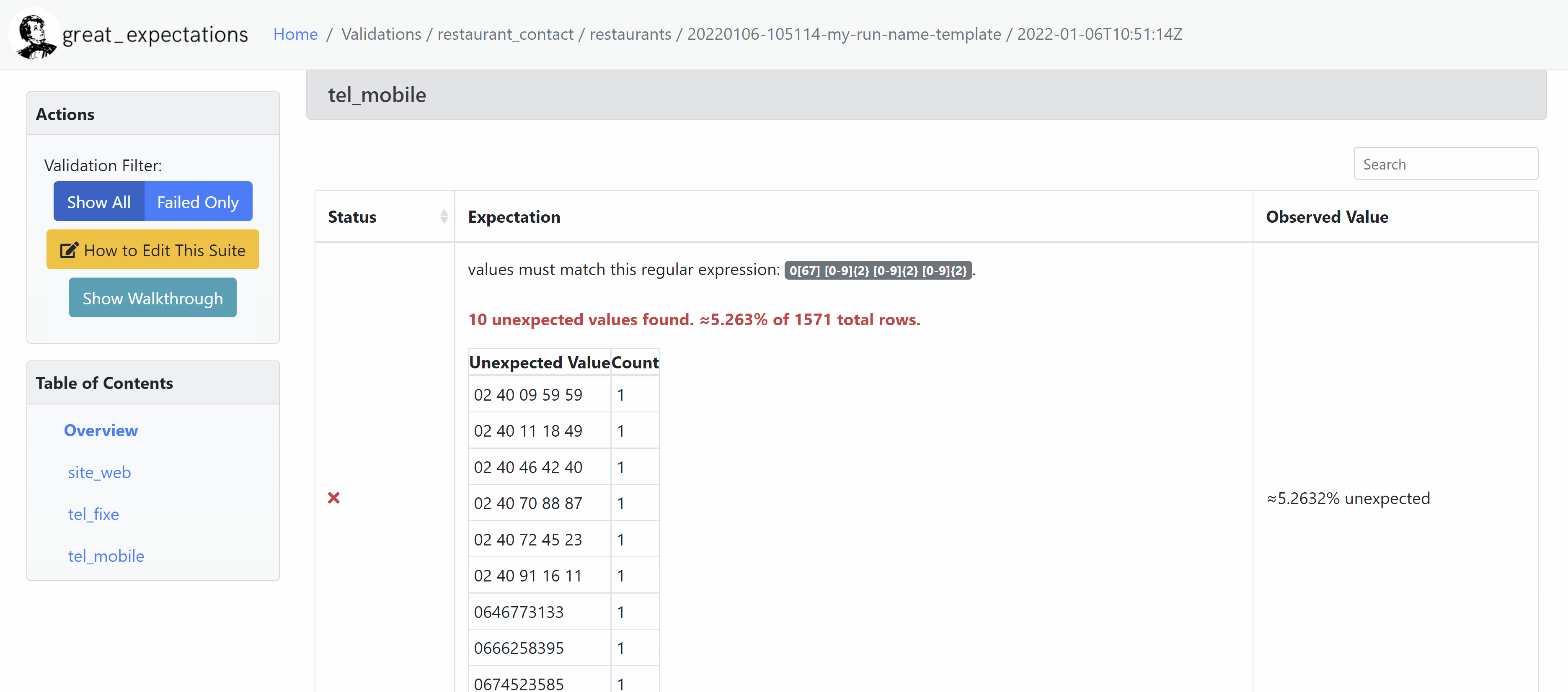
Le code des pages web est entièrement contenu dans le dossier uncommited/datadocs/localsite.
Ces pages HTML sont mises à jour à chaque exécution de Checkpoint et chaque exécution est historisée.
Il est également possible de customiser le rendu graphique de la data doc.
Tester sur des sous-ensembles de données
Dans la partie Concepts nous avons vu comment effectuer des tests sur toute une table.
Nous allons voir dans cette partie comment effectuer des tests en se basant sur une table temporaire créée à partir d’une requête SQL.
Comme on l'a vu précédemment, les suites d'Expectations sont indépendantes des données qu’elles testent. La création de la table temporaire se fera donc naturellement au niveau du Checkpoint.
Pour l'exemple, nous allons nous donner l'objectif suivant : vérifier que les Code_postal des restaurants de la Commune NANTES sont cohérents, c’est-à-dire qu'ils ont pour valeur 44000, 44036, 44100, 44200, 44300, 44321 ou encore 44325.
Nous créons une nouvelle suite d'Expectations (restaurant_cp) avec l'Expectation suivante :
expect_column_values_to_be_in_set(
column = 'Code_postal',
valueSet = [44000, 44036, 44100, 44200, 44300, 44321, 44325]
)
Ci-dessous la nouvelle configuration du Checkpoint :
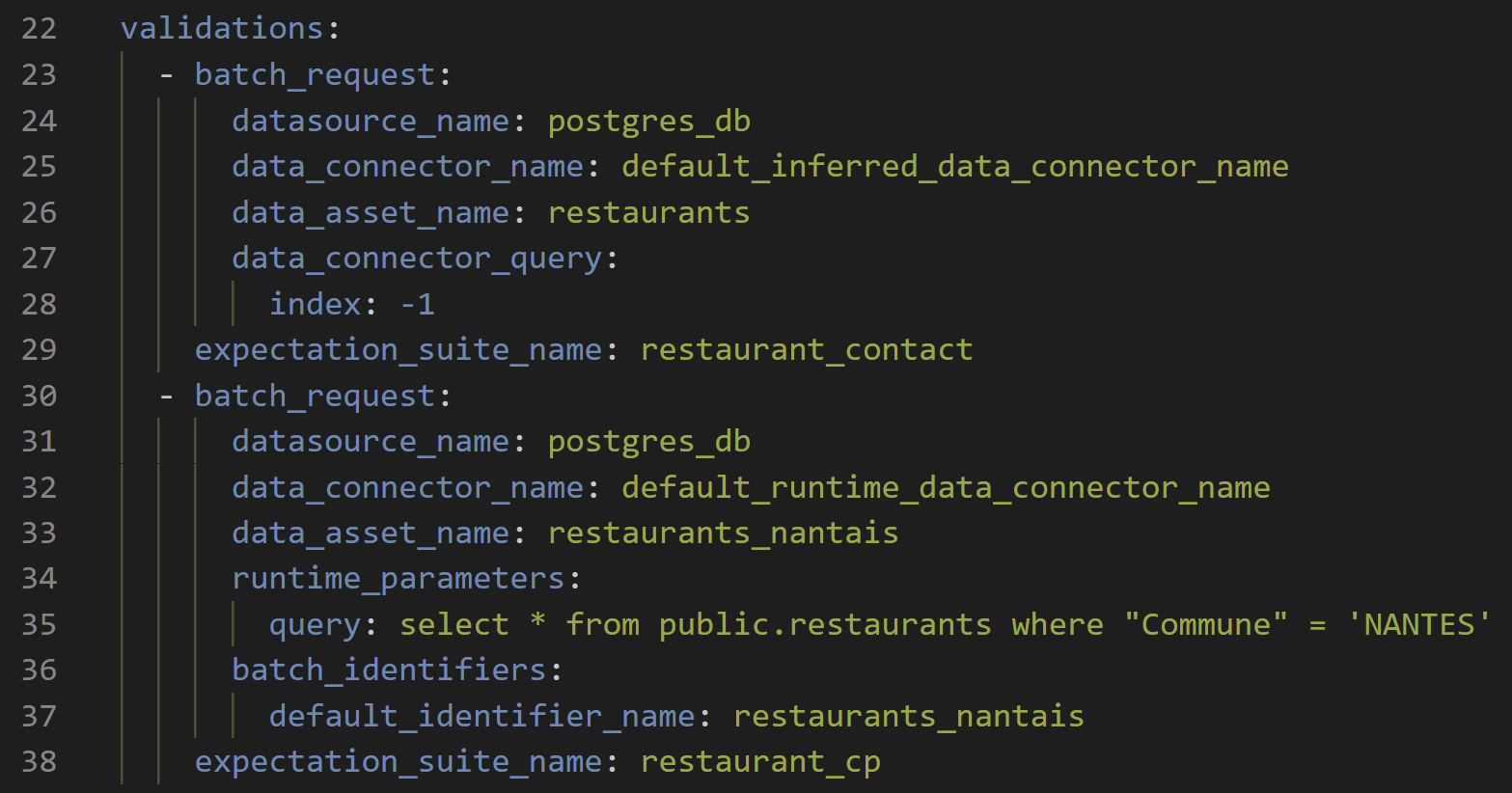
Nous avons donc rajouté la suite d'Expectations restaurants_cp au précédent Checkpoint en paramétrant différemment la batch_request.
Nous avons utilisé un autre connecteur (default_runtime_data_conector_name) et spécifié une requête dont le résultat sera le jeu de données sur lequel restaurant_cp sera testé.

Conclusion
Great Expectations est souple et offre beaucoup de possibilités de personnalisation de part son caractère open source et son architecture.
On peut imaginer beaucoup de cas d’utilisation différents.
Le data scientist peut l’utiliser comme outil d’audit avant d’exploiter les données.
Le data engineer peut s’en servir comme outil de monitoring et de validation des données tout au long du cycle de transformation des données et l’intégrer dans son workflow de développement.
Il peut être également intéressant de mettre en place un audit régulier d’une base de production afin d’assurer une certaine qualité de données et d’envoyer des alertes si une anomalie est détectée.
Il est cependant important de garder en tête que Great Expectations n’a pas vocation à orchestrer des pipelines d'exécution de tests mais propose des intégrations avec des outils de DAG d'exécution comme Airflow, dbt, Prefect, Dagster, Kedro, etc
Dans cet article nous avons vu les fonctionnalités et concepts principaux de Great Expectations. Toutes les fonctionnalités n’ont pas été présentées ici, je ne peux que vous conseiller d’aller jeter un coup d'œil à la documentation si vous souhaitez aller plus loin.
Et n’oubliez pas les paroles inspirantes de M.Dickens 😉
"Ask no questions, and you'll be told no lies."
Charles Dickens, Great Expectations
Ressources
- https://data.nantesmetropole.fr (Restaurants en Loire-Atlantique)
- https://docs.greatexpectations.io/docs (Documentation Great Expectations)
- https://gitlab.ippon.fr/bmansire/demo-great-expectations (Gitlab)