

Terraform, outil édité par HashiCorp, est désormais un outil d'Infrastructure as Code (IaC) bien connu de tous. Même s'il souffre de certaines imperfections, il a permis l'installation de concepts forts que l’on retrouve chez des concurrents parfois récents. Ces concepts sont pour certains complexes à comprendre, mais sont bien là pour nous aider à gérer notre infrastructure sur le long terme. C'est une de ces notions phares que je me propose de revoir avec vous : les états Terraform (aussi appelé tfstate ou state Terraform). Son objectif est assez bien expliqué dans la documentation Terraform et nous allons, dans cet article, nous attarder sur sa gestion et ses implications techniques.
Basiquement, la notion d'état permet à Terraform d'associer une ressource définie dans votre IaC (donc en tant que code) à une ressource du monde réel (souvent sur votre fournisseur cloud). Cela permet à l'outil de prendre des décisions vis-à-vis de la création, destruction ou modification des ressources de votre infrastructure en comparant votre code au dernier état connu de celle-ci.
Pourtant, certaines modifications de votre code (de la refactorisation en général) peuvent amener Terraform à effectuer des choix indésirables. Ces derniers peuvent même causer des problèmes sur votre infrastructure si vous les appliquez tel quel. Il faut alors agir et effectuer des corrections manuelles que nous étudierons dans cet article. Nous verrons dans un premier temps comment les détecter et les traiter sur un cas simple, puis nous passerons à un cas concret.
Préambule
Dans cet article nous allons utiliser la notion de module Terraform et ainsi que le workflow habituel de Terraform (terraform plan et terraform apply).
Vous pouvez retrouver les exemples de code de cet article ici. Ils utilisent tous le cloud provider AWS, il vous faudra donc un compte pour les effectuer avec moi. Ceux qui souhaitent suivre ces exemples peuvent trouver les différentes instructions dans le README du dépôt.
Comprendre la gestion des états Terraform
Pour bien comprendre les scénarios que je vais décrire dans quelques instants, il faut bien comprendre le comportement de Terraform lorsqu'on renomme des ressources dans notre IaC. C'est en effet un des cas qui nous implique d'agir sur le fichier d'état.
Pourquoi et comment effectuer une migration d'états
Un jour, un utilisateur vient vous voir et vous demande de lui démarrer une instance ec2 sur laquelle il pourra travailler, lancer ses calculs etc.. Vous ajoutez donc le code Terraform suivant dans votre infrastructure (exemple tiré de la documentation de la resources aws_instance).
data "aws_ami" "ubuntu" {
most_recent = true
filter {
name = "name"
values = ["ubuntu/images/hvm-ssd/ubuntu-focal-20.04-amd64-server-*"]
}
filter {
name = "virtualization-type"
values = ["hvm"]
}
owners = ["099720109477"] # Canonical
}
resource "aws_instance" "this" {
ami = data.aws_ami.ubuntu.id
instance_type = "t3.micro"
tags = {
Name = "John Doe's Workstation"
}
}
Vous appliquez ce code sur votre infrastructure avec un terraform apply et tout va bien, votre utilisateur se connecte et peut travailler (en réalité il manque quelques ressources pour accéder à l'instance, mais nous ne nous y attarderons pas dans cet article).
La semaine suivante, un autre utilisateur jaloux de son collègue vous demande la même chose. Vous finissez, sans trop y réfléchir, par copier coller le code de création de l’instance du premier utilisateur, changez le tag Name, le nom de la ressource et appliquez (terraform apply) ce nouveau code. Le deuxième utilisateur a sa nouvelle machine et peut aussi commencer à travailler.
resource "aws_instance" "foo_bar" {
ami = data.aws_ami.ubuntu.id
instance_type = "t3.micro"
tags = {
Name = "Foo Bar's Workstation"
}
}
En regardant le code, vous vous rendez compte que le nom de la ressource terraform qui correspond à l’instance du premier utilisateur ne porte pas le nom de l’utilisateur comme la seconde ressource que vous venez de créer. Vous décidez donc de changer cela en renommant la ressource aws_instance “this” en “john_doe”.
resource "aws_instance" "john_doe" {
ami = data.aws_ami.ubuntu.id
instance_type = "t3.micro"
tags = {
Name = "John Doe's Workstation"
}
}Cependant, lors du plan (avec terraform plan), vous vous rendez compte que l’instance du premier utilisateur va subir une destruction puis une recréation (cf image ci dessous), alors que vous n'avez modifié aucun paramètre de l'instance de cet utilisateur.
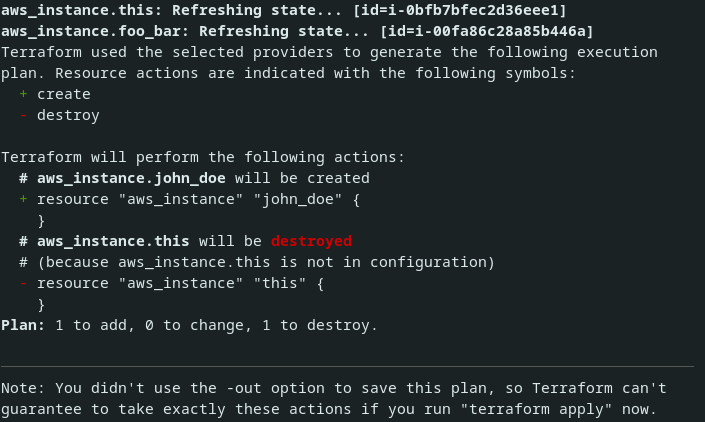
Terraform devrait en principe vous montrer un plan vide (car techniquement rien n'a changé). Le problème est que si on applique le plan Terraform, on risque de créer de l'indisponibilité pour le premier utilisateur. Pire que ça, on détruira probablement une partie du travail qu’il aura effectué sur la machine.
Alors que se passe-t-il ? Pourquoi Terraform ne se rend pas compte qu’on a juste renommé la ressource ? Pour comprendre cela, faisons un pas de côté pour expliquer comment Terraform utilise son fichier d’état.
Lorsque vous effectuez des terraform apply de votre code, Terraform va effectivement créer les ressources via les API de votre provider (AWS dans notre cas), mais il va aussi enregistrer la ressource qu’il vient de créer (ainsi que son paramétrage) dans un registre. C’est ce registre que l’on appelle communément un fichier d’état (ou tfstate). Ce dernier permet ainsi à Terraform de savoir quelles ressources existent sur l’infrastructure au moment du dernier apply.
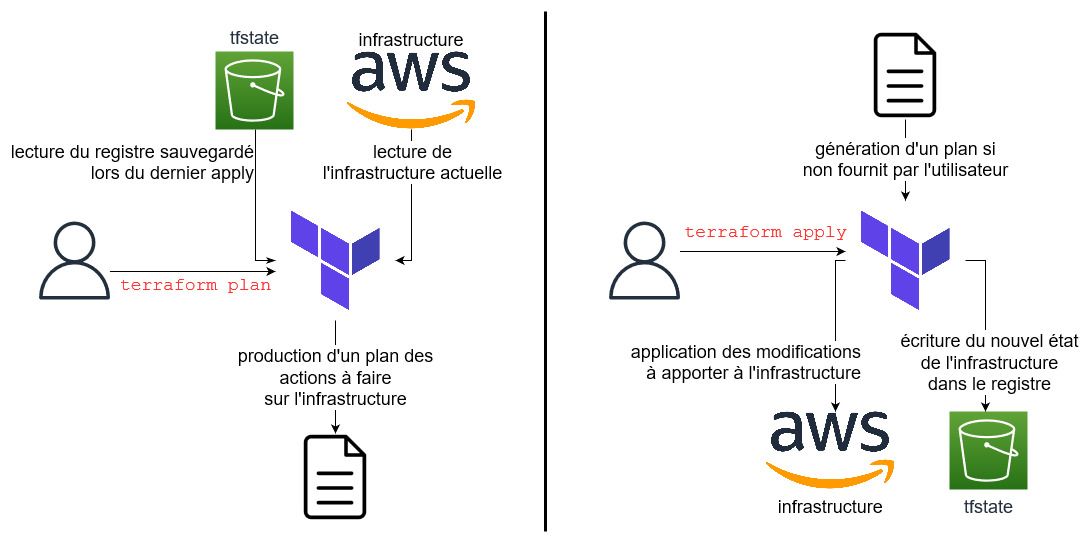
Lorsque vous renommez une ressource dans Terraform vous faites diverger votre code de ce fichier d'état. En effet, ce fichier contient notamment les chemins Terraform (le chemin d’appel dans votre code) vers toutes vos ressources. Si vous renommez une ressource A en B, vous changez ainsi son chemin et Terraform interprète cela de la manière suivante:
- la ressource A a disparu du code, mais se trouve toujours dans le fichier d'état → donc elle se trouve toujours dans l'infrastructure réelle → je dois la détruire ;
- la ressource B vient d'apparaître dans le code, mais je ne la trouve pas dans le fichier d'état → donc elle n'est pas dans l'infrastructure réelle → je dois la créer.
Terraform n'est pas capable de savoir que la ressource a simplement été renommée et tire donc de fausses conclusions concernant l'état de votre infrastructure.
Revenons à notre exemple. Pour réconcilier le fichier d’état avec la vision de l'infrastructure que nous avons, nous devons indiquer à Terraform que la ressource au chemin aws_instance.this a été renommée en aws_instance.john_doe. On peut faire cela grâce à la commande terraform state mv qui prend en paramètre l'ancien chemin d'une ressource ainsi que son nouveau chemin. Dans notre cas, cela donne terraform state mv aws_instance.this aws_instance.john_doe.
Une fois la modification du fichier d’états effectuée, la commande terraform plan n'indique aucun changement prévu, comme attendu initialement.

Afin de faciliter vos investigations, vous pouvez à tout moment voir l'ensemble des ressources disponibles dans votre fichier d’états avec la commande terraform state list. Voici ce que me donne cette commande à la fin de notre exemple.
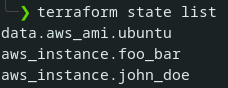
On retrouve bien nos deux instances ainsi que la ressource de type data source qui nous a permis de les construire. Vous pouvez par ailleurs décrire le paramétrage complet de chaque ressource en utilisant la commande terraform state show <resource_path> (par exemple terraform state show aws_instance.foo_bar). Ces deux commandes devraient vous permettre d'entreprendre des investigations et vérifications lors de vos manipulations du fichier d'état Terraform.
Un exemple concret d'utilisation de ces migrations
Le précédent exemple peut paraître assez simple et ne jamais arriver si on organise un peu mieux son code, mais il a le mérite de décrire un cas élémentaire où l’on aurait besoin de la commande terraform state mv. Afin de mieux comprendre les utilisations possibles de cette commande, on va s’attarder sur une utilisation un peu plus complexe en repartant de l’exemple précédent. Il s'agit d'extraire certaines ressources en un module Terraform. Cela peut être utile lorsque vous voulez découper votre IaC de manière plus fonctionnelle, lorsque vous avez (comme ici) de la duplication de code ou bien lorsque vous comptez réutiliser un ensemble de votre code dans une autre stack.
Repartons du code que nous avons à la fin de notre exemple précédent (dossier part1/command_state_mv/step2 du dépôt d'exemple). Dans celui-ci, on remarque que le seul élément qui change est le tag associé à une instance. Le reste est similaire et à priori, il est souhaitable que les deux instances aient la même configuration quel que soit l'utilisateur. C'est donc le bon moment pour créer un module qui nous permettra de définir cette configuration standard.
variable "user_fullname" {
type = string
description = "The full name of the workstation's owner"
}
data "aws_ami" "ubuntu" {
...
}
resource "aws_instance" "this" {
ami = data.aws_ami.ubuntu.id
instance_type = "t3.micro"
tags = {
Name = "${var.user_fullname}'s Workstation"
}
}Une fois le module créé, nous pouvons l’appeler depuis notre code terraform principal en lui passant une variable pour configurer le tag de nommage de l'instance.
module "john_doe" {
source = "../../../modules/workstation"
user_fullname = "John Doe"
}
module "foo_bar" {
source = "../../../modules/workstation"
user_fullname = "Foo Bar"
}Comme nous venons de déplacer nos deux instances dans un module (changeant ainsi leur chemin Terraform), nous allons devoir effectuer une migration dans notre fichier d’état. Le changement de chemin suit le pattern suivant aws_instance.<username> → module.<username>.aws_instance.this. Pour en être sûr, on peut effectuer un terraform plan . Ce dernier nous donne une sortie similaire au screenshot suivant.
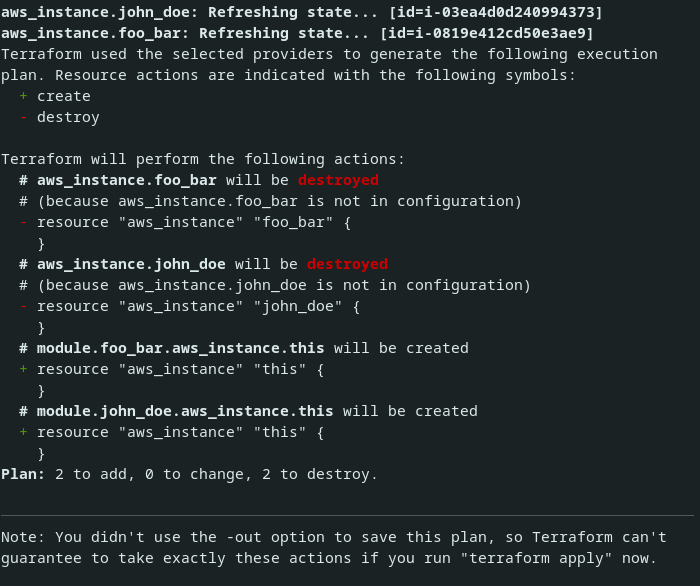
Si vous avez bien suivi jusque là, vous devriez déjà avoir trouvé les deux commandes à exécuter pour se sortir de cette situation et avoir un terraform plan sans modification d’infrastructure sur AWS 🙂
terraform state mv \
aws_instance.foo_bar \
module.foo_bar.aws_instance.this
terraform state mv \
aws_instance.john_doe \
module.john_doe.aws_instance.this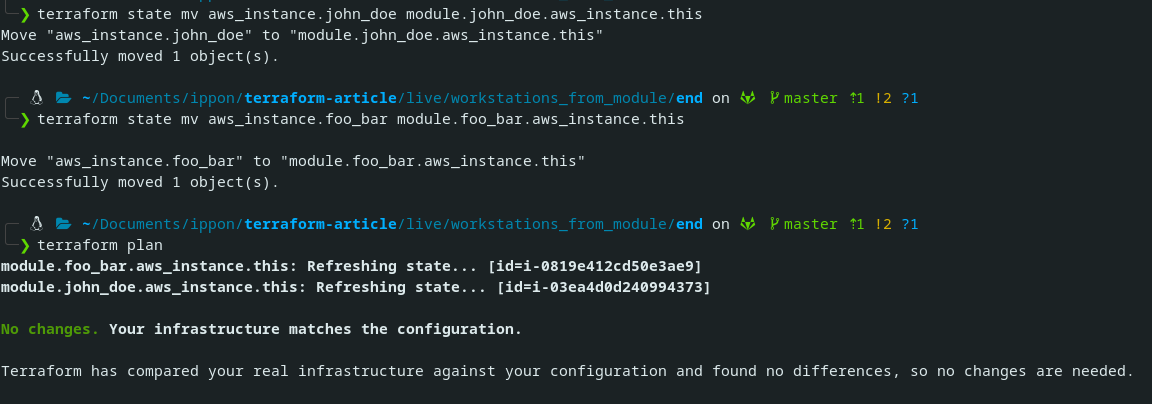
Le problème des ressources créées à l'extérieur de l'IaC
Pour être un peu plus complet au sujet de la manipulation de fichier d'état Terraform, nous allons voir un dernier cas. Admettons qu’un de vos utilisateurs ait eu besoin d'un bucket s3. Ce dernier l’a créé, à la main (via la console ou la command line) et y a déjà placé beaucoup d'objets avec lesquels il travaille. Vous voudriez être capable de gérer le cycle de vie de ce bucket depuis votre IaC Terraform.
Vous ajoutez donc la resource aws_s3_bucket en indiquant le même nom de bucket que celui fournit par l'utilisateur afin de ne pas avoir à déplacer ses fichiers dans un nouveau bucket.
resource "aws_s3_bucket" "this" {
bucket = "datascience-example-bucket"
}À ce stade votre code est prêt, vous lancez donc un premier terraform plan
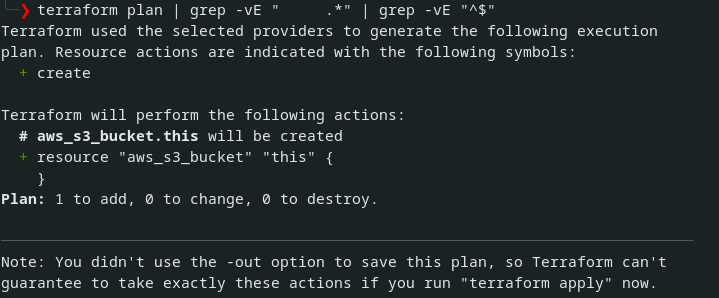
Vous notez que le plan indique que Terraform va créer la ressource, mais vous savez que celle-ci est déjà créée. Vous essayez tout de même d’appliquer ce plan, mais Terraform se plaint en vous indiquant que le bucket existe déjà.
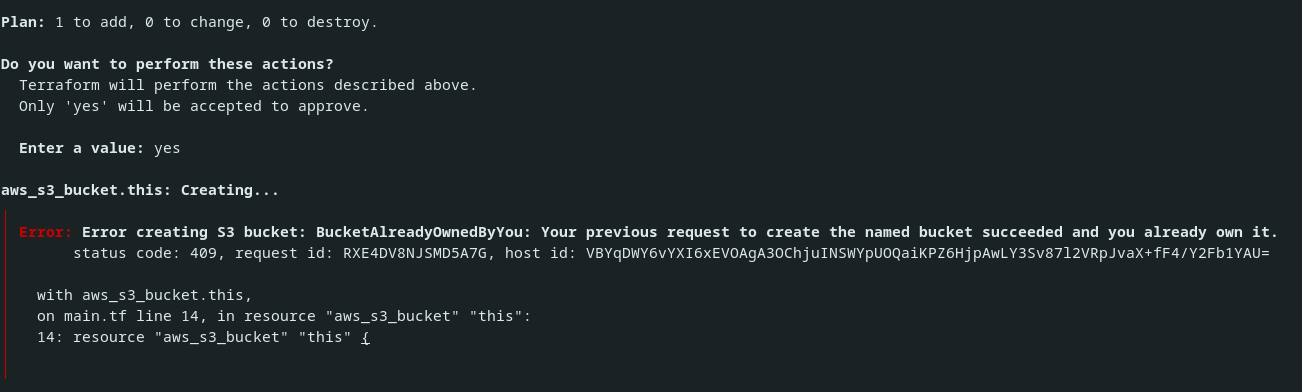
Vous observez ici un comportement qui peut paraître frustrant, mais qui est voulu. Terraform n'a pas conscience des ressources qui ont été créées en dehors de son cycle de vie (et qui ne sont donc pas dans son fichier d'états). Pour le dire autrement : Terraform n'altère pas les ressources qu'il ne gère pas. Cependant, vous savez que le bucket existe déjà et vous aimeriez que terraform comprenne cette information. C’est exactement à cela que sert la commande terraform import :
Terraform is able to import existing infrastructure. This allows you take resources you've created by some other means and bring it under Terraform management
Pour trouver comment importer une ressource d’un certain type, il faut regarder tout en bas de la documentation de la ressource en question. Attention, tout de même, certaines ressources ne peuvent pas être importées et d'autres ne le sont que partiellement (comme par exemple la ressource aws_iam_access_key). Dans le cas de la resource aws_s3_bucket, on nous donne les indications suivantes terraform import aws_s3_bucket.bucket bucket-name ce qui, dans notre cas, nous donne terraform import aws_s3_bucket.this "datascience-example-bucket".
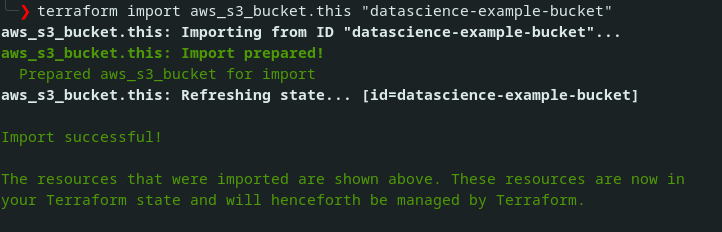
Vous pouvez ensuite lancer un terraform plan pour voir si la configuration que vous avez utilisé dans votre code Terraform est correcte par rapport à ce qui est déployé. Si ce n'est pas le cas, vous devrez rajouter les paramètres spécifiques en vous référant à la documentation de la ressource que vous utilisez.
Pour résumer, vous pouvez créer des ressources à l’extérieur de Terraform et les importer par la suite grâce a la commande terraform import. Le mieux reste tout de même d’éviter ce genre de cas où des interventions manuelles (donc parfois longues) sont nécessaires. Pour l’instant, la commande terraform import ne permet pas de générer le code associé à l'import. C'est pour cette raison qu’il faut écrire le code associé en premier lieu et, seulement après, effectuer l’import de la ressource dans le fichier d’état Terraform.
On a pu voir en détail l'utilisation de la commande terraform state mv ainsi que terraform import. Ces deux commandes rempliront la plupart de vos besoins de gestion du fichier d'état de Terraform. Pour être complet, il existe une dernière commande, terraform state rm, qui permet “d'oublier” une ressource du fichier d'état. Je l'utilise personnellement assez peu, mais elle peut parfois vous faciliter certaines tâches et reste une approche valide dans certains cas.
Conclusion
La lecture des plans à la recherche du pattern de destruction/création que l'on a pu voir dans cet article est primordiale, car même si Terraform possède quelques mécanismes de protection (le lifecycle prevent_destroy par exemple), ces derniers ne vous éviteront pas les manipulations de fichier d'état Terraform. Une fois ces patterns détectés vous pourrez facilement décrire les opérations nécessaires via la commande terraform state mv.
La notion d'état est très présente lorsqu'on gère une infrastructure avec Terraform. La gestion de ce concept demande de bien le connaître et vous obligera à effectuer les manipulations dont nous avons parlé dans l'article.
Une fois ces concepts de migration bien compris, vous aurez sans doute envie de les automatiser. En effet, la manipulation des fichiers d'états Terraform peut être parfois longue et fastidieuse. Il existe plusieurs manières de s'en sortir face à cela, nous en verrons deux dans mon article de la semaine prochaine : Comment et pourquoi industrialiser la manipulation des fichiers d'état de son infrastructure ?