

« C’est pas comme ça que je l’imaginais » - votre PO. « C’est bizarre, ça ne marche plus » - un utilisateur final après votre session de refactorisation. Si vous avez eu des flashbacks peu agréables suite à ces citations et que vous développez des data pipelines, sachez que cet article peut vous aider à ne plus revivre ces instants douloureux.
En effet, je vais vous y proposer une méthode mêlant le test first et une version data du BDD (Behaviour Driven Development). Cette méthode vous permettra de mieux comprendre ce que vous devez développer et d’éviter les régressions en testant votre code.
Mais vous vous demandez probablement : pourquoi ces deux pratiques inspirées ? Car elles se combinent parfaitement ensemble et répondent selon moi à plusieurs pain points courants dans la construction de pipelines de données (nous les appellerons aussi data pipelines par la suite). Nous adresserons principalement deux types de problèmes grâce à cette méthode :
- le fait de tester le pipeline de bout en bout, ce qui est souvent compliqué à cause de la présence de low code et d’infra as code,
- l’accès au savoir métier.
Découvrons donc ensemble comment tester vos pipelines de données de bout en bout et comment comprendre les PO !
Définition des termes
Le data pipeline
Avant de chercher à ne pas introduire de régression dans notre data pipeline, nous allons définir ce qu’il est. Le data pipeline est l’ensemble des briques entre la création de la donnée et la fin de son traitement, par exemple, l’infrastructure et le code qui permet de passer d’un fichier csv à la couche gold d’un data warehouse. Pour ne pas introduire de régression dans ce data pipeline, nous allons automatiser des tests et plus précisément, appliquer une approche* test first*.
Les tests
Maintenant que nous savons qu’il faut tester, il reste une inconnue majeure : à quoi ressemble un test ? En effet, si on prend l’exemple du craft (software craftsmanship), on a plein de types de tests (unitaire, intégration ou composant par exemple). Le problème, c’est que ces tests suffisent s’il s’agit de tester des briques sans les déployer. Dès lors que l’on veut tester une infrastructure par exemple, ils ne sont plus suffisants car il faut déployer l’infrastructure. C’est pourquoi nous allons créer un nouveau type de tests que nous nommerons data-test (NDA : Oui, leur nom est arbitraire, mais c’est mon article, je fais ce que je veux.). Nous les définirons comme suit : un data-test est un test permettant de vérifier le bon fonctionnement de toutes les briques de notre data pipeline.
Data-BDD
Maintenant que nous savons quoi tester et ce que doit faire notre data-test, intéressons-nous à une façon de définir ce qu’il doit vérifier. Pour cela, nous allons appliquer une sorte de dérivé du BDD car ce dernier ne convient pas forcément aux problématiques de la data. L’idée ici est de prendre un exemple lors de la définition de notre US et de créer une discussion à partir de cet exemple. C’est cette partie qui en plus de définir vos tests va vous permettre de mieux comprendre le comportement cible de votre data pipeline. Tout comme pour les tests, de sorte à éviter une lourdeur syntaxique, nous l’appellerons data-BDD.
Pourquoi utiliser cette méthode de travail ?
L’idée de cette méthode de travail est de s’appuyer sur le data-BDD pour la discussion avec le PO et la définition des data-tests. Pour la partie développement du pipeline, on se base sur nos tests pour développer avec une approche test first et les avantages que cela présente. De plus, les data-tests ont le gros avantage de ne pas être dépendants de l’implémentation : la seule nécessité est de savoir ce que l’on a en entrée et ce que l’on veut avoir en sortie. Cela permet de tester des pipelines de données utilisant du low code et de tester le bon fonctionnement de votre infrastructure (donc de tester l’infra as code).
Grâce au data-BDD, vous disposerez en tant que développeur d’une meilleure compréhension du métier qui vous permettra à terme :
- d’être plus pertinent dans vos discussions avec le PO,
- de répondre au moins partiellement à la problématique d’accès au savoir du métier en améliorant vos capacités de communication avec le PO,
- de connaître les cas cassants, de les tester et donc d’améliorer la résilience de votre data pipeline qui sera moins sensible à des données imprévues (cf cette vidéo si le sujet de la résilience des data pipelines vous intéresse),
- simplifier l’accès à la donnée en demandant des échantillons en exemple.
Enfin, grâce à l'approche test first, vous allez automatiser vos tests et donc réduire les risques de régression lors d’une refactorisation du code. De ce fait, vous aurez sécurisé votre équipe dans son travail en plus de tout un tas d’avantages liés à l’automatisation des tests (pour plus de renseignements sur les avantages des tests automatisés, vous pouvez lire Accelerate : Building and Scaling High Performing Technology Organizations). Sachez simplement qu’ils peuvent avoir des impacts très divers sur votre équipe, allant de la facilitation du déploiement continu à une plus grande satisfaction des développeurs.
Comment mettre la méthode en place ?
Un exemple pour mieux comprendre
La méthode repose, comme le BDD, sur le fait que l’on comprenne mieux les choses que l’on observe. Histoire de faire une petite mise en abîme, nous allons prendre un exemple qui va nous permettre de mieux comprendre la méthode présentée.
Nous allons nous baser sur un pipeline impliquant de l’infra as code qui sera composé d’un Kinesis Data Streams, un Kinesis Firehose et un S3 pour stocker la donnée, le tout paramétré dans Terraform. Concernant l’ETL, nous utiliserons Glue. On notera que si on peut utiliser des tests unitaires sur Glue pour faire du TDD, ce n’est pas le cas du reste de notre pipeline. Nous allons donc voir comment cette méthode va nous permettre de définir et de tester notre flux de données.
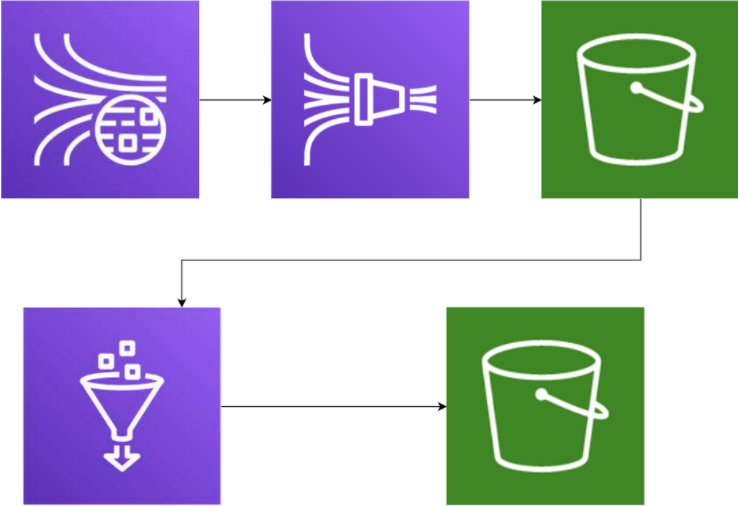
Architecture du pipeline défini en exemple
L’atelier data-BDD
Une fois que vous avez compris de quoi il s’agit, il est temps de passer à la pratique. Pour ce faire, rien de plus simple : lancez-vous lorsque vous parlez avec votre PO, demandez-lui des cas concrets. Si on reprend notre exemple, vous pouvez lui demander un exemple de message arrivant dans Kinesis Data Streams. Disons que le message ressemble à ceci :
{
"magasin" : {
"produits" :[
{
"nom" : "yaourt",
"date_de_peremption" : "19/04/2022"
},
{
"nom" : "haricots",
"date_de_peremption" : "7/12/2022"
}
]
}
}
Notre PO nous dit que les dates de péremption sont saisies à la main et qu’il faut qu’elles soient au format JJ/MM/AAAA. Si elles ne respectent pas ce format, on doit alors les accepter dans le premier bucket qui sert de couche bronze et les rejeter des couches suivantes. Dans notre message, on voit que la première date respecte bien notre contrainte, mais la seconde ne la respecte pas car le format des jours n’est pas celui attendu. Super, on a réussi la première étape ! Mais un exemple, ce n’est pas toujours assez.
Que se passe-t-il si j’ai cet autre message ?
{
"magasin" : {
"produits" :[
{
"nom" : "yaourt",
"date_de_peremption" : "19/04/2022"
},
{
"nom" : "haricots",
"date_de_peremption" : "7/12/2022"
}
]
}
}
D’un coup, on voit bien que le format semble respecté si on se fie uniquement au nombre de chiffres, mais ça ne marche pas si on prend aussi en compte qu’il n’y a que 12 mois dans l’année. Et il ne faut pas oublier que notre fichier est un JSON. Que se passe-t-il si le produit est un paquet de mouchoirs, y aurait-il une date de péremption malgré tout ou la clé serait-elle absente ?
Attention simplement à ne pas trop vous éparpiller : définissez le scope de l’US, et lorsque vous posez des questions, évitez de trop dévier du sujet et d’aller empiéter sur une autre US.
Quand devriez-vous en parler ? Tout d’abord, c’est lors d’une conversation en synchrone, sans quoi on perd l’aspect brainstorming/spontané. Vous devez en parler évidemment avec votre PO, votre testeur (QA) s’il y en a, mais vous pouvez y inviter toute personne qui va être amenée à travailler sur cette US (un testeur par exemple). Cette discussion intervient juste avant de traiter l’US, généralement sur le sprint où on l’embarque pour que tout le monde ait la discussion en tête.
Le développement en test first
Pour implémenter des tests issus de l’atelier avec notre PO, on pourrait penser à Great Expectation qui est l’étoile montante du test dans la data (un article sur la mise en place de tests Great Expectation devrait d'ici peu, n'hésitez pas à y jeter un oeil). Cependant, Great Expectation gère principalement les tests sur la transformation de données et pas sur un data pipeline complet. Dans notre cas, je vous recommanderai de faire des tests via Pytest ou Junit. Même sans utiliser un outil spécifique, un tel test peut rester contenu (quelques dizaines de lignes maximum).
Par exemple, dans un projet précédent sur une architecture très similaire à celle de notre exemple, nous avons effectué des tests en Java dans lesquels on appelait l’API de Kinesis pour y envoyer un message avant d’attendre que la donnée de ce message arrive de l’autre côté du pipeline pour vérifier son contenu.
Dans le cadre de notre exemple, on pourrait mettre tout cela en place de la manière suivante : avec un fichier bash, on crée un workspace de tests avec Terraform qui inclurait les différentes briques nécessaires au fonctionnement de notre pipeline. Ensuite, on y dépose un ou des messages via l’API Kinesis Java ou Python, on attend la fin du traitement et on fait nos assertions sur le résultat obtenu.
Les limites de cette méthode
Les limites des data-tests
Ces tests ne sont pas exempts de défauts, ceux-ci étant principalement liés au fait qu’ils testent énormément de choses différentes dans un seul data-test. Il en découle plusieurs problèmes :
-
on ne peut pas tester toutes les possibilités car la combinatoire est énorme,
-
les tests mettent beaucoup de temps à passer donc on ne peut pas utiliser une approche test driven (vous serez probablement dans l’ordre de grandeur de la minute pour pour que votre donnée aille d’un bout à l’autre du pipeline).
Deux autres problèmes sont à noter : tout d’abord, il peut être compliqué de mettre les data-tests en place. Ne serait-ce que dans notre exemple, il faut gérer les droits pour upload le message pour nos tests, il faudra potentiellement gérer des credentials pour pouvoir être identifié, etc.Il faudra aussi penser à créer un système de timeout si notre donnée met trop longtemps pour ne pas attendre indéfiniment une réponse s’il y a une erreur dans notre pipeline. Enfin, si vous vous lancez dans un tel test sans savoir exactement à quoi ressemblera votre sortie (car vous ne connaissez pas la technologie sur laquelle vous travaillez par exemple), cela pourrait vous bloquer dans l’écriture de votre test et vous serez alors condamnés à adapter votre test à vos développements, ce qui n’est pas une bonne pratique.
Cependant, la plupart de ces défauts sont à nuancer:
-
en faisant un data-test sur une sous-partie du pipeline, on peut limiter le problème de la combinatoire,
-
une fois la structure des tests mise en place, vous n’aurez plus à vous inquiéter de la gestion des credentials,
-
généralement, on sait à quoi doit ressembler la sortie de notre data-pipeline avant de commencer les développements, donc ce point est rarement gênant.
Les limites du data-BDD
Si le data-BDD n’est pas suffisant pour communiquer avec votre PO et le comprendre, je peux vous conseiller deux choses. La première est d’aller chercher dans la boîte à outils qu’est le DDD (je vous conseille cet article dessus). Par exemple l’ubiquitous language peut vous permettre de mieux comprendre le métier en parlant son jargon. Deuxièmement, si vous souhaitez améliorer la communication avec votre PO ou l’accessibilité de la donnée, l’organisation data mesh vous permettrait de le faire bien plus efficacement. Sachez cependant que sa mise en place demande de casser les silos et donc d’avoir l’appui de la direction. Or, ce n’est pas le cas de la plupart des data engineers qui doivent généralement se contenter d’une influence restreinte aux limites de leur équipe, et c’est là que cette méthode intervient. Cependant, si vous pouvez mettre cela en place, je vous conseille cet article si vous ne savez pas de quoi on parle.
Conclusion
En bref, cette méthode vous permettra de faciliter la compréhension de votre PO grâce à la partie data-BDD. De plus, l’approche *test first *avec les data-tests vous permettra de tester votre pipeline de manière automatisée. Je tiens cependant à attirer votre attention sur un point : les deux parties de cette méthode sont séparables. Vous pouvez tout à fait définir vous même vos tests de data pipeline en vous basant si vous le souhaitez sur les exemples donnés dans cet article, tout comme vous pouvez vous intéresser au data-BDD de manière isolée.
Enfin, même si cette méthode admet des limites, je pense malgré tout qu’elle est particulièrement intéressante pour tester un data pipeline et comprendre le métier. En effet, elle est très simple à mettre en place par rapport aux autres solutions que j’ai pu voir et peut tout à fait résoudre les problèmes de régressions de vos data-pipelines.
