
Nous avons réalisé l’application e-commerce d’une enseigne de grands magasins. La crise sanitaire a provoqué la fermeture de certains points de vente. Cela s’est traduit par une baisse directe du chiffre d’affaires. Le client a alors compris qu’une application mobile évolutive et pérenne était indispensable. Cette dernière venait avec de grandes ambitions et de nombreuses fonctionnalités. Il nous fallait alors choisir l'architecture la plus adaptée aux différents entrants. Nous savions que le produit allait être imposant. Nous allons vous détailler la réflexion qui nous a amené vers l’architecture hexagonale. Nous vous présenterons aussi un exemple d’implémentation en concluant sur les avantages et les limites de l’approche. Vous pouvez retrouver la seconde partie ici.
Contexte
Application Android : double backend avec possibles évolutions
Lorsque nous avons pris connaissance du projet, l’une des contraintes était l’utilisation de deux backends différents, avec deux technologies différentes : REST (actuel) et GraphQL (cible) avec un objectif de migration vers GraphQL à terme.
Mais pas seulement ! Le schéma suivant résume la situation :
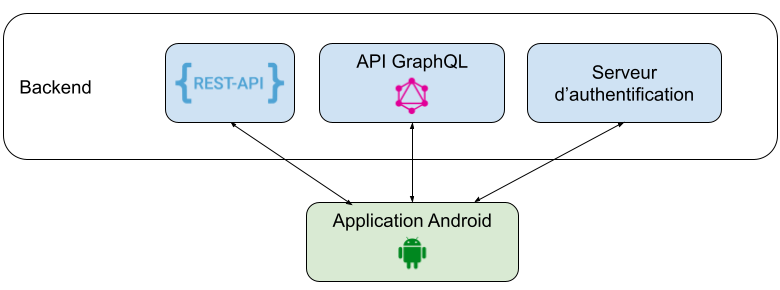
Afin de tempérer la complexité inhérente au multi-backend, nous devions les isoler du reste de l’application. Par exemple, le code métier ne devait pas être modifié pour passer d’un backend à un autre.
Projet à vocation d’être imposant
Cette application a comme ambition de devenir le compagnon idéal du client : expérience omnicanale, parcours magasin amélioré… Elle doit fournir des fonctionnalités simplifiant les achats et aider la marque à être au plus près de ses clients.
Qui dit projet imposant dit grand nombre de fonctionnalités, de développements et de développeurs.
Besoin de séparation des fonctionnalités (réutilisation / build time / cache gradle / module)
Lorsque de nombreux développeurs travaillent en parallèle, il est important de délimiter son périmètre d'intervention. Des fonctionnalités bien découpées et définies peuvent séparer les développements. Nous voulions que cela soit visible dans le code. Cela facilite in fine les tests et minimise les conflits sur les Merge Requests. On gagne alors un temps fou (et de la patience) !
Côté machine nous voulions un système de cache pour build uniquement les fonctionnalités modifiées. Avoir une Horizontal Scalability de l’application est nécessaire tant les builds sur Android peuvent être lents.
L’existant vs le besoin
Nous allons présenter les différentes architectures étudiées lors de la conception de cette application, accompagnées des raisonnements associés.
Architectures couramment utilisées
Sur Android, les patterns MVx sont souvent mis en avant. En premier, le MVC (Model, View, Controller), puis le MVP (Model, View, Presenter), le MVVM (Model, View, ViewModel) et le MVI (Model, View, Intent).
Pattern MVC
Parmi l’un des plus anciens patterns utilisés, MVC :
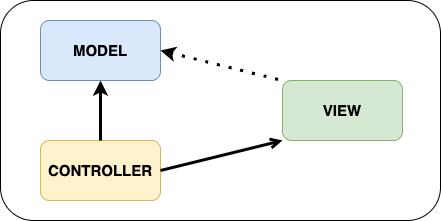
Ce pattern est représenté par :
- Le modèle : c’est la partie gestion des données. Il est observé (Observable)
- La vue : c’est la partie interface utilisateur. Elle se met à jour avec les données qu’elle observe du modèle (Observer)
- Le contrôleur : Il met à jour le modèle et choisit la vue à afficher.
- Malgré une bonne application de ce pattern, les activités/fragments se retrouvent bien souvent avec le double rôle de vue et de contrôleur. Cela est contraire au SRP.
Pattern MVP
Le pattern MVP est un dérivé du MVC. Le modèle n’est plus observé. Plutôt que de laisser la View se mettre à jour seule, c’est le Presenter qui déclenche les mises à jour.
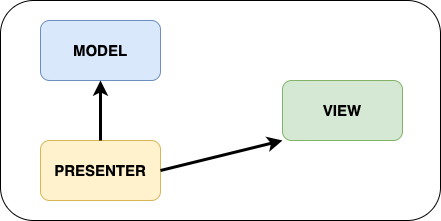
Le Presenter, comme un Controller, met aussi à jour le modèle. Puisque la vue ne gère plus elle-même sa mise à jour, il faut être vigilant quant aux problèmes de cycle de vie.
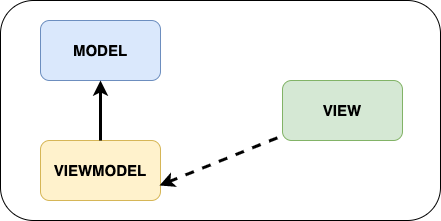
Pattern MVVM
MVVM est aujourd’hui le pattern qui est le plus utilisé sur Android. On y retrouve :
- Le modèle : c’est la partie gestion des données.
- La vue : Il s’agit de la couche UI. La vue observe le ViewModel pour se mettre à jour avec les nouvelles données.
- Le ViewModel : Il ne connaît pas la vue. Il expose la donnée observable récupérée auprès du modèle
Pattern MVI
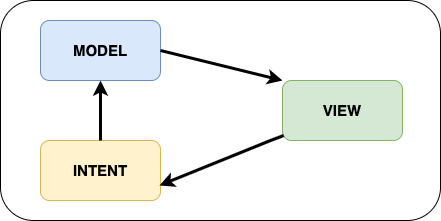
Le pattern MVI est parmi les plus récents patterns d’architecture utilisés avec Android. On y distingue plusieurs composants :
- L’intent : il représente l’intention ou l’action d’un utilisateur, qui va alors être transcrite en un nouvel état.
- Le modèle : son rôle diffère des autres patterns, puisqu’il va stocker un état immuable (car le flux est unidirectionnel ici).
- La vue : elle récupère un nouvel état et met à jour l’UI.
Utiliser MVx
Parmi les conséquences fâcheuses on citera :
- Des fichiers énormes
- Une lisibilité réduite
- Une difficulté à tester nos applications
- Du code métier dur à identifier
Nous savions que le projet allait durer dans le temps et allait comporter un large éventail de fonctionnalités.
Cela n’était pas suffisant. Nous décidions alors de continuer nos recherches et d’élargir nos champs de vision. Objectifs :
- Découpler très fortement le code Android du métier
- Avoir des couches réseaux / données interchangeables facilement
- Être compatible au maximum avec les Android Architecture Components (AAC) de Jetpack (Jetpack ViewModel entre autres).
Architectures autres
Nous nous sommes naturellement d’abord tournés vers iOS. Le pattern VIPER va plus loin que MVx dans le découplage.
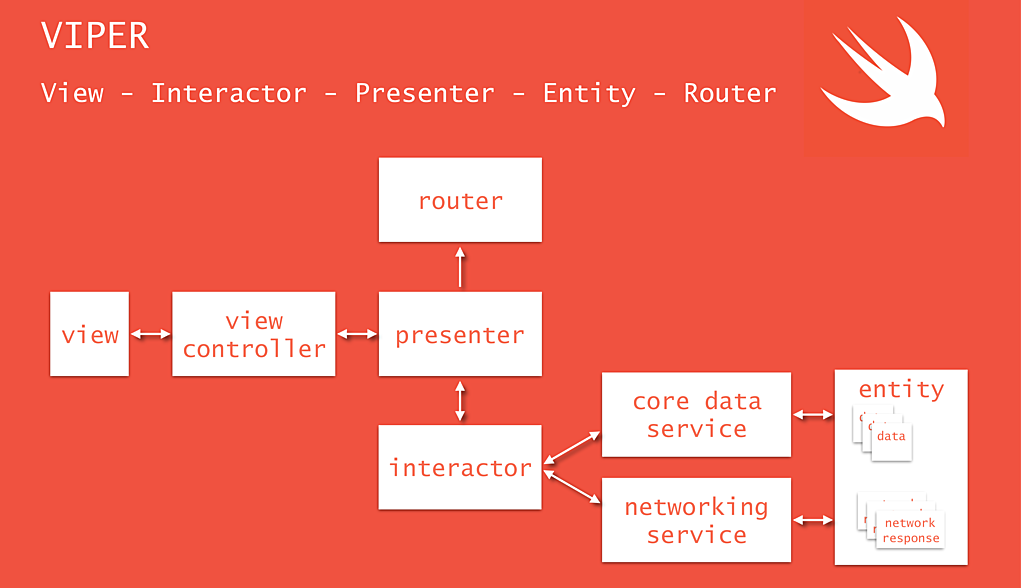
Sans rentrer dans le détail, ce pattern se distingue par la présence à la fois d’interactors, responsables du code métier, et de routers, responsables de la navigation. Selon de nombreux articles, ce pattern est l’application d’une Clean Architecture sur iOS.
Bien que séduisante, cette option ne respectait pas le besoin initial, à savoir utiliser au maximum les AAC :
- Jetpack Navigation pour le routing (donc pas de router)
- Jetpack ViewModel pour de la gestion d’état de vue événementiel (pas de presenter).
En creusant un peu plus sur la Clean Architecture, nous nous sommes renseignés sur ce que faisaient nos collègues développeurs web fullstack. Nous entendions parler d’Architecture Hexagonale.
Qu’est-ce que l’architecture hexagonale ?
Concept présenté d’abord par Alistair Cockburn, l’architecture hexagonale, ou Ports and Adapter, est une autre forme de Clean Architecture.
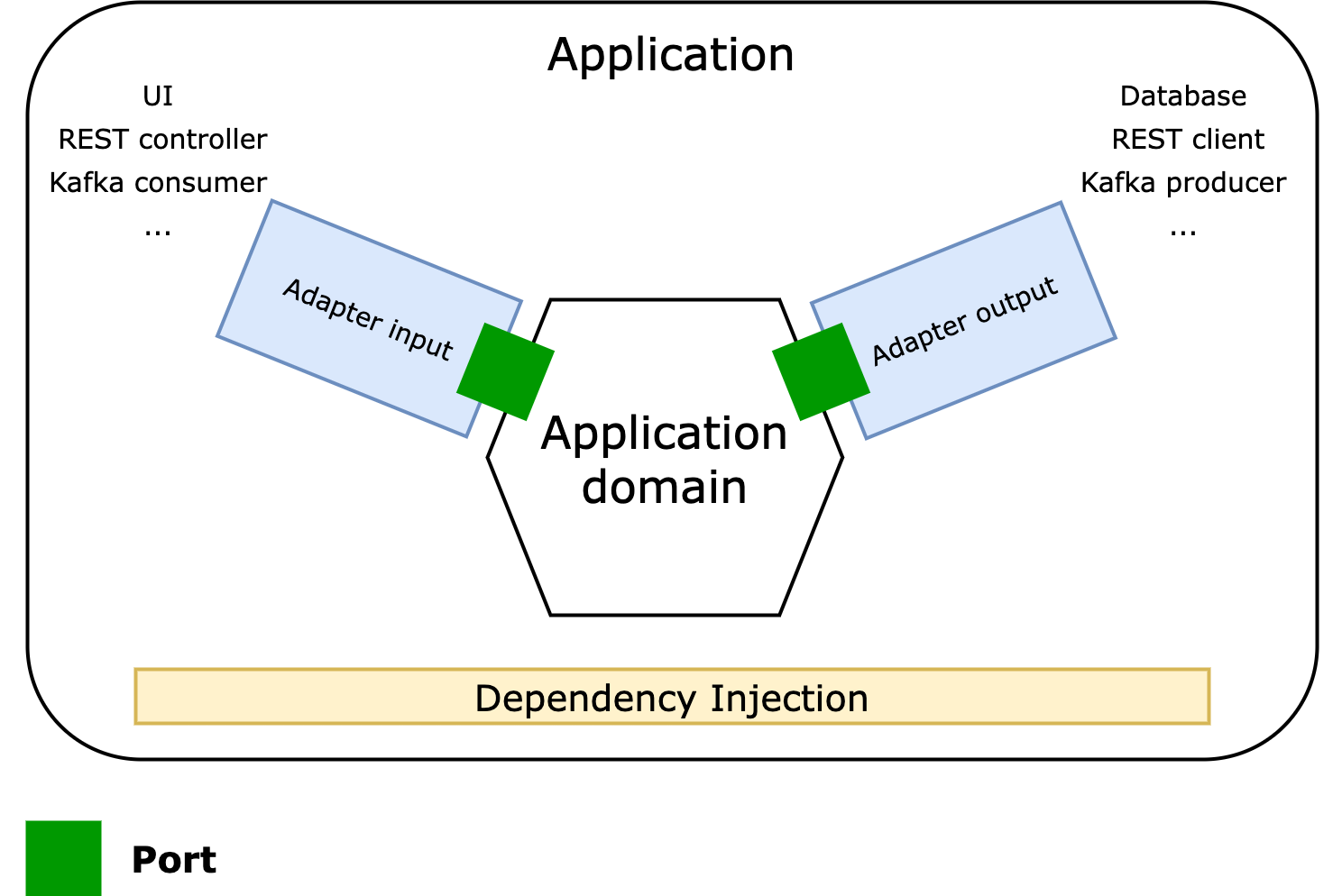
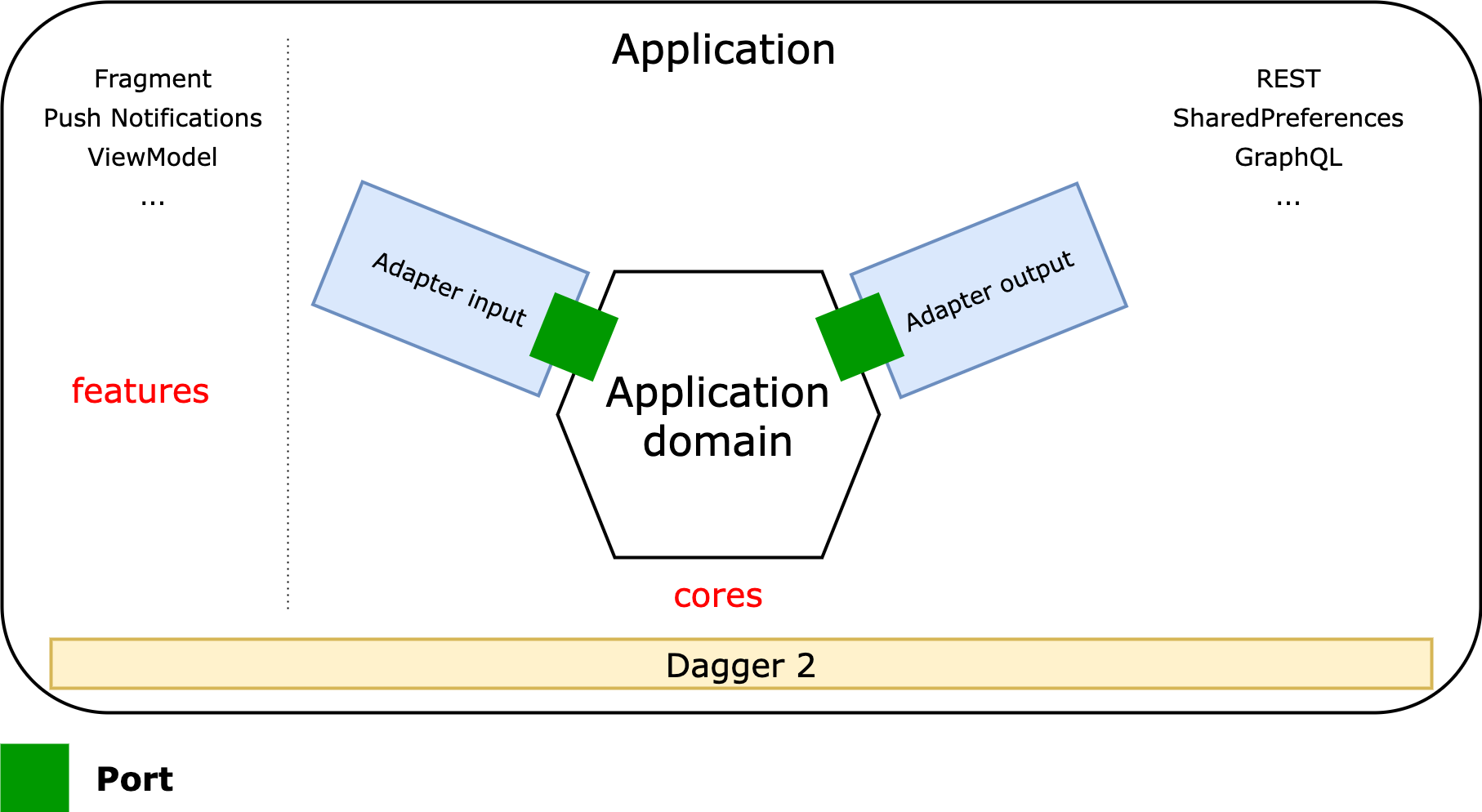
Même si tous les termes qui la définissent paraissent parfois compliqués, le principe est finalement plutôt simple. On peut la visualiser en 5 parties :
- Au centre, le code “métier” : les règles de gestion, cas d’usage, etc.
- À gauche, les flux entrants : appel REST, consumer Kafka…
- À droite, les flux sortants : persistance, appel à un serveur externe…
- Le métier expose des ports entrants (à gauche) et consomme des ports sortants (à droite). Un port est une interface.
- Des adapters entrants ont des dépendances sur les ports entrants. Des adapters sortants implémentent les ports sortants.
- Les liens sont facilités par l’inversion de dépendances. Les frameworks utilisant de l’injection comme Spring pour le web ou Dagger côté Android sont parfaits pour cette architecture.
L’énorme force de cette architecture est de proposer un découpage simple du code, et un découplage en profondeur du métier vis-à-vis du reste. Les décisions liées aux frameworks sont plus facilement reportées, et la testabilité du produit est poussée au maximum.
Ces énormes avantages sont obtenus grâce aux ports qui sont les garants d’une forte isolation.
Pour rappel, notre besoin initial était de supporter deux types de backends, GraphQL et REST. Nous devions aussi offrir une flexibilité quant aux solutions de persistances utilisées.
Nous savions surtout que des parties structurantes de l’application allaient évoluer à l’avenir. Parmi elles :
- Passage de persistance locale à une persistance sur le serveur
- Migration de services REST à GraphQL
Après mûre réflexion, nous nous sommes lancés dans l’hexagone !
Notre approche
Nous nous sommes efforcés de pousser la réflexion autant que possible pour rendre le projet scalable et utilisable par plusieurs développeurs qui travaillent en parallèle.
Structuration du projet v1
Notre projet utilisait Gradle. Un des moyens de passer à l’échelle avec cette technologie est de faire du multi-modules. Ainsi, Gradle peut paralléliser le build, et surtout profiter de cache pour ne rebuild que les modules impactés par une modification.
Lors des premiers incréments du projets, nous créions :
- des modules “common”, encapsulant des blocs de codes communs. Ces modules ne suivaient pas l’architecture hexagonale. C’étaient des Shared Kernel.
- des modules de features. Ils suivaient l’architecture hexagonale.
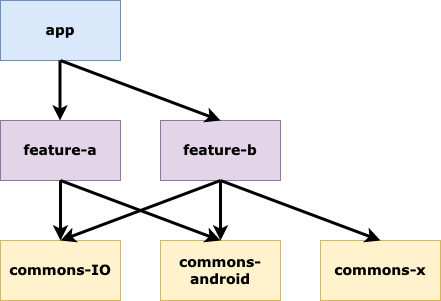
Regardons la structure qu’avait un module feature :
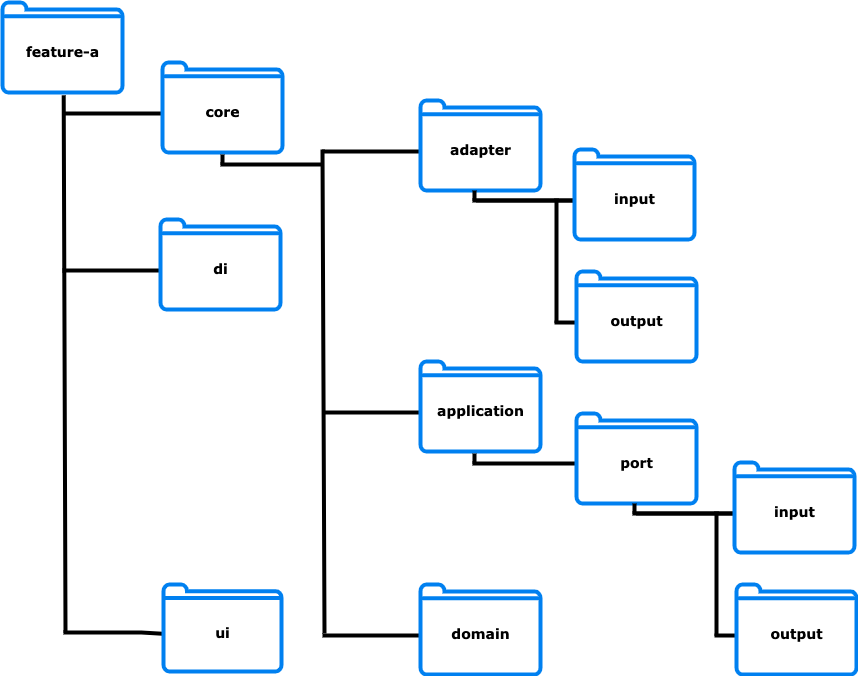
3 grandes parties sont à distinguer :
- L’UI et son ViewModel
- Le Core, conteneur des adapters, ports et du domain
- La DI (Dependency Injection), qui fait le liant entre tous les éléments d'une feature
Si on recontextualise dans l’architecture hexagonale, voici où nous en sommes :
Structuration du projet v2
Au fur et à mesure des développements, nous avons eu besoin de réutiliser des adapters et domains. Nous avons donc opté pour une granularité plus fine, avec une séparation des cores dans des modules dédiés :
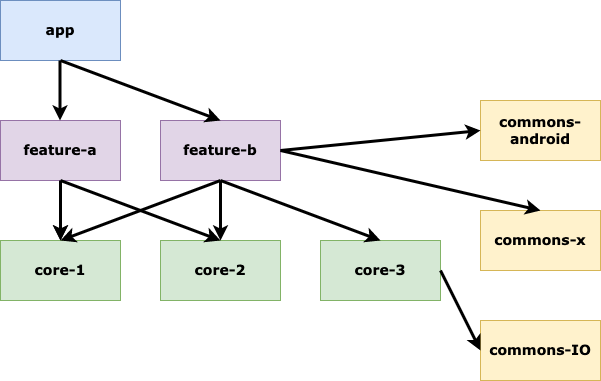
Un module de feature ne contenait alors plus que l’UI, les viewmodels et un peu de DI.
Un module core était extrait en l’état avec sa DI associée. Ainsi, un module feature / core avait une relation Customer / Supplier.
Navigation
Nous avons choisi d’utiliser Jetpack Navigation. Cette brique est efficace pour gérer les routes dans l’application :
- Elle est visuelle grâce à l’éditeur dédié situé dans Android Studio.
- Elle est simple à mettre en place.
- Elle est accompagnée d’un plugin Gradle pour générer des safe args. Ainsi, les arguments passés à une route cible sont typés fortement : il y a la sécurité à la compilation.
Chaque graphe de navigation est embarqué dans un module de feature. Si une partie de la feature devait être réutilisée ailleurs dans l’application, elle était simplement extraite dans un module de feature dédié. On profitait alors d’un double effet :
- Factorisation de code
- Horizontal Scalability du build grâce au cache Gradle et à la compilation parallélisée
Gestion d’événements applicatifs
Nous avons rapidement eu besoin de générer des événements applicatifs. Nous avons par exemple dû propager la modification du panier d’achats ou l’état de la session de l’utilisateur.
Nous avions d’abord pensé créer un module core dédié. Cependant, cela présentait plusieurs inconvénients :
- ce module risquait de devoir être inclus dans quasi chaque core et feature ; ie être un supplier inclus dans quasiment chaque customer.
- il ne porterait aucune notion métier. Son rôle se limiterait à transmettre des événements.
Nous avons alors décidé de définir une interface qui jouerait le rôle d’EventBus dans un des packages commons (shared kernel). L’implémentation est triviale : un LiveData est utilisé comme receiver et dispatcher :
class DefaultApplicationEventBus @Inject constructor() : ApplicationEventBus {
private val _events = MutableLiveData<ApplicationEvent>()
override val events: LiveData<ApplicationEvent>
get() = _events
override fun dispatchEvent(event: ApplicationEvent) {
_events.postValue(event)
}
}
Dans l’utilisation d’un LiveData, il faut en revanche vérifier que l’événement transmis ne soit pas consommé deux fois. Le cas typique est un changement d’orientation ou un retour sur l’écran qui redéclenche la consommation du LiveData.
Thread Management
Worker / UI Threads et domaine métier
En ayant en tête que le domaine métier doit être le plus isolé possible des bibliothèques et frameworks, nous avons externalisé la gestion des threads dans les adapters. Nous avons utilisé les coroutines Kotlin, le moyen le plus simple et efficace pour faire du threading.
Pour nous assurer que nous gérions chaque traitement dans le thread approprié, nous nous sommes imposés les conventions suivantes :
- Un InputAdapter (appelé par un ViewModel) exécute toutes ses méthodes publiques sur un Worker Thread
- Un OutputAdapter (appelé par le domain via des ports) exécute ses méthodes :
- Sur l’UI Thread dans le cas où l’accès au Context Android est nécessaire
- Sur un Worker Thread pour tout le reste
Les threads en question étaient disponibles par injection via des interfaces, implémentées par les adapters. Par exemple :
interface InputAdapter {
val adapterScope: InputAdapterScope
}
InputAdapterScope est une classe qui expose un CoroutineContext en étendant AdapterScope.
import kotlin.coroutines.CoroutineContext
class InputAdapterScope(context: CoroutineContext) : AdapterScope(context)
abstract class AdapterScope(private val context: CoroutineContext) : CoroutineScope {
override val coroutineContext: CoroutineContext
get() = context
}
Un CoroutineContext est ce que l’on utilise pour choisir un thread :
class SampleInputAdapter @Inject constructor(
private val sampleUseCase: SampleUseCase,
override val adapterScope: InputAdapterScope
) : InputAdapter {
suspend fun getSample() = withContext(adapterScope.coroutineContext) {
/* code */
}
}
Pour un OutputAdapter qui a deux scopes (UI et Worker), cela se présente comme ceci :
class SampleOutputAdapter @Inject constructor(
override val adapterScopeMain: OutputAdapterScopeMain,
override val adapterScopeWorker: OutputAdapterScopeWorker,
) : OutputAdapter, SamplePort {
suspend fun getSample() = withContext(adapterScopeMain.coroutineContext) {
/* code */
}
}
Selon si getSample doit être sur l’UI Thread ou un Thread Worker, il faudra renseigner adapterScopeMain ou adapterScopeWorker.
Éviter les race conditions
Une application mobile manipule plusieurs threads. Celui qui gère les actions utilisateurs (UI Thread) est différent de ceux qui les consomment (Worker Threads). Des problèmes de race conditions peuvent alors apparaître. L’exemple typique est un utilisateur qui clique deux fois sur un bouton. L’événement de clic déclenche à son tour un traitement lourd tel qu’un appel réseau. Puisque les threads UI et Network sont différents, une même requête sera dupliquée. C’est un comportement indésirable.
Il y a plusieurs moyens de résoudre ce type de problème. Souvent, on pense d’abord à désactiver le bouton dès que le clic est déclenché ; puis on le réactive une fois que la requête est terminée. Nous avons préféré faire autrement, en utilisant des mutex.
Ce composant sert de verrou, de goulet d’étranglement pour les requêtes. Le principe : synchroniser la réception des actions utilisateurs dans le ViewModel. Par exemple, pour ignorer une action qui arriverait avant la fin d’une autre dans le ViewModel, on peut implémenter :
fun <T> safeLaunch(block: suspend () -> T) = viewModelScope.launch {
if (!mutex.isLocked) {
mutex.withLock { block() }
}
}
Domaine métier
Le domaine métier est censé être le plus isolé possible. En d’autres termes, il ne doit contenir aucune référence à des bibliothèques ou frameworks. Pour notre application, nous avons considéré que les coroutines et mots clés associés (comme suspend) faisaient partie du langage utilisable dans le métier.
Conclusion
Cet article présente notre démarche et les choix qui nous ont conduits à utiliser l’architecture hexagonale. Nous vous présenterons dans un prochain article un exemple d’implémentation en concluant sur les avantages et les limites de l’approche.



{kind=link}