

L'observabilité est à une application ce qu'un tableau de bord est à une voiture. A chaque instant, il est nécessaire de connaître sa performance, et de savoir si elle est fonctionnelle. Si un incident survient, il faut être alerté rapidement afin de réagir au plus vite.
Le serverless a pris ces dernières années de plus en plus de place dans les plateformes hébergées sur le Cloud car il permet de se concentrer sur les fonctions qui créent de la valeur en déléguant une partie infrastructure au fournisseur cloud. Le serverless ne nous permet cependant pas de s'abstraire des besoins de monitoring. Aujourd'hui, je vous propose que l'on s'intéresse à l'observabilité d'une stack serverless sur AWS.
Pour le cas d’étude, nous allons utiliser plusieurs services AWS serverless : API Gateway, Lambda et DynamoDB. API Gateway sert de porte d’entrée et relaie les requêtes à Lambda. Lambda exécute le code applicatif et se contentera de procéder à des opérations CRUD sur DynamoDB. Le tout formera un “Store and Load”, sans opération particulière sur les données.
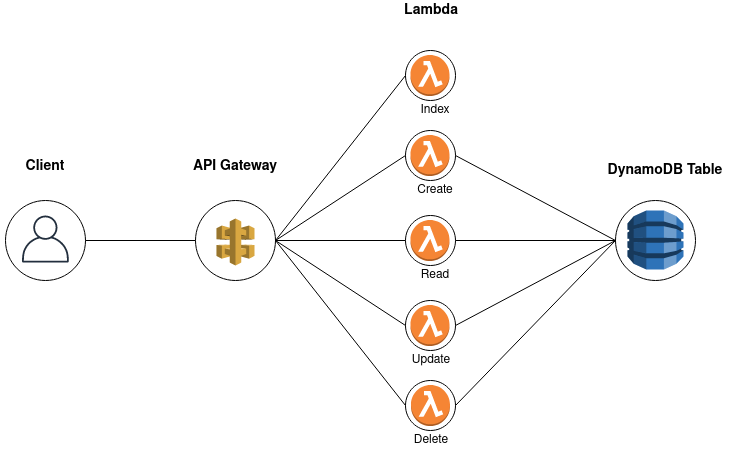
Tout le code présenté dans la suite de l’article peut être trouvé ici.
La donnée avant tout
L’observabilité permet de mesurer et d’historiser l’état d’un système, ce qui permettra par la suite de le caractériser pour en trouver ses limites.
CloudWatch est le service d'observabilité d’AWS. Les autres services d’AWS publient des données dans CloudWatch, sous la forme de métriques et de logs.
Les métriques représentent la santé et la performance de vos applications, et alimentent les alarmes et les dashboards. Elles sont associées à des dimensions pour indiquer la provenance de la donnée. AWS publie par défaut un certain nombre de métriques, vous pouvez choisir d’en publier davantage en activant le monitoring avancé sur certains services comme Lambda ou RDS. Si les métriques par défaut ne suffisent pas, vous pouvez publier vos propres métriques personnalisées.
Lambda Insights
Lambda Insight permet de collecter et de journaliser 8 métriques concernant l'exécution de la Lambda qui ne sont pas présentes par défaut. Ces métriques sont stockées dans CloudWatch et donnent des informations côté hardware comme la consommation CPU, mémoire… En somme, cela va permettre de mieux suivre le cycle de vie d'une Lambda.
Le code terraform associé :
resource “aws_lambda_function” “name”{
role = aws_iam_role.lambda_role.arn
#…
layers = ["arn:aws:lambda:${var.aws_region}:580247275435:layer:LambdaInsightsExtension:14"]
#…
}
resource "aws_iam_role_policy_attachment" "lambda_insights" {
role = aws_iam_role.lambda_role.name
policy_arn = "arn:aws:iam::aws:policy/CloudWatchLambdaInsightsExecutionRolePolicy"
}
L'Amazon Resource Name (ARN) de la layer dépend de la région dans laquelle vous déployez, on peut retrouver l’ARN correspondant à la région que l’on veut ici.
L'ARN de la layer Lambda ne peut pas être récupéré dynamiquement via une ressource Terraform car les layers sont gérées par AWS dans des comptes qui leur appartiennent.
Les métriques collectées par CloudWatch peuvent être visualisées sur un dashboard. Cela permet assez rapidement de voir de nombreuses informations sur les Lambdas :
- le dimensionnement ;
- le temps d’exécution ;
- le coût ;
- le nombre d’invocations concurrentes cumulé ;
- ....

Tracing
Les traces permettent de suivre le cheminement d’une requête au sein d'un système distribué. Grâce à elles, on pourra, pour chaque requête, identifier les ressources appelées, l’ordre dans lequel elles ont été appelées ainsi que le temps passé dans chacune d’entre elles. Une trace se traduit par un identifiant unique ajouté en en-tête aux requêtes lors de leur entrée dans le système. Cet identifiant unique sera transmis à chaque sous-requête vers de nouvelles ressources. On pourra donc cartographier et mesurer le cheminement logique d’une requête. Le service d’AWS dédié au tracing est X-Ray.
Voilà la carte de tracing créée par X-Ray pour notre système :

Une requête part d’un client pour passer par API Gateway qui distribue ensuite les requêtes aux différentes Lambdas. Certaines font ensuite appel à DynamoDB.
Pour démarrer X-Ray, il suffit souvent d’activer le tracing, qui sera une simple case à cocher dans la console AWS pour la plupart des services, et ne sera pas plus difficile à activer avec Terraform :
resource "aws_api_gateway_stage" "main" {
#...
xray_tracing_enabled = true
}
resource "aws_lambda_function" "crud" {
#...
tracing_config {
mode = "Active"
}
}
Dans le code des Lambdas, afin de suivre les services appelés, il faut instrumenter en décorant le SDK avec X-Ray. Voilà comment procéder en NodeJS :
Sans X-Ray :
const AWS = require('aws-sdk')
const ddb = new AWS.DynamoDB.DocumentClient()
//….
Avec X-Ray :
const AWSXRay = require('aws-xray-sdk-core')
const AWS = AWSXRay.captureAWS(require('aws-sdk'))
const ddb = new AWS.DynamoDB.DocumentClient()
//…
Il n’y a donc qu’une ligne à ajouter, et une à modifier, sans avoir à toucher au reste du code. On pourrait également importer le SDK AWS avec ou sans tracing selon une variable d’environnement pour s’adapter à l’environnement de déploiement.
C’est ici un exemple minimal, limité au traçage des appels API vers AWS, il est possible d’ajouter des métadonnées, modifier des paramètres, mais également de créer des segments personnalisés, de tracer des appels vers des API non AWS...
Les traces sont visibles via la console AWS, sur laquelle on va pouvoir obtenir la cartographie des services, et visuellement voir d’éventuels goulots d’étranglement et/ou incidents. Implémenter de l’alerting avec X-Ray est, à l’heure actuelle, non trivial.

X-Ray permet, via du machine learning, de détecter des anomalies dans le fonctionnement des services. Il pourra par exemple repérer une augmentation irrégulière de la latence sur un segment, ou l’augmentation du nombre d’erreurs. Il repère la source du problème et génère un événement pour Amazon EventBridge. On pourra donc faire suivre cet événement à une Lambda ou un topic SNS par exemple. Pour cela, il faut activer X-Ray Insights. A l’heure de l’écriture de cet article, cette fonctionnalité n’est malheureusement pas “terraformable”. Le bémol étant que rien n’est paramétrable, tout est caché dans l'algorithme de machine learning.
Il est toujours possible de récupérer les traces via une Lambda, et de les analyser pour trouver les anomalies soi-même, mais c'est un travail fastidieux. Avec le SDK X-Ray pour Java, il est possible de publier automatiquement des métriques vers CloudWatch, puis de mettre en place des alarmes sur ces métriques.
Dashboard
Le dashboard, c’est la première chose qui permet d’avoir une vue d’ensemble sur votre application. Les données affichables proviennent des métriques CloudWatch. AWS propose par défaut des dashboards au niveau d’un service. Ceci étant, il est bien plus intéressant de créer ses propres dashboards pour avoir une vue plus générale sur un système.
Voici un exemple de dashboard personnalisé :

Il est possible d’ajouter des zones de texte écrites en markdown pour insérer des liens vers les services AWS à surveiller afin de naviguer plus facilement vers les ressources défaillantes :
resource "aws_cloudwatch_dashboard" "main" {
dashboard_name = "${local.prefix}-main"
dashboard_body = templatefile("${path.module}/templates/dashboards/dashboard.json.tpl",
{
lambda_names = values(aws_lambda_function.crud)[*].function_name,
dynamodb_table_name = aws_dynamodb_table.main.name,
apigw_stage_name = aws_api_gateway_stage.main.stage_name,
apigw_name = aws_api_gateway_rest_api.main.name,
api_id = aws_api_gateway_rest_api.main.id,
aws_region = var.aws_region
})
}
Voilà un exemple de widget contenu dans le template Terraform JSON qui va générer le dashboard personnalisé précédent :
{
"height": 6,
"width": 12,
"y": 3,
"x": 0,
"type": "metric",
"properties": {
"metrics": [
[ { "expression": "100*(m1/m3)", "label": "Proportion of 5XX errors", "id": "e1", "region": "${aws_region}" } ],
[ { "expression": "100*(m2/m3)", "label": "Proportion of 4XX errors", "id": "e2", "region": "${aws_region}" } ],
[ "AWS/ApiGateway", "5XXError", "ApiName", "${apigw_name}", "Stage", "${apigw_stage_name}", { "id": "m1", "visible": false } ],
[ "AWS/ApiGateway", "4XXError", "ApiName", "${apigw_name}", "Stage", "${apigw_stage_name}", { "id": "m2", "visible": false } ],
[ ".", "Count", ".", ".", ".", ".", { "id": "m3", "visible": false } ]
],
"view": "timeSeries",
"stacked": false,
"region": "${aws_region}",
"period": 60,
"title": "Request Errors",
"stat": "Sum"
}
},
La création d’un dashboard se fait nécessairement par un document JSON. Afin de variabiliser le dashboard, il faut utiliser la fonction
templatefilede Terraform.
Logs et alertes
Quand un incident survient, il est important d’en être averti rapidement. C’est à ce moment que les alarmes entrent en jeu.
Alarmes
AWS CloudWatch permet la mise en place d’alarmes via des métriques. Ces alarmes se déclenchent au dépassement d’un seuil au-delà duquel on considère que le système a potentiellement un problème. Lorsque ce seuil est dépassé, une action est déclenchée. Par exemple, on peut envoyer un message à un topic SNS, ou appliquer une stratégie d'auto-scaling (comme avec les Auto-Scaling groups dans EC2).
Vous trouverez juste après un exemple d’alarme permettant de détecter du throttling sur des Lambdas. Le throttling correspond à une requête refusée car la capacité limite de concurrence a été atteinte :
resource "aws_cloudwatch_metric_alarm" "lambda_throttles_alarm" {
for_each = local.lambdas_name
# descriptors
alarm_name = "${local.prefix}-${each.key}-throttle-alarm"
alarm_description = "Alert staff when throttle occurs on a cloud-monitor project's lambda."
# operation relative to the alarm’s threshold
comparison_operator = "GreaterThanOrEqualToThreshold"
threshold = 1
evaluation_periods = 1
alarm_actions = [data.aws_sns_topic.cloudmon.arn]
# metric from which the data come from
namespace = "AWS/Lambda"
metric_name = "Throttles"
dimensions = {
FunctionName = aws_lambda_function.crud[each.key].function_name
}
statistic = "Sum"
period = 300
}
L’alarme peut, classiquement, déclencher une action lorsque un état est atteint. Il y a trois états possibles pour une alarme :
- Pas de données
- La valeur mesurée est au-delà du seuil
- La valeur mesurée est en dessous du seuil
Cela permet de définir plusieurs actions pour une même mesure, par exemple alerter en cas de dépassement de seuil ou de données manquantes, et prévenir d’une rémission.
Insights
Afin de déterminer la source d’une alarme, il est nécessaire d’aller consulter les logs. CloudWatch Insights permet de créer des requêtes pour fouiller et parser les logs stockés dans CloudWatch. On peut faire cela via un langage de requêtage spécifique qui comporte quelques directives comme fields, parse, filter, limit, sort et stats. C’est assez intuitif et plutôt rapide à prendre en main. Le gros bémol est qu’on ne peut pas écrire de requêtes imbriquées ou faire de jointures. Des outils comme Splunk ou Datadog seront bien plus adaptés pour faire de la corrélation et de la recherche dans des logs.
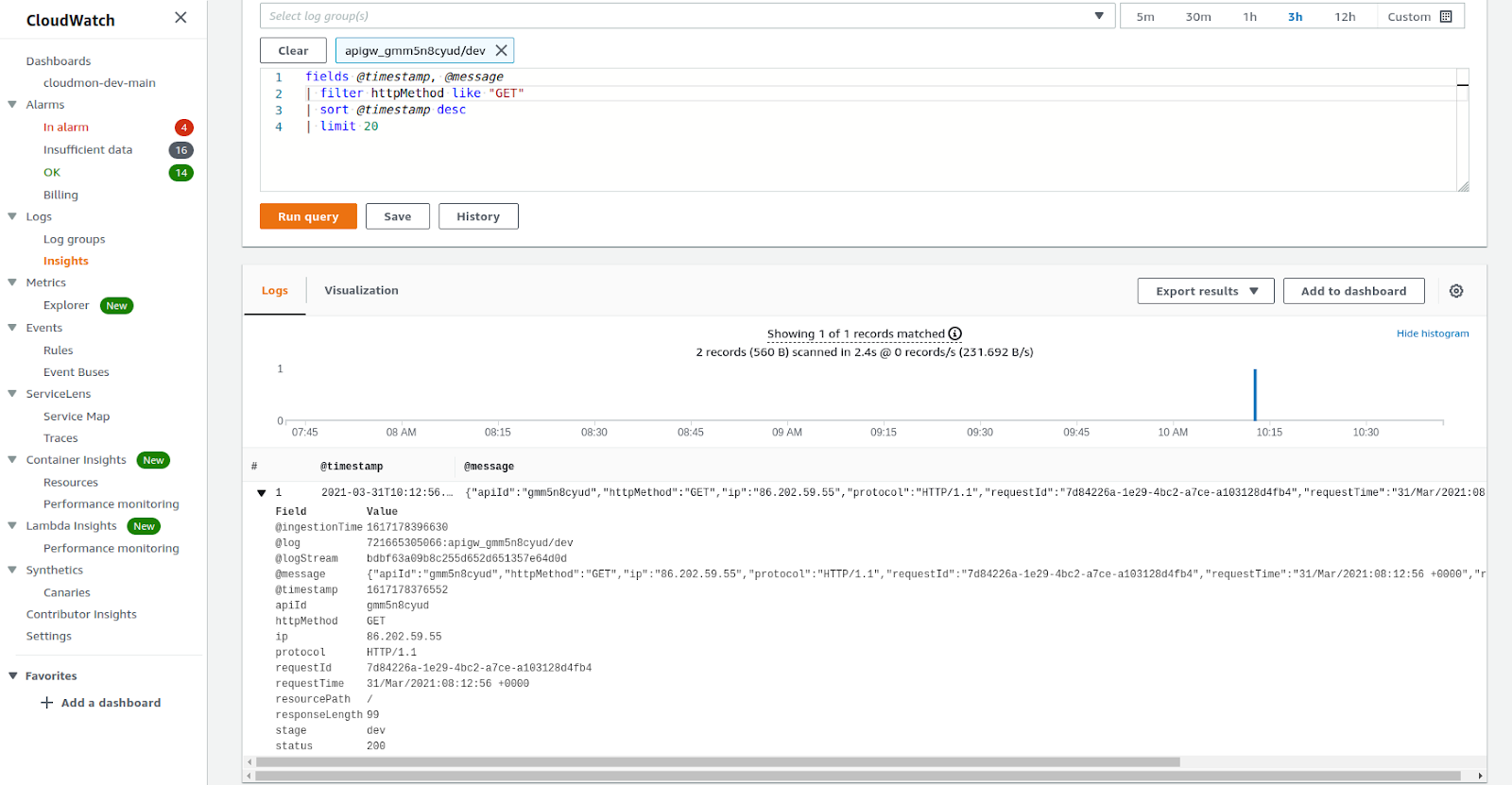
On voit également que les documents JSON contenus dans les logs sont automatiquement parsés.
Métriques personnalisées
Les métriques sont, comme nous l’avons déjà évoqué, la source de l’alerting et des dashboards. Si AWS fournit un bon ensemble de métriques par défaut à propos de la santé des ressources, il n’y en a aucune qui ne soit liée au métier. Pour cela, il faut publier ses propres métriques, processus que je vous propose d’explorer ici.
Imaginons que l’on veuille connaître le nombre de log estampillé “ERROR” grâce à une métrique. Cela permettrait de mettre en place une alarme, et de quantifier cet événement. Il existe plusieurs stratégies pour publier des métriques personnalisées. Je vais vous décrire celle qui me paraît la plus appropriée.
Un Log group peut transmettre les logs reçus à une Lambda via une souscription, si les logs respectent un certain pattern. On va donc abonner une lambda au journal de log de notre application.
resource "aws_cloudwatch_log_subscription_filter" "lambda_function_log_filter" {
name = "${local.prefix}-lambda-function-subscription"
log_group_name = aws_cloudwatch_log_group.app_logs.name
filter_pattern = "ERROR"
destination_arn = aws_lambda_function.publisher_via_logs.arn
}
Il est aussi possible de fouiller les logs avec une Lambda programmée toutes les 1 à 5 minutes.
Grâce à la propriété `filter_pattern` on ne donne à la lambda que les logs contenant le mot “ERROR”. Elle pourra ensuite publier via l’API AWS PutMetricData le nombre de logs reçus au temps courant. Par la suite, on pourra mettre en place des alarmes ou des dashboards rendant compte de la quantité d’erreurs générées par l’application.
const AWS = require('aws-sdk')
const zlib = require('zlib');
const CW = new AWS.CloudWatch()
exports.handler = async function(event,context){
return new Promise((resolve,reject) => {
console.log("Event: "+JSON.stringify(event))
var payload = Buffer.from(event.awslogs.data, 'base64');
zlib.gunzip(payload, function(error, result) {
if (error) {
console.error(JSON.stringify(error, null, 2))
reject(error)
} else {
//début du traitement du log stream fourni
result = JSON.parse(result.toString('ascii'));
console.log("Event Data after decoding: ", JSON.stringify(result, null, 2));
const params = {
Namespace: "App/custom",
MetricData: {
MetricName: 'Number of Applicative Errors',
Dimensions: [
{
Name: 'AppName',
Value: "My App Name"
}
],
Timestamp: Math.floor(Date.now()/1000),
Unit: "Count",
Value: result.logEvents.length
}
};
console.log("PutMetricData parameters : "+JSON.stringify(params))
CW.putMetricData(params).promise()
.then(data=>{
console.log("PutMetricData succeeded :"+JSON.stringify(data))
resolve(data)
})
.catch(err=>{
console.error(err)
reject(err)
});
}
});
})
};
On pourrait également classifier ces erreurs pour différencier celles qui sont critiques et celles qui sont moins graves.
Conclusion
L’observabilité est un sujet important dans la culture DevOps pour comprendre et maîtriser les ressources déployées. Dans un environnement serverless où le développeur n’a pas la main sur l’infrastructure sous-jacente, il est important de connaître et utiliser les services d'observabilité qui permettent de garder la main sur son application.
AWS offre plusieurs services qui permettent d’intégrer l’observabilité à son application. Cloudwatch gère les logs et les métriques, tandis que X-Ray est plus évolué et permet de faire du tracing. Ces services sont très utiles pour collecter des informations pour un minimum de mise en place. Leur intégration avec les services serverless est extrêmement facilité par AWS. Néanmoins, ces services approchent leurs limites lorsque l’on sort du cadre “AWS”. Il est par exemple fastidieux de fouiller les logs ou de faire de la corrélation d’erreur en croisant les données. La facilité de mise en place est contre-balancée par la difficulté d’utiliser ces outils avec des grands volumes de données de monitoring. C’est par conséquent parfait pour des petites applications, des Proof-of-Concept (PoC) ou pour tester. En revanche, pour des applications de plus gros volumes, il peut être intéressant d’étudier la mise en place d’outils dédiés à l’observabilité comme Datadog ou Splunk.
