

Mise en œuvre
Dans la première partie de cet article, nous avons vu ce qu’est une architecture event-driven et en quoi Kafka peut être utilisé pour faire transiter et exposer les événements.
Dans cette partie nous aborderons quelques points importants à considérer pour la mise en œuvre de flux d’événements.
Deux enjeux me semblent importants à considérer au lancement d’une architecture event-driven :
- Fiabilité : tous les événements produits dans le cadre de flux critiques doivent être traités
- Adoption : le socle et les outils mis en place dans le cadre d’un premier cas d’usage doivent faciliter l’adoption de l’architecture par d’autres équipes, pour permettre son extension / sa généralisation
Fiabilité / At-least-once delivery
Dans une approche event-driven, tous les événements doivent être acheminés et traités, sous peine de désynchroniser l’état du service producteur et du/des service(s) consommateur(s) de l’événement.
Une garantie “At-least-once-delivery” (“délivré au moins une fois” en français) doit donc être mise en œuvre pour s’assurer :
- Qu’un événement ne puisse pas être perdu une fois émis
- Que chaque événement soit bien traité
- Qu’un événement ne soit traité qu’une seule fois même si émis plusieurs fois
Durabilité des événements
Pour garantir la durabilité des données qui transitent via Kafka, il faut instancier plusieurs nœuds serveur appelés communément “brokers” et y dupliquer les données des topics. Cela est possible grâce au mécanisme de réplication interne du cluster Kafka. Ainsi, il sera possible de perdre un à plusieurs brokers selon la configuration, sans que les données ne soient perdues.
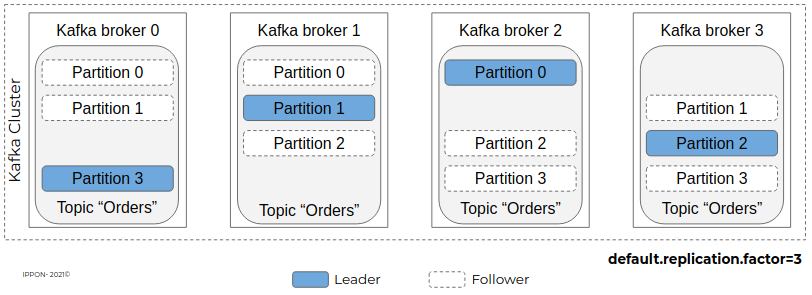
Dans l’exemple ci-dessous, on dispose d’un cluster de 4 brokers Kafka, avec un facteur de réplication de 3 pour le topic “orders”, qui compte 4 partitions :
- Chaque nœud est “leader” d’une partition (équitablement réparties entre les nœuds du cluster)
- Chaque partition est répliquée sur 2 nœuds (présente 3 fois au total donc) grâce au paramétrage “default.replication.factor=3” qui peut être défini topic par topic et qui vaut 1 par défaut (pas de réplication).
Pour que cette réplication soit effective à tout moment et éviter la perte de message, notamment lors de la production d’un événement, il faut que le broker n’acquitte l’écriture qu’après avoir procédé à la réplication.
Pour cela il faut configurer le topic avec le paramètre “min.insync.replicas” pour définir le nombre minimal de réplicas à maintenir en synchronisation à 2, et l’application productrice avec le paramètre “request.required.acks” à all.
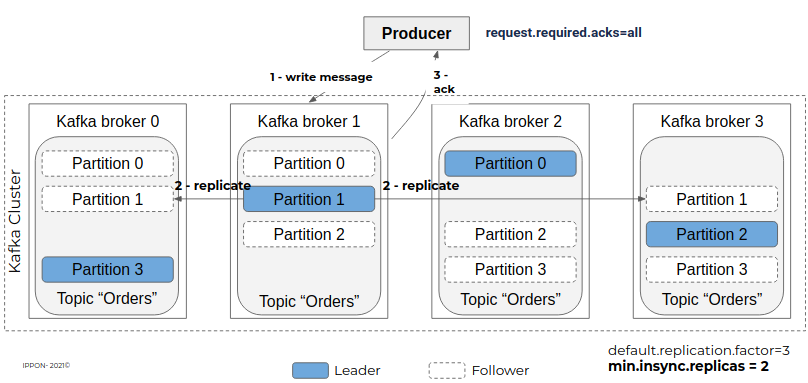
Grâce à ces paramétrages, si le broker 3 devient indisponible par exemple, les données des partitions 1, 2 et 3 ne sont pas perdues car répliquées sur les autres nœuds.
Un autre nœud sera alors élu leader pour la partition 2 (ici broker 1 ou 2 par exemple), et les partitions 1 et 3 seront répliquées sur un autre nœud.
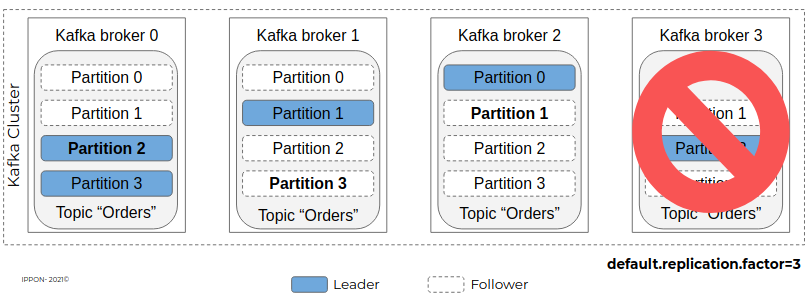
Si un autre broker vient à être indisponible, le topic devient alors read-only car le nombre de nœuds est insuffisant pour héberger 3 réplicas de ses partitions.
Garantir le traitement des événements
Les applications qui consomment les événements publiés sur un topic sont responsables de communiquer leur avancement au broker. Elles déclenchent pour cela une opération de “commit” auprès du broker en indiquant le dernier offset lu. Celui-ci va alors le stocker dans un topic technique “__consumer_offsets” qui va centraliser l’avancement de l’ensemble des consommateurs de ce broker.
Par défaut, le client Kafka embarqué dans les consommateurs va réaliser un “commit” périodique (autocommit) sans s’assurer que les messages consommés n’aient été réellement traités.
Dans le cadre d’une architecture event-driven, chaque message doit être traité sous peine de désynchroniser l’état du producteur et du consommateur de l’événement.
Pour garantir le traitement de chaque événement, les applications consommatrices d’événement doivent donc :
- désactiver l’autocommit : enable.auto.commit=false
- réaliser un commit explicite en fin de traitement
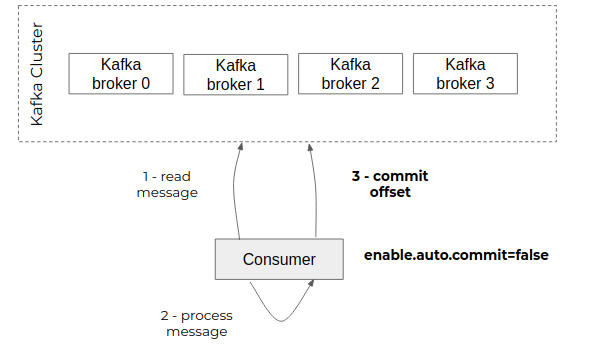
Ainsi on a la garantie que chaque événement qui a fait l’objet d’un commit a bien été pris en compte par le consommateur et en particulier que les données nécessaires ont bien été enregistrées côté consommateur.
Idempotence
Grâce à la réplication interne et au commit manuel, on s’assure qu’un événement sera bien transmis de l’application productrice à l’application consommatrice et traité par cette dernière.
Toutefois, et comme l’évoque le titre de cette partie (“at-least-once delivery”), il se peut que certains événements soient réceptionnés en double.
Exemple 1 (doublon technique) :
- Un consommateur traite une série d’événements
- Celui-ci plante alors brutalement après le traitement d’un événement E mais avant le commit de ce dernier
- Kafka va alors détecter que le consommateur ne répond plus et effectuer un rebalancing des partitions entre les consommateurs restants
- Le consommateur qui reprend la partition contenant E va alors de nouveau le consommer, bien que ses données soient enregistrées en base de données
Exemple 2 (doublon fonctionnel) :
- Un producteur produit un événement E1 avec une clé C1 correspondant à son identifiant métier
- Un consommateur va consommer E1 et persister ses données
- Le même producteur produit un événement E2 avec un identifiant technique différent mais avec la même clé C1 (à cause d’une implémentation fragile : par manque de contrôle avant émission, ou pour des raisons d’accès concurrents à une même entité…)
- Le consommateur va consommer E2
De ce fait, il est nécessaire que le traitement d’un événement soit implémenté de manière idempotente, c'est-à-dire de façon à ce qu’une deuxième occurrence de l’événement n’ait pas d’effet sur les données du consommateur.
Dans l’exemple ci-dessous, le traitement implémente deux niveaux de contrôle :
- Dédoublonnage technique basé sur l’identifiant technique du message (via l’identifiant technique de l’événement, transmis via un header)
- Dédoublonnage fonctionnel basé sur la clé fonctionnelle du message (via la clé de l’événement, portant les informations nécessaires)
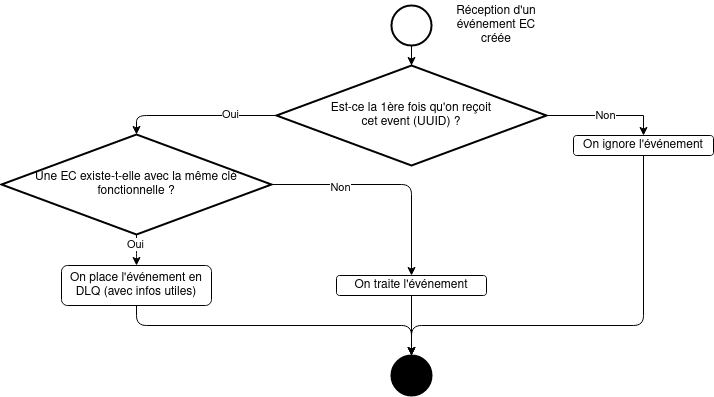
Le premier niveau peut par exemple être implémenté en stockant la liste des derniers événements reçus en base de données et le second en vérifiant l’unicité de la clé, en s’appuyant par exemple sur une contrainte de clé unique sur la base de données.
Dans le cas d’un doublon technique, il suffit d’ignorer l’événement et réaliser un commit.
Dans le cas d’un doublon fonctionnel, celui-ci devra être placé dans une Dead Letter Queue, ou plus précisément Dead Letter Topic, qui contiendra les événements qui n’ont pu être traités, pour analyse manuelle. Sauf erreur d’implémentation, aucun événement ne devrait se trouver dans ce topic. Dans le cas contraire, il faudra corriger la cause du problème et consommer de nouveau ces événements ou corriger manuellement la désynchronisation des données entre producteur et consommateur.
Faciliter l’adoption
Qu’un système soit construit de base avec une approche event-driven ou qu’il soit adapté pour embrasser cette approche, il est important que les nouveaux flux puissent facilement être intégrés, notamment en automatisant les déploiements et en préparant la gouvernance du format des messages
Format des événements
Sérialisation / Déserialisation
Pour des raisons de performance et de volume de données, les messages transitent en binaire dans Kafka. Les événements (clé d’une part et valeur d’autre part) doivent donc être :
- Sérialisés lors de leur production
- Désérialisés lors de leur consommation
Kafka fournit un certain nombre de Serializers et Deserializers pour les types courants (String, Long, …). Pour les contenus plus complexes / composites, il faut recourir à des librairies de sérialisation comme Avro / Protobuf ou JSON Schema.
Apache Avro présente plusieurs avantages parmi lesquels :
- Format binaire très compact
- Très bien intégré dans l'écosystème Kafka / l’outillage
- Possible de générer des objets (Java par exemple) pour manipuler les événements dans le code applicatif
- Permet de contrôler la compatibilité lors de l’évolution du format d’un événement
- Le schéma peut être historisé en gestion de configuration
Schema registry
Le schéma registry est un composant qui permet d’héberger de manière centralisée le schéma des événements qui transitent dans le système et ainsi assurer que les producteurs et consommateurs d’événements utilisent un format d’échange commun.
Il permet également de contrôler les changements apportés à un schéma, en garantissant la compatibilité ascendante ou descendante selon qu’on souhaite mettre à jour d’abord les applications productrices ou consommatrices de l’événement associé.
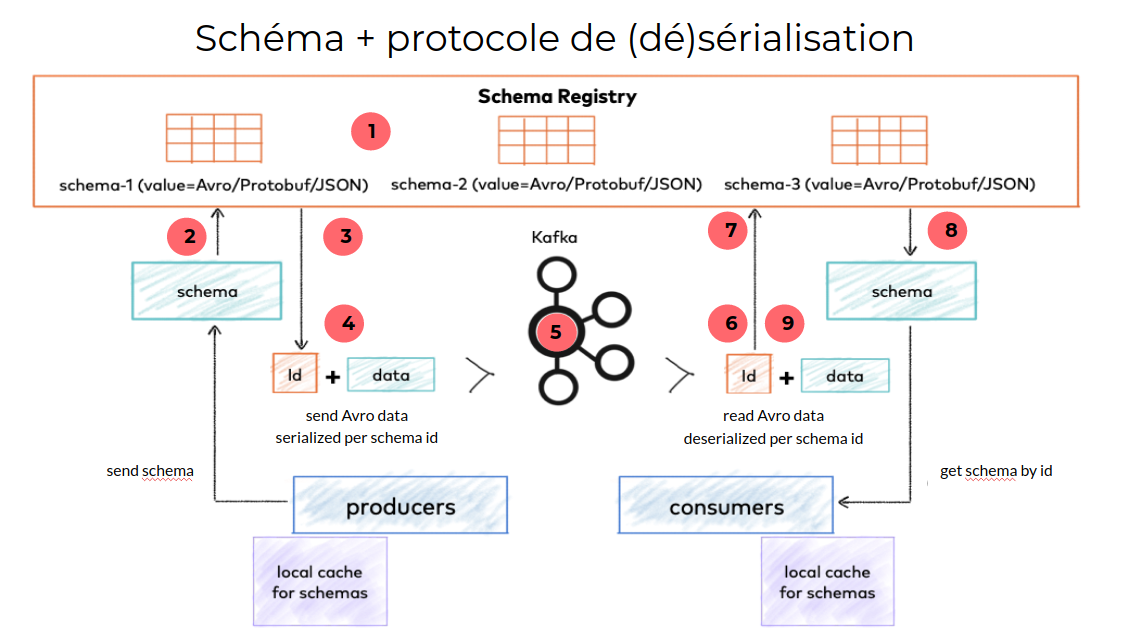
- Publication des schémas en amont via CI/CD
- Le producteur envoie le schéma de l’événement qu’il souhaite publier au registry pour vérifier la compatibilité avec le schéma actuel et récupérer son identifiant
- Le schema registry renvoie l’identifiant du schéma
- Le producteur sérialise la donnée en binaire et ajoute l’identifiant du schéma au début de l’événement
- L’événement est envoyé sur le topic kafka
- Le consumer extrait l’identifiant du schéma à partir de l’événement
- Le consumer envoie l’identifiant du schéma au schema registry
- Le schema registry renvoie le schéma associé
- Le consumer peut désérialiser la donnée binaire en un objet Java
Pour éviter de solliciter le schema registry à chaque publication / consommation d’événement, les producteurs et consommateurs conservent les données utiles en cache.
Déploiement automatisé
Schémas
Par défaut, les clients Kafka sont configurés pour publier automatiquement le schéma lors de la production d’un événement (auto.register.schemas=true).
En production, il est recommandé de publier les schémas en amont, via une CI/CD après les avoir créés ou modifiés. Le schéma registry vérifie alors la compatibilité des changements avec la stratégie définie pour le sujet associé (exemple : avec une compatibilité BACKWARD visant à mettre à jour les consommateurs avant les producteurs d’un événement, seules les suppressions de champs ou les ajouts de champs optionnels sont autorisés, ce qui permet au producteur de continuer à fonctionner avec l’ancienne version du schéma).
Pour éviter la lourdeur de syntaxe des schémas Avro, il est possible d’utiliser le format IDL Protocol qui est plus condensé et permet de générer des schémas Avro. Chaque événement peut alors être stocké individuellement en gestion de configuration sous sa version IDL.
Exemple de pipeline de déploiement :
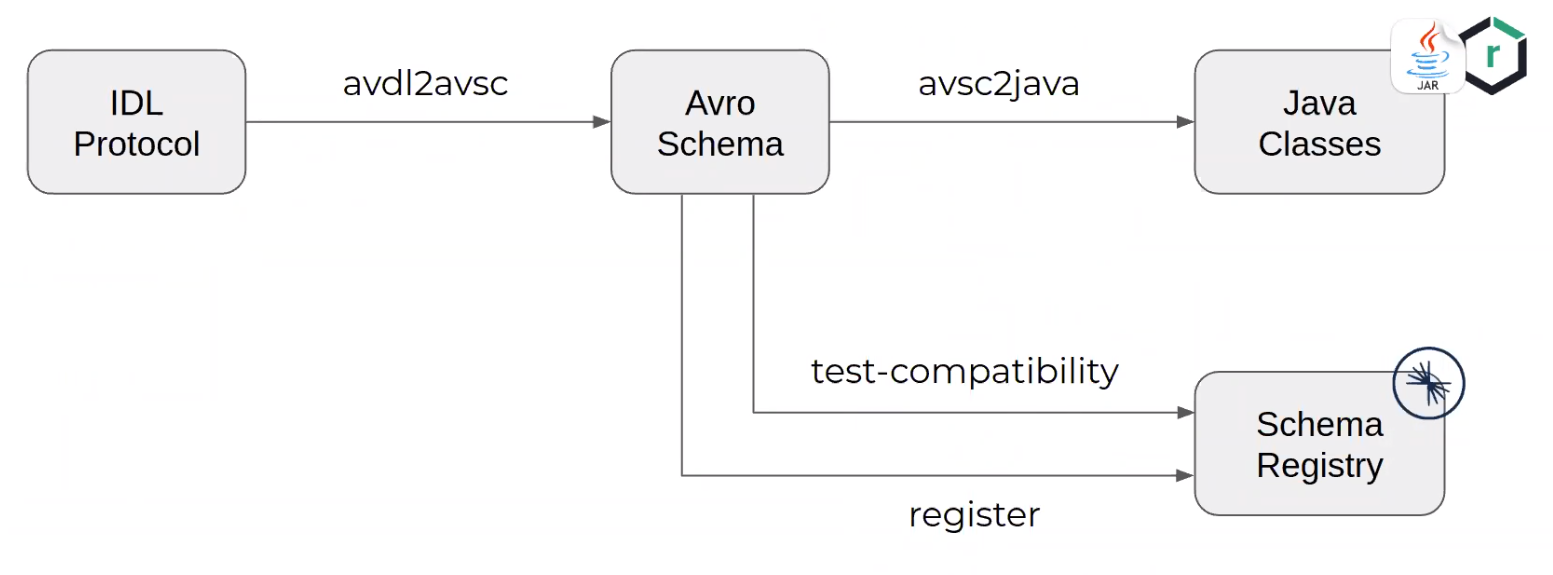
avdl2avsc : utilise la commande “idl2schema” de l’utilitaire “org.apache.avro:avro-tools”
avsc2java : génère les sources via le goal “schema” du plugin “avro-maven-plugin”
test-compatibility : utilise le goal “test-compatibility” du plugin kafka-schema-registry-maven-plugin
register : utilise le goal “register” du plugin kafka-schema-registry-maven-plugin
Les applications peuvent alors déclarer une dépendance vers le ou les événements qu’ils produisent ou consomment via Maven par exemple.
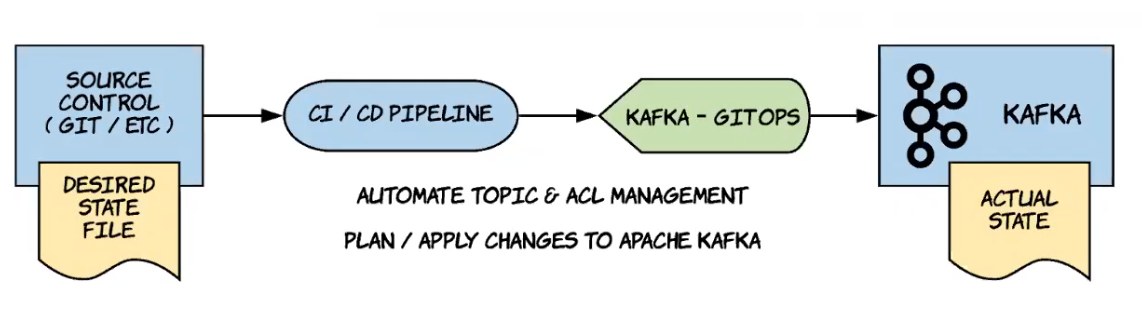
Topics et ACLs
Les topics et ACLs peuvent être déployés au moyen de Kafka Gitops, produit Open Source disponible ici : https://github.com/devshawn/kafka-gitops.
Kafka Gitops permet de définir un état désiré via des fichiers Yaml :
- Topics et paramétrages associés
- Services utilisant les topics et comptes associés
Il fournit une CLI qui permet d’appliquer les changements par rapport à un état précédent.
Conclusion
Les éléments exposés dans cette partie permettent de répondre aux principaux enjeux de mise en œuvre d’une architecture event-driven avec Kafka.
L’acheminement et le traitement des événements est garanti par la multiplication des brokers et le paramétrage ‘at-least-once-delivery’ de Kafka. Il faut également se prémunir de l’occurrence d’événements en doublons qui se produiront fatalement de par la nature distribuée du système. Cela permet de garantir qu’un événement qui se produit dans le système est toujours pris en compte par les composants qui s’y abonnent et d’offrir le même niveau de fiabilité qu’avec des échanges synchrones.
Par ailleurs, les applications composant le système doivent parler un même langage, qui doit pouvoir évoluer au cours du temps. Nous avons vu ici que le schema registry est un bon moyen d’y parvenir en centralisant le format de tous les événements et en permettant de tester la compatibilité à la production d’événement ainsi qu’à la publication de la nouvelle version d’un événement.
Enfin, pour faciliter la maintenance et la construction de nouveaux flux événementiels, il est nécessaire d’industrialiser le déploiement des différents artefacts permettant de faire fonctionner l’architecture événementielle (topics, schémas, ACLs…). Cela permet de faciliter la vie des équipes qui seront amenées à construire d’autres flux sur le socle technique Kafka et de faciliter la généralisation de l’architecture event-driven sur le système.
