

Une architecture orientée événements (en anglais : event-driven architecture) est un paradigme de plus en plus utilisé dans les architectures modernes à base de microservices, qui promet une application plus réactive aux événements métier tout en offrant un meilleur découplage technique.
Séduisant ! Mais comment bien démarrer ?
Dans cet article en 2 parties, je vous propose de passer en revue les éléments importants à considérer pour démarrer la mise en place d’une architecture orientée événements avec Kafka.
Architecture event-driven et Kafka
Dans cette première partie, je tenterai de définir ce qu’est une architecture event-driven et comment Kafka peut être utilisé pour construire ce type d’architecture.
Architecture event-driven
Pour définir ce qu’est une architecture event-driven, revenons d’abord sur les concepts de commande et d’événement.
Commande vs Evénement
Une commande est initiée par un utilisateur ou un composant technique, qui demande à un système de réaliser une action.
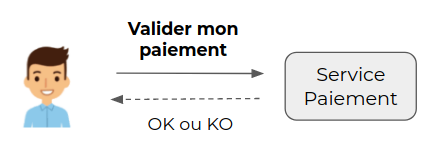
Un événement est initié par le système pour exprimer le fait que quelque chose s’est produit.

La différence fondamentale entre les deux est la suivante :
- Lorsque la commande est lancée, l’action n’est pas encore réalisée et l’état du système n’est pas encore affecté. Elle peut aboutir ou non et on peut la retenter en la modifiant si nécessaire.
- Lorsque l’événement est instancié, l’action est déjà réalisée et l’état du système est déjà affecté. L’événement est donc immuable et devra être traité.
Orchestration vs Chorégraphie
Dans un scénario construit à base de commandes, le service sollicité par la commande initiale pilote l’action des autres services impliqués.
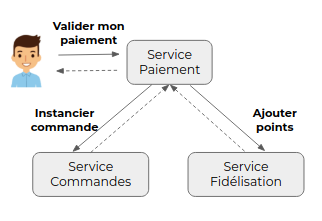
Ici, lorsque le service de paiement va traiter la demande de validation, il va solliciter les autres services pour déclencher les actions qui suivent l’action de validation : par exemple ici l’instanciation de la commande correspondant au paiement et l’ajout de points de fidélité. C’est donc le service de paiement qui orchestre ici le scénario.
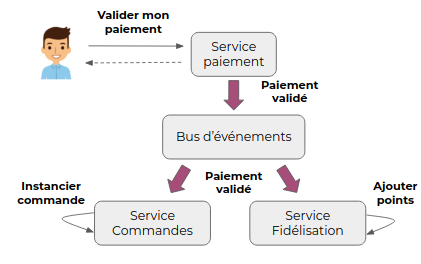
Reprenons le même scénario avec une approche event-driven : une fois que le service de paiement a traité la demande de validation dont il est responsable, il va émettre un événement sur un bus d’événements. Cet événement sera ici consommé par les services de commande et de fidélisation pour déclencher les actions qui suivent la validation d’un paiement.
Ces services agissent de manière indépendante à partir d’un événement ce qui s’apparente ici à une chorégraphie.
Bénéfices
Le premier bénéfice qui apparaît dans l’exemple précédent est le découplage des composants. Le service de paiement réalise le traitement dont il est responsable et avertit qu’il a terminé, sans se soucier des actions qui doivent suivre la validation du paiement. Il peut également répondre à la demande de l’utilisateur même si les services commandes et fidélisation sont indisponibles, ce qui améliore la résilience d’ensemble.
Le second bénéfice est la scalabilité, autrement dit une facilité à multiplier indépendamment les instances des services, en fonction de leur charge de travail. On peut par exemple ajouter N instances du service des commandes si le traitement déclenché par l’événement est long et/ou si la charge globale est importante.
Mais le bénéfice le plus important à mes yeux est l’exposition des événements en temps réel. Il sera facile d’abonner de nouveaux consommateurs aux événements produits sans impact sur les services en place, en particulier le service producteur de l’événement.
Ils pourront également être utilisés pour alimenter des pipelines data ou des outils d’analyse en temps réel, par exemple ici pour analyser les volumes de paiement par tranches horaires.
Challenges à relever
Comme tout choix d’architecture, les bénéfices viennent avec des contreparties. Les challenges principaux à relever dans la mise en place d’une architecture event-driven sont les suivants :
Premièrement, l’état des différents services se retrouve désynchronisé pendant un certain laps de temps, correspondant au délai entre la mise à jour de l’état côté producteur de l’événement et la mise à jour de l’état dans le service consommateur de l’événement. La cohérence entre les services n’est pas immédiate, on parle de cohérence à terme. Il faudra intégrer cet aspect dans la conception des traitements et veiller à ce que le délai de synchronisation ne soit pas trop important, en s’assurant par exemple que la consommation des événements soit plus rapide que leur production.
Deuxièmement, il faudra s’assurer que tous les événements soient acheminés et traités, sans quoi deux services pourraient se trouver définitivement désynchronisés pour certaines entités. Il faudra être vigilant sur le paramétrage du bus d’événements ainsi que des applicatifs producteurs et consommateurs d’événements. Il faudra aussi gérer les erreurs à la consommation des événements, avec des stratégies de rejeu pour les erreurs récupérables (ex : base de données indisponible) et de mise à l’écart pour les erreurs non récupérables (format d’événement incorrect, ou événement non attendu par exemple).
Enfin, pour surveiller les différents problèmes qui pourraient se produire dans l’acheminement et la prise en compte des événements, un monitoring efficace devra être mis en place.
Kafka comme bus d’événements
Apache Kafka est une plateforme d’event streaming distribuée, développée initialement par LinkedIn et open-source depuis 2011.
Elle est utilisée par un très grand nombre d’entreprises pour mettre en place des data pipelines haute performance, permettre l’analyse de données en temps réel ou intégrer les données d’applications critiques.
Pourquoi Kafka ?
Kafka a été construit dès l’origine pour publier et consommer des d’événements en temps réel et ce à grande échelle de par sa nature distribuée.
Les événements qui sont publiés dans Kafka ne sont pas supprimés dès leur consommation, comme dans les solutions orientées messaging (ex : RabbitMQ). Ils sont supprimés après une certaine durée de rétention (voire pas du tout comme dans l’event sourcing). Pendant toute leur durée de vie, ils pourront alors être lus par plusieurs consommateurs différents, répondant ainsi à différents cas d’usage, ce qui correspond bien à ce qu’on souhaite faire dans une approche event-driven.
Kafka vient avec un écosystème d’outils riche, comme Kafka Connect qui permet de capturer les événements d’un système tiers (exemple : base de données, S3…) et de les émettre sur un topic Kafka, ou à l’inverse d’émettre les événements d’un topic Kafka vers un système tiers.
Kafka Streams permet quant à lui de travailler sur les flux d’événements (stream processing) et de constituer de nouveaux flux à partir de ceux existants, ce qui permet de tirer le meilleur parti des données qui transitent, avec une très grande souplesse.
Événement
Un événement dans Kafka est principalement composé :
- d’une clé
- d’une valeur
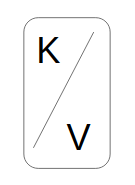
Les deux peuvent être composés d’un champ de type simple (String, Long …) ou d’une structure de données plus complexe.
Ces événements sont écrits dans un flux, d’où le terme “event streaming”. Chaque nouvel événement est ajouté à la fin du flux et les anciens événements ne sont jamais modifiés.

Si les événements concernent une entité (ex : un produit) et que celle-ci change plusieurs fois d’état, plusieurs événements seront produits pour matérialiser les états successifs.
Dans Kafka, ce flux d’événement est implémenté sous la forme d’un commit log.

C’est la notion centrale de Kafka.
Topics
Dans une application, les événements vont concerner plusieurs types d’entités (clics utilisateurs, commandes, clients...).
Pour les isoler les uns des autres et permettre aux consommateurs de ne consommer que ceux qui les intéressent, les événements sont répartis dans des topics.
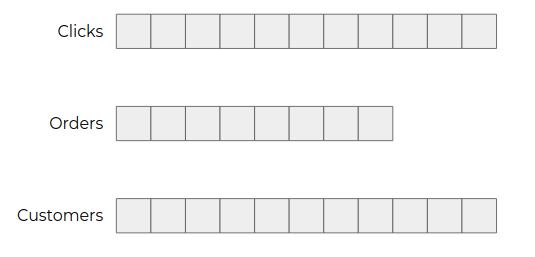
Il s’agit de regrouper ensemble les données similaires, comme on peut le faire avec la notion de tables dans une base de données.
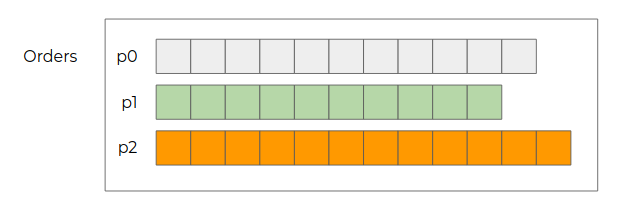
Partitions
Pour permettre la consommation d’un topic par plusieurs instances d’un consommateur, les topics sont découpés en partitions. C’est ce qui va permettre à Kafka de traiter les événements à grande échelle.
Production des événements
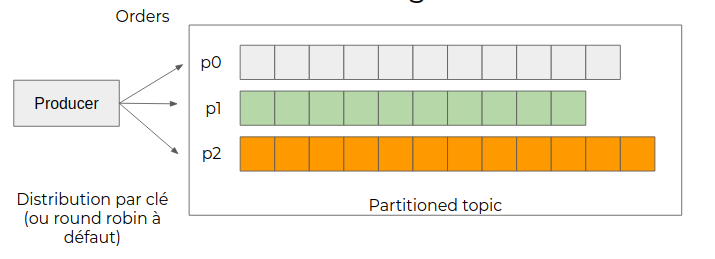
Lorsqu’une application va produire des événements dans un topic, ceux-ci vont être répartis dans les différentes partitions de celui-ci :
- Soit par clé si celle-ci est définie : les événements portant la même clé seront écrits dans la même partition
- À défaut, en répartition homogène (round-robin)
Consommation des événements
Plusieurs consommateurs différents
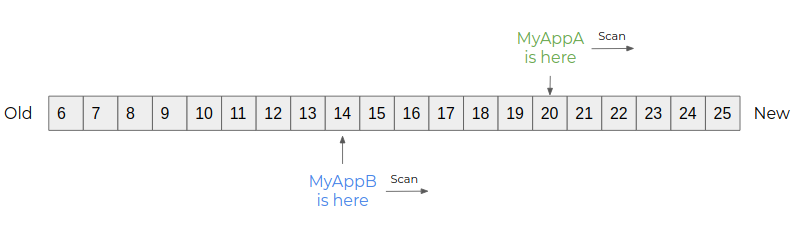
Plusieurs applications différentes vont pouvoir s’abonner à un même topic. Chacune va alors lire l’ensemble des partitions à son rythme. Chaque événement sera alors consommé par MyAppA et MyAppB.
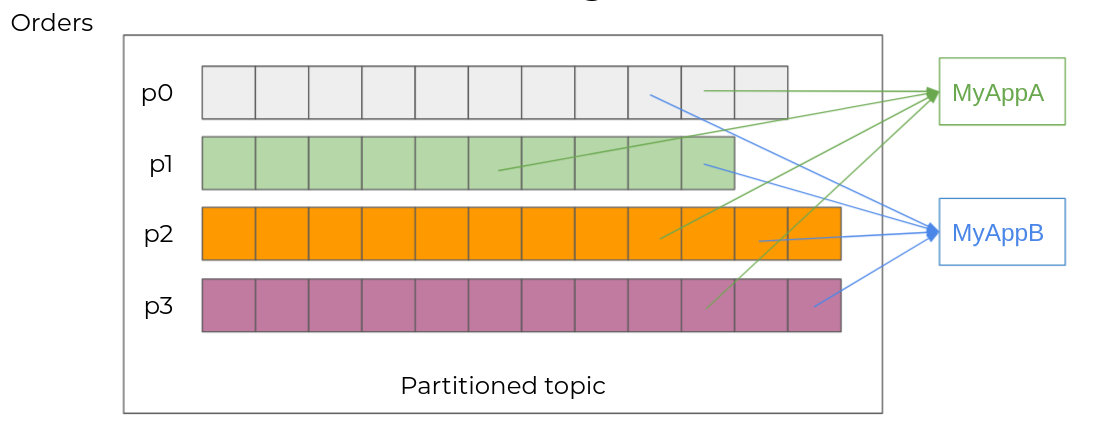
Pour cela, Kafka va associer à chaque événement un numéro unique au sein de sa partition : l’offset. Chaque consommateur va pouvoir consommer le flux d’événements à son rythme, en enregistrant son avancement dans Kafka.
Plusieurs consommateurs identiques
Pour multiplier les capacités de traitement, il est également possible d’ajouter plusieurs instances d’un même consommateur, qui seront alors inscrites dans le même consumer group. Chaque instance consomme alors un sous-ensemble des partitions du topic, réparties équitablement entre les consommateurs.
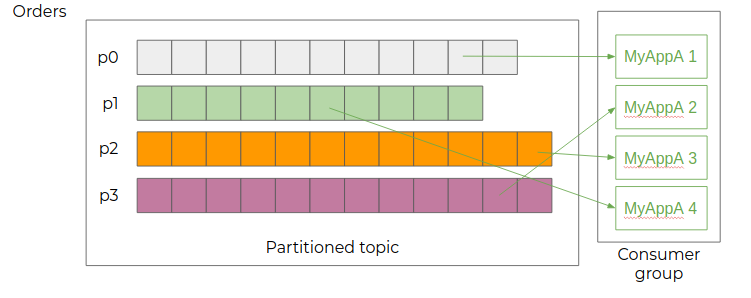
Le nombre d’instances au sein d’un consumer group n’est pas limité, mais s’il dépasse le nombre de partitions du topic consommé, les instances excédentaires n’auront aucune partition assignée.
En utilisant la répartition par clé au niveau de la production on va s’assurer que l’ensemble des événements concernant une même entité (donc avec la même clé) sera traité par la même instance de consommateur. Et comme Kafka garantit l’ordre des événements au sein d’une partition, ils pourront être consommés dans l’ordre de leur émission. C’est particulièrement important pour les événements dont l’ordre importe (ex : commande créée, commande modifiée, commande annulée).
Conclusion
Nous avons vu dans cette partie qu’une architecture event-driven est un changement de paradigme important qui vise à construire un système sur la base des événements qui s’y produisent. Cela permet notamment de construire des services qui réagissent en temps réel à ces événements.
Kafka est particulièrement adapté pour mettre en œuvre ce type d’architecture en permettant d’exposer les événements de manière structurée, et de s’y abonner facilement sans impact sur les applications productrices. Il permet en outre une scalabilité des consommateurs.
Dans la seconde partie de cet article, je détaillerai certains éléments de mise en œuvre pour assurer la transmission des événements de manière fiable et faciliter l’adoption de l’architecture par d’autres équipes.
