

Je sais ce que vous allez vous dire, Big Data sur SQL Server ? Et puis quoi encore ?! Pourtant, comme il y aura toujours des mainframes, il y aura encore longtemps des bases de données SQL Server. Alors voyons dans cet article comment les aider à prendre le virage du Big Data et de l’analytique moderne.
Depuis la version 2019, SQL Server est plus qu’un simple moteur de base de données. C’est une plateforme de données unifiée, qui, grâce à la nouvelle technologie Big Data Clusters, prend en charge l'apprentissage automatique, l'analyse de données, la conteneurisation des applications et son orchestration via Kubernetes et la virtualisation des données avec Azure.
Big Data Clusters (BDC) est une implémentation en grappes multiples de SQL Server orchestrée par Kubernetes, intégrant le framework de calcul distribué Apache Spark, le gestionnaire de clusters Hadoop YARN, le système de fichiers distribué de Hadoop [HDFS], Apache Hive, Apache Knox, Apache Ranger et Apache Livy ; pour proposer une plateforme unique qui peut prendre en charge le traitement des transactions en ligne OLTP, les données non structurées et même les besoins en Machine Learning.
Architecture
Le Big Data Cluster est un cluster de conteneurs Docker orchestré par Kubernetes. C’est un ensemble de nœuds (machines virtuelles ou physiques) composés d’une instance SQL Server, une instance Spark et HDFS. Chaque nœud exécute un ou plusieurs pods avec un composant kubelet pour assurer le démarrage, l'arrêt et la maintenance des pods et un composant kube proxy pour gérer les opérations réseau et le routage du trafic vers les différents conteneurs.
Un pod est l’unité de déploiement atomique de Kubernetes. Un pod regroupe, sous forme logique, un ou plusieurs conteneurs ainsi que les ressources associées nécessaires pour exécuter une application. Chaque pod s’exécute sur un nœud ; un nœud peut exécuter un ou plusieurs pods. Le master Kubernetes attribue automatiquement des pods aux nœuds du cluster.
De quoi se compose un Big Data Cluster ?
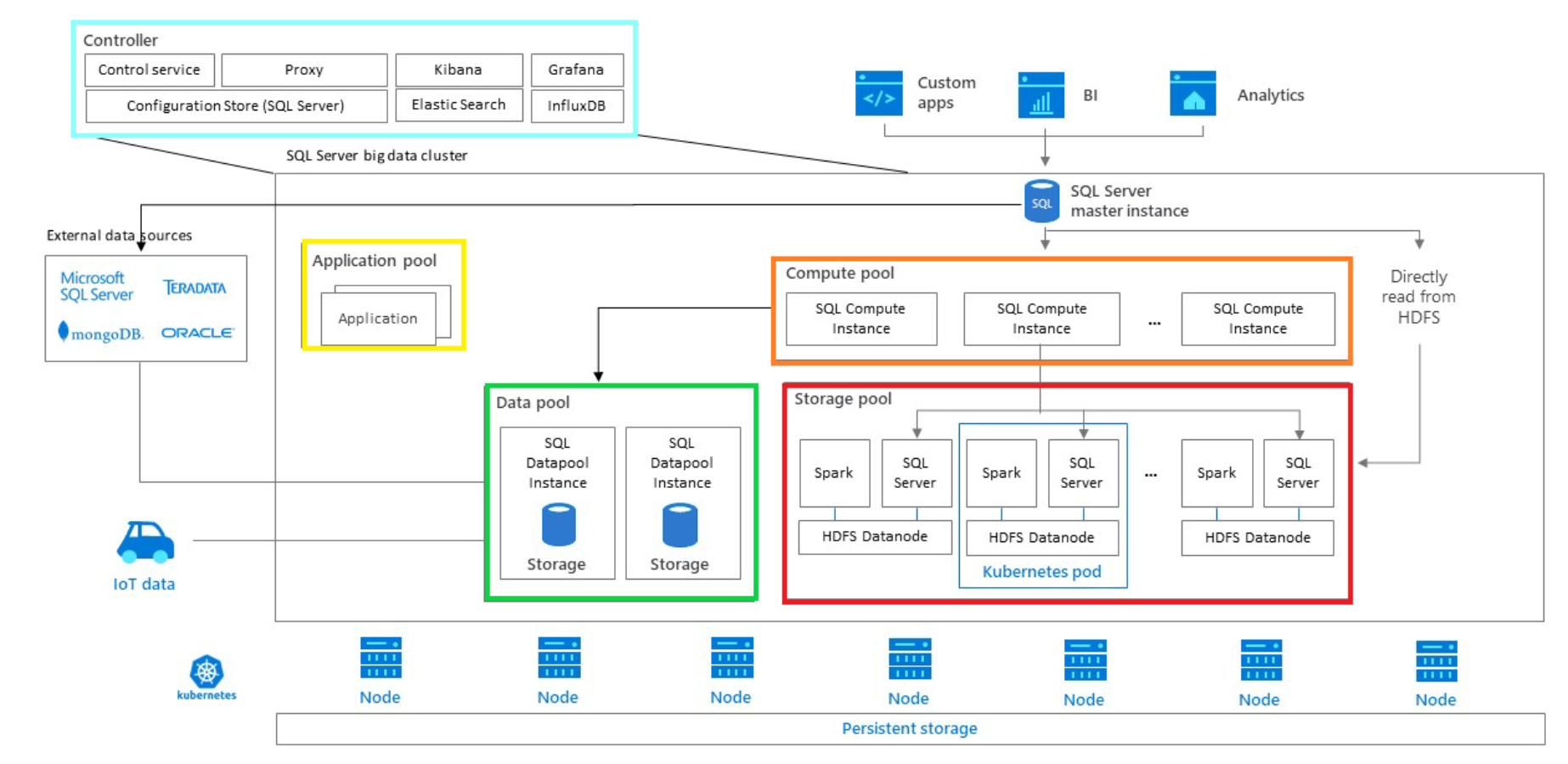
Un Big Data Cluster se compose d’un Contrôleur (Controler), d’une Instance SQL Server Master (SQL Server master instance) et de 4 pools, Le pool de calcul (Compute pool), Le pool de stockage (Storage pool), le pool de données (Data pool) et le pool d’application (App pool).
-
Dans le contrôleur, on trouve Kubernetes master node qui se charge de la gestion et du contrôle des services suivants : le cluster Kubernetes, la base de données distribuée pour le stockage des métadonnées Spark Apache Hive, la passerelle d’authentification Apache Knox, le framework de sécurité Apache Ranger, le planificateur de tâches Apache Livy et d’autres services tels que Kibana et ElasticSearch pour la visualisation et la recherche de logs, ou encore Grafana pour des dashboards de monitoring de la performance des services du cluster.
Ce composant contient aussi le service de contrôle qui permet d’observer l’état du cluster et la gestion des pools et de la sécurité. Le service de contrôle peut être accessible via Azdata utility (Azure Data CLI) ou Azure Data Studio Tool.
-
SQL Server master instance est une exécution de SQL Server 2019 dans un pod sur un noeud du cluster Kubernetes, cette instance contient un moteur de requête avec scale-out, utilisé pour distribuer les requêtes entre les instances SQL Server du pool de calcul et une base de données pour stocker les métadonnées des tables HDFS. Cette instance fournit également un point de terminaison TDS accessible depuis l’extérieur pour le cluster.
-
Le pool de données constitue le datamart scale-out des clusters Big Data, c’est un caching layer pour faire des analyses de données. Le pool est constitué d’une ou plusieurs instances de SQL Server où on ingère les données à partir de requêtes SQL ou de jobs Spark. Il permet d'interroger des données mises en cache, ce qui nous permet d’éviter une connexion aux datasources d’origine (très utile quand on a des données qui proviennent de plusieurs sources Polybase ou si on a besoin d’une actualisation périodique des données).
-
Le pool de stockage est un ensemble de nœuds de stockage qui font partie d’un cluster HDFS géré par YARN avec un namenode qui contient les métadonnées et des datanodes sur lesquels les données sont réparties et dupliquées pour le traitement parallèle et la tolérance aux pannes.
Chaque nœud contient un ou plusieurs pods. et chaque pod contient, un conteneur Hadoop avec du YARN qui peut lancer des jobs Spark et une instance SQL Server pour lire les données à partir de HDFS. -
Le pool de calcul s’occupe du calcul distribué avec des instances SQL Server sous la direction du SQL Server master instance. Le pool fournit un Groupe Polybase scale-out entièrement configuré, ce qui permet une utilisation facile et simple de ce dernier.
-
Le pool d’applications est un ensemble de pods qui contiennent plusieurs types de points de terminaison dans le système. Ce pool permet de déployer des applications SSIS (SQL Server integration services) et ML Server (Machine Learning Server) avec du R, Python et MLeap. Les applications déployées sur BDC bénéficient de nombreux avantages, tels que la puissance de calcul du cluster, et la possibilité d'accéder à des données disponibles sur le cluster, ce qui permet d'augmenter les performances des applications, car elles se trouvent dans la même zone que les données.
Comment peut-on déployer un cluster Big Data ?
Le Big Data Cluster est facile et rapide à déployer, il peut être déployé sur n'importe quel cluster K8s on-premises en utilisant Kubeadm et [kubectl] directement sur une machine Linux, ou dans le Cloud Azure en utilisant Azure Kubernetes Service (AKS) ou Azure Red Hat OpenShift (ARO).
Le service de contrôle peut être accessible via Azdata (Azure Data CLI) et Azure Data Studio pour la gestion, le déploiement et la configuration des pods du BDC.
Azure Data Studio est un outil de base de données multiplateforme pour les professionnels des données qui utilisent des plateformes de données locales et Cloud. Il dispose des fonctionnalités IntelliSense, des extraits de code, l’intégration du contrôle de code source et un terminal intégré. Il est conçu en tenant compte de l’utilisateur de la plateforme de données, avec l’intégration de la représentation graphique des jeux de résultats de requête et des tableaux de bord personnalisables.
Azure Data CLI (azdata) est un utilitaire en ligne de commande écrit en Python qui permet de démarrer et de gérer les services de données via des API REST.
On peut installer une instance de SQL Server 2019 sur une machine locale, en suivant les étapes d’installation comme pour les versions antérieures de SQL Server.
Nouvelles fonctions SQL Server 2019 à ne pas manquer !
Virtualisation des données
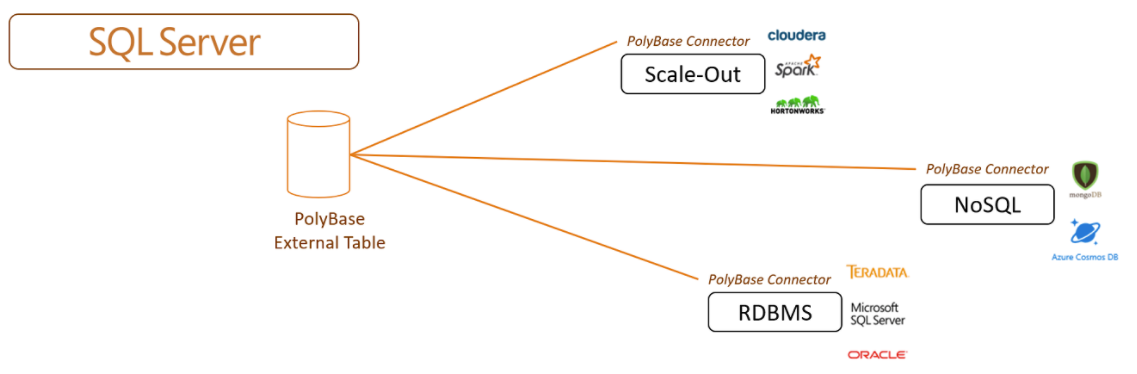
Grâce à l’option Polybase, SQL Server peut lire des données dans des sources externes. Polybase existe dans SQL Server depuis la version 2016. Elle permet d’accéder à des données externes dans Hadoop et dans Azure Blob Storage.Dans la version 2019, de nouveaux connecteurs ont été ajoutés pour Oracle, Teradata, Mongodb, Cloudbased database, Azure SQL Data Warehouse, Azure SQL Database et Cosmosdb.
Comme les Big Data Clusters disposent d’un pool de stockage HDFS, cela permet de stocker les données intégrées des différentes sources de données externes et les combiner facilement quel que soit le type ou le format (base relationnelle, non relationnelle, filesystem, structurées, non-structurées) ce qui fait de SQL Server 2019 un véritable Data Lake.
Traitement intelligent des requêtes
SQL Server 2019 a mis en place un processeur de requête intelligent qui crée automatiquement un plan d’exécution qui s’adapte aux données et apprend de ses exécutions déjà réalisées. Il est capable, automatiquement, d’allouer plus de ressources pendant le traitement au fur et à mesure que les requêtes sont traitées.
Cette version introduit également l’infrastructure légère de profil de statistiques d’exécution de requête (The lightweight query execution statistics profiling infrastructure), qui a été activée par défaut dans SQL Server 2019. Cette fonctionnalité permet de fournir des informations sur les performances à tout moment et en tout lieu pour les requêtes actives sur un serveur en cours d'exécution. L’option existe dans les versions précédentes de SQL Server, mais nécessite l'activation des indicateurs de trace et entraîne également des frais supplémentaires.
Evolutions SQL Server Analysis services
SQL Server Analysis Services est un moteur OLAP (Online Analytical Processing) d’exploration de données pour les applications décisionnelles, qui intègre également des fonctionnalités de Datamining et est chargé d’effectuer les tâches de traitement des cubes (calculs des agrégations) et de répondre aux requêtes de consultation des données.
SSAS 2019 a ajouté une option pour mettre en facteurs les indicateurs redondants : les groupes de calcul dans les modèles tabulaires.
Exemple : On veut faire une analyse des recrutements chez Ippon par mois à jour (MTD), trimestre à ce jour (Taj), année à jour (CÀJ), commandes année à jour pour l’année précédente (PY). Au lieu de créer une mesure pour chaque calcul (colonne par mesure) on va créer un groupe de calculs sous forme de table avec une seule colonne qui regroupe tous les calculs.
Cette version introduit également les relations many-to-many dans les relations tabulaires, ce qui permet de relier une table qui porte une clé étrangère à une table qui n’a pas comme clé primaire la colonne sur laquelle se base la relation.
Evolutions SQL Server Reporting Services
SQL Server Reporting Services est un ensemble d’outils et services prêts à l’emploi pour créer, déployer et gérer des rapports BI.
SSARS 2019 supporte les bases de données managées Azure SQL database et prend en charge des datasets PowerBI premium comme source de données en utilisant le connecteur Microsoft SSAS.
Amélioration des processus d’indexation
Un index est une structure de données qui permet d'améliorer la performance des requêtes SQL. Une opération d'indexation peut des fois consommer beaucoup de ressources et perturber le fonctionnement de la base de données, si cela arrive dans SQL Server 2019, l'opération d'indexation peut être interrompue puis reprise aux heures creuses. Et si jamais un processus d'indexation a échoué, le processus peut être repris sans avoir à tout recommencer, chose qui n'existait pas dans les versions précédentes.
Pour les amoureux du Java
En plus du Python et R, la version 2019 de SQL Server propose d'utiliser du code Java dans le système de gestion de base de données et supporte les UDFs (User Defined Functions).
Conclusion
SQL Server n’est pas la seule technologie Microsoft à intégrer Apache Spark, qui est au cœur de Azure Databricks et Azure HDInsight. Sa particularité est de pouvoir combiner et analyser facilement des données relationnelles avec des données non structurées. Ceci en fait un outil particulièrement adapté pour les utilisateurs fidèles de SQL Server qui veulent intégrer une variété de données et les analyser sans avoir à changer toute l’architecture de leurs bases de données relationnelles.
SQL Server 2019 va leur permettre de gagner du temps grâce à la virtualisation des données via Polybase, optimiser les performances avec du calcul distribué dans le Big Data Cluster et réduire les coûts en utilisant une seule plateforme unifiée, facile à mettre en place et à maintenir pour tout type de traitement.
Aujourd’hui, les outils Data sont obligés de suivre l’évolution technologique qui repose sur le calcul distribué et les solutions Cloud. Ils ont deux choix, soit prendre la vague “big data & cloud computing” ou se noyer. Personnellement, je pense que SQL Server a fait un take-off très réussi.