
Valohai est une plateforme de gestion du cycle de vie des modèles prédictifs pour la construction de systèmes d'apprentissage automatique. Valohai régit les modèles statistiques depuis la naissance (pré-traitement + entraînement + déploiement) jusqu'à la production.
Cette plateforme permet de construire un système de Machine Learning de la façon la plus automatique possible. Un système de Machine Learning se base principalement sur trois briques :
- Extraire des features des données,
- Envoyer ces features à des modèles de prédiction,
- Utiliser les résultats des modèles pour générer des prédictions.
Vous pouvez utiliser Valohai pour construire la plupart des composants nécessaires pour réussir un workflow ML. Voici une liste non exhaustive de ce que vous pouvez faire :
- Transformation de données,
- Data augmentation,
- Anonymisation des données,
- Gestion de données,
- Du développement itérative,
- Entraînement des modèles,
- Optimisation des hyperparamètres,
- Gestion des modèles,
- Analyse des modèles,
- Interprétabilité des modèles,
- Expérimentation en ligne,
- etc.
Steps
Chacun des composants cités au-dessus peut consister à une étape dans un workflow Valohai. Pour créer une étape “Step”, il faut créer une exécution.
Les exécutions sont contrôlées par version, donc la réexécution de toutes les charges de travail antérieures fonctionnera tant que l'image Docker et les inputs existent toujours. Comme vous pouvez le voir sur la figure ci-dessous, un exemple d’exécution avec une simple étape “Step” d'entraînement.
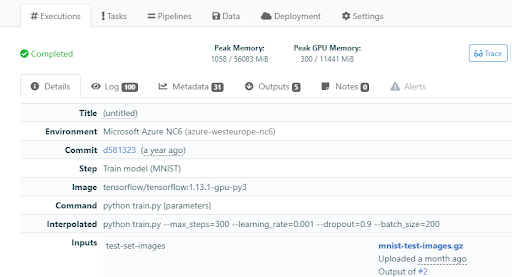
Les projets d'apprentissage automatique étant très différents les uns des autres, les utilisateurs sont autorisés à être aussi flexibles que possible dans la création de leurs propres pipelines de Machine Learning.
Des étapes distinctes sont généralement définies pour :
- Prétraiter les fichiers et les télécharger pour être utilisés par d’autres étapes,
- S’intégrer aux services de base de données pour créer un snapshot contrôlé par version pour les données d'entraînement,
- Exécuter un script Python ou un code C, par exemple pour entraîner un modèle de prédiction,
- Valider si un modèle d'entraînement peut être utilisé pour la prédiction,
- Déployer un modèle entrainé du staging à la production,
- Créer des fichiers binaires d’application à utiliser dans d’autres étapes.
Exécutions
Les workloads du Machine Learning sont encapsulés dans des entités appelées exécutions. Une exécution est un concept similaire à “un job” ou bien “une expérience” dans d’autres systèmes, l’accent étant mis sur le fait qu’une exécution est une pièce plus petite, dans un processus de Data Science ou de Machine Learning beaucoup plus vaste.
En termes simples, une exécution est une ou plusieurs commandes strictement définies, exécutées sur un serveur distant.
L’exécution d’une étape crée une exécution ; on peut dire que plusieurs exécutions implémentent la même étape avec des paramètres variables, des fichiers d’entrée, du matériel ou une autre configuration.
Le contexte dans lequel les commandes sont exécutées dépend de trois choses principales :
- Environnement signifiant le type de machine et le Cloud Provider (AWS, Azure, GCP). Par exemple, vous souhaitez effectuer un entraînement d’un réseau de neurones sur une instance AWS avec 8 GPU, mais une étape d’extraction de features peut nécessiter une instance gourmande en mémoire sans GPU.
- L’image Docker contenant les principaux outils, bibliothèques et frameworks.
- Le contenu d’un commit dans votre répertoire, comme par exemple les scripts d'entraînement. Le contenu du commit sera disponible dans /Valohai/Repo, qui est également le répertoire de travail par défaut lors des exécutions.
Paramètres
Dans le contexte de Valohai, tous les paramètres à enregistrer sont définis avant de lancer une exécution. Si vous souhaitez enregistrer quelque chose qui est défini ou qui change pendant l’exécution, vous pouvez utiliser les metadatas de Valohai.
Définir les paramètres
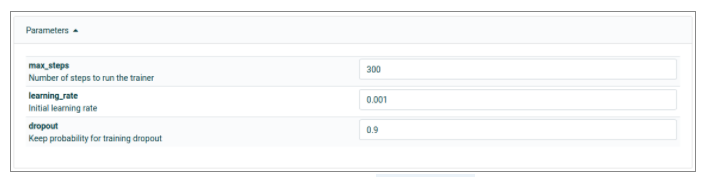
Vous pouvez ajouter les paramètres dans un fichier YAML. On peut voir dans l’exemple ci-dessous un exemple avec une étape “Step” pour définir trois paramètres.

Cela va générer la commande suivante :

Sélection des valeurs
Les valeurs des paramètres sont définies dans le fichier YAML, mais vous pouvez également les modifier en utilisant l’interface WEB (Voir figure ci dessous), la commande en ligne ou l’API. Toutes les modifications sont contrôlées par des versions et font partie d’une exécution Valohai.
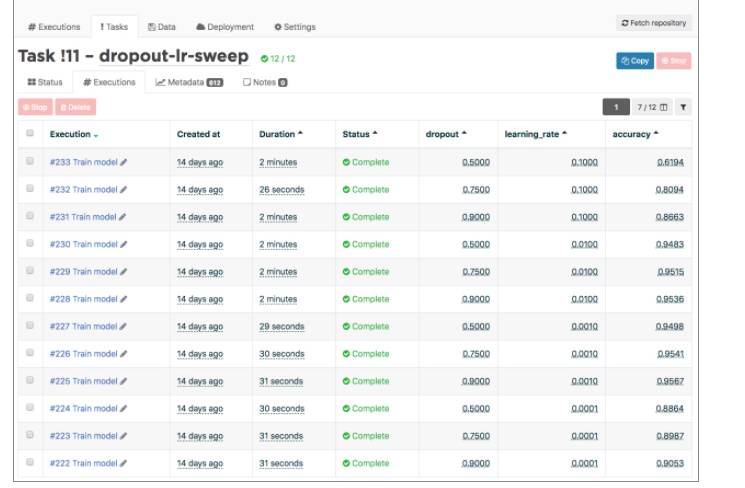
Recherche d'hyper paramètres
Il peut être décourageant d'essayer différents hyperparamètres un par un. Valohai propose un mécanisme pour effectuer des recherches d'hyper paramètres en utilisant des exécutions parallèles et une recherche par grille. Celles-ci sont appelées tâches.
Lors du démarrage d’une tâche, au lieu d’une seule valeur pour un seul hyperparamètre, vous pouvez définir plusieurs valeurs à la fois. Il existe différents modes au choix, par exemple Simple, Multiple, Linéaire, Logspace, Aléatoire.

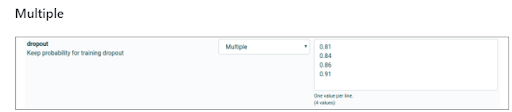
Multiple veut dire une liste de valeurs à essayer pour un hyperparamètre spécifique. Dans l'exemple, 4 valeurs différentes sont testées.
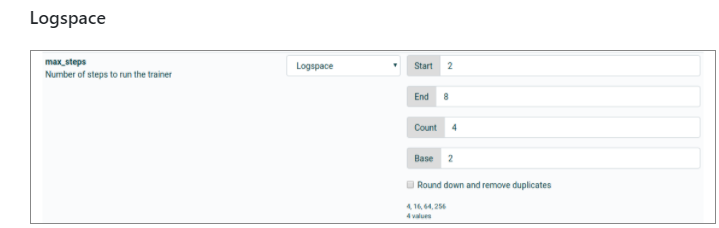
Logspace est une recherche avec des valeurs dans un intervalle logarithmique. Dans l’exemple on voit 4 différentes valeurs entre 2^2 - 2^8 (Base^start - base^end)
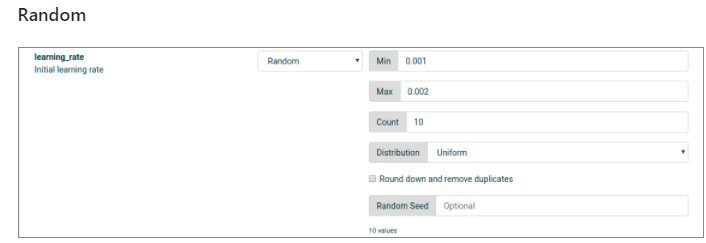
Faire de la recherche aléatoire. Dans l’exemple suivant on essaie 10 différentes valeurs entre 0.001 et 0.002 :
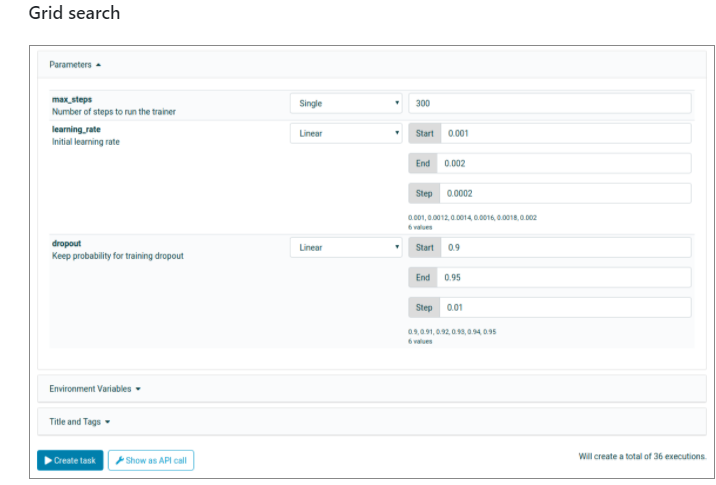
C’est le cas si vous voulez chercher plusieurs valeurs pour plusieurs hyperparamètres, toutes les permutations sont recherchées. Dans l’exemple, 6 valeurs différentes pour le learning rate et 6 autres valeurs pour le Dropout. Ce qui fait 36 exécutions.
Bayesian search
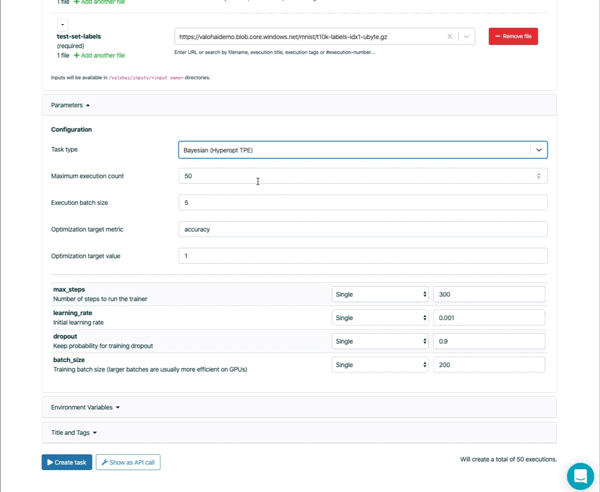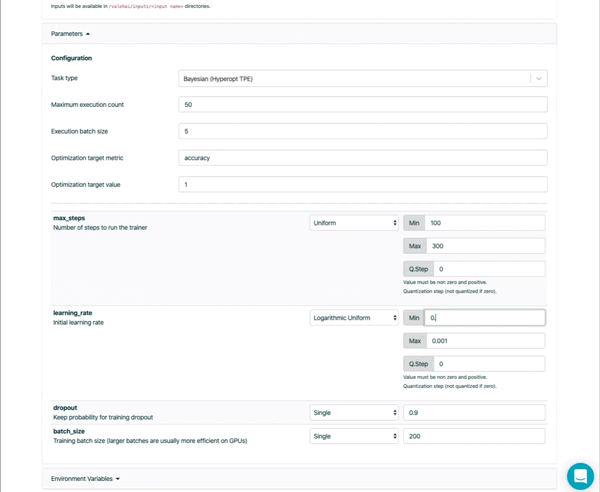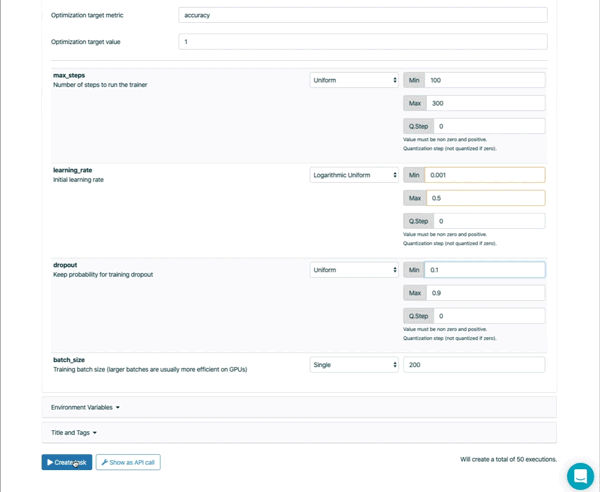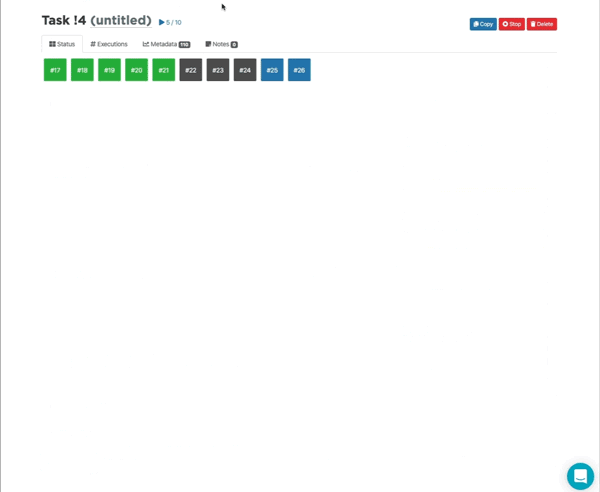
L’utilisation de l’optimisation interactive des hyperparamètres peut rendre le réglage des hyperparamètres plus rapide et plus efficace qu’une recherche aléatoire ou une recherche par un grid search.
Valohai utilise l’algorithme Tree Parzen Estimator de la librairie Hyperopt open source pour utiliser les hyperparamètres et les sorties des exécutions précédentes pour suggérer des hyperparamètres d’exécution futurs.
L’optimisation bayésienne suit quatres étapes :
- Créer une exécution de démarrage avec une recherche aléatoire,
- Sur la base de ces exécutions, créer une fonction simplifiée pour modéliser la relation entre les hyperparamètres et la valeur de la métrique cible (par exemple «Loss»),
- Sur la base de cette simplification de leur relation, trouver les valeurs optimales pour l'hyperparamètre et ainsi rendre la métrique cible aussi proche que possible de la valeur cible,
- Exécuter le prochain lot d'exécutions et répéter le processus à partir de l'étape 2.
Data Stores
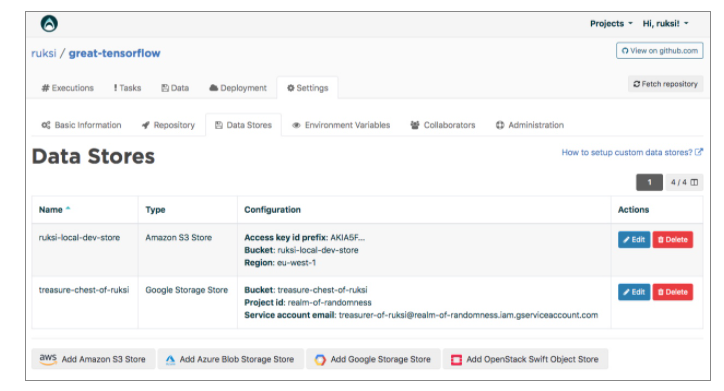
Chaque projet Valohai possède un ou plusieurs data stores. Un data store est un endroit sûr pour conserver vos fichiers; vous téléchargez les données d'entraînement à partir de là et y téléchargez vos modèles entraînés.
Valohai supporte plusieurs types de Data Stores :
- AWS S3,
- Azure Storage Account,
- Google Cloud Storage,
- OpenStack Swift.
Si vous n'assignez pas de Data Store à votre projet, vos fichiers seront téléchargés dans un bucket Amazon S3 sous un compte Valohai. Le bucket n'est pas public, vos données sont donc en sécurité, mais c’est recommandé d’utiliser un Data Store privé.
Tâches
Sont des collections d'exécutions associées. La tâche la plus courante est l'optimisation des hyperparamètres où vous exécutez une seule étape avec diverses configurations de paramètres pour trouver la disposition, les poids et les biais de réseau neuronal les plus optimaux.
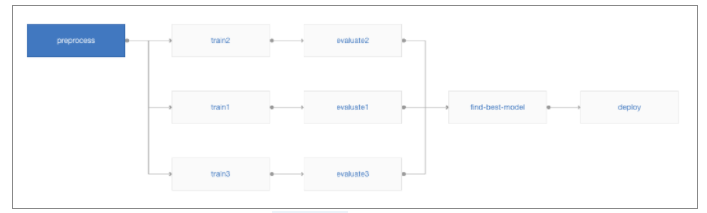
Pipelines
Pipeline est une collection d'exécutions contrôlées par version dont certaines reposent sur les résultats des exécutions précédentes, créant ainsi un graphe orienté. Ces graphiques de pipeline se composent de nœuds et d'arêtes.
Par exemple, on peut considérer la séquence d’opérations suivantes :
- Préparation,
- Entrainement,
- Evaluation,
- Choix de modèle,
- Déploiement.
Le pipeline aurait 4 nœuds ou plus ; au moins un pour chaque étape mentionnée ci-dessus et un pour le déploiement.
Pour l’exemple on peut imaginer la création de trois entraînements en parallèle, les comparer et choisir le modèle le plus performant pour le déployer en production.
Les pipelines peuvent être gérés dans l’interface web. Votre projet doit être connecté à un dépôt GIT avec une section pipelines dans le fichier Valohai.yaml. Voici une partie de l’exemple :

Deployments
Un déploiement est une collection versionnée d’un ou plusieurs web-endpoints pour l'inférence en ligne.
Chaque déploiement a une cible. La cible est un cluster Kubernetes sur lequel le service sera servi. La cible de déploiement par défaut est un cluster Kubernetes partagé géré par Valohai, mais vous pouvez également utiliser votre propre cluster. Vous pouvez avoir plusieurs déploiements si vous souhaitez exécuter votre service dans différentes localisations.
Version
Une version de déploiement est une image Docker que Valohai construit au-dessus de l'image Docker que vous spécifiez dans la définition YAML de l’endpoint. L’image contient :
- Votre dépôt de code,
- Tous les fichiers que vous aurez définis dans le fichier YAML.
La version de déploiement est l'artefact actuel qui est servi dans le cluster Kubernetes cible. Les versions de déploiement en cours seront accessibles sur un lien comme :
https: //valohai.com/
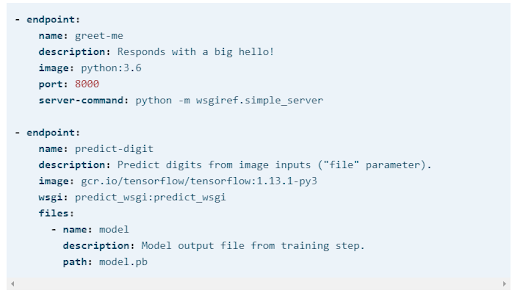
Endpoint
Un endpoint est un conteneur Docker exécutant un serveur HTTP dans un cluster Kubernetes auto-scalable. Vous pouvez avoir plusieurs endpoints par version de déploiement, car un seul projet peut avoir divers besoins d'inférence pour différents contextes. L'authentification peut être ajoutée de différentes manières, mais le plus simple est d'utiliser HTTP Basic Auth.
Vous pouvez définir votre endpoint dans le fichier YAML.
Notez que chaque endpoint que vous spécifiez dans le fichier YAML va avoir un URL séparé :
https: //valohai. cloud/<owner>/<project>/<deployment>/<version>/<endpoint>
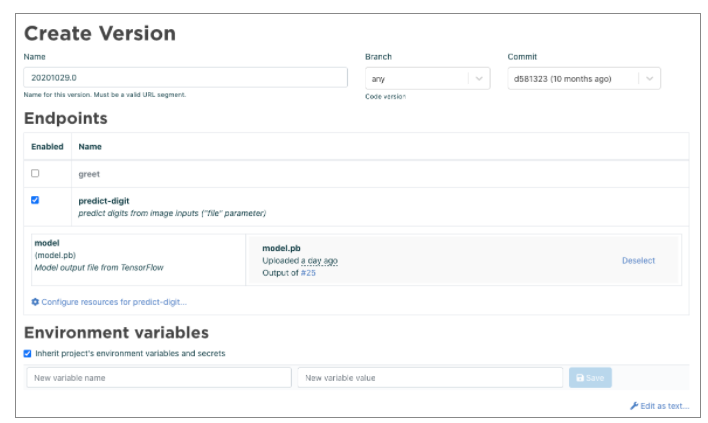
Variables d’environnement
Vous avez deux choix pour utiliser les variables d’environnement :
- Définir les variables d'environnement pour une version de déploiement particulière,
- Utiliser des variables d'environnement d’un autre projet.
Dans l'application Web :
- Project -> Deployment -> [your-deployment] -> Create version,
- Définir un pair Clé/Valeur dans l’interface.
Conclusion
Valohai est une plateforme de gestion de pipeline ML qui vous permet d’automatiser tout le workflow ML avec toutes les combinaisons possibles ; le tout gérable facilement à l’aide d’une interface Web. Vous pouvez choisir le Cloud Provider que vous voulez et les machines que vous voulez selon vos besoins.
Dans la plateforme tous vos projets sont versionnés, et réutilisables facilement. Vous avez également la possibilité de lancer plusieurs expérimentations en parallèle, choisir le meilleur modèle et l’utiliser comme un dernier modèle pour la production.
Tout cela va faciliter le travail des Data Scientists, qui vont pouvoir se concentrer sur le plus essentiel sans se soucier de l’infrastructure du Machine Learning ni de l’exécution des tâches répétitives.
