
Dans la partie précédente, nous avons eu un aperçu de SageMaker Studio d'Amazon et nous avons appris comment faire tourner une instance de Jupyter Notebook avec des ressources personnalisées, puis nous avons appris comment utiliser un modèle de classification pré-entraîné et le déployer sur un endpoint SageMaker.
Le endpoint déployé contient un modèle de classification des images de chiens et de chats, de sorte que notre endpoint peut effectuer des inférences sur de nouvelles images et produire des labels pour celles-ci.
Dans cette partie, nous apprendrons comment exposer notre modèle ML à une application web en tant qu'API serverless, toujours avec un niveau de détails permettant aux non initiés de le réaliser soi-même
Un excellent choix pour déployer notre modèle dans une application serverless est AWS Lambda, qui permet de livrer notre application beaucoup plus rapidement et de garantir l'évolutivité, la sécurité, les performances et la rentabilité de notre application avec moins de travail et sans gérer l'infrastructure sous-jacente.
Pour créer une application serverless utilisant Lambda, nous devons créer une API Gateway, écrire du code Lambda, rédiger une IAM policy et l'associer à la Lambda par le biais d'un rôle IAM qui donnera à la Lambda les autorisations d'accès aux services AWS, tels que SageMaker. Mais cet effort peut être évité en utilisant Chalice.
Qu’est ce que Chalice?
Chalice est un microframework open-source permettant d’écrire des applications serverless en Python. Il fournit une CLI conviviale qui facilite la création, le déploiement et la gestion de votre application serverless sur AWS. Pour plus de détails sur Chalice : https://github.com/aws/chalice.
Pré-requis
Mise en place des credentials AWS
Pour déployer une application sur AWS, vous devez configurer vos identifiants AWS qui se trouvent généralement sur ~/.aws/config via la commande suivante :
$ aws configure
Vous obtiendrez un message vous invitant à saisir votre Access Key ID, votre Secret Access Key (que vous avez obtenues à partir du tableau de bord de la console AWS) en plus du nom de la région par défaut et du format de sortie par défaut. Pour plus d'informations sur la manière de définir vos paramètres de configuration :
https://docs.aws.amazon.com/cli/latest/userguide/cli-configure-files.html
Créer une IAM policy et un IAM rôle pour la fonction AWS Lambda
En production, pour obtenir une inférence à partir d'un modèle hébergé sur un endpoint SageMaker, l'application cliente invoque le endpoint via l'API InvokeEndpoint. Pour authentifier cette action, nous devons écrire une IAM policy et l'associer à un IAM rôle.
En suivant les étapes ci-dessous, vous allez créer une policy et un rôle qui seront utilisés par la fonction Lambda.
- Connectez-vous à la console de gestion AWS.
- Dans la console AWS, cliquez sur Services > IAM pour ouvrir le tableau de bord IAM.
- Dans la barre latérale gauche, cliquez sur Policies > Create policy.
- Dans la console Create policy, cliquez sur l'onglet JSON puis remplacez l'exemple de policy par le script json suivant :
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"sagemaker:InvokeEndpoint"
],
"Resource": [
"*"
]
}
]
}
- Cliquez sur Review Policy.
- Dans la zone de texte Name, tapez sagemaker-lambda-policy.
- Cliquez sur Create policy.
- Dans la barre latérale gauche, cliquez sur Create role.
- Dans la console Create role, dans Select type of trusted entity sélectionnez AWS puis dans Choose a use case cliquez sur Lambda.
- Cliquez sur Next: Permissions.
- Dans la barre de recherche, recherchez la sagemaker-lambda-policy que vous venez de créer.
- Choisissez sagemaker-lambda-policy > Next: Tags > Next: Review.
- Dans la zone de texte Name, tapez sagemaker-lambda-role > Create role.
- Dans la liste des rôles, recherchez sagemaker-lambda-role puis cliquez dessus.
- Sur la page de résumé du rôle, notez l'ARN du rôle qui sera utilisé plus tard.
Mise en place du projet Chalice
Premièrement, créez et activez un environnement virtuel Python.
$ python -m venv .venv
$ source .venv/bin/activate
Puis installez Chalice & boto3.
(.venv)$ pip install chalice
(.venv)$ pip install boto3
Une fois que Chalice et boto3 sont installés sur votre environnement virtuel, utilisez Chalice CLI pour générer un modèle de projet Chalice.
$ chalice new-project image-classifier
Cette commande a créé un répertoire appelé image-classifier. Maintenant, allons dans ce répertoire du projet et regardons les fichiers.
image-classifier
├── .chalice
│ └── config.json
├── .gitignore
├── app.py
└── requirements.txt
.chalice/config.json : configuration pour l'application serverless.
requirements.txt : contient la liste des bibliothèques dont votre fonction aura besoin.
app.py : ce fichier est constitué de fonctions Python, avec des décorateurs indiquant les web routes.
Si nous regardons dans app.py, nous pouvons voir qu'il s'agit d'un exemple d'API REST qui, lorsqu'il est appelé, renvoie le JSON body {"hello": "world"}.
from chalice import Chalice
app = Chalice(app_name='image-classifier')
@app.route('/')
def index():
return {'hello': 'world'}
Nous allons apporter les modifications suivantes au fichier app.py pour qu'il puisse invoquer le SageMaker endpoint que nous avons créé dans le post précédent.
Remplacez le contenu de app.py par le code ci-dessous :
from chalice import Chalice
from chalice import BadRequestError
import base64, os, boto3, ast
import numpy as np
import json
from urllib.request import urlopen
app = Chalice(app_name='image-classifier')
app.debug=True
# Get environment variables
ENDPOINT_NAME = os.environ['ENDPOINT_NAME']
sm_runtime = boto3.client('sagemaker-runtime')
@app.route('/', methods=['POST'])
def index():
body = app.current_request.json_body
image = base64.b64decode(body['data']) # byte array
# Invoking SageMaker Endpoint
response = sm_runtime.invoke_endpoint(
EndpointName=ENDPOINT_NAME,
ContentType='application/x-image',
Body=image)
propa_result = json.loads(response['Body'].read().decode())
# Load names for image classes
text_url = urlopen("https://raw.githubusercontent.com/a-shlash/"
"sagemaker_chalice_app/master/"
"imagenet1000_clsidx_to_labels.txt")
image_categories = {}
for line in text_url:
decoded_line = line.decode("utf-8")
key, val = decoded_line.strip().split(':')
image_categories[key] = val
result = "Result: \n label: " +
image_categories[str(np.argmax(propa_result))]+
" \n probability: " + str(np.amax(propa_result))
return(result)
Pour mettre en place la configuration du projet, ouvrez le fichier /image-classifier/.chalice/config.json, remplacez son contenu par le script suivant :
{
"version": "2.0",
"app_name": "image-classifier",
"autogen_policy": false,
"lambda_timeout" : 60,
"lambda_memory_size": 512,
"manage_iam_role":false,
"iam_role_arn":"YOUR_SAGEMAKER_LAMBDA_ROLE_ARN",
"environment_variables": {"ENDPOINT_NAME": "YOUR_SAGEMAKER_ENDPOINT"},
"stages": {
"dev": {
"api_gateway_stage": "api"
}
}
}
Ensuite, remplacez YOUR_SAGEMAKER_LAMBDA_ROLE_ARN par le rôle ARN que vous avez généré précédemment pour le rôle sagemaker-lambda-role et remplacez YOUR_SAGEMAKER_ENDPOINT par le endpoint que vous avez créé dans le post précédent.
Tester la fonction Lambda en local
Chalice supporte le développement en local, ce qui est un moyen de développer et de déboguer notre fonction Lambda sans l’API Gateway ni la fonction Lambda avant de la déployer sur AWS.
Pour lancer Chalice en local, depuis votre terminal, utilisez la commande suivante :
(.venv)$ chalice local
Serving on http://127.0.0.1:8000
Par défaut, Chalice tournera sur le port 8000. Pour tester la fonction, lancez une requête curl sur cet endpoint dans un deuxième terminal :
(.venv)$ export URL='http://localhost:8000'
(.venv)$ export IMG='border_collie.jpg'
(.venv)$ (echo -n '{"data": "'; base64 $IMG; echo '"}') |
curl -H "Content-Type: application/json" -d @- $URL
Result:
label: 'Border collie',
probability: 0.866693377494812
Une fois que l'application est configurée et testée avec succès, nous pouvons la déployer dans l'infrastructure AWS (Lambda et API Gateway).
Déploiement sur AWS
Pour déployer l'application sur AWS, retournez sur le terminal et quittez le serveur Chalice local, puis déployez l'application en utilisant la commande chalice deploy.
Un déploiement réussi de l'application affiche l'ARN Lambda et l'URL de l'API REST, comme indiqué dans l'image suivante :
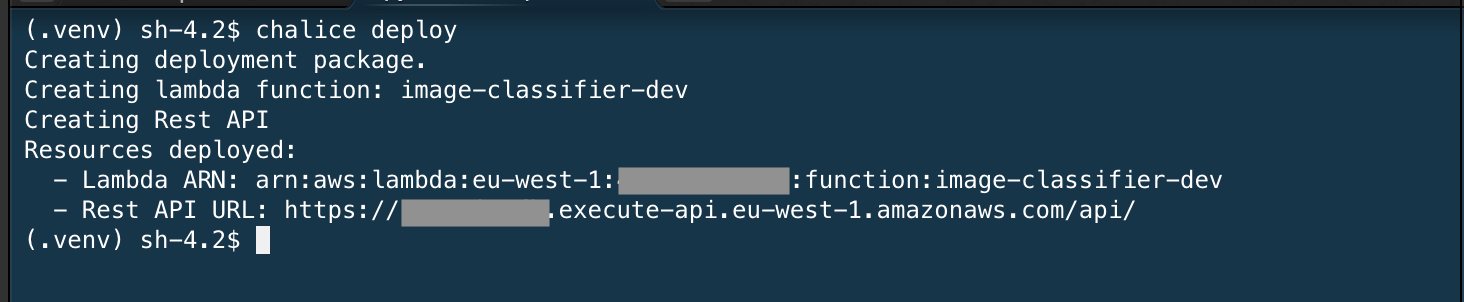
Copiez l'URL de l'API REST et lancez une requête curl sur cet endpoint par le biais de cette URL comme suit :

L'application Chalice, utilisant Lambda, invoquera le endpoint SageMaker pour appliquer l'inférence sur l'image. Elle l'utilisera pour déterminer un label puis la retournera.
Nettoyer
Enfin, si vous souhaitez supprimer les ressources AWS créées pour cette expérimentation, suivez les étapes suivantes.
- Supprimez toutes les ressources que Chalice a déployées sur AWS en exécutant la commande suivante :
(.venv)$ chalice delete
Cela supprime le endpoint API Gateway et la fonction Lambda.
- Depuis Amazon SageMaker, dans la console de gauche, sous Inference, choisissez Endpoints.
- Sélectionnez le endpoint créé dans le notebook, puis choisissez Actions > Delete.
- Ouvrez la console Amazon S3, videz le bucket créé par SageMaker puis supprimez-le.
- Ouvrez IAM Policies, recherchez sagemaker-lambda-policy et supprimez-la.
- Ouvrez IAM Roles, recherchez le rôle sagemaker-lambda-role et supprimez-le.
Conclusion
Félicitations ! Vous venez de déployer une application serverless sur AWS à l'aide de Chalice qui peut invoquer un modèle ML hébérgé dans un endpoint SageMaker. A noter que vous pouvez tout à fait déclencher vos lambdas créées à l'aide de Chalice par des events extérieurs comme les events S3. Par exemple, dès la réception d'une image dans un bucket S3, l'endpoint du modèle pourra être sollicité pour faire une prédiction concernant l'image en question.
