

Au démarrage d'un projet, le choix de la base de données est une étape importante au bon déroulement de celui-ci. En fonction du type de données à stocker, on pourra choisir d’utiliser plutôt une base relationnelle, graphe, documents ou autre.
Certains projets peuvent nécessiter la mise en place de plusieurs bases de données, une base pour chaque type.
Le choix n’est pas toujours facile au début du projet car les données pourraient être amenées à changer.
ArangoDB répond en partie à cette problématique, car elle a la particularité d’être multi-modèle.
Multi-modèle
ArangoDB fait partie des bases de données dites NoSQL. Celles-ci regroupent quatre grands types de structure de données : clé-valeur, documents, colonnes et graphe.
ArangoDB prend en charge nativement les données de type document, graphe et clé/valeur.
Il n'y aura donc besoin d'installer et monitorer qu’une seule base et de n'apprendre qu’un langage de requête.
Langage unique
ArangoDB utilise son propre langage, l’AQL (Arango Query Language). L’AQL se rapproche du SQL dans la logique de construction des requêtes.
D’un point de vue technique, les 3 modèles sont stockés différemment, mais cela est transparent pour l’utilisateur final car les requêtes se font comme si l’on n'avait qu’une seule et même base. Ainsi, on peut récupérer des données des 3 modèles dans la même requête.
La syntaxe ressemble à du JavaScript. Des exemples de requêtes sont disponibles dans la deuxième partie de l’article.
Open source et version gratuite
Le projet commencé en 2011 est open source (Apache Licence 2.0) et a récemment dépassé les 10000 étoiles sur Github.
ArangoDB se décline en 2 versions, la version community et la version enterprise. La version enterprise apporte quelques fonctionnalités supplémentaires, en particulier sur le mode cluster et la sécurité.
Join natif
Contrairement à la plupart des bases de données NoSQL, ArangoDB permet de réaliser des requêtes JOIN tout en gardant la souplesse des bases de données documents. Il n’y a pas de contrainte sur les clés étrangères par exemple.
GeoJSON
GeoJSON est un format d’encodage pour les données géospatiales utilisant la norme JSON.
ArangoDB supporte ce format et permet de faire des requêtes pour calculer des distances, rechercher des points dans une zone géographique, etc.
Full-text search
Il est possible avec ArangoDB de définir un index full-text sur certains champs textuels et d’effectuer des requêtes complexes dédiées à la recherche dans du texte. Par exemple, on peut chercher dans un texte plusieurs mots clés et en exclure certains.
Facilité d'installation
ArangoDB propose un large choix d’installation, on pourra l’installer on-premise sur les différents OS (Windows, Linux, MacOs) ou virtualisée avec Docker.
Si l’on souhaite utiliser Kubernetes, un chart Helm permet de rapidement mettre en place un cluster.
Depuis un an, ArangoDB propose l'offre ArangoDB Oasis, entièrement managée dans le cloud avec le choix de l'hébergeur (AWS, GCP, ou Azure). Elle apporte en plus une meilleure gestion de la sécurité, une scalabilité facile et peut facilement être intégrée à des solutions d’Infrastructure-as-Code grâce à une API dédiée.
Nombreux drivers
ArangoDB propose des drivers officiels pour les langages Java, JavaScript, PHP, et Go, ainsi que des drivers communautaires pour PHP, .NET, Go, Python, Scala, Ruby.
Une intégration avec Spring Data et un connecteur spark Scala/Java sont aussi proposés.
L’utilisation des drivers nécessite tout de même d’écrire les requêtes avec le langage AQL.
Distribuée
L’installation proposée par défaut est le mode stand-alone mais ArangoDB propose d’autres modes d’installation :
Master/Slave: un Master et un ou plusieurs Slaves. Les requêtes en écriture doivent être envoyées au Master, le Slave réplique les données du Master de façon asynchrone.Cluster: dans cette configuration, les requêtes peuvent être envoyées sur n’importe quel nœud. On parle de Master/Master.
ArangoDB possède un système de transactions qui respecte les propriétés ACID. En mode stand-alone, les requêtes multi-documents et multi-collections sont supportées, en mode cluster, seules les requêtes single-document sont garanties ACID.
La documentation d’ArangoDB présente en détail le fonctionnement des transactions (Transactions) ainsi que les différents modes d’installation (Architecture).
Performante
ArangoDB a réalisé un benchmark en 2018 pour comparer son produit avec les bases MongoDB, PostgreSQL (tabular & JSONB), OrientDB et Neo4j. Les résultats sont accessibles sur leur site : Benchmark: MongoDB, PostgreSQL, OrientDB, Neo4j and ArangoDB.
Selon leur test, les performances d’ArangoDB étaient tout à fait à la hauteur de ses rivales pour les écritures / lectures. Les performances étaient très bonnes pour les agrégations et la recherche de voisins dans les graphes. La consommation mémoire était cependant un peu supérieure à la moyenne.
Elle était supérieure à la célèbre base Neo4j sur tous leurs critères de test.
ArangoDB est cependant moins performante qu’une base clé/valeur classique.
Un document clé/valeur dans ArangoDB est simplement un document avec un seul champ value. ArangoDB déconseille d’utiliser cette base dans le seul but de stocker des données clé/valeur.
Interface web
L’interface web n’est pas forcément la fonctionnalité la plus recherchée dans le choix d’une base de données, pourtant, elle peut apporter un vrai plus dans le management et le monitoring de la base.
L’interface web d’ArangoDB remplit parfaitement ce rôle grâce à un dashboard de monitoring, un éditeur de requêtes, et un outil de visualisation de graphes.
Documentations
ArangoDB propose une documentation complète avec de nombreux exemples : Documentation Overview
Une vingtaine d’entreprise ont partagé leur retour d’expérience sur ArangoDB et leur cas d’usage : ArangoDB Customers - NoSQL Multimodel Database
Il est aussi possible de rejoindre le Slack officiel ou un Google Groups dédiés à ArangoDB pour obtenir du support.
Hands-on
Ce tutoriel a pour but de prendre en main rapidement l’interface web d’ArangoDB et de comprendre les fonctionnalités principales, en particulier :
- Key/Value,
- Documents,
- Join,
- GeoJSON,
- Graphe.
On prendra comme exemple un réseau social qui aurait besoin de stocker des posts (Posts), des utilisateurs (Users) avec leur localisation (Cities) et des commentaires (Comments) sur les posts.
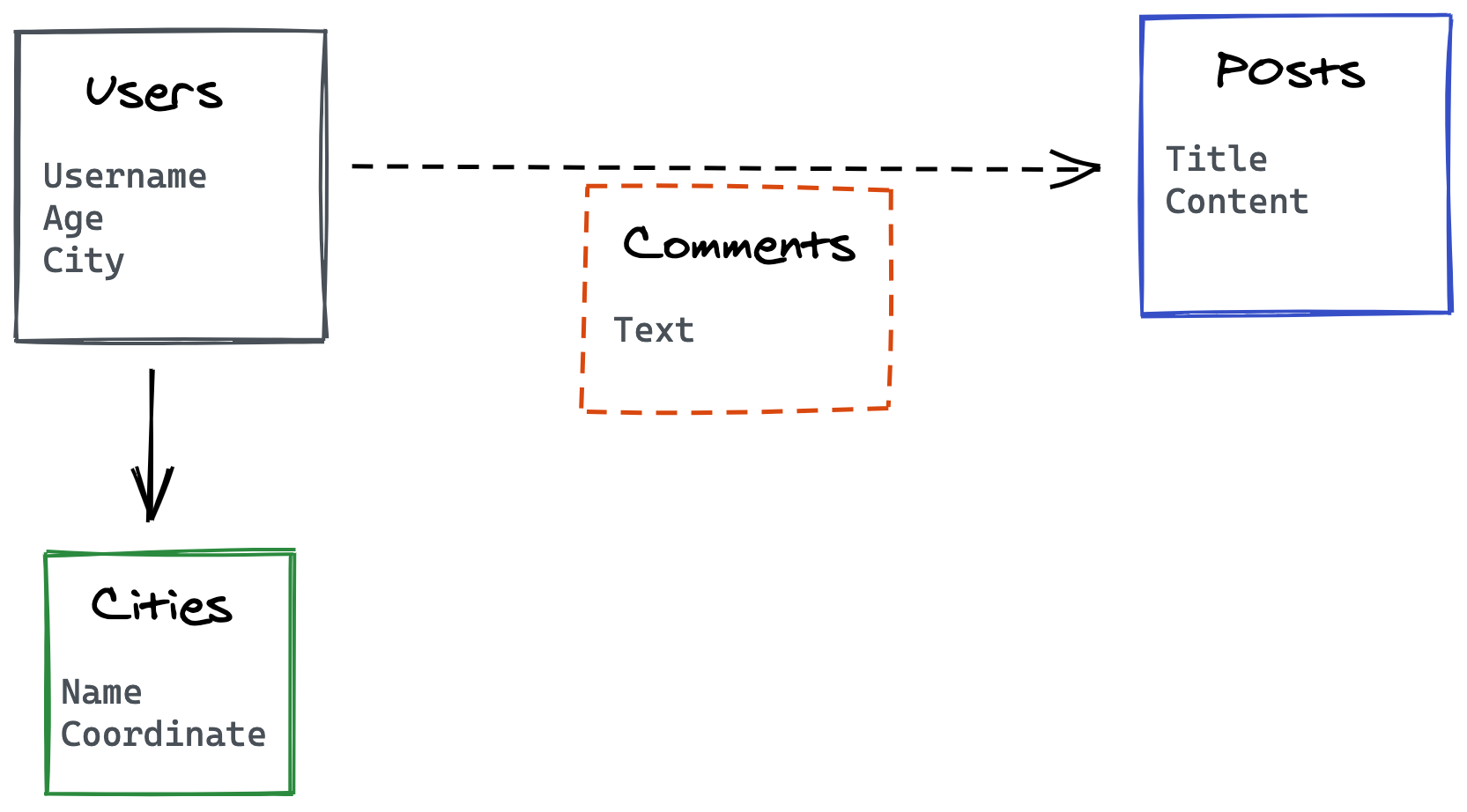
Installation d’ArangoDB
La solution la plus rapide pour tester ArangoDB est d’utiliser l’image Docker. Il est toutefois possible d’installer la base sur une autre plateforme en suivant la documentation officielle (Download ArangoDB Database Community Edition).
Si Docker est installé sur votre poste, lancez la commande suivante :
docker run -p 8529:8529 -e ARANGO_ROOT_PASSWORD=openSesame arangodb/arangodb:3.7.2.1
L’interface web est disponible à l’adresse : http://localhost:8529/.
Une fois sur la page de connexion, connectez-vous en utilisant l’utilisateur root et le mot de passe openSesame.
Choisissez la base _system (la seule disponible pour l’instant).
La base _system propose un dashboard de monitoring, la gestion des utilisateurs et bases de données, la réplication, les logs, etc.
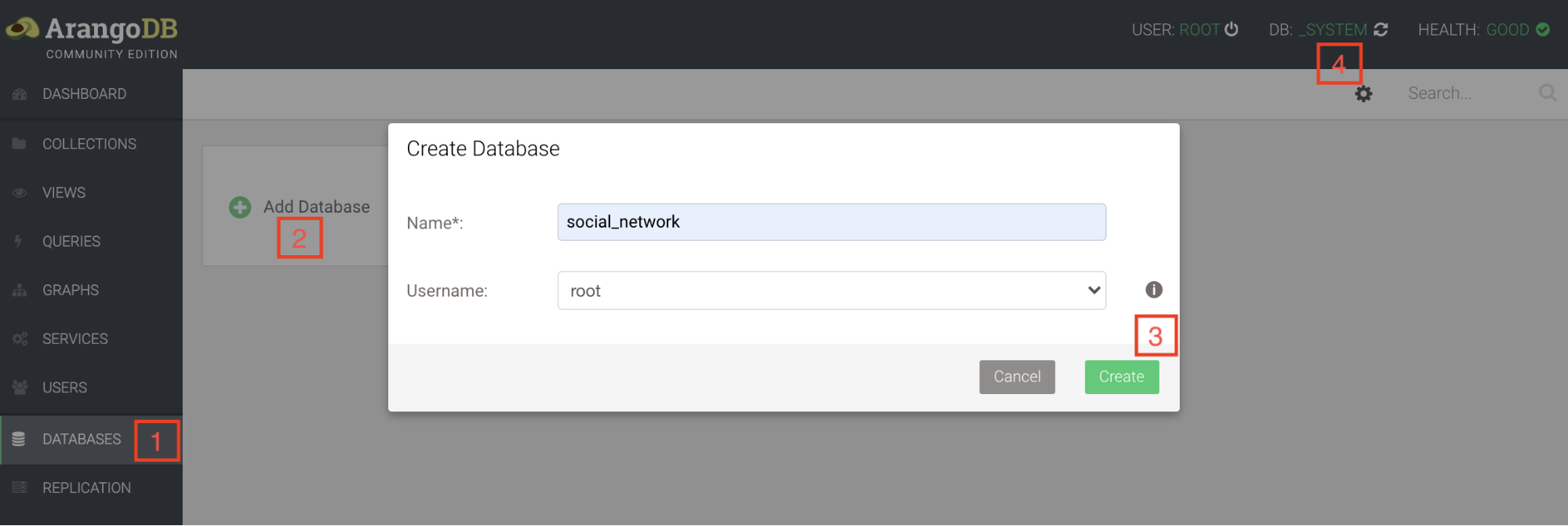
Création de la base
Créez une nouvelle base nommée social_network à partir de l’onglet DATABASES (1) et passez de la base _system à la nouvelle base (4).
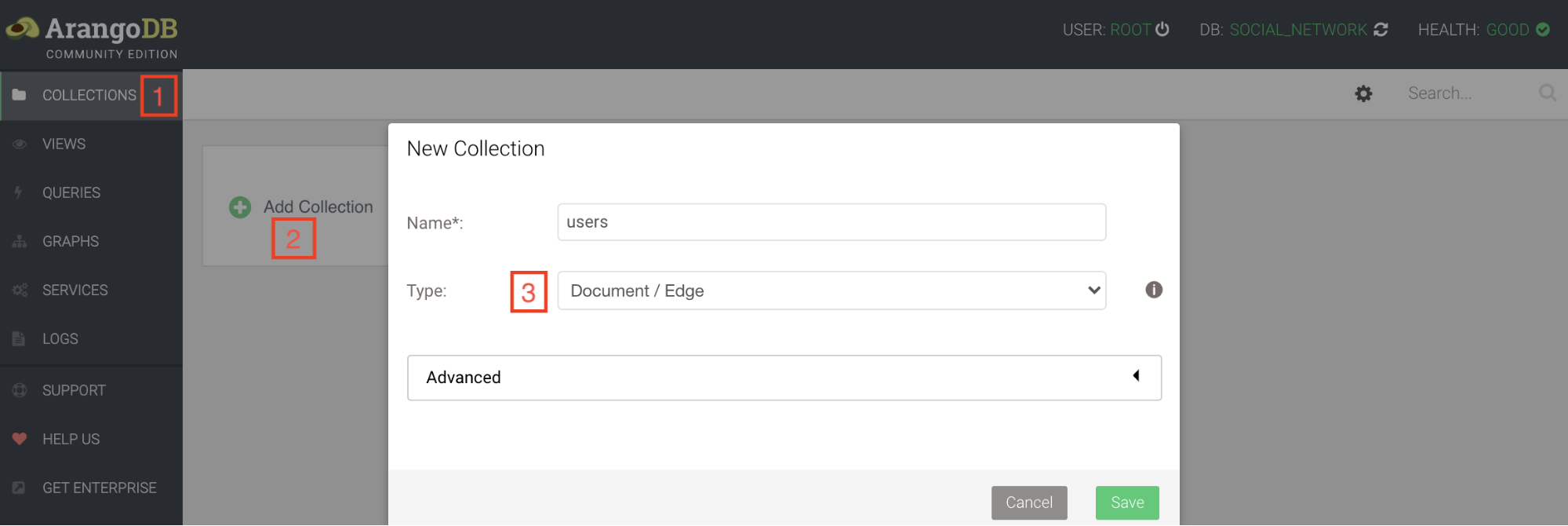
Création des collections
Il existe 2 types de collections dans ArangoDB :
Document;Edge: dédiée aux graphes, les documents dans une collectionEdgepermettent de faire le lien entre deux documents classiques.
Pour le réseau social, on va créer 3 collections du type Document :
users;posts;cities;
et 1 collection du typeEdgepour les commentaires qui fera le lien entre lesuserset lesposts:comments.
Dans l’interface web, on remarque l’utilisation de logos différents pour les collections Document et les collections Edge.

Insertion des données
Les documents ArangoDB possèdent des champs particuliers :
- _key : la clé du document. Si elle n’est pas définie, celle-ci sera générée. La clé est indexée et unique ;
- _id : l’id est la concaténation du nom de la collection et de la clé. L’id est indexé. On peut faire une requête pour obtenir un document directement grâce à son id.
Pour les documents de type Edge, qui représentent les relations :
- _from : l’id du document d’origine,
- _to : l’id du document d'arrivée.
Pour insérer les données, on va utiliser le langage AQL dans l'éditeur de requête.
Sélectionnez dans le menu QUERIES (1), écrivez la requête (2), et exécutez-là (3).
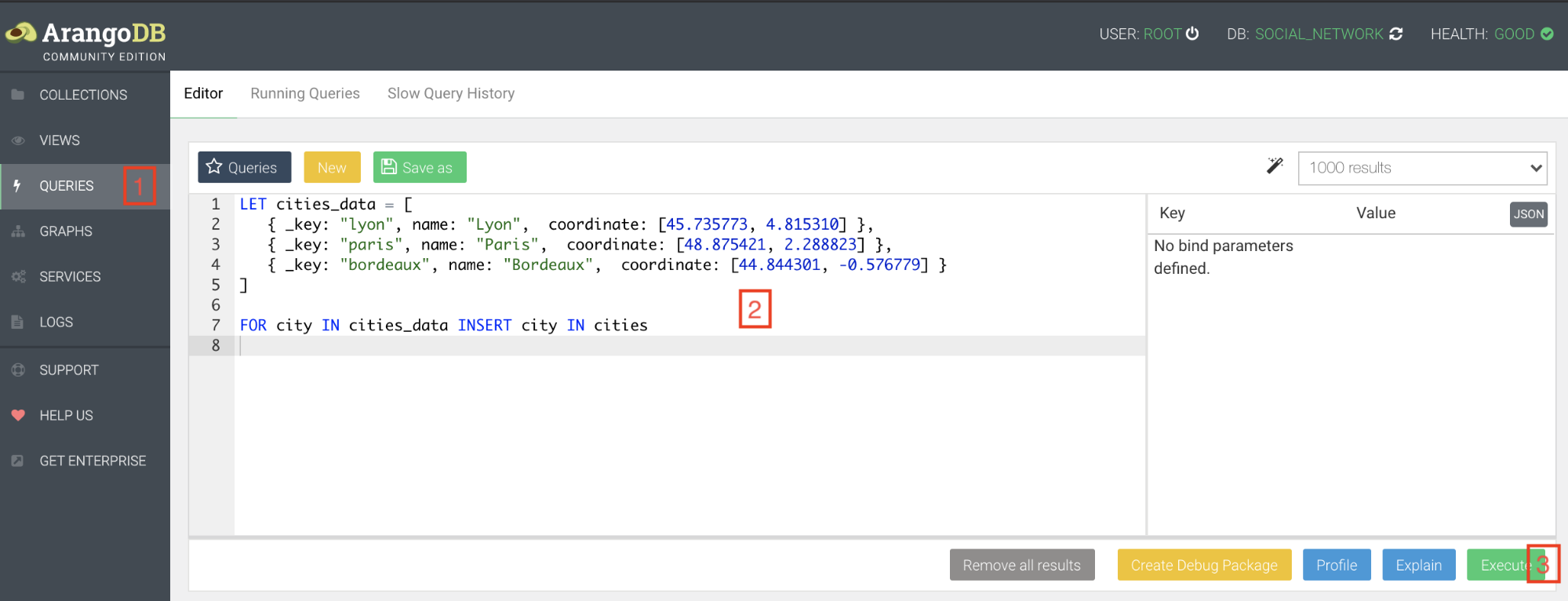
Cities
On insère 3 villes avec leurs coordonnées GPS.
LET cities_data = [
{ _key: "lyon", name: "Lyon", coordinates: [45.735773, 4.815310] },
{ _key: "paris", name: "Paris", coordinates: [48.875421, 2.288823] },
{ _key: "bordeaux", name: "Bordeaux", coordinates: [44.844301, -0.576779] }
]
FOR city IN cities_data INSERT city IN cities
Users
On insère 4 utilisateurs possédant un nom d’utilisateur, un âge et l’id d’une ville précédemment insérée dans la collection cities.
LET users_data = [
{ _key: "user_1", username : "user 1", age: 25, city: "cities/lyon" },
{ _key: "user_2", username : "user 2", age: 35, city: "cities/lyon" },
{ _key: "user_3", username : "user 3", age: 55, city: "cities/paris" },
{ _key: "user_4", username : "user 4", age: 60, city: "cities/bordeaux" }
]
FOR user IN users_data INSERT user IN users
Posts
On insère 4 posts avec leur titre et leur contenu.
LET posts_data = [
{ _key: "post_1", title: "post 1", content: "content 1" },
{ _key: "post_2", title: "post 2", content: "content 2" },
{ _key: "post_3", title: "post 3", content: "content 3" },
{ _key: "post_4", title: "post 4", content: "content 4" }
]
FOR post IN posts_data INSERT post IN posts
Comments
On insère des commentaires qui font le lien entre des utilisateurs (_from) et des posts (_to).
LET comments_data = [
{ _from: "users/user_1", _to: "posts/post_1", text: "Comment of user 1 on post 1" },
{ _from: "users/user_1", _to: "posts/post_3", text: "Comment of user 1 on post 3" },
{ _from: "users/user_2", _to: "posts/post_1", text: "Comment of user 2 on post 1" },
{ _from: "users/user_2", _to: "posts/post_2", text: "Comment of user 2 on post 2" },
{ _from: "users/user_2", _to: "posts/post_3", text: "Comment of user 2 on post 3" },
{ _from: "users/user_3", _to: "posts/post_3", text: "Comment of user 3 on post 3" },
{ _from: "users/user_3", _to: "posts/post_4", text: "Comment of user 3 on post 4" }
]
FOR comment IN comments_data INSERT comment IN comments
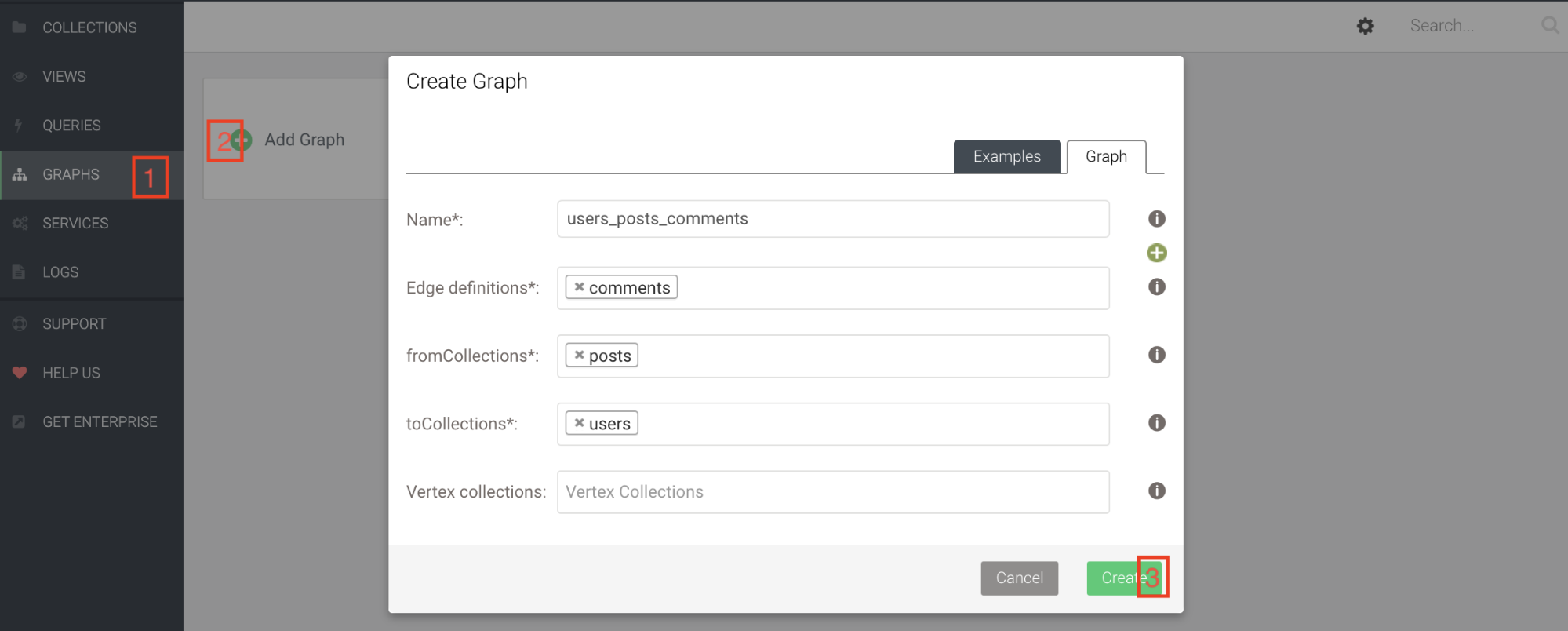
Création du graphe
On va maintenant créer un graphe pour modéliser la relation entre les utilisateurs, les posts et les commentaires.
Pour cela, sélectionnez GRAPHS dans le menu (1), ajoutez un graphe (2), puis créez le graphe en définissant la collection edge à utiliser (comments) ainsi que la collection from (posts) et to (users) (3).
Une fois le graphe créé, on va pouvoir visualiser les données.
Toujours dans l’onglet GRAPHS sélectionnez le graphe créé (1).
Seulement quelques nœuds sont chargés par défaut, dans le graphe créé, on a très peu de données, on peut charger sans risque l'intégralité des données en cliquant sur le bouton (2).
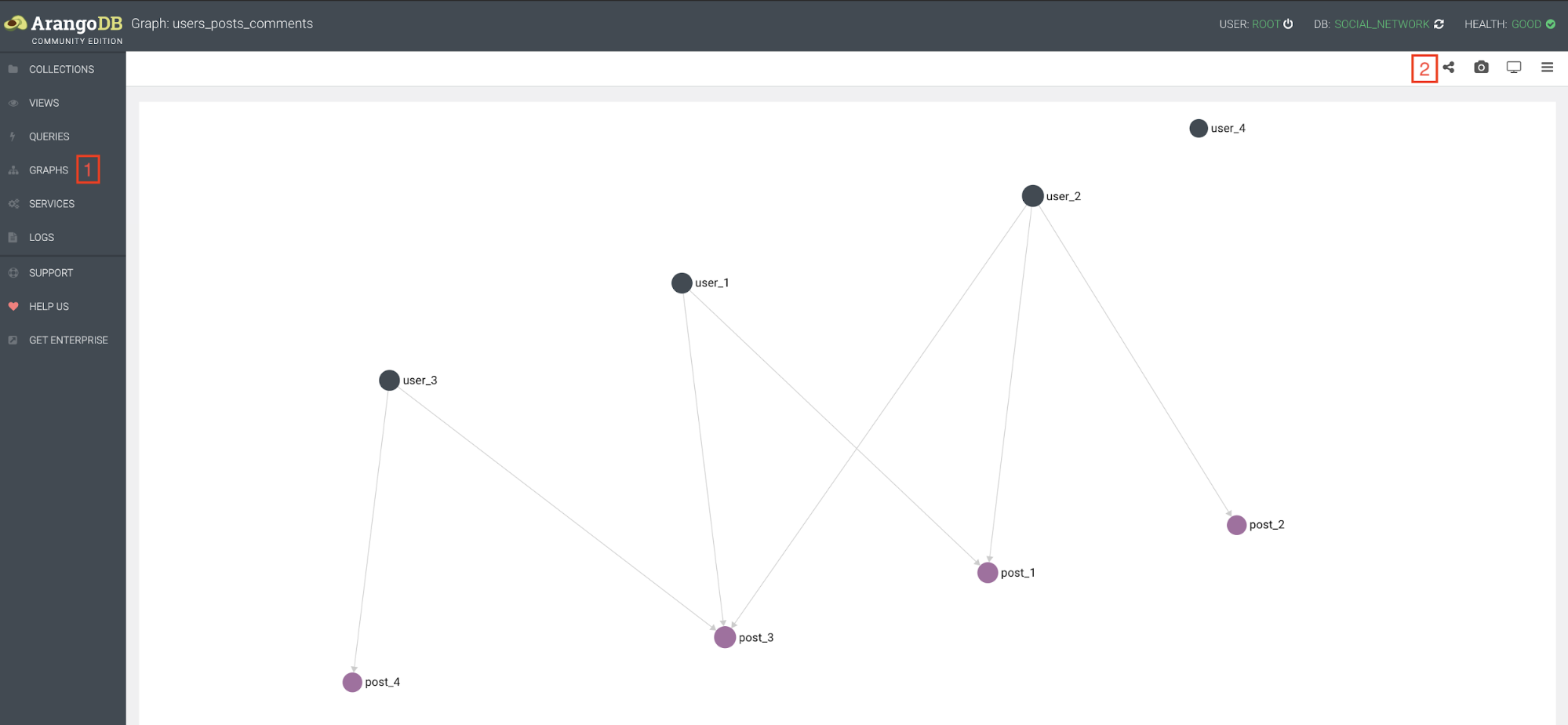
Les relations entre les utilisateurs et les posts correspondent bien aux commentaires insérés. C’est un graphe orienté, le sens des flèches indique la direction de la relation. Dans ce cas, ce sont des utilisateurs qui commentent des posts.
Requêtes
Pour réaliser les requêtes, on va utiliser l’interface web.
Cliquez sur l’onglet QUERIES (1) pour accéder à l’éditeur, écrivez une requête (2) puis exécutez-la (3).
Le résultat apparaît en dessous, sous forme de tableau par défaut, mais cela peut être changé pour s’afficher au format json (4).
Key/Value
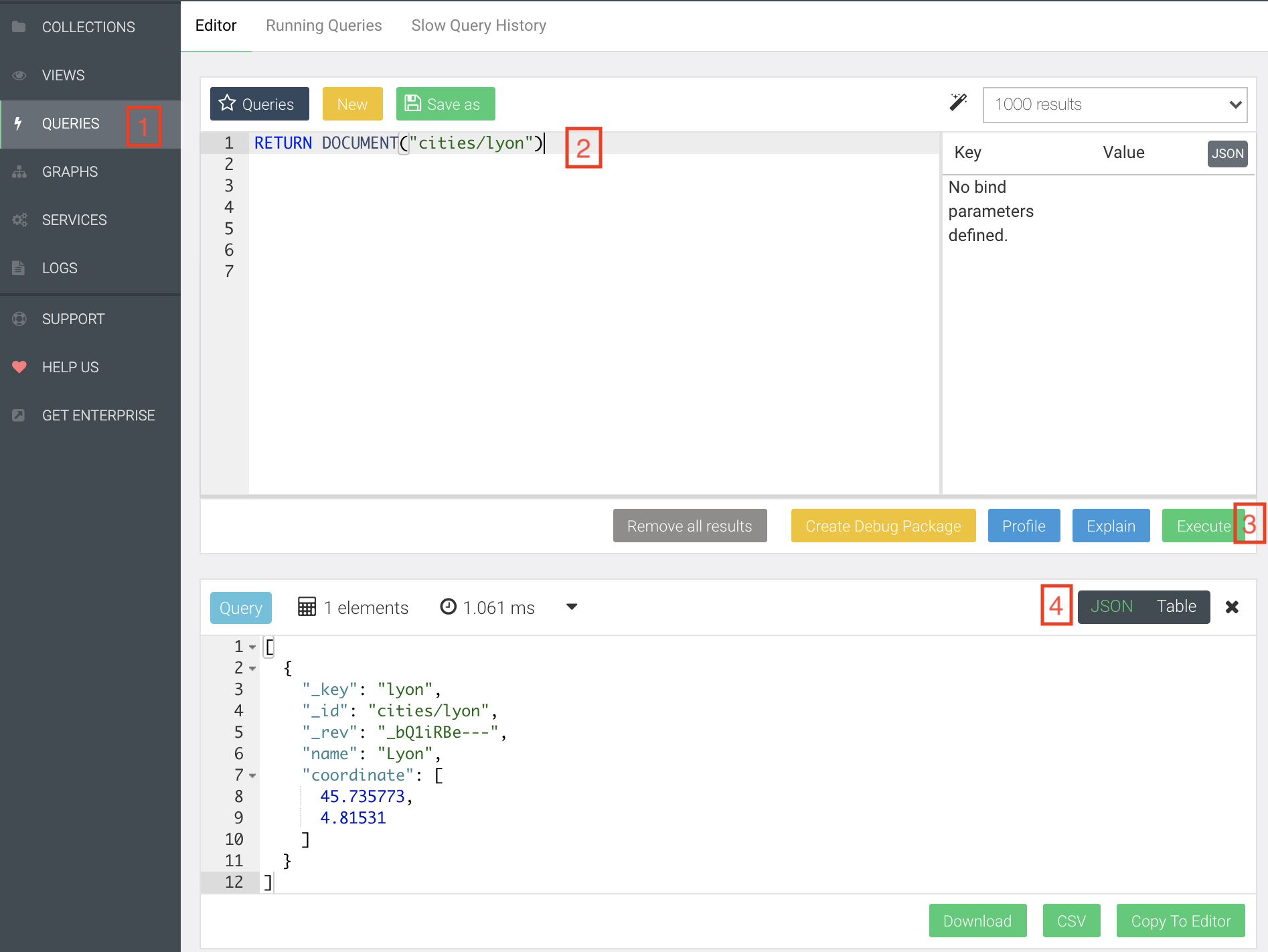
On peut requêter un document en connaissant son id (généré à partir de la collection et de la clé)
Si l’on souhaite récupérer le document associé à la ville de Lyon, on fera la requête suivante :
Requête :
RETURN DOCUMENT("cities/lyon")
Résultat :

Documents
On souhaite récupérer pour tous les utilisateurs, leur nom d’utilisateur et leur âge.
Requête :
FOR user IN users
RETURN {
username: user.username,
age: user.age
}
Résultat :
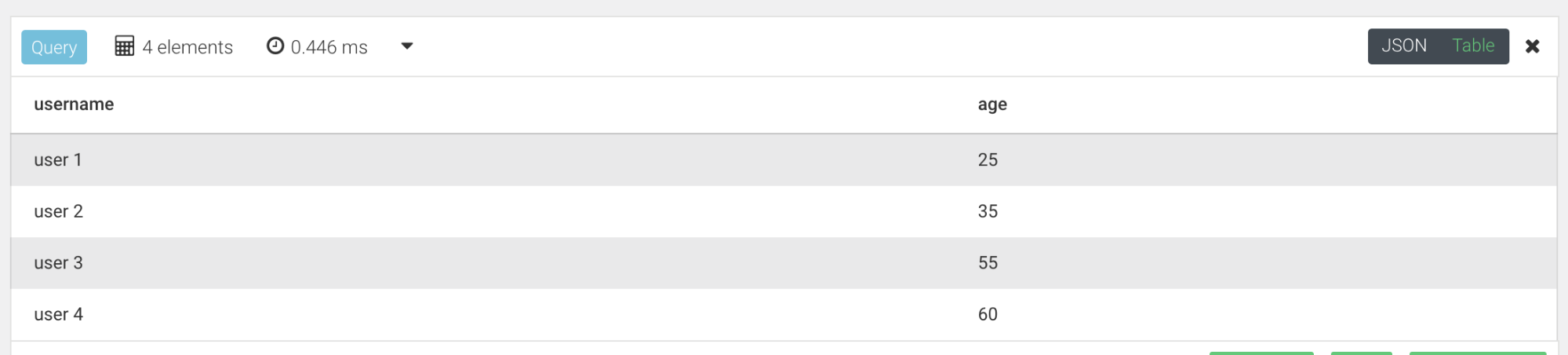
Join
On souhaite maintenant récupérer les utilisateurs de plus de 25 ans avec les informations détaillées sur les villes.
Requête :
FOR user IN users
FOR city IN cities
FILTER user.city == city._id
FILTER user.age > 25
RETURN MERGE(user, {city: city})
On utilise la fonction MERGE afin d’obtenir un seul document à partir de l’utilisateur et de la ville correspondante. ArangoDB propose de nombreuses fonctions prédéfinies documentées sur leur site : ArangoDB Query Language AQL Functions
Résultat :

On retrouve bien les 3 utilisateurs avec le document correspondant à leur ville inclus dans le champ city.
Geojson
Prérequis :
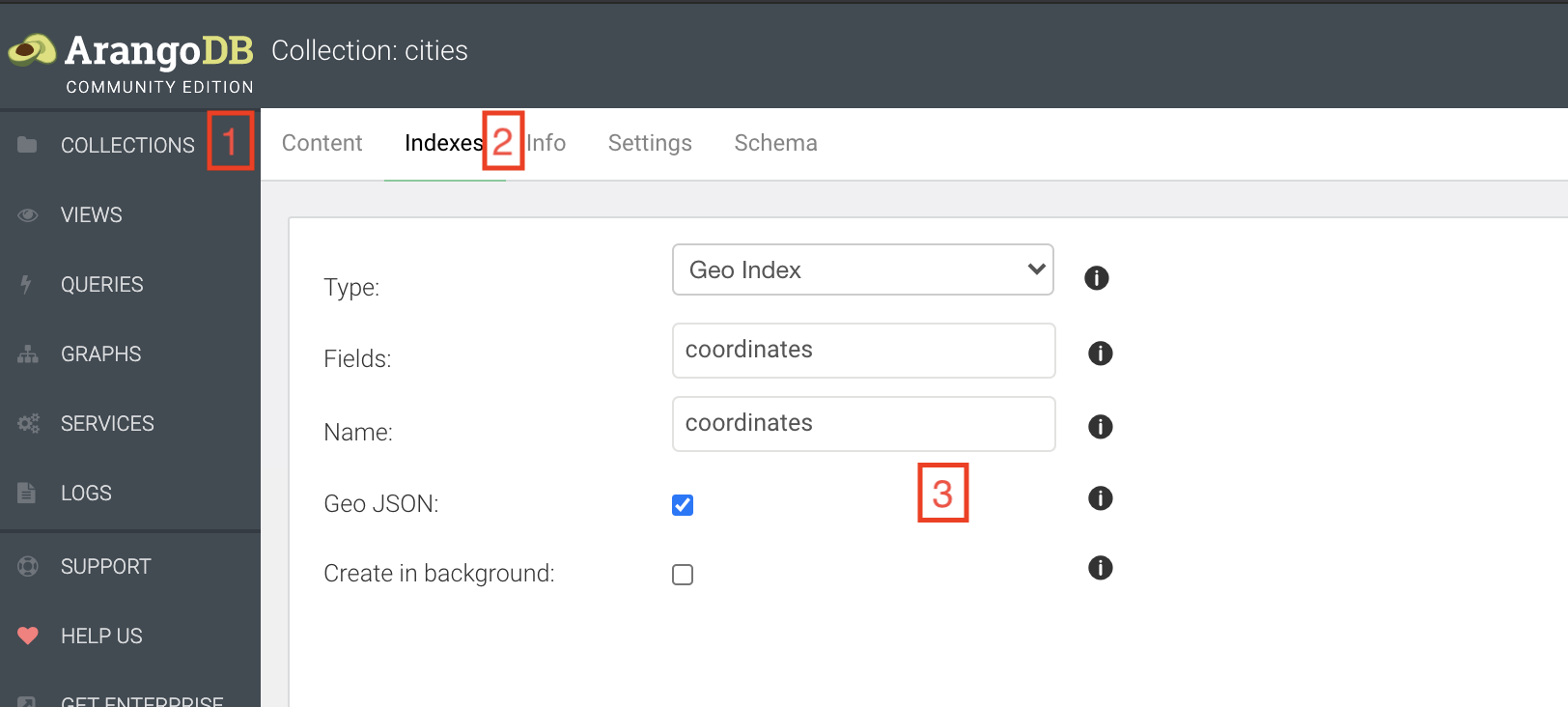
Pour réaliser des requêtes utilisant des coordonnées GPS, ArangoDB a besoin d’indexer le champ contenant les coordonnées.
Sélectionnez dans l’onglet COLLECTIONS la collection cities (1), puis allez dans l’onglet indexes (2).
Ajoutez un index de type Geo Index sur le champ coordinates et cochez la case Geo JSON (3).
On souhaite calculer la distance des utilisateurs par rapport à la tour Eiffel (48.858723, 2.295468).
Pour cela, on stocke le résultat de la requête précédente avec les 3 utilisateurs de plus de 25 ans dans une variable et on exécute une requête pour calculer la distance sur ces données.
Requête :
LET users_with_city = (
FOR user IN users
FOR city IN cities
FILTER user.city == city._id
FILTER user.age > 25
RETURN MERGE(user, {city: city})
)
FOR user IN users_with_city
LET distance = DISTANCE(user.city.coordinates[0], user.city.coordinates[1], 48.858723, 2.295468)
RETURN {
username: user.username,
city: user.city.name,
distance: distance / 1000
}
Les distances sont en mètres, on divise par 1000 pour convertir en kilomètres.
Résultat :

Les résultats sont cohérents, l’utilisateur 3 de Paris est à 1,9 km de la tour Eiffel, les deux autres utilisateurs sont à plus de 350 km.
Graphe
Prérequis :
Les requêtes en AQL de type graphe utilisent le vocabulaire des graphes.
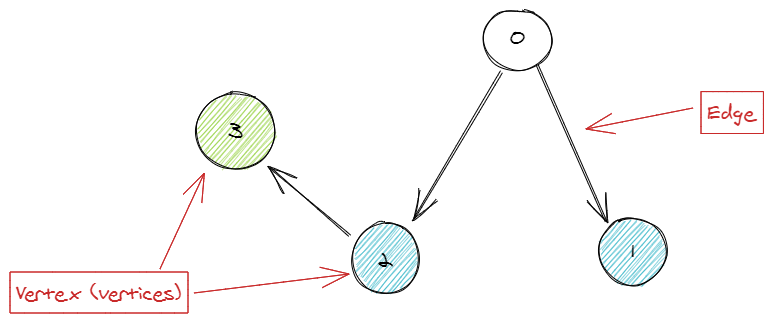
- Vertex (Vertices au pluriel) : les sommets/nœuds du graphe (0, 1, 2, 3),
- Edge : les arêtes qui relient deux sommets entre eux (l'arête 0 vers 2 , 2 vers 3 par exemple),
- Path : les chemins parcourus entre deux nœuds,
- Outbound / Inbound / Any : le sens de parcours,
- Outbound : le même sens que la relation (2 vers 3),
- Inbound : sens inverse de la relation (2 vers 0),
- Any : parcours du graphe dans les deux sens,
- Min..Max : la profondeur minimum et maximum du graphe,
- 1..1 retournera les nœuds en bleu,
- 2..2 retournera le nœud en vert,
- 1..2 retournera les nœuds bleu et vert.
Cas 1 :
On souhaite utiliser le graphe pour obtenir les commentaires de l’utilisateur 2.
Requête :
FOR vertex, edge, path IN 1..1 OUTBOUND
'users/user_2' GRAPH 'users_posts_comments'
RETURN {
post_title: vertex.title,
comment: edge.text
}
Résultat :

L’utilisateur 2 a commenté les posts 1, 2, et 3.
Cas 2 :
On souhaite obtenir les utilisateurs qui ont commenté le post 3. Pour cela, on doit parcourir notre graphe dans le sens inverse, on utilise le mot clé INBOUND.
Requête :
FOR vertex, edge, path IN 1..1 INBOUND
'posts/post_3' GRAPH 'users_posts_comments'
RETURN vertex
Résultat :

Les utilisateurs 1, 2 et 3 ont commenté le post 3.
Cas 3 :
Enfin, on souhaite obtenir les utilisateurs qui ont commenté les mêmes posts que l’utilisateur 1 ainsi que le nombre de posts qu’ils ont commentés en commun. Cela permet par exemple d’en déduire les utilisateurs qui ont des goûts similaires à l’utilisateur 1.
Cette requête est dite traversal, on va traverser le graphe sur deux niveaux (users -> posts -> users). On indique dans ArangoDB le degré de profondeur (2..2) et que l’on souhaite traverser dans les 2 sens (ANY).
On utilise la fonction COLLECT et COUNT pour compter le nombre d'occurrences des utilisateurs.
Requête :
FOR vertex, edge, path IN 2..2 ANY
'users/user_1' GRAPH 'users_posts_comments'
COLLECT user = vertex WITH COUNT INTO length
RETURN {
username: user.username,
length
}
Résultat :

L’utilisateur 1 et l’utilisateur 2 ont commenté 2 articles en commun.
Conclusion
ArangoDB est une bonne candidate pour les projets nécessitant le stockage de données sous forme de documents et de graphe.
Cette base est facile à installer et à utiliser grâce aux nombreux drivers disponibles.
Elle propose un mode cluster et différents systèmes de réplication.
Certes, le langage AQL pourra être perturbant au début, en particulier pour les requêtes graphe, cependant, la documentation officielle est très complète.
ArangoDB mérite d’être considérée dans le choix de la base de données, pour des besoins multi-modèle ou si le modèle de données n’est pas bien défini.
