

Certains utilisateurs de PySpark se reconnaîtront dans ce qui suit :
- Mon algorithme est super lent… Pourtant mon code semble bon !
- Fais ça pour voir : spark.conf.set("spark.sql.execution.arrow.pyspark.enabled", "true")
… Quelques minutes après...
- Ah ouais tu m’as sauvé la vie, c’est plus rapide !
(Sauvé la vie… J’en rajoute un peu !)
Quand on regarde la quantité de librairies open-source, on y trouve de tout (et c’est ça qu’on vient chercher généralement), mais il est très rare de trouver, caché, des librairies impactant autant la manière de penser le “compute”.
Une de ces librairies dont je voudrais vous parler aujourd’hui est Apache Arrow.
On retrouve Arrow dans des frameworks comme Apache Spark, Apache Flink, Apache Parquet ou encore Pandas. C’est une petite librairie présente dans l’ombre des frameworks les plus utilisés dans le domaine de la Data.
Il est temps de la mettre en lumière !
Posons les bases
Apache Arrow est un ensemble de librairies et d’outils pour le traitement de données en mémoire (In-memory). Arrow peut être vu comme une liste de spécifications pour le transfert de données en mémoire. Mais...
Arrow n’est pas un exécutable ou un système installable, ce n’est pas une solution de cache mémoire ou d’IMDB (In Memory DataBase).
La librairie a été créée dans un but analytique et non dans la gestion de données temps réel ou dans un environnement transactionnel.
Apache Arrow propose un format de données en mémoire multilangage, multiplateforme et en colonnes. Il propose également des frameworks IPC (Inter-Process Communication) et RPC (Remote Procedure Call) pour l’échange de données entre processus et entre nœuds (d’où sa présence dans l’écosystème du Big Data et la gestion des processus distribués).
“In-memory computing”
Regardons comment cela fonctionnait avant l’arrivée d’Apache Arrow :

Prenons l’exemple de Spark s’appuyant sur des données stockées au format Parquet.
Nous devons lire et désérialiser la donnée stockée au format Parquet nous obligeant à stocker entièrement la donnée en mémoire.
- Nous allons d’abord lire la donnée dans un buffer en mémoire.
- Nous allons convertir la donnée du format Parquet vers la représentation de notre donnée dans notre langage de programmation (nécessaire car la représentation d’un nombre en Parquet, par exemple, n’est pas la même que la représentation de ce même nombre en Python).
Quelle perte de performance et de stabilité pour notre algorithme ! Pourquoi ?
- Nous devons copier et convertir la donnée avant de faire une quelconque opération dessus.
- La donnée doit tenir entièrement en mémoire (que faire si j’ai 8Gb de mémoire de libre et 10Gb de donnée en entrée de mon code Spark ?).
Voyons maintenant comment cela fonctionne avec Apache Arrow :

Au lieu de copier et convertir la donnée, Arrow sait comment lire et opérer la donnée sérialisée. Pour que cela fonctionne, la communauté Arrow a défini un nouveau format de données qui permet d'interagir directement sur la donnée sérialisée. Ce format de données peut être lu directement depuis le disque (stocké sous forme de fichiers) donc nul besoin de le stocker en mémoire. Bien sûr certaines parties de la donnée vont passer en RAM mais il n’y a plus besoin d’y stocker la totalité de cette donnée grâce à un système de memory-mapping permettant de ne remonter en mémoire que la donnée à traiter à l’instant T.
Arrow élimine le besoin de sérialisation car les données sont représentées par les mêmes octets sur chaque plateforme et langage de programmation. Ce format commun permet le transfert de données sans copie dans les systèmes Big Data, afin de maximiser les performances du transfert de données.
Format de stockage en colonnes
Le cœur d’Arrow est son format de stockage colonne.
Dans la plupart des systèmes de stockage, la donnée est stockée row-wise. C'est-à-dire que la donnée sera stockée sur disque ligne par ligne. Maintenant imaginons que l’on souhaite agréger la donnée, il faudra alors lire toutes les lignes, entièrement, une à une et extraire la donnée à agréger.
Un exemple parlant : imaginons que nous avons un site de e-commerce et qu’on travaille sur la gestion du panier. Chaque produit ajouté au panier correspond à une ligne dans notre système et une des colonnes est le “prix”. L’agrégation peut consister alors à sommer toutes les valeurs de la colonne “prix”. Il faudra donc lire TOUTES les lignes, filtrer la valeur dans la colonne “prix” et sommer ces valeurs.
Dans un domaine BI/BA (Business Intelligence/Business Analysis), les agrégations sont le cœur du métier. Le stockage row-wise est une perte de temps, d’espace de stockage, de performance.
Si on pense maintenant en format colonne où chaque colonne et ses valeurs sont stockées au même endroit, nous n’aurons besoin d’accéder qu’à la colonne à agréger pour faire notre calcul. Quel gain pour notre cas d’utilisation en BI/BA !
Le stockage colonne nous permet de gagner en efficacité pour accéder à une colonne mais permet également de profiter au maximum des avantages des architectures de CPU moderne quand on parle de caching, pipelining et d’instructions Single Instruction Multiple Data (SIMD) au niveau du processeur. Je vous laisse lire l’excellent article de Dremio sur le sujet et leur benchmark.
Qu’est ce qu’on gagne en passant sur un format colonne ? De la rapidité !
Si on souhaite mettre du visuel sur les mots voilà la représentation d’Arrow en mémoire :
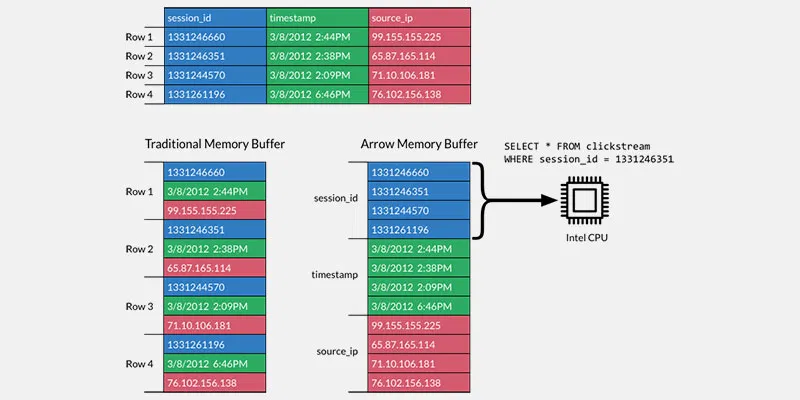
Attention, ce n’est pas Arrow qui rattrapera les médiocres performances d’une application mal développée mais elle permet de faire, par son gain en performance, des choses qu’on ne pouvait pas faire avant.
Langages supportés
Voilà la liste des langages supportés par Apache Arrow :
- C++
- C#
- Go
- Java
- JavaScript
- Rust
- Python (via la librairie C++)
- Ruby (via la librairie C++)
- R (via la librairie C++)
- MATLAB (via la librairie C++)
Mais Apache Arrow n’est pas juste un nouveau format de fichier plus performant !
IPC (Inter-Process Communication)
La librairie Arrow offre également une interface et des moyens de communiquer entre les processus et les nœuds. Ce qui veut dire que des processus, un processus Python et un processus Java, peuvent efficacement s’échanger de la donnée sans la copier localement. Au niveau des nœuds d’un réseau, également, nous profitons d’optimisations de par la nature d’Arrow. En effet, au travers du réseau ne transitera que les colonnes nécessaires au traitement lancé sur le nœud distant.
Rappelons par ailleurs, que nous n’aurons toujours pas besoin de désérialiser la donnée, à aucun moment, vu que Arrow sait l’opérer sérialisée.
A en croire Dremio, PySpark (algorithme Python sur un moteur Spark tournant sur une JVM) a profité pleinement d’Arrow : “IBM measured a 53x speedup in data processing by Python and Spark after adding support for Arrow in PySpark”.
RPC (Remote Procedure Call)
Depuis fin 2019, la communauté Arrow porte un projet nommé Flight sous forme de librairie. Arrow Flight est un framework de développement permettant d’implémenter des services d’échange bi-directionnel de flux de données, basé sur Arrow. C’est un protocole de transfert de données optimisé pour l’analytique.
Dans un environnement distribué, Arrow Flight offre la puissance d’Arrow en exposant la donnée via des endpoints (au lieu de travailler avec la donnée localisée).
Arrow Flight tire parti du streaming bi-directionnel de gRPC (basée sur la diffusion HTTP / 2) pour permettre aux clients et aux serveurs de s’envoyer simultanément des données et des métadonnées pendant que les demandes sont traitées.
Cette parallélisation des moyens d’interactions entre services permettra, entre autres, d’accélérer les transferts réseau.
Dremio (ce n’est pas la première fois que je parle d’eux, un jour un article sortira sur leur excellente solution de Data Lake Engine) a observé lors du benchmark de leur connecteur Apache Arrow qu’en utilisant Arrow ils ont amélioré drastiquement (20-50 fois supérieur) les performances réseau comparé à une connection ODBC via TCP.
Qu’est ce qu’il manque alors à Arrow ?
La compréhension de comment fonctionne Arrow peut être primordiale dans notre quête de performances. Beaucoup de projets, comme Pandas, l’ont compris et ont misé dessus. Arrow est devenu un standard dans l’industrie de la donnée en mémoire.
Ce qu’il manque à Arrow est un moteur de requêtage natif permettant de manipuler simplement les données stockées au format Arrow. Mais quelque chose me dit que la communauté Arrow, ultra active et réactive, est déjà en train de travailler dessus…
