

Retour d’expérience sur la construction d’un entrepôt de données par Christophe GRALL, Patrick TRAN et Yann KAISER
Agrégateur leader en France, Agregio est la filiale du groupe EDF dédiée à l’agrégation de production d’énergie renouvelable, de flexibilité et d’effacement de consommation. Il s’adresse à deux types de clients: les producteurs d’électricité renouvelable (éolien, solaire, …) et les clients consommateurs d’électricité (industriels, entreprises, …).
Pour les producteurs d’électricité, Agregio propose des offres sur-mesure pour optimiser et vendre leur production sur les marchés, en leur sécurisant des revenus dans la durée.
Agregio s’adresse également aux consommateurs industriels et tertiaires, qui sont prêts à réduire ou à déplacer leur consommation contre rémunération, en fonction des besoins du système électrique.
Pour administrer tout cela, Agregio utilise non seulement sa plateforme d’agrégation, mais aussi de nombreux boîtiers placés chez les clients pour monitorer la production ou la consommation d’énergie.
Pour améliorer la performance d’Agregio sur le marché, leurs data scientists ont de nombreux besoins d’analyse du passé pour prévoir les comportements à venir sur les prix, la production, la consommation ou la tension du système électrique. Des timeseries sont utilisées pour stocker des multitudes de données comme les productions, prévisions de production, disponibilités en terme d’énergie d’un client etc. et ce en général pour chaque pas d’1 seconde à 30 minutes. Avec l'augmentation du nombre des clients d’Agregio le nombre de données a explosé, il est donc nécessaire de pouvoir accéder aux données et de pouvoir les utiliser pour différents usages : facturation, optimisation, prévisions, ….
La création d’un entrepôt de données apporte les fonctionnalités suivantes:
- Basculement des données opérationnelles 24/7 vers l’entrepôt de données afin de stocker et analyser les données.
- La gestion des données de facturation pour le “back-office”.
- L’utilisation de nombreuses données opérationnelles et externes pour améliorer les process d’optimisation et de prévisions.
Basculement de données
L’architecture de la plateforme d’agrégation est composée de plusieurs microservices agrégeant des données de sources diverses (API externes, données IOT, …). Dans le but de stocker l’historique des données opérationnelles pour les utiliser et les analyser, une solution de bascule des données vers l’entrepôt de données a été envisagée.
La base de données de l’entrepôt contiendra donc l’historique des données. Ce nouveau projet se veut novateur: un des piliers architecturaux de notre équipe est d’utiliser au maximum les services managés AWS.
Après une étude des différentes solutions potentielles, nous avons retenu le service DMS (Data Migration Service) d’AWS. Il permet de transférer simplement et rapidement tout ou partie d’une base de données source, vers une autre base de données (la cible). Pour des soucis de service, nous avons choisi la solution de créer et partager un snapshot de la base de données de la plateforme d’agrégation vers l’entrepôt de données.
Point technique DMS
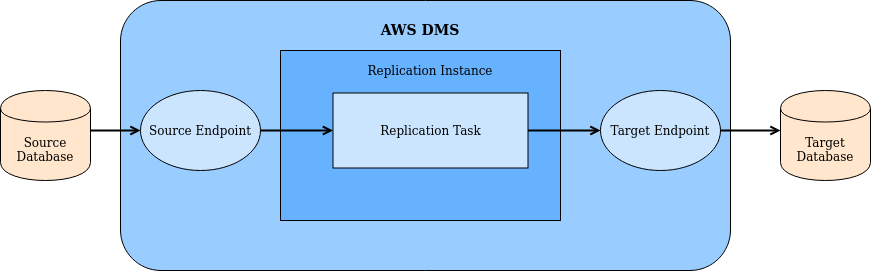
Un snapshot est une “image” de la base de données à un instant donné. Il faut voir cela comme une sauvegarde brute du contenu de celle-ci.
Une première approche
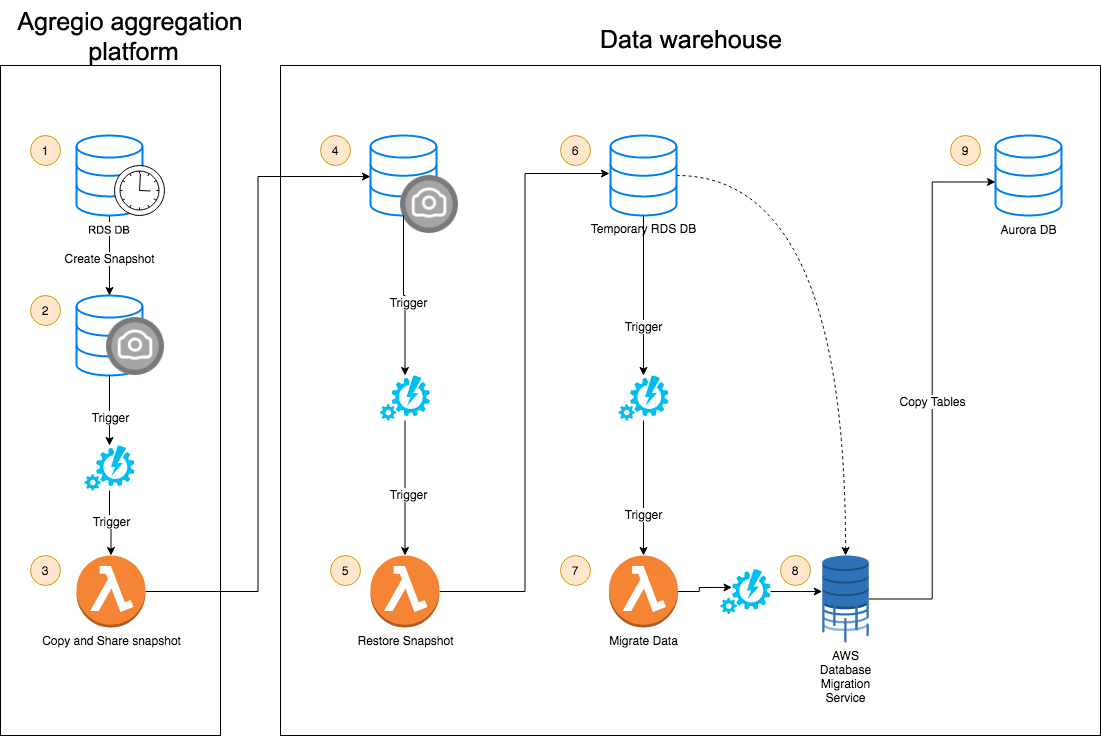
- Un snapshot est planifié par un CRON (par ex. tous les jours à 08h00)
- Lorsque le snapshot est créé, un événement est déclenché et exécute une lambda de copie.
- La lambda de copie “transfère” le snapshot du compte source de la plateforme d’agrégation vers le compte destination de l’entrepôt de données.
- Un événement est déclenché à la fin de la copie / du transfert, qui exécute une lambda de restauration.
- La lambda de restauration va simplement créer une base de données contenant les données du snapshot (fonctionnalité restore from snapshot d’AWS RDS)
- Dès que la base de données est disponible (que l'on peut y lire et écrire), un autre événement est déclenché: la migration des données
- La lambda de migration des données crée les tâches de migration dans DMS et lance leurs exécutions
- DMS s’exécute: les tables sont migrées à la vitesse de la lumière
- La base de données cible est mise à jour avec les dernières données
Et si je supprime des données entre deux migrations ?
Dans la première solution présentée ci-dessus, les tables de la base de données source sont copiées “telles qu'elles” vers la destination: cela implique que si des données ont été supprimées entre deux migrations, elles le seront aussi dans la base de données destination… Pas idéal pour répondre au besoin d’historisation !
Pour régler ce problème, il y a une solution, et elle est native dans DMS ! Il est possible, lors de la création d’une tâche de migration de table, de spécifier des conditions, par exemple ne migrer que les lignes contenant une certaine valeur, ou uniquement les lignes à partir d’un certain ID. C’est notamment cette dernière condition qui nous permet de ne prendre que les nouvelles données, tout en gardant le contenu dans la base de destination !
La deuxième proposition, concrètement, modifie légèrement la lambda de migration (point 7 du schéma). Désormais, cette lambda peut récupérer la dernière ID de la table de destination, et ne migre que les lignes de la table source ayant un ID supérieur. Pour garder un fonctionnement normal lors de la première migration, tout le système fonctionne sur deux modes:
- INITIAL: migration initiale, pas de filtre, on migre les tables “telles quelles”
- INCREMENTAL: migration des nouvelles données uniquement
Et si je veux répercuter des modifications sur mes données entre deux migrations ?
Les données concernées par cette migration ne subissent que très rarement des modifications. Evidemment, le besoin peut changer dans le futur: il faut pouvoir y répondre. Et ca tombe bien: pour ce cas particulier, DMS a aussi une solution !
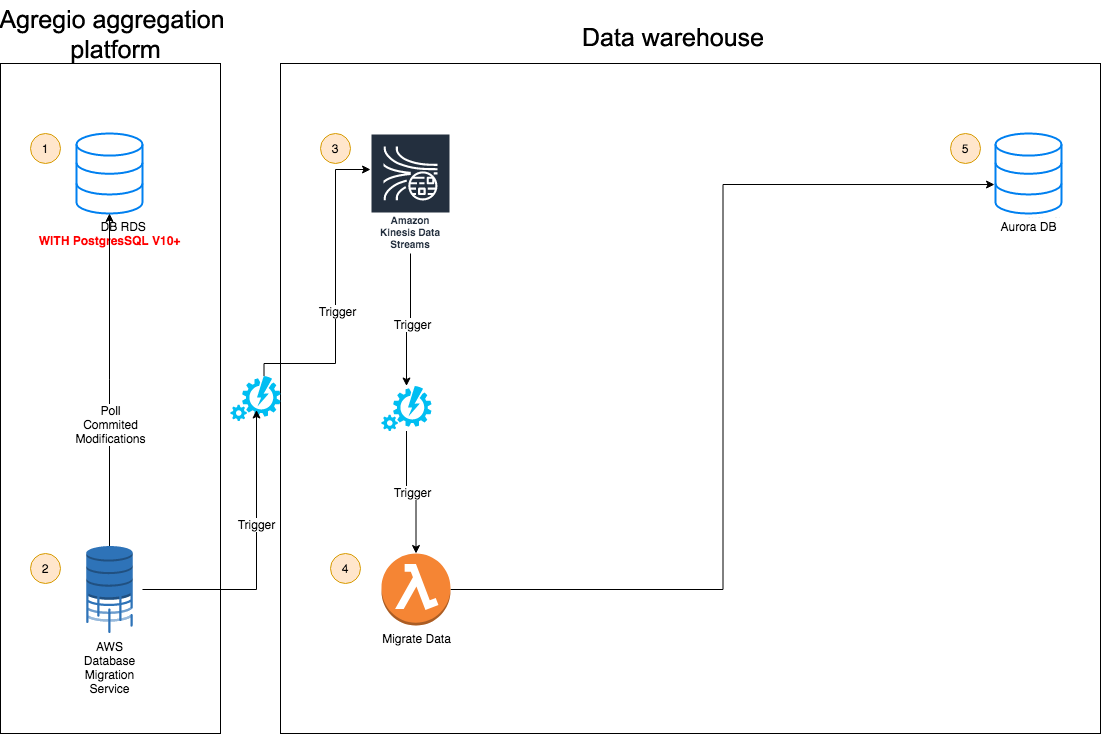
Nous avons parlé jusqu’alors des migrations ponctuelles de tables entières (ou avec filtre), mais pas des migrations en temps réel. Dans cette approche, DMS permet de récupérer les commit logs d’une base de données source, pour les dispatcher dans un autre service.
Dans la solution étudiée, les commit logs (JSON) sont envoyés dans une flux kinesis datastream, puis, la lambda Migrate Data récupère les records Kinesis, et est responsable d’insérer, mettre à jour, ou supprimer les données dans la base cible de l’entrepôt de données.
Facturation des producteurs d' énergie renouvelable ou ma lambda ne manque pas d’R
Agregio a défini un processus de facturation pour les producteurs, le fichier de facturation complété par les producteurs est réceptionné par Agregio et doit être traité tous les mois dans le système d’information.
Afin de répondre à ce besoin, l’utilisation d’une architecture serverless a été choisie dans une optique de flexibilité et de maîtrise des coûts.
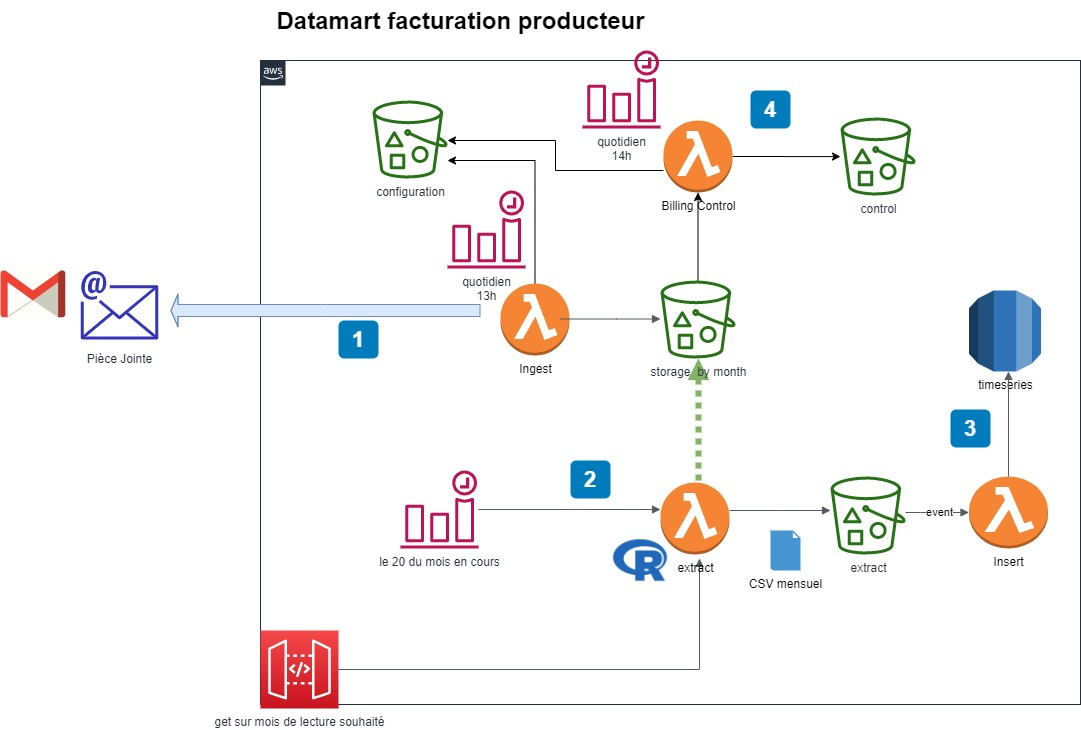
- Chaque jour, la lambda ingest récupère les fichiers et les stocke dans le bucket S3 storage.
- En fin de mois, la lambda extract effectue un traitement complexe (algorithme en R spécifique développé par une data scientist de l’équipe).
- Le résultat de cette extraction est inséré en base de données par la lambda insert.
- La lambda billing Control est également exécutée quotidiennement pour effectuer une opération de contrôle métier.
Point technique sur la lambda extract:
L’algorithme fourni par la data scientist est implémenté en R. Ce langage n’est pas supporté nativement par les lambdas. Nous devons ajouter un custom runtime spécifique R (provided dans la console AWS).
Pour séparer la fonction du runtime, le layer 1 contenant le runtime R est créé ainsi que les layers 2 et 3 embarquant des packages R supplémentaires importés par l’algorithme.

Le layer runtime R est un fichier zippé (tout comme les layers des packages R) avec l’arborescence suivante :
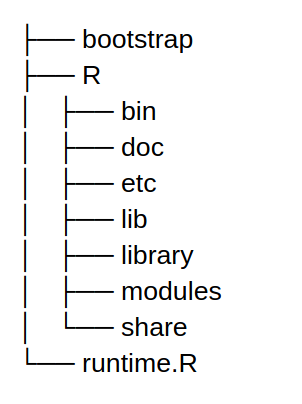
En deux mots, le fichier bootstrap permet de récupérer l’event, extraire le requestID, puis exécuter la fonction en R en exécutant runtime.R et envoyer le résultat à l’API lambda.
Prévision hydraulique
Un autre use-case est de générer des prévisions de production (hydraulique dans notre cas) à partir de données techniques de certains sites de production et en stockant le tout dans un datamart.
Ces données sont utilisées en entrée d’un algorithme de machine learning développé par les data scientists.
Avant d’être opérationnel, cet algorithme doit s’entraîner à partir d’une certaine quantité de données choisie par le data scientist, c’est la phase d’entraînement (ou apprentissage). Une fois l’entraînement terminé, il est possible de générer un modèle à partir duquel il est possible de prédire les futurs productions, c’est la phase d’inférence.
Quelles solutions ont été choisies ?
Pour la partie stockage, nous avons décidé de mettre en place un micro-service Spring Boot qui fait l’appel au partenaire périodiquement pour stocker les mesures, et invoque l’algorithme de prévision à une certaine fréquence.
Pour la partie algorithme, le service SageMaker d’AWS pilote les phases de l’entraînement à l’inférence. Dans notre cas, le modèle entraîné est fourni par le data scientist. L’avantage de SageMaker est de pouvoir faire un déploiement automatique du modèle entraîné via un script CloudFormation ainsi que du endpoint qui permet de faire appel à l’algorithme et également de réentraîner le modèle en cas de besoin. L’endpoint déployé est de la forme:
https://runtime.sagemaker.xx-yyyyy-z.amazonaws.com/endpoints/hydro/invocations.
L’appel à cet endpoint se fait dans le microservice via un client Feign.
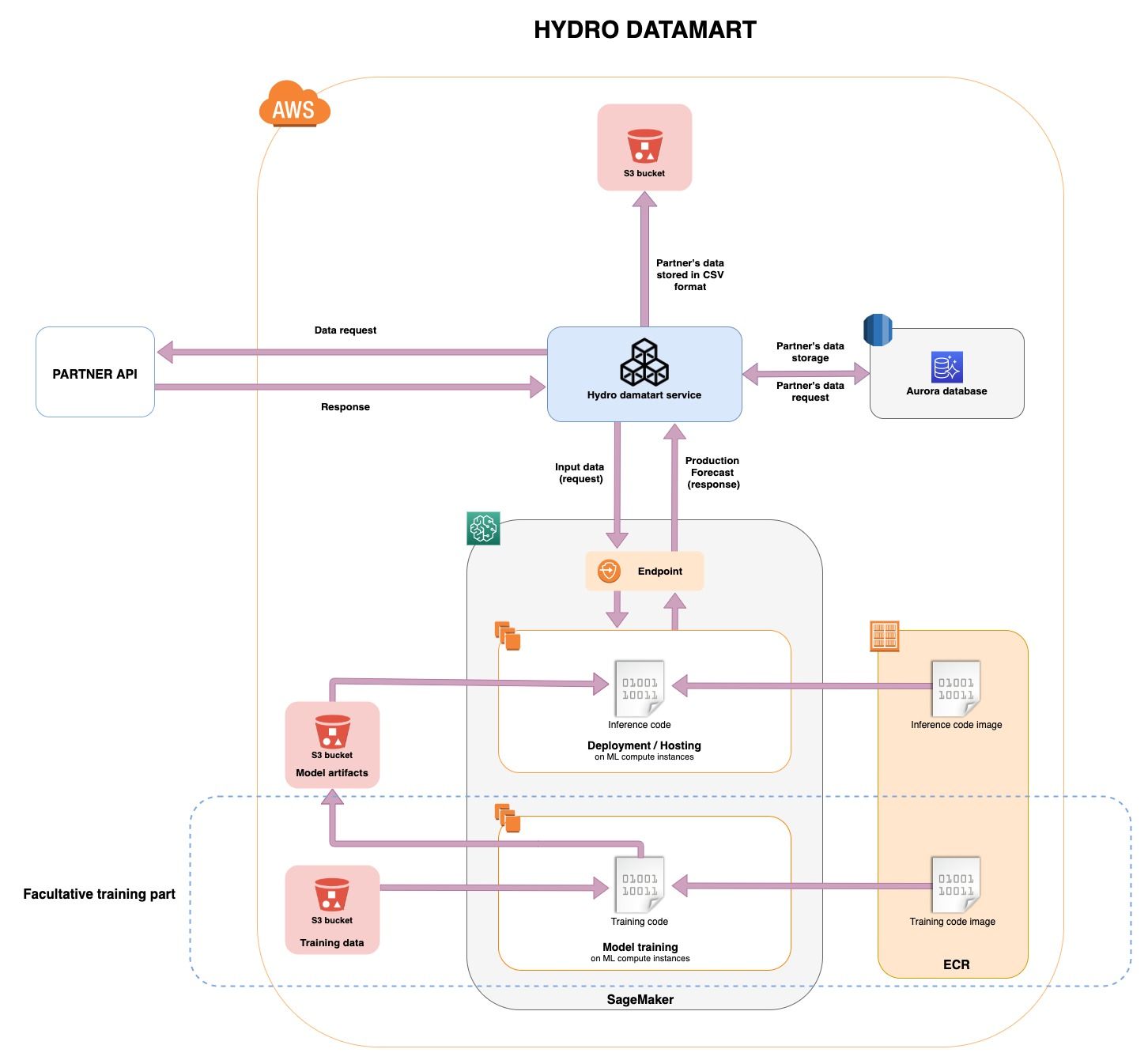
Quelles sont les étapes de déploiement de l’algorithme ?
- Déploiement de l’image Docker contenant le code d’entraînement et les entrées nécessaires sur ECR (étape facultative, script bash)
- Déploiement de l’image Docker contenant le code d’inférence sur ECR
- Création d’un modèle (ressource AWS SageMaker)
- Création d’une configuration d’endpoint (pour dire au endpoint de pointer sur le modèle que l’on veut utiliser)
- Création du endpoint
Tout est déployable automatiquement sauf la partie entraînement qui n’est pas disponible directement dans les scripts Cloudformation. Il est toutefois possible de le faire via des solutions comme celle-ci https://github.com/aws-samples/aws-sagemaker-build qui se base sur des events S3 et lance un training job à chaque fois que des données d’entraînement sont ajoutées à un bucket par exemple. Dans notre cas, la fréquence d’entraînement du modèle ne nécessite pas une automatisation.
Attention aux coûts !
Les instances EC2 utilisées pour la partie training et inférence ont leur propre grille tarifaire que vous pouvez retrouver ici: https://aws.amazon.com/sagemaker/pricing/.
Pour vous donner un ordre d’idée, derrière l’endpoint mis à disposition par SageMaker pour notre algorithme, nous avons une machine ml.t2.large qui est une des plus petites machines disponible et qui coûte 0.1299$ par heure soit 3.11$ par jour, 21.77$ par semaine et environ 87$ par mois. C’est le prix à payer pour un seul endpoint !
De plus, il est impossible d’éteindre cet EC2 lorsque l’on décide de ne pas l’utiliser pendant une certaine période, sans supprimer l’endpoint. Le prix est donc à prendre en considération avant d’utiliser cette solution.
Conclusion
Ce post a démontré l’usage pertinent et la prise en main de nombreux services managés AWS orientés data et machine learning pour la création d’un entrepôt de données. L’architecture serverless a permis de développer un nouveau service back office avec agilité.
Nous remercions également Agregio pour la confiance dans nos choix de conception.
Nous espérons que la lecture de ce retour d’expérience, partagé par l’équipe Ippon travaillant sur ce produit, a été bénéfique pour le lecteur.