

ClickHouse, abrégé CH, est une base de données distribuée orientée colonnes (DBMS). Elle permet d’effectuer des traitements analytiques (OLAP) rapides sur de grandes quantités de données.
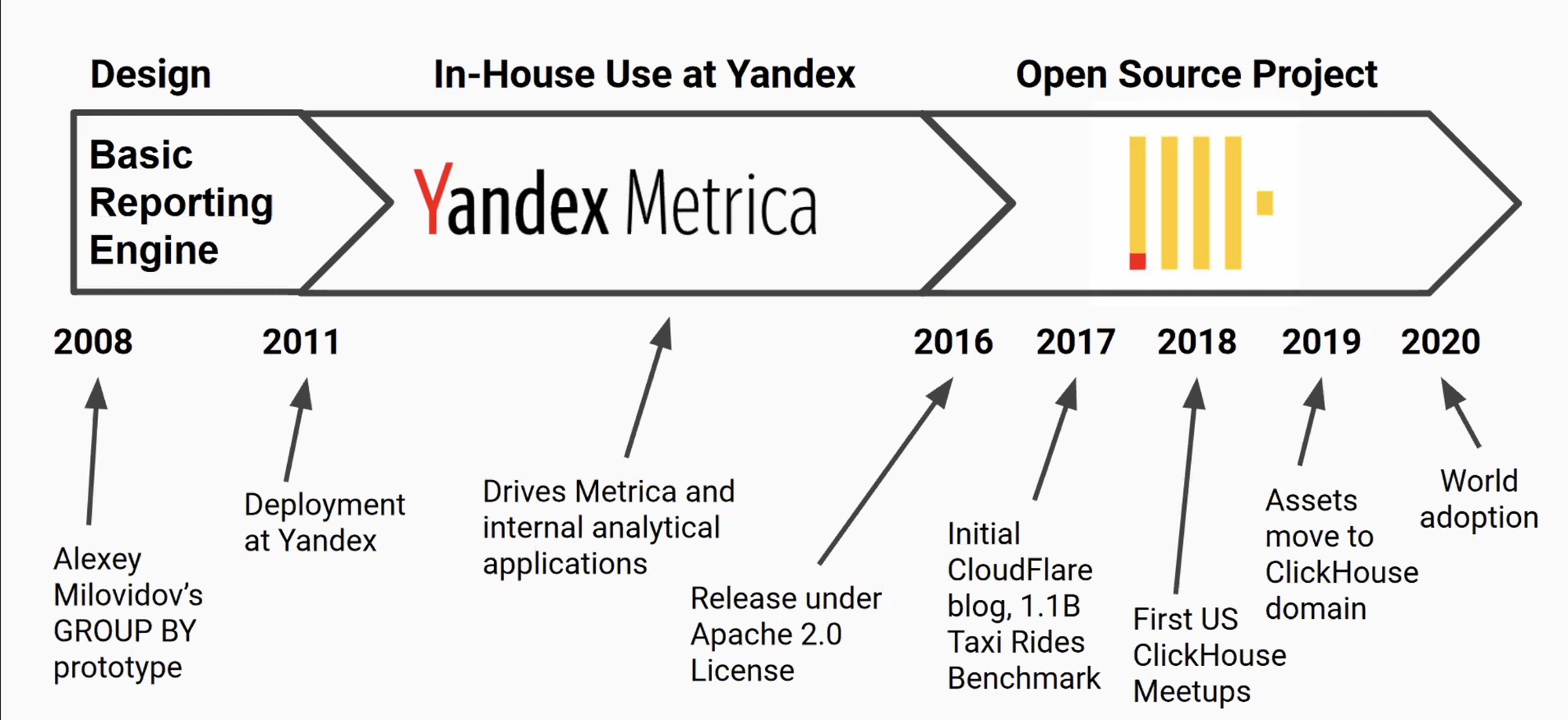
Le projet a été publié sous forme de logiciel libre sous les termes de la Licence Apache 2.0 en juin 2016. ClickHouse est développée en C++ par la société russe Yandex. Initialement, CH a été conçue pour réaliser des traitements de requêtes d’analytiques en moins d’une seconde et se voit bien rentrer en concurrence avec des Data Warehouses dans le Cloud comme AWS Redshift et aussi Druid.
Use Cases
ClickHouse est plus appropriée pour des cas d’usages analytiques sur de grandes quantités de données et l’ingestion des données en temps réel. Il n'est pas souhaitable de l'utiliser comme principale base de données transactionnelle (OLTP). ClickHouse ne trouve pas son intérêt pour des usages avec des grandes fréquences de suppression et de mises à jour des données. La solution est conçue pour répondre à des besoins de scalabilité et de vélocité dans le chargement et d’interrogation des données à des fins des traitements analytiques.
Déploiement
ClickHouse se déploie parfaitement dans le Cloud, mais aussi dans vos propres datacenters, ce qui fait la force de cette solution. Le déploiement sur l'orchestrateur de conteneurs Kubernetes est aussi possible par l'utilisation de l’Operator Kubernetes ClickHouse développé par la société Altinity.
Quelques caractéristiques de ClickHouse
Les principales caractéristiques de ClickHouse sont :
- Organisation et stockage des données en colonnes ;
- Parallélisation et vectorisation des exécutions de requêtes ;
- La vectorisation consiste en une forme de batching de traitement des données au niveau du CPU (registre). Sur certaines architectures CPU qui supportent SIMD (Single Instruction Multiple Data), une même opération peut être exécutée simultanément sur des données. Initialement, cette opération manipule des paires de valeurs de type primitif. La vectorisation permet d’effectuer une même opération sur des paires de vecteurs, ce qui multiplie l’exécution par la dimension du vecteur.
- Scalabilité horizontale et verticale à travers l’utilisation de l’opérateur kubernetes ;
- Partitionnement des données en plusieurs “parts” ou “shards”. Les requêtes seront donc plus performantes par la répartition de la charge sur les noeuds ;
- Compression des données par défaut. Les données occupent donc moins d’espace sur disque et cela réduit par conséquent les entrées/sorties disque ;
- Capacité à effectuer des calculs très rapides en moins d'une seconde ;
- Prise en charge de SQL. ClickHouse prend en charge un langage étendu proche de SQL qui inclut les tableaux et les structures de données imbriquées, les approximations ainsi que les fonctions URI, Géographique ;
- Utilisation du stockage en plusieurs volumes (Fig. 1) dont chacun contient plusieurs devices et la capacité de transférer automatiquement des données entre eux (multi-tiering) ;
- Capacité de mise en oeuvre en multi-datacenter.
Organisation des données
Les données dans ClickHouse sont organisées en tables avec des schémas bien définis. Ces tables sont réparties sur plusieurs serveurs. Les tables sont stockées physiquement sur plusieurs parties (Parts) qui ne sont rien d’autre que des répertoires dans le système de fichiers, ces répertoires contiennent un fichier index et d’autres fichiers pour la description des colonnes.
IStorage représente l'interface commune pour toutes les tables dans ClickHouse. Différentes implémentations de cette interface sont fournies. Chaque implémentation correspond à un type de table, dit aussi moteur de table (Table Engine), qu'on doit préciser au moment de la création de la table. Le moteur de table détermine
- l'endroit où les données seront stockées,
- les requêtes supportées,
- l’accès concurrent aux données,
- si le multithreading lors des exécutions des requêtes est possible,
- si les indexes sont pris en charge,
- etc..
La principale famille de moteurs de table utilisée en production est le MergeTree qui permet le stockage résilient de grands volumes de données et prend en charge la réplication. Il existe également une famille Log pour le stockage léger de données temporaires et un moteur Distributed pour l'interrogation d'un cluster. Une autre famille concerne les moteurs d’intégration comme Kafka ou HDFS.
Compression de données
ClickHouse ne se contente pas que d'un stockage en colonnes des données, le Data Warehouse supporte aussi la compression des données sur disque. Les données occupent moins d’espace sur disque et ça réduit par conséquent les I/O ce qui améliore les performances d’exécution des requêtes. Les données sur disque sont compressées et encodées via LZ4 par défaut ou Zstd.
ClickHouse supporte d'autres méthodes de compression via l'encodage des données comme les algorithmes communs Dictionary, Delta, Double-Delta ou Gorilla. On trouve d’autres algorithmes spécifiques à CH comme T64.
Cette compression des données améliore la performance des exécutions des requêtes et permet de traiter plus rapidement des données qui ne tiennent pas en mémoire vive.
Architecture
Le système ClickHouse dans un système distribué, résilient et hautement disponible. L'architecture d'un cluster ClickHouse se compose d'un ensemble ZooKeeper pour le quorum et une liste de serveurs physiques ou virtuels (les "nodes") pour le stockage et la distribution des traitements. Les noeuds jouent le même rôle au sein du cluster, il n’y a pas de SPOF (Single Point Of Failure) du système. Je vous conseille la lecture de cet article qui présente une vue d’ensemble sur les architectures de systèmes distribués. Les données sont partitionnées en plusieurs "shards" et la réplication multi-master asynchrone est utilisée.
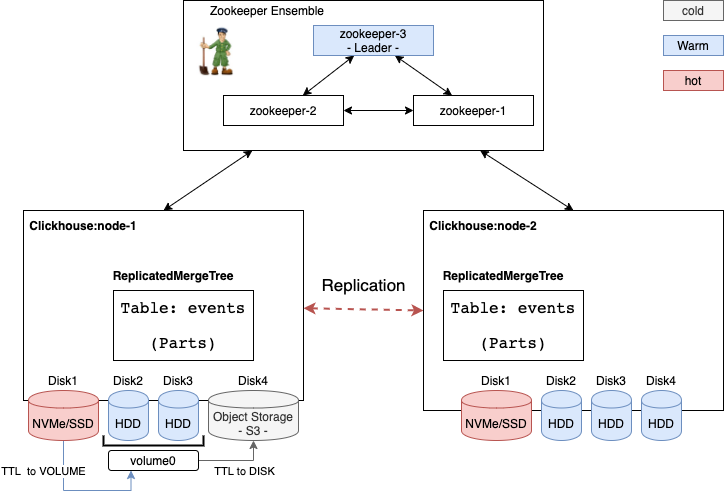
ZooKeeper est utilisé pour synchroniser les processus comme la réplication, mais ne participe pas aux traitements et à l’exécution des requêtes. Il maintient l'état du cluster et les métadonnées sur les tables et les colonnes, etc.
Le rôle de chaque noeud dans le cluster est à la fois le stockage et le traitement de données contrairement à d’autres Data Warehouse comme Snowflake qui séparent la couche stockage de la couche de traitement.
Chacun des noeuds dispose d’un ou plusieurs disques attachés avec des performances qui varient entre des disques rapides nVME/SSD ou des disques capacitifs HDD. CH configure le stockage des données via des “storage policies”, qui sont des fichiers XML. Dans une politique de stockage, les disques attachés aux serveurs sont organisés en volumes. CH propose la fonctionnalité TTL (Time-To-Live) pour transférer des donnés entres disques et volumes. Par exemple, on peut garder des données fraîches sur les disques rapides et graduellement les historiser lorsqu'elles deviennent de moins en moins utilisées vers des disques moins rapides.
Supprimer ces données après un certain temps de manière automatique est aussi possible via la fonctionnalité TTL.
Réplication
La réplication permet de garantir la durabilité et la haute disponibilité des données. Les données dans ClickHouse sont répliquées de manière asynchrone. Un avantage avec ClickHouse est que les données répliquées peuvent être automatiquement dé-dupliquées a posteriori. La réplication est supportée uniquement par les tables dans la famille MergeTree. Les tables sont partitionnées en plusieurs "shards", la réplication permet de créer des copies des "shards" sur d’autres serveurs. Les données sont écrites sur n'importe lequel des replicas disponibles, puis distribuées sur les replicas restants. Pour assurer le bon fonctionnement du processus de réplication, ClickHouse s'appuie sur ZooKeeper pour stocker les informations sur les leaders et les réplicas de chaque "shard". ClickHouse utilise la version 3.4.5 de ZooKeeper au minimum.Une particularité de ClickHouse concernant la réplication est qu'elle fonctionne et peut être configurée au niveau des tables et non pas comme un paramètre du cluster. Un serveur peut donc stocker en même temps des tables avec réplication activée et des tables sans réplication. Le facteur de réplication peut aussi être configuré par table.
Load balancing
Une fois que la table est configurée avec le moteur de table ReplicatedMergeTree et les données insérées, le moteur copie automatiquement les données sur toutes les réplicas. Cependant, tous les SELECT sont exécutés sur le serveur auquel le client est connecté.
Prenons l’exemple d’une table configurée avec trois réplicas. Le client envoie des requêtes à des serveurs où on trouve le réplica. Même si la réplication est activée, la répartition de charge n’est pas automatique et donc seul le serveur sollicité sera utilisé et deux restants ne feront généralement rien. Pour permettre l'équilibrage de la charge entre plusieurs réplicas, ClickHouse fournit le moteur distribué (Distributed Engine) au mécanisme interne d'équilibrage de la charge. Il équilibrera les demandes entre plusieurs réplicas en fonction de règles spécifiques ou de la configuration des préférences. Plusieurs politiques d’équilibrage de la charge sont offertes par ClickHouse : Random, Nearest Hostname, Round Robin.
Scalabilité
ClickHouse peut monter à l’échelle de plusieurs péta-octets de données. Les deux modes de scalabilité sont possibles, à savoir, une scalabilité verticale à travers le rajout des ressources matérielles (Disque, mémoire, CPU) et une scalabilité horizontale linéaire par l’extension du cluster avec des noeuds supplémentaires. Avec une architecture shared-nothing les noeuds ont le même rôle au sein du cluster.
La scalabilité horizontale n’est pas automatique, du moins pour le moment. Le déploiement de ClickHouse sur Kubernetes et la supervision technique peuvent faciliter la mise en place des mécanisme de scalabilité suivant les contraintes de nos projets.
Haute performance
CH assure le traitement rapide des requêtes et a démontré de très bonnes performances dans des use case analytiques avec des temps de réponses de moins d’une seconde.
CH a la capacité de traiter plusieurs péta-octets de données. Les données sont stockées sous un format compressé et seulement par colonnes, mais sont traitées par vecteurs (portions de colonnes).
Les calculs par approximation et l’échantillonnage sont gérés par ClickHouse. Les traitements de requêtes distribuées et parallèles sont disponibles (incluant les jointures).
Cette technique permet à ClickHouse de livrer de bonnes performances sur des grandes quantités de données.
CH pourrait utiliser toute la capacité CPU du cluster ou une partie pour la parallélisation des exécutions. CH peut utiliser 1 core ou tous les cores mis à disposition ou toute valeur entre les deux.
Quelques fonctionnalités de ClickHouse
Vues matérialisées
Après cette présentation de ClickHouse, cette section présente quelques fonctionnalités intéressantes comme la prise en charge des vues et des vues matérialisées. Les vues matérialisées stockent les données transformées par la requête SELECT correspondante. La requête SELECT peut contenir DISTINCT, GROUP BY, ORDER BY, LIMIT, etc.
Les vues matérialisées permettent de calculer des agrégats, de lire des données de Kafka et de réorganiser les index primaires des tables et l'ordre de tri. Au-delà de ces capacités fonctionnelles, les vues matérialisées s'adaptent bien à un grand nombre de nœuds et fonctionnent sur de grands ensembles de données. Elles constituent une des caractéristiques de ClickHouse.
Indexes
ClickHouse prend en charge les index sur les clés primaires. Le mécanisme d'indexation est appelé index “sparse”. Dans le MergeTree, les données sont triées par clé primaire lexicographiquement dans chaque partie. Ensuite, ClickHouse sélectionne quelques marques pour chaque Nième ligne, où N est choisi de manière adaptative par défaut. Cette technique d’indexation permet d'effectuer des recherches efficaces par plage.
S’interfacer avec ClickHouse
CH fournit de multiples interfaces utilisateur, notamment une interface HTTP, un driver JDBC, une interface TCP, un client en ligne de commande.
ClickHouse pour le Machine Learning
L’apprentissage automatique est l’un des domaine qui reçoit des intentions particulière par plusieurs acteurs. ClickHouse s’inscrit dans ce domaine comme une source de données rapide. Les équipes de ClickHouse ont mis aussi en place le support des algorithmes ML, ce qui rend l'exécution de ML sur les données ClickHouse beaucoup plus facile et rapide. Ils ont commencé avec l'algorithme open source Yandex CatBoost, mais il peut être étendu avec d'autres algorithmes dans le futur. Voici un article publié sur le sujet qui démontre la façon dont ClickHouse peut être utilisé pour exécuter les modèles CatBoost.
Intégration
ClickHouse s’intègre à la plupart des solutions de visualisation du marché comme Tableau, Looker et Superset via les pilotes compatible JDBC et ODBC. Il s’intègre aussi avec d’autres technologies de la Data dont HDFS ou Kafka pour la collecte des données. La supervision de ClickHouse est possible par son intégration à de multiples outils open-source dont Grafana, Prometheus et Zabbix.
Prise en main
Après la présentation de ClickHouse, le moment est venu pour une prise en main rapide par l’installation, le chargement des données et l’exécution de premières requêtes.
ClickHouse installation
Lors de l’installation sur une distribution Ubuntu, un message est affiché pour demander de saisir un mot de passe pour l’utilisateur par défaut (utilisateur = default). Nous avons choisi le mot de passe (admin).
sudo apt-get update -y
sudo apt-get install dirmngr -y
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv E0C56BD4
echo "deb http://repo.clickhouse.tech/deb/stable/ main/" | sudo tee \
/etc/apt/sources.list.d/clickhouse.list
sudo apt-get update -y
sudo apt-get install clickhouse-server clickhouse-client -y
# Entrer un mot de passe (e.g. admin )
Démarrage de service
sudo service clickhouse-server start
Vérifier la version
clickhouse-client --password admin --user default --query='SELECT version()'
Création de la base de données
Le nom de la base de données à créer est “demo”.
clickhouse-client --password admin --user default --format_csv_delimiter="," --query="CREATE DATABASE IF NOT EXISTS demo"
Définition de table
clickhouse-client --password admin --user default
CREATE TABLE demo.events
(
`antiNucleus` Int8,
`eventFile` Int64,
`eventNumber` Int8,
`eventTime` Float32,
`histFile` Int64,
`multiplicity` Int8,
`NaboveLb` Int8 ,
`NbelowLb` Int8,
`NLb` Int8,
`primaryTracks` Int8,
`prodTime` Float32,
`Pt` Float32,
`runNumber` Int8,
`vertexX` Float32,
`vertexY` Float32,
`vertexZ` Float32
)
ENGINE = MergeTree()
PRIMARY KEY eventTime
PARTITION BY eventTime
ORDER BY (eventTime)
ENGINE = MergeTree() : indique comment les données et les requêtes sont gérées.
PARTITION BY eventTime : indique comment les données seront partitionnées.
ORDER BY (eventTime) : indique comment indexer et ordonner les données dans chacune des parties.
Après la définition des colonnes, vous spécifiez MergeTree comme moteur de stockage pour la table. La famille de moteurs MergeTree est recommandée pour les bases de données de production en raison de sa prise en charge optimisée des grandes insertions en temps réel, de sa robustesse globale et de sa prise en charge des requêtes. En outre, les moteurs MergeTree prennent en charge le tri des lignes par clé primaire, le partitionnement des lignes, ainsi que la réplication et l'échantillonnage des données.
Si vous avez l'intention d'utiliser ClickHouse pour archiver des données qui ne sont pas souvent interrogées ou pour stocker des données temporaires, vous pouvez utiliser la famille de moteurs Log, optimisée pour ce cas d'utilisation.
Vous pouvez définir d'autres options au niveau de la table. La clause PRIMARY KEY définit eventTime comme la colonne clé primaire et la clause ORDER BY stockera les valeurs triées par la colonne eventTime. Une clé primaire identifie de manière unique une ligne et est utilisée pour accéder efficacement à une seule ligne et à une colocation efficace des lignes.
Préparation et chargement des données
sudo wget http://sdm.lbl.gov/fastbit/data/star2002-full.csv.gz
sudo zcat star2002-full.csv.gz > star2002-full.csv
sudo rm star2002-full.csv.gz
clickhouse-client --password admin --user default --format_csv_delimiter="," --query="INSERT INTO tutorial.events FORMAT CSV" < star2002-full.csv
clickhouse-client --password admin --user default --query="select count(*) from demo.events"
Interrogation de ClickHouse
Exemple de requêtes
clickhouse-client --password admin --user default --query="select count(*) from demo.events"
# Se connecter à clickhouse
clickhouse-client --password admin --user default-
clickhouse-client --password admin --user default
use demo;
SELECT count(*) FROM events
SELECT count(*) FROM events WHERE eventNumber > 1
SELECT count(*) FROM events WHERE eventNumber > 20000
SELECT count(*) FROM events WHERE eventNumber > 500000
SELECT eventFile, count(*) FROM events GROUP BY eventFile
SELECT eventFile, count(*) FROM events WHERE eventNumber > 525000 GROUP BY eventFile
SELECT eventFile, eventTime, count(*) FROM events WHERE eventNumber > 525000 GROUP BY eventFile, eventTime ORDER BY eventFile DESC, eventTime ASC
Conslusion
Nous sommes convaincus que cette technologie présente de nombreux avantages en comparaison à des Data Warehouses dans le Cloud en terme de sa rapidité, son coût et sa scalabilité. ClickHouse a démontré de très bonnes performances dans des cas d’usages analytiques et ses domaines d’application ne cessent de grandir : gestion de logs, finance, e-commerce, timeseries, etc. ClickHouse a de grandes capacité d'ingestion et se comporte parfois mieux qu'un influxDB (pas dans l'absolu). Voici une comparaison de ClickHouse, InfluxDB et TimeScaleDB.
On trouve des comparaisons avec d’autres Data Warehouses dans le Cloud (Redshift vs ClickHouse), et cela démontre des gains intéressants de performance et de coût.
Des nouvelles fonctionnalités sont dans le roadmap comme la séparation du stockage et du compute avec S3 à partir de la version +20.6. L’ajout d’un autre mode d’indexation dit “compact vs sparse” qui rend cette fonctionnalité possible, et plein de mises à jour sur les performances et de nouvelles capacités d’intégration.
Pour aller plus loin
- Documentation Officielle : https://clickhouse.tech/docs/en/
- Blog Altinity : https://altinity.com/blog/
- Intégration avec ClickHouse : ici
- Tabix - SQL Editor & Open source simple business intelligence for ClickHouse. ici
- Should You Use ClickHouse as a Main Operational Database? ici
- Analytics at Speed: Introduction to ClickHouse and Common Use Cases. ici
- ClickHouse vs Amazon RedShift Benchmark, ici
- ClickHouse pour le timeseries ici