

En mars 2019, la société américaine Prefect annonçait la mise à disposition en open source de son nouveau système d'automatisation et de planification de workflows, Prefect Core. Au bout d'un an seulement, la société franchit de nouveau une étape importante avec le lancement de Prefect Cloud, une offre payante dédiée aux entreprises incluant une couche supplémentaire d'orchestration complète et managée, ainsi qu'une interface utilisateur de surveillance semblable à Airflow UI. Ce projet est le fruit d'un travail collaboratif ayant réuni de nombreux métiers en vue de couvrir un maximum de cas d'usage et de réduire les frictions fondamentales qui existent dans les architectures data modernes. Aujourd’hui, Prefect s’impose comme une meilleure alternative à Airflow : cela vaut donc la peine de l’essayer !
As a result, at launch, Prefect is already the easiest, most powerful, and best-tested open-source workflow engine.
The Prefect Blog

Introduction
Le projet Prefect est un framework d’automatisation de workflow développé en Python permettant de construire, automatiser, gérer et exécuter des data pipelines robustes sous forme de code. L'outil est né du constat qu'une grande majorité de data engineers et de data scientists nécessitait du support technique pour résoudre des problèmes liés à l'utilisation de Apache Airflow, l'outil open source le plus utilisé sur ce segment de marché. Bien qu'il soit parfaitement adapté pour exécuter des successions de tâches statiques selon un calendrier préétabli, l’utilisation de Airflow peut vite devenir laborieuse en essayant de forcer l'adaptation de son modèle à nos cas d'utilisation. Nous pouvons citer comme exemple la création de DAGs (Directed Acyclic Graphs) avec une logique de branchements complexe ou qui reposent sur l'échange de données, sur lequel je reviendrai.
Comme l’a dit très justement Jeremiah Lowin, CEO et fondateur de Prefect, une des difficultés à laquelle sont confrontés les data engineers est de parvenir à écrire du code robuste et défensif de manière à anticiper les défaillances possibles. C'est la définition même du negative data engineering. À l'inverse, le positive data engineering consiste à écrire du code pour être exécuté et atteindre un objectif sans se soucier de sa robustesse. Prefect vise justement à soulager les data engineers de cette charge d'ingénierie négative souvent chronophage et rébarbative.
Cette suite d'articles a pour but non pas de lister les bonnes pratiques pour mener un projet Prefect en production mais de montrer comment l'outil parvient à combler les faiblesses de Airflow à travers ses fonctionnalités et sa logique d'implémentation.
Prefect Core
Avant d'installer Prefect, assurez-vous d’avoir sur votre instance locale une version égale ou ultérieure à Python 3.6. Il vous suffit alors de lancer la commande suivante avec votre installateur de package préféré pour Python :
pip3 install prefectCréation d'une tâche
Par définition, une tâche représente une action discrète dans un workflow et a pour objectif de produire un résultat. La façon la plus simple de créer une tâche dans Prefect à partir d’une fonction Python personnalisée est d’utiliser le décorateur @task. Il s'agit de l'API fonctionnelle. Cette dernière s’avère très utile pour déclarer des tâches qui se comportent comme des fonctions, mais également pour construire de manière naturelle et pythonique un graphe de tâches :
from prefect import task
from prefect.tasks.core.function import FunctionTask
@task
def hello_world():
print("Hello World!")
# roughly equivalent to:
FunctionTask(fn=lambda x: print("Hello World!"))
Les tâches peuvent également s'écrire sous forme de classes héritant de prefect.core.task.Task pour une meilleure personnalisation et un meilleur contrôle de votre flux. En général, l'API impérative est utilisée pour spécifier des dépendances de tâches plus complexes. Cette API sera plus familière aux développeurs ayant l’habitude d'utiliser Airflow.
from prefect.core.task import Task
class HelloWorld(Task):
def __init__(self, name, **kwargs):
self.name = name
def run(self):
print("Hello {}!".format(self.name))
Ces personnes remarqueront d’ailleurs que Prefect nous épargne l'utilisation obligatoire du PythonOperator pour décrire les tâches représentant des fonctions Python arbitraires. Cependant, la syntaxe de création de tâches plus courantes comme l'exécution d'une commande Bash ou encore l'upload de données vers un bucket Amazon S3 est similaire à celle de Airflow. Prefect propose une bibliothèque de tâches très complète qui inclut des implémentations et des intégrations de tâches pour que vous puissiez facilement interagir avec vos applications externes (K8s, AWS, Docker, Snowflake...).

Lancement d'un premier flux
Pour lancer un workflow de plusieurs tâches successives, il est nécessaire dans un premier temps d'initialiser le flux qui va permettre de définir les dépendances de vos tâches ainsi que leurs données. Les lignes de code suivantes illustrent un exemple de déclaration de flux sous la forme d'un simple ETL (Extract Transform Load) :
from prefect import Flow, task
@task
def extract():
return [1, 2, 3]
@task
def transform(x):
return [i * 10 for i in x]
@task
def load(y):
print("Received y: {}".format(y))
with Flow("My first ETL") as flow:
e = extract()
t = transform(e)
l = load(t)
flow.run()
Nous noterons que l’exécution locale du workflow n’est effective qu’au moment où nous faisons appel à la méthode flow.run(). Avant cette étape, aucune tâche n’est exécutée puisque Prefect effectue uniquement la résolution des dépendances entre les tâches et la construction du graphique d’exécution, plus connu sous le nom de DAG dans Airflow. Résultat final : aucune ligne de code supplémentaire n’est nécessaire pour construire un workflow avec Prefect.
Nous pouvons ainsi d’ores et déjà tester notre flux manuellement à l’aide d’une simple exécution du script, sans avoir à lancer des services dépendants comme c’est le cas avec Airflow. En effet, avant de pouvoir exécuter une instance de DAG avec Airflow, il faut préalablement instancier un scheduler et initialiser une base de données backend. Dans le cas présent, nous n’avons à aucun moment besoin de démarrer des services externes pour exécuter notre programme. Voici le résultat de l’exécution :
[2020-05-25 15:00:14] INFO - prefect.FlowRunner | Beginning Flow run for 'My first ETL'
[2020-05-25 15:00:14] INFO - prefect.FlowRunner | Starting flow run.
[2020-05-25 15:00:14] INFO - prefect.TaskRunner | Task 'extract': Starting task run...
[2020-05-25 15:00:14] INFO - prefect.TaskRunner | Task 'extract': finished task run for task with final state: 'Success'
[2020-05-25 15:00:14] INFO - prefect.TaskRunner | Task 'transform': Starting task run...
[2020-05-25 15:00:14] INFO - prefect.TaskRunner | Task 'transform': finished task run for task with final state: 'Success'
[2020-05-25 15:00:14] INFO - prefect.TaskRunner | Task 'load': Starting task run...
Received y: [10, 20, 30]
[2020-05-25 15:00:14] INFO - prefect.TaskRunner | Task 'load': finished task run for task with final state: 'Success'
[2020-05-25 15:00:14] INFO - prefect.FlowRunner | Flow run SUCCESS: all reference tasks succeededÉchange de flux de données
Dans le scénario précédent, nous remarquons qu’avec l’API fonctionnelle de Prefect, l’échange de flux entre les différentes tâches s’effectue de manière simple et intuitive : ces dernières reçoivent des données en entrée et retournent des résultats en sortie. Rien de bien sorcier à cela, étant donné que nous manipulons des fonctions pures. Cependant, cette conception permet au moteur Prefect de gérer de manière complètement transparente les dépendances entre les tâches tout en garantissant un stockage en mémoire sécurisé et privatif des données qui transitent.
Sous Airflow, cette fonctionnalité d’échange de messages est connue sous le nom de XComs (abréviation de « cross-communication ») et a été conçue dans le but d’échanger uniquement des blocs de métadonnées et non des données. Cette spécificité s’explique par le fait que les valeurs sont écrites dans la base de métadonnées de Airflow sous forme de BLOB (Binary Large Object) avec une taille limitée (1 Go par défaut avec SQLite). Outre cela, les valeurs insérées ont une durée de vie illimitée si aucune action de purge n’est faite de votre part. Je vous laisse donc imaginer les conséquences que cela pourrait engendrer en termes de performance si vos tâches échangent à chaque étape un dataframe de 10 Go.
cid name type notnull dflt_value pk
---------- ---------- ---------- ---------- ---------- ----------
0 id INTEGER 1 1
1 key VARCHAR(51 0 0
2 value BLOB 0 0
3 timestamp DATETIME 1 0
4 execution_ DATETIME 1 0
5 task_id VARCHAR(25 1 0
6 dag_id VARCHAR(25 1 0Enfin, l’implémentation des flux de données avec les XComs est souvent source de bugs puisque la déclaration des relations est complètement dissociée de la déclaration des dépendances de données. Par exemple, si une tâche B dépend d’une action « push » entreprise par une tâche A et que l’utilisateur ne définit pas explicitement la relation entre ces deux tâches, Airflow les exécutera dans un ordre aléatoire et ne saura pas quoi faire en cas d’échec.
Avec Prefect, les dépendances ne sont pas esquivées puisque les déclarations sont établies au même endroit. Évidemment, il existe des solutions pour contourner cette limitation, mais cela renforce néanmoins l’idée que Airflow n’est pas vraiment adapté à la construction de pipelines de données.
Pour appuyer mes propos, j’ai implémenté deux tâches push_task() et pull_task() qui se succèdent et qui échangent un dictionnaire, d’abord avec Airflow, puis avec Prefect :
def push_task(**kwargs):
return {"Firstname": "Hello", "Name": "World"}
def pull_task(**kwargs):
# nous sommes censes recuperer dans les kwargs la valeur qui a ete push par une tache push_task()
pulled_value = kwargs['ti'].xcom_pull(key=None, task_ids='push_task')
print("Received value: {}".format(pulled_value))
with DAG("xcom_dag", default_args=default_args, schedule_interval="@once", catchup=False) as dag:
push_task = PythonOperator(task_id="push_task", python_callable=push_task)
pull_task = PythonOperator(task_id="pull_task", python_callable=pull_task, provide_context=True)
# declaration de la relation : push_task() s execute en premier et pull_task() en deuxieme
push_task >> pull_task
@task
def push_task():
return {"Firstname": "Hello", "Name": "World"}
@task
def pull_task(pulled_value):
print("Received value: {}".format(pulled_value))
with Flow("XCom demo") as flow:
# declaration de la relation : push_task() s execute en premier et pull_task() en deuxieme
v1 = push_task()
pull_task(v1) # on passe directement la valeur v1 en arguments qui a ete retournee par push_task()Planification
N’oublions pas que l’une des caractéristiques fondamentales d’un gestionnaire de workflow est de pouvoir lancer l’exécution d’un flux à n’importe quel moment et à un intervalle régulier. Prefect fournit justement un objet versatile configurable qui, une fois associé à votre flux, vous permet de planifier son exécution dans le temps. En fonction des paramètres fournis, la planification peut être complexe et détaillée afin d’ajuster subtilement le calendrier d’exécution. L’objet Schedule se compose des trois éléments suivants :
clock: responsable de l’émission des événements selon la fréquence paramétrée ;filters: décident si un événement doit être inclus ou non ;adjustments: permettent de modifier des événements filtrés.
En utilisant cet objet, nous parvenons ainsi à définir facilement un calendrier avec un comportement complexe :
schedule = Schedule(
clocks=[IntervalClock(timedelta(hours=1))],
filters=[is_weekday],
or_filters=[
between_times(pendulum.time(9), pendulum.time(9)),
between_times(pendulum.time(15), pendulum.time(15)),
],
not_filters=[between_dates(1, 1, 1, 31)],
adjustments=[next_weekday]
)
with Flow("Schedule demo", schedule=schedule) as flow:
...Le flux défini ci-dessus se lancera uniquement à partir de la semaine prochaine et seulement en semaine à toutes les heures entre 9 heures et 15 heures excepté au mois de janvier.
Workflows dynamiques
L’une des autres fonctionnalités intéressantes de Prefect est la création de workflows parallèles dynamiques que l’on appelle également « task mapping ». Cela s’avère très pratique et efficace lorsque vous souhaitez répéter l’exécution d’une tâche sans connaître préalablement le nombre de répétitions. Par exemple, imaginez une tâche A qui effectue une requête à une table client d’une base de données afin de récupérer la liste de tous les nouveaux clients, et une tâche B qui envoie un email de bienvenue à chaque client de cette liste. À partir de là, chaque enregistrement doit être envoyé dans une tâche qui envoie l’email pour chaque nouveau client. Pour se faire, il suffit simplement de « mapper » la tâche d’envoi d’email à la liste des nouveaux clients et Prefect créera automatiquement une copie de la tâche pour chaque élément de cette liste :
class SendEmailTask(EmailTask):
def run(self, customer, **kwargs):
super().run(
subject="Test Mapping",
msg="Welcome {} {}".format(customer[1], customer[2]),
email_to=customer[3],
email_from="notifications@prefect.io",
**kwargs)
with Flow("Prefect mapping example") as flow:
customers = SQLiteQuery("prefectDB.db").run(query="SELECT * FROM customers
WHERE new_customer=1")
SendEmailTask().map(customers)
with prefect.context(secrets=dict(EMAIL_USERNAME=GMAIL_CREDS["username"], EMAIL_PASSWORD=GMAIL_CREDS["password"])):
flow.run()L’implémentation de ce même cas d’usage avec Airflow n’est pas aussi trivial puisque vous devrez transférer la liste de la tâche A vers la tâche B et itérer chaque élément de la liste dans cette seule et même tâche. Si l’exécution de l’un des enregistrements échoue, vous comprendrez que c’est la tâche entière qui échoue. De ce fait, vous devez implémenter votre propre logique de reprise sur erreur idempotente afin de reprendre l’itération. Néanmoins, cela rend tout de même difficile le suivi des tâches via l’interface de Airflow pendant l’exécution.
Workflows paramétrés
En complément des workflows dynamiques, Prefect vous offre également la possibilité de définir des paramètres en entrée pour vos workflows et de pouvoir les modifier au moment de l’exécution en temps réel. Un exemple de scénario d’utilisation pourrait consister à créer un paramètre qui contient un code ISO de pays et de le fournir dans un workflow qui récupère en fonction de ce pays le nombre de personnes rétablies de la Covid-19, depuis une API. Une valeur par défaut pourrait être « FR » (code ISO de la France) pour les tâches planifiées, mais pourrait être modifiée lors des exécutions manuelles de flux pour des tests locaux par exemple. Un paramètre se déclare dans un objet de type Parameter (pouvant prendre une valeur par défaut) et peut être passé comme argument au moment de l’exécution d’un workflow :
with Flow("Parametrized flow") as f:
country = Parameter("country", default="FR")
cases = recovered_people_by_country(country)
load(country, cases)
f.run(country="CA")
f.run(country="US")Le réel avantage de cette fonctionnalité est la capacité à lancer simultanément plusieurs instances de workflows ayant une logique d’activités communes avec des valeurs d’entrée différentes. De cette manière, vous pouvez configurer des workflows qui répondent aux évènements et leur faire suivre différentes branches en fonction du contenu de l’évènement.
Débogage et supervision en local
Un bon moyen de tester et vérifier rapidement la fiabilité de votre flux en local avant de le déployer est d’utiliser le paramètre run_on_schedule=False au moment de son lancement, c’est-à-dire lors de l’appel à my_flow.run(run_on_schedule=False). Cela exécutera le flux immédiatement et indépendamment de son calendrier d’exécution.
Notez que lorsque Prefect rencontre une erreur en exécutant un flux, son mécanisme de gestion des erreurs intercepte l’exception puis poursuit l’exécution. Rien d’extraordinaire à cela puisqu’il agit de la même manière qu’un bloc try… except. Cependant, il se peut que parfois nous ne souhaitions pas que les exceptions soient interceptées mais au contraire levées afin de pouvoir générer les erreurs au moment où elles se produisent et ainsi stopper l’exécution. Pour ce faire, Prefect fournit un gestionnaire de contexte raise_on_exception pour lever les exceptions en temps réel :
from prefect import Flow, task
from prefect.utilities.debug import raise_on_exception
@task
def div(x):
return 1 / x
@task
def add(y):
return 1 + y
with Flow("My Flow") as my_flow:
res_div = div(0)
res_add = add(res_div)
with raise_on_exception():
state = my_flow.run() # raises ZeroDivisionError and `add` task will not be executed
my_flow.visualize(flow_state=state) # flow visualization (will open new window)Outre le débogage du flux via la stack trace générée par Prefect, les erreurs dans les dépendances de tâches ainsi que les statuts peuvent être supervisés et visualisés sous la forme d’un graphe orienté acyclique. Les noeuds du graphe correspondent aux tâches et sont labellisés par le nom de la tâche correspondante. Les arêtes représentent quant à elles les dépendances et sont labellisées par le nom de l’argument sous-jacent si des données sont transmises. Cela peut être utile pour comprendre les dépendances des tâches et éventuellement déboguer votre logique de branchement sans avoir à exécuter vos tâches. La figure ci-dessous est la représentation statique du diagramme de flux de l’exemple précédent (une fois l’exécution terminée) :
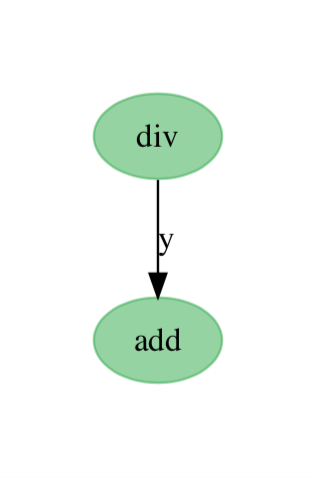
Les statuts des tâches individuelles sont représentés en couleur (ici, vert pour « SUCCESS »).
Et ce n’est pas fini…
J’aborde ici les fonctionnalités de Prefect Core pertinentes à cet article, mais il en existe beaucoup d’autres tout aussi intéressantes. Je vous invite donc à parcourir la documentation, que je trouve très claire.
Quoi de neuf ?
Le 14 mai 2020, les contributeurs de Prefect ont annoncé la sortie de la dernière version 1.0.11, marquant l’aboutissement des améliorations réalisées pour la création de workflows expressifs et complexes. Parmi les nouvelles fonctionnalités et les améliorations livrées avec cette version figurent :
- L’extension d’options pour interagir plus simplement avec les résultats des tâches avec davantage de possibilités pour l’utilisateur ;
- La mise en cache de tâches basées sur la présence de données persistantes ;
- La simplification d’utilisation des secrets déclarés dans les flux ;
- L’ajout d’une nouvelle API conditionnelle semblable à l’instruction if en Python permettant d’écrire de la logique conditionnelle au sein d’un flux.
Pour plus d’informations, je vous invite à lire l’article écrit par le fondateur de Prefect qui expose plus en détails ces améliorations.
Conclusion
Après avoir testé et parcouru les différentes fonctionnalités et possibilités offertes par Prefect Core, celui-ci semble très prometteur. L’outil parvient à simplifier la mise en place de data pipelines modernes aussi bien pour les data engineers que pour les data scientists afin de répondre à des cas d’usage dynamiques relatifs aux données, notamment grâce à ses APIs légères et user-friendly en Python. La sémantique des workflows popularisée par Airflow a aujourd’hui été adoptée par la plupart des data engineers et cette dernière a été reprise et développée par Prefect pour permettre la construction de pipelines robustes.
Dans la deuxième partie, je me pencherai sur la gestion et l’orchestration de workflows avec Prefect Cloud.
Références
Christopher White, Why not Airflow?, https://medium.com/the-prefect-blog/why-not-airflow-4cfa423299c4
Hendrik Pauthner, Prefect: Das zeitgemäße Airflow?, https://www.inovex.de/blog/prefect-das-zeitgemaesse-airflow/?fbclid=IwAR2Uv56QTXCTRjPtPm-wEFuJMTrVrtN3skYeIhBCPiep5rr86xTKcHUdAI8
