

Avec l'hégémonie annoncée du cloud computing, on voit de plus en plus d’architectures logicielles migrer vers ces infrastructures dont les défis ne se limitent finalement pas aux principes du manifeste 12-Factor Apps. Bien sûr, une application dite “cloud-native” se doit d’être modulaire, adaptable, résiliente, déployée en continu et supervisée… j’en oublie sans doute. Pourtant une dimension supplémentaire, presque cachée mais tributaire des caractéristiques déjà énoncées, s’impose bien au marché moderne des applications.
Cette dimension du Something “as-a-Service" ne date pas d’hier, mais elle reste difficile à aborder concrètement pour des développements basés sur les concepts datant de l’âge de l’évolutivité verticale, où l’augmentation de la puissance matérielle suffisait à répondre à une demande croissante. La mise à l’échelle horizontale, elle, implique toujours une refonte profonde de la gestion des ressources, avec la distribution des états et la gestion de leurs transitions au sein de services tiers : database, data-grid, message broker. Toutes ces solutions requérant une grande rapidité d’exécution et de solides mécanismes de synchronisation.
L’étape suivante consistera à fournir un produit suffisamment robuste pour proposer à la demande une expérience utilisateur complètement personnalisée, et dans une infrastructure entièrement mutualisée, afin de bénéficier d’économies d’échelle en exploitation. Les architectures multi-tenant, ou multi-entités, ou multi-locataires, sont censées réaliser cette promesse. Et nous allons tenter de voir quels sont les défis spécifiques à cette attente :
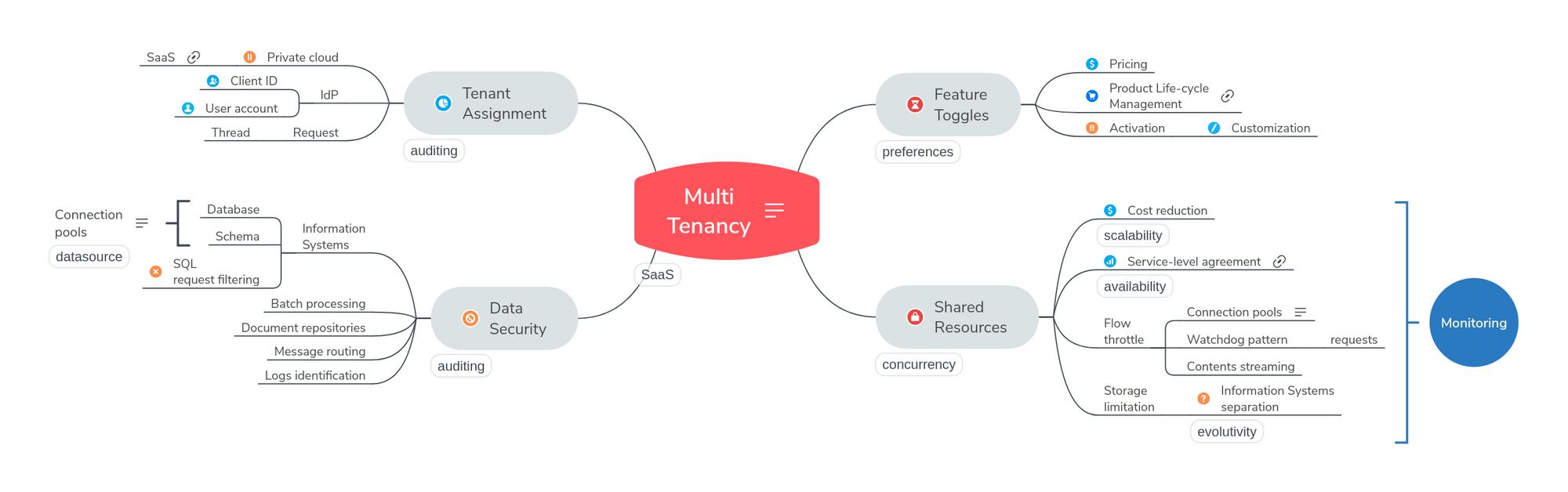
- L’assignation des utilisateurs aux “tenants”, évidemment
- La gestion du cycle de vie des services et l’activation dynamique des fonctionnalités
- Le cloisonnement des données et des ressources informatiques
Tenant assignment
Dans notre réflexion présente, le “tenant” correspond à un contrat de service qu’il convient d’honorer en fournissant les fonctionnalités attendues ; c’est un groupe d’utilisateurs qui bénéficient de cette prestation. Même si on peut anticiper un certain niveau d’activité dans le système, en fonction de la taille du groupe et de la nature de leur activité, il est toujours complexe de prévoir quelles seront les charges de travail réelles, et surtout leurs fluctuations à petite (journée, semaine) ou grande (mois, année) echelle.
Une première tentation est de déployer l’application dans un environnement complètement autonome (dedicated, isolated) - comme un private cloud ou un virtual private network, voire un data center à part - accessible uniquement par le client ciblé. Cette solution a l’avantage (non négligeable) de nous débarrasser purement et simplement de la problématique de multi-tenancy ! Cependant cela ouvre la voie à toute une série de tracasseries, telles que le refus possible d’évolutions par le client qui pourrait se montrer rétif à former les équipes à des fonctionnalités dont il n’aurait pas ressenti le besoin ; dans ce cas on prend le risque de devoir maintenir plusieurs versions parfois très éloignées les unes des autres. Ou encore le fait de devoir supporter le coût d’une infrastructure sous-utilisée ; ne serait-ce qu‘en dehors des heures de bureau, si les utilisateurs sont localisés dans le même fuseau horaire.
Alors, bien sûr, si l’on souhaite éviter au moins les deux écueils mentionnés plus haut, nous voudrions déployer une seule application pour tout le monde, avec une publication systématique des correctifs et des évolutions. Pour plus de sécurité, et une meilleure efficacité des équipes de développement, cette solution a bien des attraits. Et l’on doit choisir une stratégie de détermination du “tenant” correspondant à chaque utilisateur qui sera autorisé à accéder au système. Voici une liste des courses possible :
- Un mécanisme de gestion de plusieurs fournisseurs d’identité (IdP)
- Organisation de la correspondance des IdP avec les “tenants” gérés
- Un mécanisme de filtrage des ressources au sein de chaque requête
- Contextes de communication systématiquement contrôlés
- Pools de connexion disponibles pour toutes les couches (data access, view, etc.) afin d’éviter la latence dans l’instanciation des accès aux ressources
- Un mécanisme de facturation par rapport à la charge consommée (audit) ?
Quoi qu’il en soit, on ne doit jamais oublier que l’assignation doit se faire prioritairement au niveau requête (c’est-à-dire du thread en Java qui fournit la classe ThreadLocal, tandis que Spring MVC gère des portées de niveau “session” et “request”). Cette assignation se basera sur le mécanisme d’identification existant, qui constitue un premier filtrage.
Product life-cycle and feature toggles
Il n’est pas toujours possible de “vendre” toutes les fonctionnalités d’une application à tous les utilisateurs. Il arrive très fréquemment que ceux-ci n’emploient qu’une partie de ces fonctions pour leur activité quotidienne, et c’est même souvent souhaitable afin de distinguer entre les responsabilités de chacun. Et bien que dans la plupart des cas on soit capable de déterminer à la conception les différents profils d’utilisation, sous la forme de combinaisons de modules par exemple. On peut ainsi vouloir répartir la puissance du logiciel dans des offres distinctes, avec des facturations précises.
Des problèmes peuvent toutefois survenir, lorsque les fonctions optionnelles sont en réalité des développements personnalisés, pour répondre aux besoins spécifiques de tel ou tel client. Il n’est pas rare d’observer l’apparition d’équipes dédiées à ces problématiques, et à leur maintenance. Le pire étant le cas où une fonctionnalité d’origine est détournée de son but, pour élargir son champ d’action ou carrément en dévier sans espoir de réconciliation.
- Mise en place d’un cycle de déploiement unique
- Adaptation de la gestion des clients pour tenir compte de spécificités (c’est une logique de groupe, qui peut vite dériver vers une logique de profil, voire individuelle)
- Gestion des configurations (paramétrage des interfaces, par exemple)
- Gestion de la souscription aux fonctionnalités en option, avec éventuellement des offres dégressives en fonction des bouquets souscrits
- Mise en place de rôles, ou prise en compte des groupes d’utilisateurs
- Facturation à la souscription (date à date) ou à l’utilisation (temps, volume)
Comme il est relevé plus haut, on ne doit pas négliger la question du paramétrage propre à chaque “tenant”. Il est difficile d’imaginer ne pas fournir aujourd’hui (même dans les produits destinés au grand public) un degré minimum de personnalisation (organisation des données et des modules applicatifs, thème de présentation, catégories libellées, etc.) même s’il est facile d’externaliser au moins la gestion des accès.
Data security
Il est temps à présent de se pencher en profondeur sur la question cruciale du multi-tenancy, à savoir le cloisonnement des données. Ce sujet est sous-jacent à tous les autres aspects concernés. On a déjà dit qu’il reste possible, en marge d’une véritable stratégie de colocation, de déployer le système dans son propre environnement. Mais si cela n’est pas le cas, plusieurs options générales sont à envisager :
- Réservation d’une instance de base de données à part…
- À multiplier par le nombre de systèmes différents nécessaires.
- Réservation d’un schéma dans une base de données commune
- Partage des tables elles-mêmes, avec discrimination des lignes par un champ dédié
- Les techniques de partitionnement horizontal peuvent également servir à une séparation des données de bas niveau, pour des gains de performance.
Il est bien évident que la première option est la plus facile à mettre en oeuvre, mais elle constitue aussi un retour en arrière qui correspond à la stratégie d’évitement : on devra superviser chaque instance de base séparément et les surveiller comme le lait sur le feu. Dans le second cas, on a un compromis entre la souplesse d'administration et un cloisonnement clair ; par ailleurs, comme il n’y a pas vraiment de différence (en Java) entre un datasource sur une base et un schéma, c’est tout bénéfice pour nous dans ce cas.
La troisième option, quant à elle est… désastreuse, n’ayons pas peur des mots. En effet, le risque de ne pas complètement maîtriser les extractions des données peut provenir autant des erreurs de programmation que de jointures malheureuses… sans parler des menaces d’injection SQL ! Vous aurez suffisamment de sueurs froides comme ça, rien que dans le routage des messages, inutile de rajouter de la faiblesse à la complexité.
- Cloisonnement du stockage des données
- Séparation des schémas SGBDR, des partitions NoSQL
- Utilisation de dépôts séparés pour le stockage de documents
- Filtrage fort des messages émis dans le cadre des communications asynchrones
- Identification claire du contexte des journaux d’exécution émis
- Cloisonnement du traitement des données par lots, de la sauvegarde ?
J’attire votre attention sur le fait que le cloisonnement des données occulte parfois l’autre cloisonnement, celui des infrastructures, que nous allons traiter dans la section suivante.
Shared resources
Les bénéfices que nous avons évoqués jusqu’ici sont sans compter le fait qu’avec l’architecture multi-tenancy il devient possible de limiter le nombre de ressources actives dans l’infrastructure, et donc de réduire les coûts d’exploitation. En effet, avec une infrastructure partagée, on bénéficie du lissage de la charge, du fait d’horaires de travail potentiellement décalés entre les utilisateurs ; mais également des rythmes d’activité, nécessairement dépendants de tâches de natures diverses réparties dans le temps.
Attention cependant, à ne pas sacrifier la qualité du service dans le même temps. On doit trouver une façon d’empêcher que l’activité d’un groupe d’utilisateurs ne compromette celle des autres, en s'accaparant les ressources disponibles sans aucune contrainte. Il n’est pas simple du tout de parvenir à cet équilibre. On peut limiter les bandes passantes dans l’absolu, par exemple avec un nombre limité de connexions ou grâce au pattern “watchdog”, ou instaurer le streaming des flux de réponse (médias et listes), voire d’entrée (upload).
- Limitation des pools de connexion aux ressources informatiques
- Limitation du nombre de sessions actives, du nombre de requêtes simultanées…
- Modulation des débits par le streaming des flux de données
- Limitation des volumes de stockage
- Système de surfacturation en cas de dépassement
Mais on préférera sans doute tenir compte de la charge totale du système. Après tout, pourquoi refuser une charge de travail, si elle peut être supportée ? Surtout si elle peut être facturée… On aura donc recours à la modulation des seuils, via une supervision globale.
Pour conclure
Sur toutes les logiques que nous avons vues, doit s’appliquer une politique stricte de supervision, qui doit permettre de contrôler (au moins a posteriori) le cloisonnement des données et la gestion optimale des flux de travail. On ne doit donc pas se cacher que des efforts particuliers de visibilité sont nécessaires à la réussite d’un tel projet.
Si une première étape, dans la migration d’applications “classiques” consiste à permettre une évolutivité à la fois fonctionnelle (mises à jour ciblée sur des services découplés) et en termes de performances (capacité à s’adapter aux fluctuations de charge), c’est une excellente chose, et déjà pas si simple à mettre en oeuvre. Mais une application SaaS doit également adresser une problématique de cloisonnement qui est cruciale. En effet, une offre “à la demande” doit être disponible immédiatement, en permanence (notamment sans arrêts de maintenance), tout en garantissant la sécurité des données impliquées. Elle doit aussi remplir un contrat de prestation de services, afin d’assurer aux utilisateurs des performances perçues fluides.
Tous ces objectifs ne sont atteignables qu’après avoir soigneusement envisagé les différentes options disponibles pour le(s) système(s) d’information et les infrastructures de déploiement (voir le schéma synthétique en introduction). Il s’agit donc d’une approche d’architecture globale qui doit être prise en compte dès la conception et le développement du logiciel.
