
Introduction
Dans le cadre d’une mission, j’ai eu l'opportunité d'étudier la solution d’Apache Knox et d’analyser sa réponse à certains use cases, dont son utilisation dans une architecture On-premises composée de clusters Hadoop.
Le but de cet article est de faire un petit tour sur cette technologie pour présenter brièvement et simplement : son concept, son fonctionnement, ses cas d’utilisation et la pérennité de cet outil Apache peu connu.
Le concept
Apache Knox est l’API Gateway de la fondation Apache. Créé en 2013, il vise à répondre à des besoins de sécurité des clusters Hadoop.
Une API (Application Programming Interface) Gateway est une application qui permet d’avoir accès à un groupe de services via une entrée unique.
Concrètement, dans le cas de Knox, elle permet aux applications extérieures et aux clusters d’avoir accès aux différents frameworks de Hadoop (Hive, Map Reduce, HDFS, etc.) et de les utiliser via un seul canal.
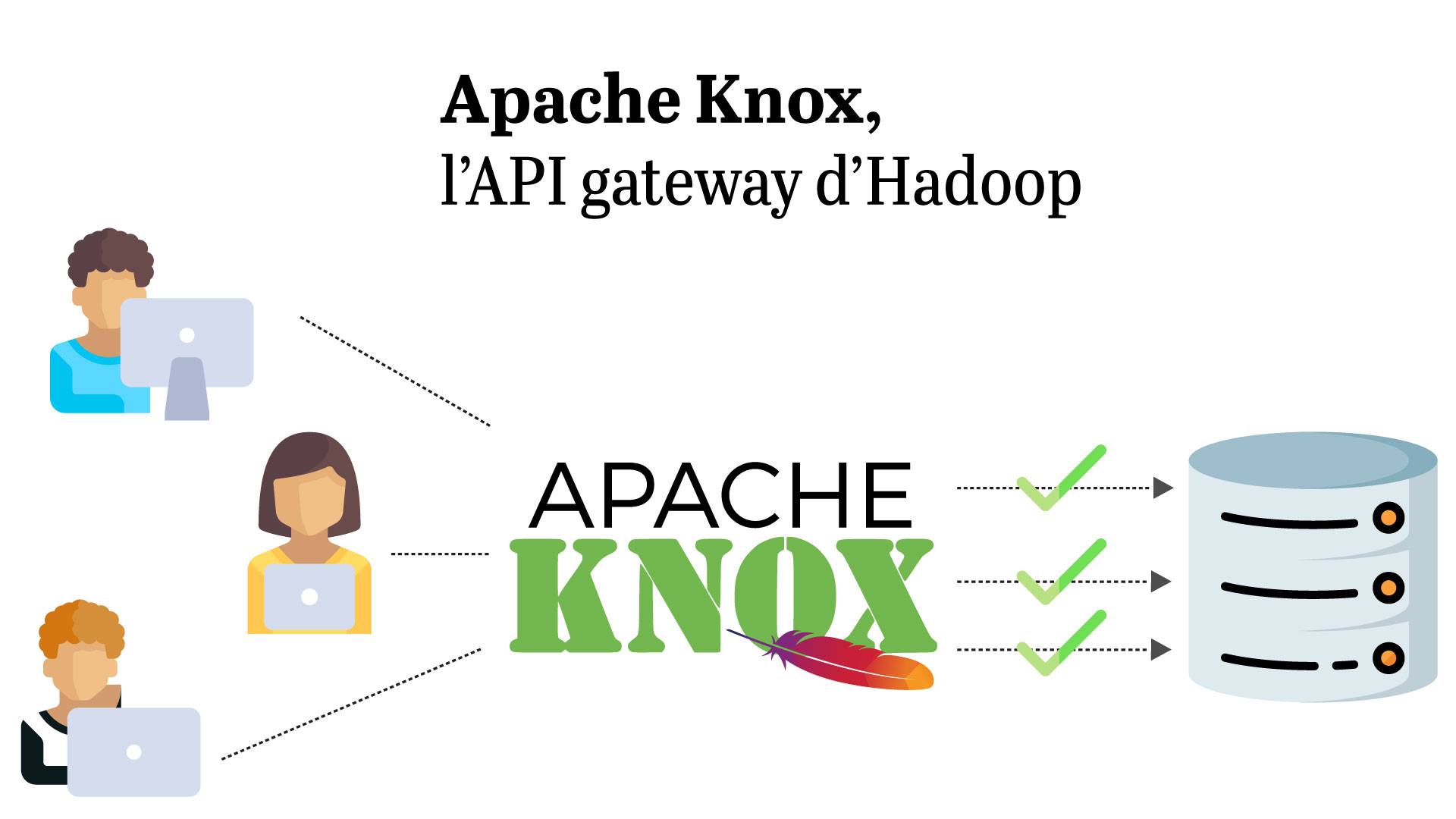
Tout cela peut se résumer avec le schéma suivant :

Sur cette illustration, nous avons à gauche : des utilisateurs qui peuvent être des applications (comme Tableau Software), des personnes qui font des requêtes directes (via Beeline par exemple), des jobs, etc. Ils souhaitent interroger un framework Hadoop via une requête HTTP.
L’initiateur de la requête va dans un premier temps envoyer la requête à Knox qui va interroger le service d’autorisation et/ou d’authentification (tel que Kerberos, Shiro, LDAP, etc.) afin de savoir si cet utilisateur a le droit de contacter le service concerné. Ensuite, Knox va aller interroger un service Hadoop, et retourner la réponse à l’utilisateur.
Cela permet donc de :
- Protéger les informations du cluster de l'extérieur car on ne s’y connecte plus directement mais via Knox,
- Diminuer le nombre de services avec lesquels le client doit interagir car désormais il communiquera uniquement avec Knox,
- Simplifier le mécanisme d’authentification en n’en utilisant qu’un seul basé sur du HTTP, dans le cas où les clusters sont déjà sécurisés.
En terme de sécurité, Knox fonctionne avec les différentes couches d’autorisation et d’authentification des clusters Hadoop. Il est donc utilisable avec Apache Ranger, Kerberos , le protocole LDAP, ... et s'intègre bien avec les principaux IMS (Identity Management Solutions) du marché .
Fonctionnement
Je vais maintenant vous montrer comment Knox s’utilise de manière concrète en nous connectant à Hive.
Pour cela, le graphique suivant complète le précédent en vous montrant ce qu’il se passe dans Knox lors de l’envoi de la requête par un utilisateur :
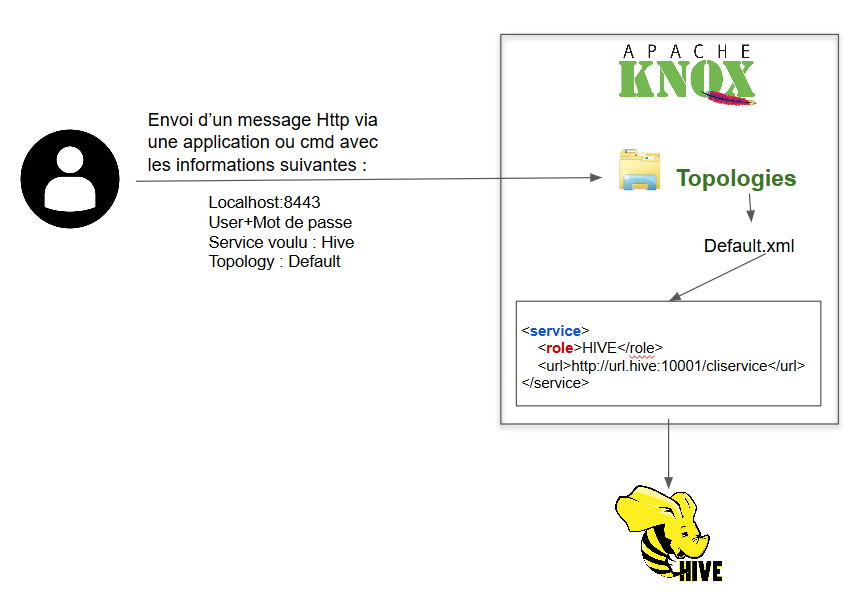
Pour appuyer cette illustration et mieux comprendre la suite, voici quelques définitions :
-
Topology : C’est l’endroit où l’on va retrouver l’ensemble des services. Il peut y avoir plusieurs topologies dans le cas où l’on souhaite que les services appelés varient en fonction des utilisateurs ou autres paramètres.
-
Service : Une topologie contient plusieurs services. Chaque service contient au minimum un rôle et une URL.
-
Rôle : Le rôle est contenu dans le service, il indique quel framework on appelle. Dans notre exemple, nous appelons Hive, mais cela aurait pu être WebHDFS, WebHCat, Oozie, HBase, Yarn, Kafka et j’en passe.
Dans un premier temps, l’utilisateur va envoyer un message HTTP en direction de Knox (par défaut https://localhost:8443/…). Le message contiendra :
- la topologie avec laquelle il souhaite interagir (ici la topologie “default” configurée dans le fichier default.xml),
- le rôle, qui sera l’application avec laquelle il souhaite communiquer (ici Hive),
- un user et un mot de passe si besoin,
- la requête (par exemple “show tables”).
Dans le fichier default.xml du dossier Topologies, il va directement aller voir quel service a pour rôle “Hive” et ainsi contrôler le user et le mot de passe.
Si tout est bon en terme d’autorisations, Knox va envoyer la requête à l’URL indiquée, qui est l’URL de Hive. La requête est transmise à Hive, qui y répondra. Knox renverra alors la réponse de Hive aux utilisateurs.
En résumé, Knox va véritablement agir comme un Proxy qui permet au client de communiquer avec les serveurs Hadoop via un seul point d’accès.
Attention, en aucun cas Knox ne suffira comme seule couche de sécurité :
- Dans notre cas, l’URL de Hive reste toujours active donc, sauf paramétrage particulier, nous pouvons toujours passer par cette URL pour d’autres services.
- En aucun cas Knox ne permet de remplacer Kerberos, ou les autres couches de sécurité citées à la fin de la première partie : les services sont complémentaires.
Les cas d’utilisations
Maintenant que nous comprenons le fonctionnement de base de l’outil, il est temps de parler de ses cas d’utilisations.
Knox est fait pour être utilisé dans un environnement avec des clusters Hadoop.
Il permettra de répondre à ces besoins :
- Étendre/simplifier les accès aux clusters sans perdre en sécurité,
- Simplifier les configurations de sécurité des clusters.
Il peut être utilisé dans un EMR AWS (clusters Hadoop dans le cloud d’AWS) comme le montre cet article.
Knox est donc utilisable comme API Gateway pour des clusters Hadoop dans un environnement On-premises mais aussi Cloud, qu’il soit public ou privé, ce qui étend considérablement ses possibilités. D’autant plus que les API Gateway potentiellement proposées par ces services, comme AWS API Gateway ou Cloud Endpoint, ne permettront pas forcément de proxifier des clusters Hadoop comme le fait Knox.
Il peut aussi répondre à des cas d'utilisations plus particuliers :
- authentification (en LDAP, SSO, SAML, etc.),
- autorisation (il dispose de son propre ACL),
- configuration de Kerberos (en l'encapsulant, évitant ainsi des configurations côté client).
De plus, certaines distributions comme Cloudera (et Hortonworks pour ceux qui sont sur une ancienne version) proposent de l’installer directement via leur UI (User Interface). En revanche, même si l’installation via l’UI est parfois possible pour les Data platforms, je vous conseille de faire bien attention à la version qui est utilisée.
Personnellement, j’ai commencé avec la version 0.12 de Knox, qui était la version de base dans mon SI. Je me suis ensuite décidé à passer sur la v1.3 qui est beaucoup plus stable, avec une bonne documentation et contient plus de fonctionnalités (comme l’intégration de Kafka et d’Elasticsearch par exemple !)
Pérennité
Avant d’envisager toute mise en prod de ce genre d’application, il faut être sûr de sa pérennité. D’autant plus que Knox reste assez peu connu. J’ai donc fait cette analyse en allant sur le repository GIT de l’application, son Jira et en consultant Google Trend
À l’heure où j’écris cet article, sur leur Github, il y a 42 contributeurs. Certes cela peut sembler peu, mais le repo est très actif avec des commits quasi quotidiens.
Le nombre de commits est potentiellement lié au nombre de tickets Jira ouvert ( 227 tickets ouvert pour 80 environ tickets de types bug), ce qui peut nous faire émettre quelques réserves vis-à-vis de la stabilité de l’application.
Il faut également souligner que beaucoup des commiteurs sont de Cloudera et anciennement d’Hortonworks.
Il y a une plus forte activité depuis la version 1.3 parue en juillet 2019, ce qui rassure sur la pérennité du projet, d’autant plus qu’on remarque que le nombre de recherches sur Apache Knox est stable par rapport à 2016.
Le point noir par rapport à la durabilité de Knox est que l’on manque de visibilité sur les entreprises qui l’utilisent, bien qu’il ait été porté par Hortonworks et aujourd’hui Cloudera.
En bref, à la vue des informations citées précédemment, je pense que cette application sera maintenue et mise à jour, tant que les Data platforms comme Cloudera existeront.
Conclusion
Je vous ai ainsi présenté le fonctionnement de Knox d’un point de vue simplifié et généraliste, afin de vous faire connaître cette application et ses possibilités.
Je pense que ce framework d’Apache a totalement sa place sur les gros SI, avec des clusters Hadoop en On-premises ou Cloud, et c’est normal car il a été développé pour ça ! Cela permet faciliter les différents accès aux clusters et dans certains cas cela peut même simplifier l'implémentation de protocoles.
Pour mener à bien cette étude, je me suis appuyé sur la documentation et sur cet article assez complet, que je vous conseille de consulter si vous voulez aller plus loin sur Apache Knox.
