
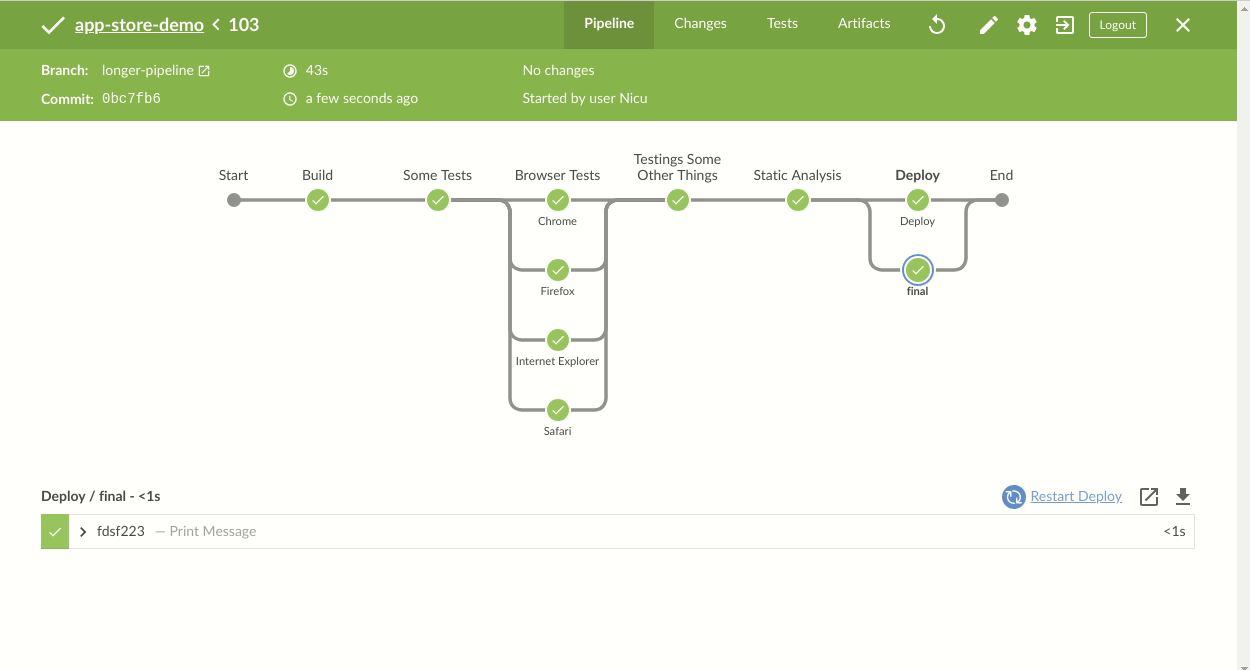
L’usine logicielle pour le développement d’applications comprend de nombreuses pièces répondant chacune à des besoins différents : Stockage du code source, construction du code, tests, analyse qualité, intégration continue, stockage des livrables, déploiements automatisés, système d’alertes. L’élément central qui s’interface avec tous les autres éléments est l’intégration continue. Des nombreuses solutions d’intégration continue existent. Une des plus utilisées est Jenkins.
Jenkins
La mise en place d’un serveur Jenkins est relativement simple : installation du serveur, téléchargement des premiers plugins, configuration basique du serveur (notamment la gestion des droits d’accès) et des extensions. Ensuite, les équipes commencent à créer des processus de construction, des « jobs » selon la dénomination de Jenkins.
Au début, pour commencer rapidement, les équipes utilisent l’interface d’administration et créent des jobs ‘free-style’ et y ajoutent des étapes de construction en fonction des extensions disponibles. Mais au fur et à mesure des déclarations de jobs, la configuration de l’outil devient rapidement un enchaînement fastidieux et répétitif de clics. En outre, l’ajout d’un peu de logique entre les différentes étapes de construction se révèle compliqué.
La version 2 de Jenkins apporte une nouvelle capacité pour réduire les actions répétitives lors de la configuration de l’outil. Il est désormais possible avec l’aide de l’extension Pipeline, de transformer une partie de la configuration en code.
Jenkins Pipelines
Un job ‘Pipeline’ permet la décomposition d’une construction Jenkins en plusieurs étapes et utilise le langage Groovy pour décrire les actions à exécuter et la logique à prendre en compte. Les différentes étapes sont définies dans un fichier dont le nom par défaut est ‘Jenkinsfile’. Il existe 2 syntaxes de Pipelines : Declarative Pipeline et Scripted Pipeline. Declarative Pipeline est une syntaxe récente plus simplifiée et plus explicite que la syntaxe Scripted Pipeline fournie par défaut. Son utilisation est recommandée pour débuter avec les Pipelines et dans des cas d’utilisation simples. Contrairement à Declarative Pipeline, Scripted Pipeline est une syntaxe pour un usage plus étendu et moins contraint. La plupart des fonctionnalités fournies par le langage Groovy sont mises à la disposition des utilisateurs de Scripted Pipeline.
Cependant, un point de blocage apparaît rapidement dès l’ajout de script Groovy complexe dans le fichier ‘Jenkinsfile’. Car pour protéger Jenkins de l'exécution de scripts malveillants, le code Groovy est exécuté dans un bac à sable Groovy, qui limite l’accès aux API internes, notamment sur l'instanciation de classes et l’appel de méthodes statiques.
L’utilisation d’une API non autorisée se conclut par l’échec de l’exécution du Pipeline Jenkins. Les administrateurs doivent ensuite utiliser la page "In-process Script Approval" (https://jenkins.io/doc/book/managing/script-approval/), fournie par l’extension ‘Script Security’, pour déterminer, le cas échéant, quelles méthodes non-sécurisées doivent être autorisées dans l'environnement Jenkins. Ces actions manuelles et répétitives font pratiquement perdre tout l’intérêt de la syntaxe Scripted Pipeline.
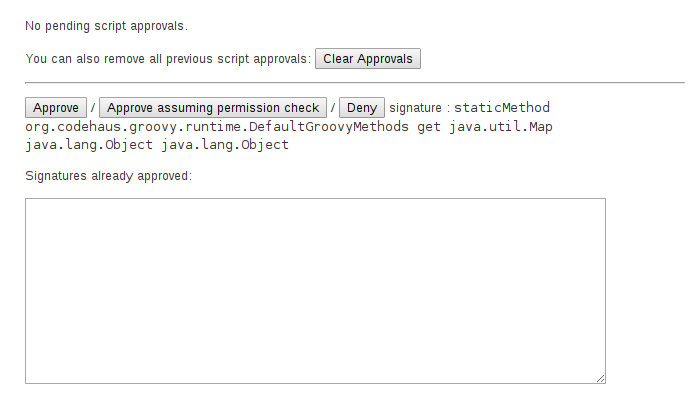
Ⓒjenkins.io/doc/book/managing/script-approval/
Shared Libraries
Néanmoins, un contournement est possible. L’extension ‘Pipeline: Shared Groovy Libraries’ permet de définir une bibliothèque partagée dans un projet git distinct. Le code contenu dans la bibliothèque partagée n’est pas soumis à l’approbation de script. Attention, il faut garder à l’esprit qu’une personne avec les droits de publication sur le dépôt git contenant la bibliothèque partagée, a ainsi un accès illimité au serveur Jenkins.
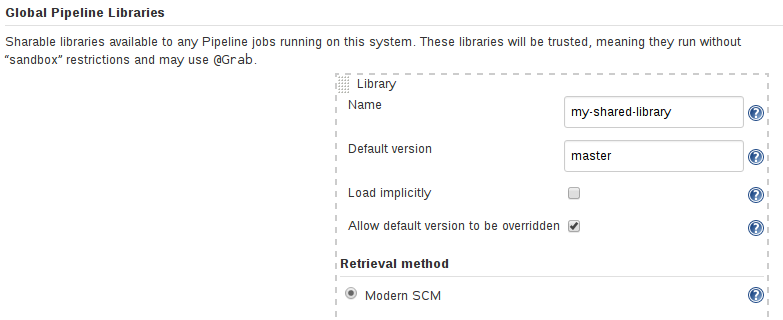
Ⓒjenkins.io/doc/book/pipeline/shared-libraries/
La bibliothèque partagée est déclarée dans la configuration générale de Jenkins (Administrer Jenkins > Configurer le système), dans la section ‘Global Pipeline Libraries’.
En cliquant sur le bouton ‘Ajouter’, une nouvelle déclaration de bibliothèque est disponible. Il suffit alors de renseigner un nom (qui sera utilisé pour identifier la bibliothèque), de donner une version par défaut à charger si un Pipeline n'en sélectionne aucune autre. Cela peut-être un nom de branche, une balise, un hachage de validation, etc., en fonction le type de gestion de code source utilisé.
Dans les sous-sections ‘Retrieval method’, ‘Source Code Management’, il faut renseigner le type de gestion de code source utilisé, l’adresse du référentiel de code source et les informations de connexion (nom d’utilisateur / mot de passe) à ce référentiel.
Une bonne pratique est de décocher ‘Load implicitly’ et de déclarer explicitement l’import de la bibliothèque dans le fichier Jenkinsfile à l’aide de l’annotation @Library. Cela est utile dans les cas où plusieurs bibliothèques sont déclarées sur un serveur Jenkins et certains jobs ‘Pipelines’ n’en utilisent qu’une seule ou bien aucune.
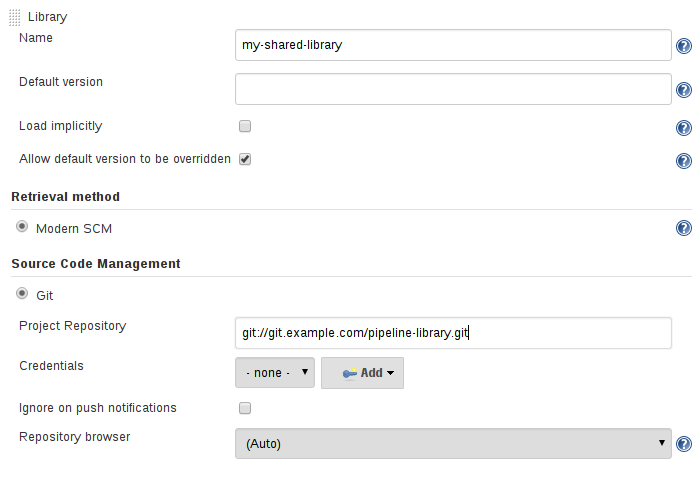
Ⓒjenkins.io/doc/book/pipeline/shared-libraries/
Une documentation sur les bibliothèques partagées est disponible sur le site de Jenkins : https://jenkins.io/doc/book/pipeline/shared-libraries/
Quelques retours d'expérience
Lors d’une première utilisation et la maintenance des bibliothèques partagées, quelques règles ont été précieuses pour éviter certains désagréments.
1- Il faut toujours vérifier la compilation du code de la bibliothèque partagée (avec des outils comme Maven ou Gradle) avant de publier sur le référentiel de code source. Sinon à la moindre erreur, tous les jobs ‘Pipelines’ utilisant la bibliothèque sont en erreur au lancement d'une construction.
2- Pour tester les scripts contenus dans la bibliothèque avant à la mise à disposition générale, l’utilisation d’une ou plusieurs branches de développement sur le référentiel de code source ainsi que l’utilisation de plusieurs jobs Pipeline de test référençant ces branches de développement est souhaitable.
3- Centraliser les fichiers ‘Jenkinsfile’ dans un référentiel de code source indépendamment du code source des projets est pratique lorsque ces référentiels ‘projet’ contiennent des dizaines de branches et qu’une modification dans un fichier ‘Jenkinsfile’ doit être répercutée sur toutes les branches.