

Introduction
Dans cet article, nous allons découvrir les outils que nous met à disposition Microsoft sur Azure afin de mieux analyser et valoriser la donnée.
Actuellement le problème pour les entreprises est l’analyse de la data et comment la monétiser, l’utiliser et la comprendre.
On constate depuis quelques années que le coût du stockage baisse, les baies de stockage ont de plus en plus de capacité de ce fait, on collecte de plus en plus de données sans toutefois bien l’utiliser.
analyser ces données coûte cher, il faut des machines de plus en plus performantes pouvant faire face à la capacité de données à traiter, il faut donc prendre en compte le coût, l’évolution et le maintien du matériel existant permettant d’effectuer ces traitements.
Le cloud permet donc à moindre frais de pouvoir analyser nos données, mieux les comprendre et savoir si elles ont de la valeur et donc permettre de la monétiser.
Cela peut permettre à un décideur de prendre une décision concernant son entreprise au sujet d’un produit, s’il est intéressant ou rentable, ou encore à un site internet de savoir quel type de population vient le consulter.
Pourquoi la donnée est elle importante aujourd’hui
La plupart des entreprises ont encore du mal à obtenir des analyses pertinentes de leurs données et à exploiter pleinement le potentiel de l'intelligence artificielle. La migration vers le Cloud permet de simplifier le Big Data et l’IA comme la solution Databricks désormais proposée par Microsoft en tant que service intégré Azure.
Databricks est la principale plateforme d’analyse basée sur Spark. Ce nouveau service fourni aux équipes de data science une plateforme rapide, simple et collaborative basée sur Spark dans Azure. Il offre aux utilisateurs une plateforme unique pour le traitement de données volumineuses et l’apprentissage automatique.
Azure Databricks est maintenant intégré nativement à Microsoft Azure de plusieurs façons, allant d’un simple clic à une facturation unifiée. Il exploite la sécurité d'Azure et s'intègre de manière transparente aux services Azure tels que Azure Active Directory, SQL Data Warehouse et Power BI. Tout cela a pour seul but de rendre l’analyse Big Data et l’IA beaucoup plus accessibles pour les utilisateurs.
Pourquoi de la data sur Azure
Mais avant tout, pourquoi Azure ? L’avantage des solutions d’analyse de la data dans le Cloud Azure est qu’elles sont complètes et particulièrement bien documentées. Il existe des outils disponibles sur le marketplace pour la réplication et l’ingestion des données en temps réel tel que Attunity par exemple :
- https://databricks.com/blog/2017/11/15/introducing-azure-databricks.html
- https://docs.microsoft.com/fr-fr/azure/architecture/reference-architectures/data/stream-processing-databricks
- https://www.qlik.com/us/products/data-integration-products

Les solutions proposées par Microsoft sont les suivantes :
Azure HDInsight est une distribution cloud des composants Hadoop de Hortonworks Data Platform (HDP). Azure HDInsight permet de traiter des quantités énormes de données facilement, rapidement et à moindre coût. Vous pouvez utiliser les frameworks open source les plus populaires tels que Hadoop, Spark, Hive, LLAP, Kafka, Storm, R.
Azure Databricks est une plateforme d'analyse basée sur Apache Spark, optimisée pour la plateforme de services cloud Microsoft Azure.
Azure Data Lake Analytics est un service managé d'analyse à la demande qui simplifie le Big Data. Au lieu de déployer, configurer et ajuster le matériel, vous écrivez des requêtes pour transformer vos données et extraire des informations précieuses.
Ci-dessous le processus d’ingestion et de traitement de la donnée avec Azure Databricks

Ci-dessous le processus d’ingestion et de traitement de la donnée avec Azure Data Lake Storage Gen2

Azure leader dans le traitement de la donnée dans le Cloud
Microsoft est le leader dans la gestion de la donnée comme nous le montre le magic quadrant, porté par l’ensemble des solutions mise à disposition des data scientists dans le Cloud Azure.

Présentation de Azure Data Factory
Azure Data Factory est le service ETL disponible dans cloud d’Azure qui permet au travers d’une pipeline de mettre à disposition des données dans un blob storage ou vers Azure Data Lake

Voici le lien vers différents tutoriaux Microsoft permettant de créer un pipeline Azure Data Factory :
- https://docs.microsoft.com/fr-fr/azure/data-factory/tutorial-control-flow
- https://docs.microsoft.com/en-us/azure/data-factory/tutorial-copy-data-portal

Présentation de Azure Data Lake Analytics
Azure Data Lake est un service d'analyse et de stockage dans le Cloud évolutif et à la demande. Il peut être divisé en deux services connectés, Azure Data Lake Store (ADLS) et Azure Data Lake Analytics (ADLA).

Azure Data Lake Store est un système de fichiers qui permet le stockage de tous type de données de n'importe quelle structure, et est donc parfait pour l'analyse et le traitement de données non structurées.
Azure Data Lake Analytics est une plateforme de travail distribuée en parallèle qui permet l'exécution de scripts U-SQL dans le cloud. La syntaxe est basée sur SQL et C #.
Les fichiers texte de différentes sources sont stockés dans Azure Data Lake Store et sont joints, manipulés et traités dans Azure Data Lake Analytics. Les résultats de l'opération sont transférés vers un autre emplacement dans Azure Data Lake Store.
Les tâches ADLA peuvent uniquement lire et écrire des informations depuis et vers Azure Data Lake Store. Il est possible de le compléter avec un service d'orchestration de données tel que Data Factory.
Voici le lien vers la présentation du produit chez Microsoft :
Analyse avec Data Lake Analytics
Data Lake Analytics offre des fonctionnalités similaires à Databricks. Vous pouvez écrire du code pour analyser les données et l’analyse peut être automatiquement parallélisée.

Microsoft a publié une nouvelle version de Data Lake, qu’il appelle Data Lake Storage Gen2 basée sur du storage Blob afin d’améliorer les performances des analyses effectuées avec Data Lakes Analytics . Les données stockées dans un Data Lake sont accessibles de la même manière que sur un volume HDFS et Microsoft fournit un nouveau pilote pour accéder aux données d'un Data Lake pouvant être utilisé avec SQL Data Warehouse, HDinsight et Databricks.
Avec Data Lake Analytics, l'analyse des données est conçue pour être effectuée en U-SQL. Bien qu'il prenne en charge les bibliothèques R et Python, les utilisateurs de cette technologie devront se familiariser avec U-SQL, qui ressemble beaucoup à C #.
Présentation de Databricks

Azure Databricks est la dernière offre Azure pour les data scientistes. Les points forts de Databricks sont les suivants :
- Solution intégrée nativement à Azure
- Environnement collaboratif et interactif basé sur des notebooks
Databricks est optimisé par Apache Spark et offre un panel d'API pouvant être utilisée par les langages R, SQL, Python, Scala et Java. L'écosystème Spark permet également de faire du Streaming avec MLib et GraphX.
Les données peuvent être collectées à partir de diverses sources, telles que Blob Storage, ADLS et à partir de bases de données ODBC utilisant Sqoop.
Analyse avec Databricks
Pour analyser vos données avec Databricks vous pouvez utiliser trois langages différents R, Scala et Python.
Les données peuvent être lues à partir de différentes options Azure Storage, notamment Blob Storage, Data Lake et à l'aide d'une connexion JDBC. Vous pouvez également vous connecter à Azure SQL DB, ainsi que Azure SQL Data Warehouse.
Étant donné qu'il existe trois langages différents pouvant être utilisés, il n'y a aucune raison d'apprendre un nouveau langage, car la plupart des gens connaissent déjà très bien au moins l'un des trois langages pris en charge.
En plus de la possibilité de développer du code, Databricks offre d'autres fonctionnalités que l'on ne retrouve pas dans Data Lake Analytics. De nombreux projets prévoient que les gens travaillent en équipe et auront besoin d'un environnement pour partager le code et le mettre à jour. Cette fonctionnalité est intégrée à Azure Databricks, dans la mesure où elle fournit un environnement permettant de partager des données avec d'autres, et de sauvegarder les données nativement dans un référentiel GitHub. L’environnement de développement est Jupyter Notebooks, qui constitue un excellent moyen de documenter le code et d’inclure des échantillons de données. Databricks inclut également un composant de planification de travail afin que le travail créé dans Databricks puisse utiliser un planificateur natif permettant de relancer et d'envoyer des messages configurables en cas d'erreur ou d'achèvement. L’ensemble de ces fonctionnalités donnent à Databricks un avantage décisif dans la détermination de la technologie à utiliser.
HDInsight

Azure HDInsight est un service cloud qui permet le traitement de données à l'aide de frameworks open source tels que Hadoop, Spark, Hive, Storm et Kafka, entre autres.
À l'aide d'Apache Sqoop, nous pouvons importer et exporter des données vers et depuis une multitude de sources, mais le système de fichiers natif utilisé par HDInsight est Azure Data Lake Store ou Azure Blob Storage.
Parmi toutes les technologies ETL Azure basées sur le cloud, HDInsight est la solution la plus proche d’un IaaS, du fait de la gestion des clusters. La facturation est calculée à la minute, mais les activités peuvent être planifiées à la demande à l'aide de Data Factory, même si cela limite l'utilisation du stockage à Blob Storage.

Comparaison
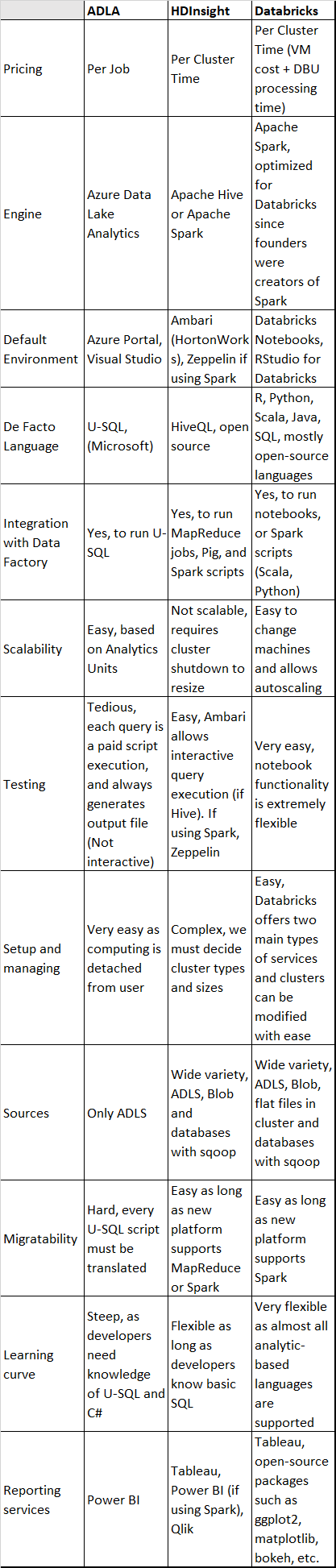
Voici une comparaison complète des trois services:
Petite news du Microsoft Ignite :)
Microsoft nous a présenté lors du Microsoft Ignite : Azure Synapse Analytics

Azure Synapse Analytics est une évolution de SQL Data WareHouse, actuellement, c'est le seul système d'analyse à avoir exécuté TPC-H à l'échelle pétaoctet.
De ce fait Azure Synapse Analytics permets aux entreprise d'analyser plus rapidement leurs sources, entrepôts de données et système d'analyse de big data.
Avec Azure Synapse, les ingénieurs data peuvent interroger des données relationnelles et non relationnelles à l'échelle du pétaoctet à l'aide du langage SQL
Il est intégré à Power BI et Azure Machine Learning pour élargir la découverte des informations de vos données et appliquer des modèles d’apprentissage automatique à vos applications

Le studio Azure Synapse fournit un espace de travail unifié pour
- la préparation de données,
- la gestion de données,
- l'entreposage de données,
- les données volumineuses
- et les tâches d'intelligence artificielle.
Il permet aux équipes de travailler plus efficacement :
- Les ingénieurs de données peuvent utiliser un environnement visuel sans code pour gérer les pipelines de données.
- Les administrateurs de base de données peuvent automatiser l'optimisation des requêtes.
- Les scientifiques de données peuvent créer des POC en quelques minutes.
- Les analystes métier peuvent accéder en toute sécurité aux jeux de données et utiliser Power BI pour créer des tableaux de bord en quelques minutes, tout en utilisant le même service d'analyse.

Conclusion
Comme nous l'avons vu, le type de plateforme est à choisir suivant son besoin.
ADLA est particulièrement puissant lorsque nous ne souhaitons pas allouer autant de temps que nécessaire à l'administration d'un cluster. Cela permet également aux développeurs qui connaissent C # à exploiter tout le potentiel de U-SQL.
HDInsight a toujours été très fiable lorsque nous connaissons les charges de travail et la taille des clusters que nous devrons exécuter. Mais la mise à l'échelle est fastidieuse, car les machines doivent être supprimées et activées de manière itérative jusqu'à ce que nous trouvions le bon paramétrage. Utiliser Hive est un avantage, étant donné qu’il est open source et très similaire à SQL, il nous permet de passer directement au développement sans formation supplémentaire. En utilisant Hive, nous tirons pleinement parti de la puissance de MapReduce, qui brille dans les situations où les quantités de données sont énormes.
Databricks semble un choix idéal lorsque l'expérience interactive sur ordinateur portable est indispensable, lorsque les ingénieurs de données et les informaticiens doivent travailler ensemble pour obtenir des informations à partir de données et s'adapter en douceur à différentes situations, car l'évolutivité est extrêmement facile. Un autre avantage de l'utilisation de Databricks est sa vitesse, grâce à Spark.
Data Lake Analytics est plus efficace lors des opérations de transformation et de chargement grâce au traitement à l'exécution et aux opérations distribuées.
