

La construction d'un Data Warehouse est assez similaire au développement d'une application comprenant une BDD relationnelle comme couche de persistance d'un point de vue projet. Vous avez autant (voire plus) de contraintes qui nécessitent une automatisation de la gestion du cycle de vie du schéma de données :
- Vous avez besoin de gérer plusieurs environnements (PROD, TEST, DEV, etc.) afin de pouvoir développer de nouvelles features sans risquer de mettre en péril le service et les valider fonctionnellement avant de déployer en production.
- Vous avez des pipelines d’ingestion de données (ETL/ELT) et des Dashboards (DataViz) à versionner afin de suivre l’évolution du schéma de données nécessaire pour ajouter des nouvelles features.
- Vous voulez (je l'espère en tout cas) faire profiter les utilisateurs des nouvelles features le plus rapidement possible sans passer votre vie à les mettre en production.
Vous avez donc tout intérêt à mettre en place les pipelines CI/CD dès le début de projet, et je vais vous montrer comment le faire facilement et rapidement pour Snowflake.
Le présent article est un retour d'expérience d’un projet récemment réalisé par Ippon dont la partie CI/CD était sous ma responsabilité. L’article n'a pas pour prétention d'être exhaustif ou de détenir la vérité absolue. Néanmoins, il vous donnera un bon point de départ pour vous lancer dans la construction de Data Warehouse avec Snowflake en mode DevOps.
Pourquoi Sqitch ?
Comme beaucoup de mes collègues je suis familier avec l’outil bien connu Liquibase (il fait partie de la stack JHipster), je voulais donc tout naturellement l’utiliser pour Snowflake. Le problème est que Liquibase ne supporte pas Snowflake nativement. Il existe une extension tierce, mais le projet ne semble pas être très actif. Le dernier commit date d’il y a plus de deux ans. Pour cette raison, je ne l'ai pas retenu.
Suite à mes recherches sur le forum de Snowflake, je suis tombé sur des retours positifs à propos de Sqitch, un outil similaire à Liquibase. Je l’ai installé (avec quelques douleurs quand même) et testé avec Snowflake, tout fonctionnait comme prévu. De plus, ce projet fournit le Dockerfile permettant d’utiliser Sqitch via un container Docker, ce qui m’a permis de gagner du temps lors de la mise en place des pipelines CI/CD sur Gitlab.
L’installation de Sqitch en local et son utilisation sortent du périmètre de cet article. Je vous laisse lire le manuel de Sqitch pour Snowflake. Cette présentation vous aidera à comprendre ses concepts rapidement.
Quels objets confier à Sqitch ?
Dès le début du projet, vous avez un choix à faire : décider quels types d’objet Snowflake vous allez gérer via Sqitch. Ce choix impacte la réalisation de vos scripts de migration et le workflow de la CI.
La hiérarchie des objets de Snowflake :
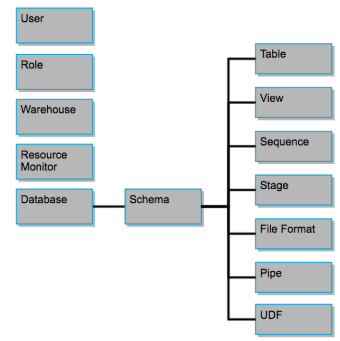
On distingue deux approches différentes :
- Automatiser uniquement la gestion du cycle de vie des objets appartenant à une Database (Schemas, Tables, Views, etc.).
- Gérer également les objets globaux.
La première approche a le mérite d’être simple. Pour détruire l’ensemble des objets créés par la CI, il suffit de supprimer la base de données. Il n’y a pas besoin de générer dynamiquement les noms des objets globaux en fonction de l'environnement.
L'inconvénient de cette approche est qu’elle ne permet pas la séparation des environnements au sein d’un même compte comme le préconise l’article d’Arnaud COL sur la gouvernance Snowflake. Vous serez obligés de créer des rôles statiques cross-environnement et de leur affecter les droits via scripts Sqitch sur les objets qu’ils créent. Gérer les droits à la main serait fastidieux, vous auriez perdu tout l’intérêt de l'automatisation.
Nous avons privilégié la deuxième approche en décidant de gérer le cycle de vie des Warehouses et des Roles par Sqitch.
Les avantages de cette approche :
- Les rôles dédiés à leurs environnements permettent de restreindre les accès aux données et aux ressources de production (on peut donner à un utilisateur un rôle ayant les droits sur l'environnement de test sans lui accorder les mêmes privilèges sur l’environnement de production).
- Les Warehouses dédiés à leurs environnements permettent de garantir que le service en production ne soit pas impacté par une quelconque activité sur un autre environnement. Cela permet également de suivre les coûts générés par chaque environnement.
- Cette approche permet de créer des environnements identiques sur des comptes Snowflake différents et donc de les isoler totalement. Nous n’avions pas besoin d’aller jusque là dans le cadre du projet réalisé.
En revanche, cette approche impose quelques contraintes :
- Elle nécessite un workflow plus complexe pour valider les scripts Sqitch par la CI. Il est facile de cloner une base de données Snowflake (zero-copy clone), mais ce n’est pas le cas pour l’ensemble de l’environnement qui intègre maintenant les Warehouses et les Roles. Vous allez voir le workflow que j’ai élaboré dans le paragraphe dédié.
- Elle demande plus de rigueur lors du développement. Si vous avez mis l’environnement de DEV dans un état incohérent et que vous souhaitez repartir from scratch, vous allez devoir supprimer à la main non seulement la base mais aussi tous les Warehouses et Roles associés, ce qui vous fera perdre du temps.
- Elle nécessite une technique qui permet de lier les objets globaux à un environnement dans les scripts Sqitch. Dans le paragraphe suivant, je vous donne l’astuce que nous avons utilisée.
Comment associer des objets à leurs environnements ?
Databases, Warehouses et Roles sont des objets globaux au sein d’un même compte Snowflake. Le seul moyen de les grouper par environnement est de respecter une convention de nommage. Même sans parler d’automatisation, préfixer les noms de ces objets par le nom de leur environnement constitue une bonne pratique.
La première idée qui vient à l'esprit est de passer le nom de l’environnement en paramètre de commande Sqitch :
> sqitch deploy <URI> --set env='TEST'
À l’exécution, Sqitch remplacera dans les scripts toutes les occurrences de &env par “TEST”.
L'inconvénient de cette approche est qu’il y a un risque de conflit entre ce paramètre et celui qui indique la base de données. Exemple :
> sqitch deploy 'db:snowflake:///PROD_DB?Driver=Snowflake' --set env='TEST'
De plus, la base de données à laquelle Sqitch va se connecter peut être configurée de trois façons différentes :
- dans l’URI (exemple ci-dessus),
- dans le fichier
~/.snowsql/config, - via la variable d'environnement SNOWSQL_DATABASE.
Pour éviter cette collision, et garantir que les requêtes s’exécutent sur la bonne base de données, il vous faudra commencer tous vos scripts par la requête :
USE DATABASE &env_DB;
ou utiliser le nom complet pour chaque objet. Exemple :
ALTER TABLE &env_DB.SALES_SCH.CUSTOMER ...;
Cela augmente considérablement le risque d’erreur. J’ai donc trouvé une autre solution qui consiste à déduire le nom de l’environnement du nom de la base de données :
SET env = split_part(current_database(), '_', 1);
On en a besoin uniquement dans les scripts qui manipulent les Warehouses et Roles. Il y a donc moins de code à écrire, moins de paramètres d'exécution, soit moins de risque d’erreur.
Que doit-on attendre de la CI/CD ?
Quand vous aurez écrit vos scripts, vous les aurez sans doute déjà testés (n’est-ce pas ?) sur l’environnement de développement, mais ce qui vous importe vraiment c’est de garantir que ces scripts s’exécuteront sans erreur en production. C’est l’unique objectif de la CI que j’ai configurée. Il peut y en avoir d’autres, comme par exemple déployer les modifications du schéma sur l’environnement de test/recette ou valider la compatibilité de l’ensemble des composants de la plate-forme. Libre à vous de la personnaliser.
Il est important de tester les scripts sur une copie complète de la base de production (schéma et données) pour les raisons suivantes :
- Les scripts peuvent contenir des requêtes de migration/transformation de données.
- Certaines modifications d’une table peuvent être acceptées ou rejetées en fonction des données qu’elle contient (modification de type de colonne, contraintes d’unicité, etc.).
L’énorme avantage de Snowflake par rapport aux autres solutions est que la copie complète d’une base de données est instantanée et ne coûte rien grâce à la fonctionnalité zero-copy clone. Seuls les deltas des données modifiées généreront un coût de stockage supplémentaire (uniquement si vos scripts modifient les données) sur une durée très courte (le temps d'exécution des pipelines CI). Vous avez donc la possibilité de réaliser le dry run de vos scripts de migration à un prix dérisoire et en un temps record.
L’objectif de mon CD est de déployer automatiquement les modifications du schéma en production. Bien évidemment, vous pouvez le compléter par le déploiement des autres composants de votre plateforme (Ingestion et DataViz).
Voici donc mes besoins exprimés sous forme de User Story :
- En tant que Dev paresseux, je veux que mes scripts (deploy & revert) soient validés automatiquement sur un environnement identique à la production dès que je push un nouveau commit sur une branche de merge request et je veux être notifié en cas d’erreur.
- En tant que “pas Ops du tout”, je veux que les modifications du schéma soient appliquées automatiquement en production dès qu’une merge request est validée et mergée sur le master.
Ma recette pas-à-pas
Snowflake
Tout d’abord, créez un Warehouse configuré pour être le plus économique possible sur votre compte Snowflake nommé SQITCH (c’est le Warehouse que Sqitch utilise par défaut) :
CREATE WAREHOUSE SQITCH WITH
WAREHOUSE_SIZE = 'XSMALL'
WAREHOUSE_TYPE = 'STANDARD'
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE
MIN_CLUSTER_COUNT = 1
MAX_CLUSTER_COUNT = 1
INITIALLY_SUSPENDED = TRUE;
Ensuite, créez un utilisateur dédié à la CI/CD (je l’ai appelé SQITCH également) :
CREATE USER SQITCH
PASSWORD = <pwd>
MUST_CHANGE_PASSWORD = FALSE;
Cet utilisateur aura besoin des rôles SYSADMIN et SECURITYADMIN :
GRANT ROLE SYSADMIN TO USER SQITCH;
GRANT ROLE SECURITYADMIN TO USER SQITCH;
Gitlab
Afin d’exécuter les commandes Sqitch par le service CI/CD de Gitlab, il vous faudra une image Docker qui embarque l’outil avec toutes ses dépendances correctement configurées.
Pour ne pas réinventer la roue, j’ai pris le Dockerfile de ce projet qui fournit un wrapper des commandes Sqitch permettant de les exécuter via un container (sans installer Sqitch et ses dépendances). J’ai donc dû le modifier légèrement pour l’adapter à la CI/CD de Gitlab.
Voici le contenu de mon Dockerfile :
FROM debian:stable-slim AS snow-build
WORKDIR /work
# Download the ODBC driver and SnowSQL.
# https://docs.snowflake.net/manuals/user-guide/snowsql-install-config.html#downloading-the-snowsql-installer
# https://docs.snowflake.net/manuals/release-notes/client-change-log-snowsql.html
ADD https://sfc-snowsql-updates.s3.us-west-2.amazonaws.com/bootstrap/1.1/linux_x86_64/snowsql-1.1.81-linux_x86_64.bash snowsql.bash
# https://sfc-repo.snowflakecomputing.com/index.html
ADD https://sfc-repo.snowflakecomputing.com/odbc/linux/2.19.5/snowflake_linux_x8664_odbc-2.19.5.tgz snowflake_linux_x8664_odbc.tgz
COPY conf ./
# Tell SnowSQL where to store its versions and config. Need to keep it inside
# the image so it doesn't try to load the version from $HOME, which will
# typically be mounted to point to the originating host.
ENV WORKSPACE /var/snowsql
# Set locale for Python triggers.
ENV LC_ALL=C.UTF-8 LANG=C.UTF-8
# Install prereqs.
ARG sf_account
RUN apt-get -qq update \
&& apt-get -qq --no-install-recommends install odbcinst \
# Configure ODBC. https://docs.snowflake.net/manuals/user-guide/odbc-linux.html
&& gunzip -f *.tgz && tar xf *.tar \
&& mkdir odbc \
&& mv snowflake_odbc/lib snowflake_odbc/ErrorMessages odbc/ \
&& mv simba.snowflake.ini odbc/lib/ \
&& perl -i -pe "s/SF_ACCOUNT/$sf_account/g" odbc.ini \
&& cat odbc.ini >> /etc/odbc.ini \
&& cat odbcinst.ini >> /etc/odbcinst.ini \
# Unpack and upgrade snowsql, then overwrite its config file.
&& sed -e '1,/^exit$/d' snowsql.bash | tar zxf - \
&& ./snowsql -Uv \
&& echo "[connections]\naccountname = $sf_account\n\n[options]\nnoup = true\nlog_bootstrap_file = ./log_bootstrap\nlog_file = ./log" > /var/snowsql/.snowsql/config
FROM sqitch/sqitch:latest
ENTRYPOINT [""]
# Install runtime dependencies, remove unnecesary files, and create log dir.
USER root
RUN apt-get -qq update \
&& apt-get -qq --no-install-recommends install unixodbc \
&& apt-get clean \
&& rm -rf /var/cache/apt/* /var/lib/apt/lists/* \
&& rm -rf /man /usr/share/man /usr/share/doc \
&& mkdir -p /usr/lib/snowflake/odbc/log \
&& printf '#!/bin/sh\n/var/snowsql --config /var/.snowsql/config "$@"\n' > /bin/snowsql \
&& chmod +x /bin/snowsql
# Install SnowSQL plus the ODDB driver and config.
COPY --from=snow-build /work/snowsql /var/
COPY --from=snow-build --chown=sqitch:sqitch /var/snowsql /var/
COPY --from=snow-build /work/odbc /usr/lib/snowflake/odbc/
COPY --from=snow-build /etc/odbc* /etc/
# The .snowsql directory is copied to /var.
USER sqitch
ENV WORKSPACE /var
Container Registry de Gitlab permet de stocker les images Docker spécifiques aux projets. Si votre projet est sur un Gitlab interne de votre société, il est possible que cette fonctionnalité ne soit pas activée. Vous pouvez donc soit demander à l’administrateur de Gitlab de l'activer soit utiliser un autre dépôt d’images. Sur gitlab.com, Container Registry fait partie de l’offre gratuite.
Buildez et uploadez votre image avec les commandes suivantes :
> docker build &&
--tag registry.gitlab.com/<account>/<project>/sqitch/sqitch:sqitch-snowsql . &&
--build-arg sf_account=<snowflake account>
> docker login registry.gitlab.com
> docker push registry.gitlab.com/<account>/<project>/sqitch/sqitch:sqitch-snowsql
Vous pouvez désormais configurer vos pipelines CI/CD en ajoutant le fichier .gitlab-ci.yml à la racine de votre projet. Voici le contenu du mien :
image: registry.gitlab.com/<account>/<project>/sqitch/sqitch:sqitch-snowsql
variables:
SNOWSQL_ACCOUNT: <account>.<region>
SNOWSQL_REGION: <region>
SNOWSQL_WAREHOUSE: sqitch
SNOWSQL_ROLE: sysadmin
PROD_URI: db:snowflake://${SNOWSQL_ACCOUNT}.snowflakecomputing.com/PROD_DB?Driver=Snowflake
stages:
- test
- deploy
test_sqitch:
stage: test
script:
- ISSUE_ID=$(echo $CI_COMMIT_REF_NAME | cut -d'-' -f 1)
- export SNOWSQL_DATABASE="CI${ISSUE_ID}_DB"
- export URI="db:snowflake://${SNOWSQL_ACCOUNT}.snowflakecomputing.com/${SNOWSQL_DATABASE}?Driver=Snowflake"
- cd sqitch
- /bin/snowsql -q "CREATE DATABASE $SNOWSQL_DATABASE;"
- PROD_STATE=$(sqitch status $PROD_URI | grep '# Name:' | cut -d':' -f2 | awk '{$1=$1};1')
- /bin/sqitch deploy $URI --mode change --to $PROD_STATE
- /bin/snowsql -q "DROP DATABASE $SNOWSQL_DATABASE;"
- /bin/snowsql -q "CREATE DATABASE $SNOWSQL_DATABASE CLONE PROD_DB;"
- /bin/sqitch deploy $URI --mode change
- /bin/sqitch revert $URI
- /bin/snowsql -q "DROP DATABASE $SNOWSQL_DATABASE;"
only:
refs:
- merge_requests
changes:
- sqitch/**/*
deploy_sqitch:
stage: deploy
variables:
SNOWSQL_DATABASE: PROD_DB
script:
- cd sqitch
- /bin/sqitch deploy $PROD_URI
only:
refs:
- master
changes:
- sqitch/**/*
Si le workflow du CD (deploy_sqitch) est très simple et parle de lui-même, celui de la CI (test_sqitch) mérite quelques explications :
- Il crée un environnement vierge dont le nom est suffixé par le numéro de la tâche afin d’éviter tout risque de collision avec un autre environnement.
- Il exécute les scripts Sqitch uniquement jusqu’à l’état actuel de la production afin de créer l’ensemble des objets globaux (Warehouses et Roles) qui ne peuvent pas être copiés depuis l’environnement de production.
- Il remplace la base créée par une copie de la base de production.
- Il exécute les scripts Sqitch afin d’appliquer les nouvelles modifications.
- Il détruit l’ensemble de l’environnement en exécutant les scripts revert (voilà pourquoi il est important de les implémenter correctement).
Dans cette approche, il est possible que la CI retourne une erreur sans que ce soit la faute du développeur qui a commité les scripts. Cela se produira, par exemple, si l’état de la base de production a été modifié outre que par le CD. Le résultat reste le même : les modifications ne peuvent pas être appliquées à la production et il vaut toujours mieux s’en rendre compte rapidement.
Comme vous pouvez le remarquer, il n’y a ni le login ni le mot de passe de l’utilisateur Snowflake dans le fichier .gitlab-ci.yml. Pour des raisons évidentes, ces informations ne doivent pas se retrouver dans le code source. Il faut donc les configurer via des variables d’environnement que Gitlab stockera encryptées et injectera dans les pipelines CI/CD.
Allez dans Settings → CI/CD → Variables et ajoutez les variables SNOWSQL_USER et SNOWSQL_PWD.

Voici à quoi vont ressembler les logs de votre CI :
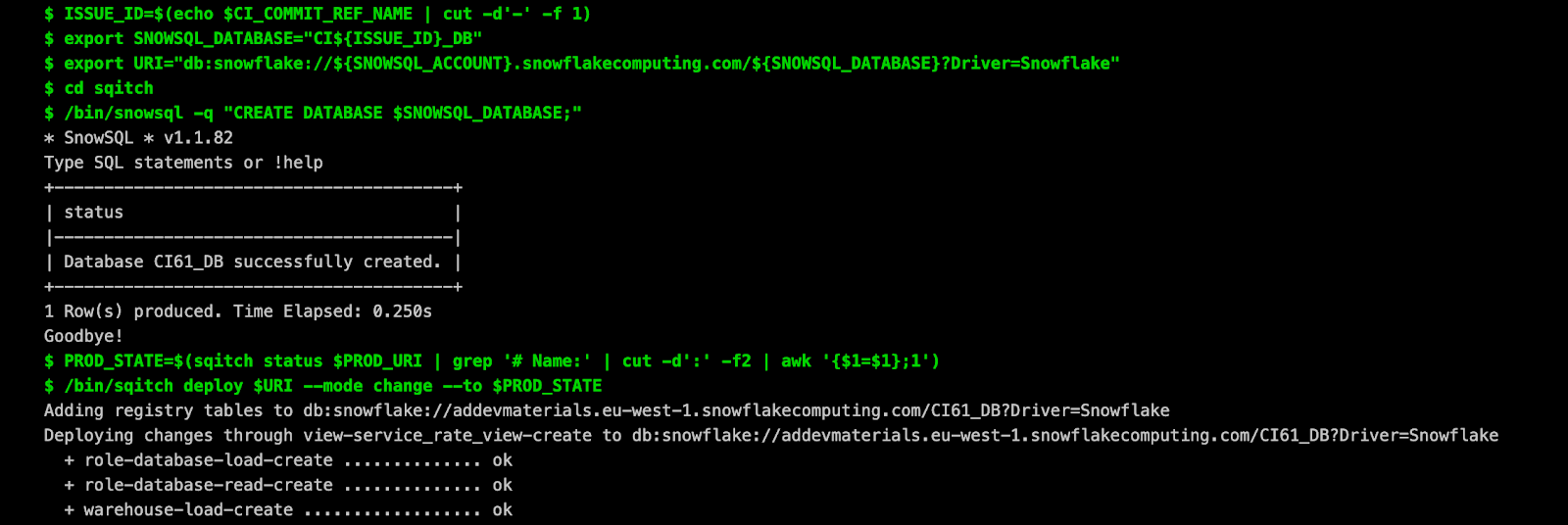
…
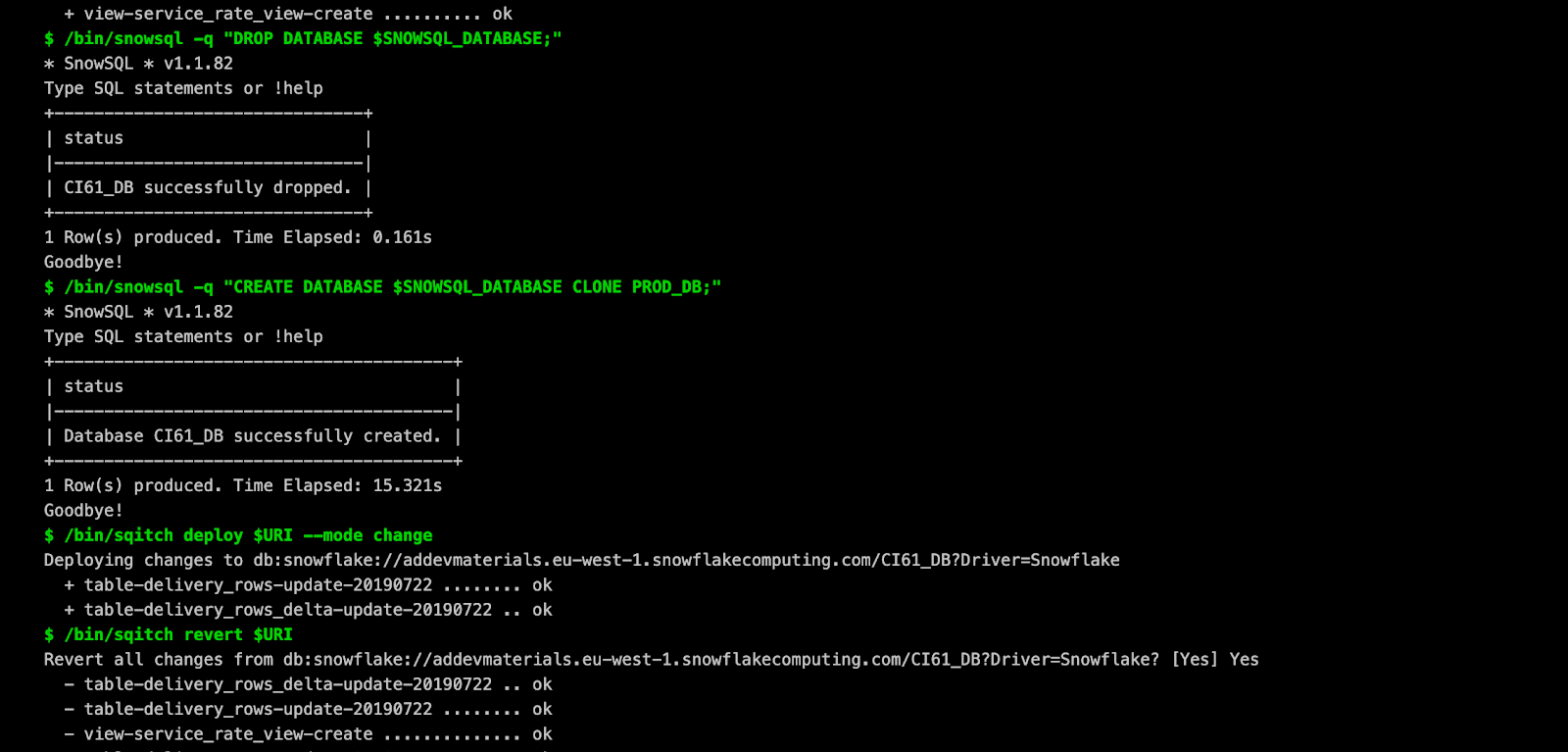
…

Vous pouvez désormais activer l’option de Merge Approvals dans Gitlab (sur gitlab.com, il faut avoir au moins le niveau Bronze à 4$/mois pour en bénéficier) qui n'autorisera de merger dans le master une merge request que lorsque toutes les pipelines associées sont terminées avec succès.
Allez dans Settings → General → Merge Requests et cochez la case :

Quelques conseils
- Si vous n’êtes pas familier avec Sqitch prenez le temps de jouer avec cet outil pour bien comprendre son fonctionnement et ses limites.
- Limitez la portée des modifications d’un script à un seul objet pour avoir la meilleure traçabilité des changements et limiter le risque d’erreur dans le script revert.
- Implémentez et testez toujours le script revert tant que les changements sont réversibles. Cela permet de revenir à un état stable en cas d’erreur lors de déploiement et de détruire l’ensemble des objets créés par la CI.
- Autant que possible, ne faites qu’une seule requête par script afin de limiter le risque de mettre la base dans un état intermédiaire. Snowflake ne permet pas de faire les modifications de schéma de façon transactionnelle.
- Créez une convention de nommage pour les scripts Sqitch. Vu que chaque modification du schéma est représentée par un fichier dont le nombre va sans cesse grandir, une convention de nommage vous permettra de mieux les organiser grâce au tri alphabétique. Voici le pattern de nommage que nous avons utilisé :
<object>-<name>-<CRUD>(-<date>).
Exemples :
schema-sales-createtable-customer-createtable-customer-update-20190101
- Faites très attention lorsque vous écrivez les scripts à ne jamais spécifier la base de données en dur dans les requêtes.
- Créez toujours les Warehouses avec l’option
INITIALLY_SUSPENDED = TRUEpour ne pas gaspiller votre argent (ou l’argent de votre client) à chaque déclenchement de la CI.
Conclusion
Avec cet outillage, vous pouvez valider vos montées de version de base de données en toute sérénité. Et la bonne nouvelle, c’est que cela ne vous coûtera quasiment rien car les ordres DDL ne sont pas facturés par Snowflake et son zero-copy clone ne consomme pas du stockage.
La CI/CD vous permet également de vous concentrer sur la création de la valeur métier en automatisant les tâches répétitives et chronophages.
En partant des configurations que je vous ai présentées, vous pouvez mettre en place votre CI/CD rapidement et l’améliorer ou la compléter par la suite pour mieux correspondre à vos besoins.
