
Cet article fait partie d'une série visant à accompagner les entreprises dans leur migration d'un SI Big Data existant vers les offres cloud d'AWS.
Le but de cette série n'est pas de faire un comparatif détaillé sur l'intérêt d'une migration vers le Cloud ! Nous supposons que le choix est déjà fait et qu'il faut donc choisir parmi les solutions natives proposées par AWS la plus adaptée.
Les solutions cibles favorisées sont les solutions natives équivalentes lorsqu'elles existent (Kinesis, DynamoDB, ...) et non les offres managées (solutions externes hébergées).
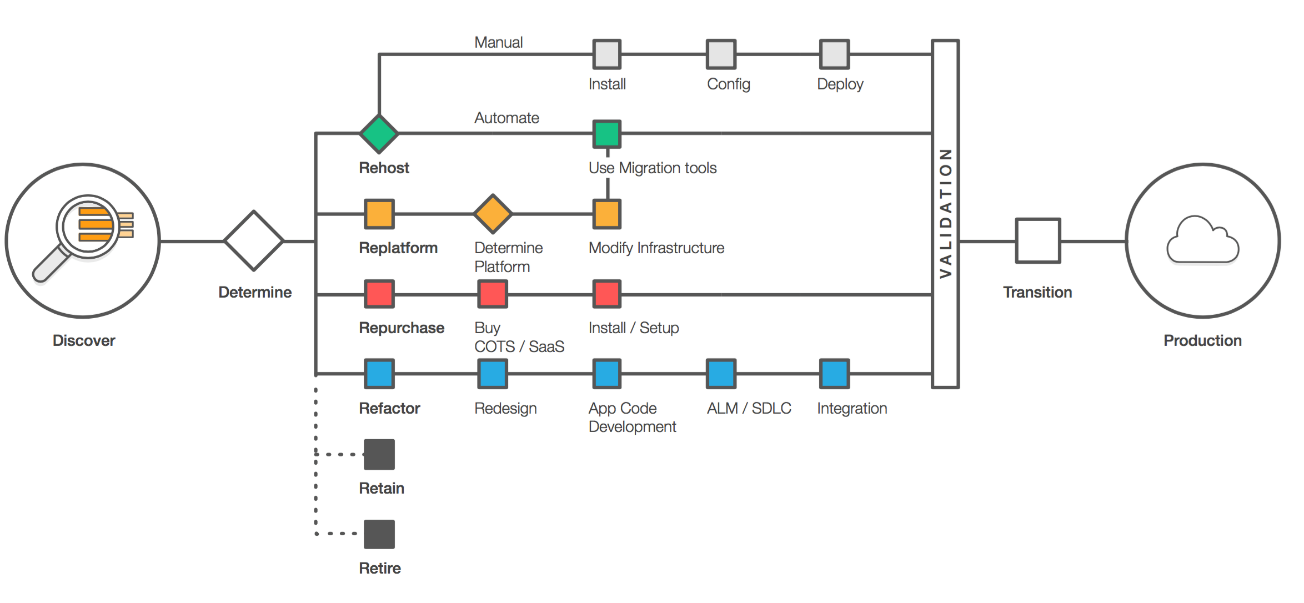
Nous avons donc privilégié le replatforming et non le lift and shift (Cf. stratégies de migration vers le cloud, les "6 R").
En effet, les solutions natives offertes par AWS présentent les avantages suivants :
- Administration simplifiée et entièrement prise en charge par AWS
- Facturation plus avantageuse
- Solution parfaitement intégrée dans l'écosystème AWS
Chacun des articles de la série va s'intéresser à une solution source très répandue dans le monde du Big Data et permettre :
- De comprendre les différences fondamentales entre les solutions,
- D'identifier les cas d'usage propices à la migration vers les solutions natives,
- D'identifier les cas d'usage propices à la migration vers une solution managée.
Introduction
On va retrouver les solutions Kafka et Kinesis dans des architectures orientées événements et temps réel afin de stocker des messages correspondants à des événements au sein du SI :
- nouvelles données,
- modification de données existantes,
- événements métiers nécessitant le recalcul de données,
- ...
Ce sont des solutions d'ingestion de données avec les notions communes suivantes :
- durabilité des messages,
- scalabilité grâce au partitionnement et à la notion de réplication,
- résilience des données grâce à la notion de réplication,
- notion de consommateur et de producteur.
Le cœur des deux systèmes est une log immutable de messages ordonnés.
Les nouveaux messages sont ajoutés à la fin et référencés par un identifiant unique (sa position dans la log).
Genèse des projets
Kafka
L'histoire d'Apache Kafka commence en 2010 chez LinkedIn pour des besoins internes, en voici les dates clés :
- 2011 : le projet devient open source
- 2012 : Le projet intègre l'incubateur Apache
- 2014 : Les créateurs du projet fondent la société Confluent
- 2018 : AWS annonce une offre Kafka entièrement managée lors du salon Re:Invent (https://aws.amazon.com/fr/msk/)
Kinesis
- 2013 : Amazon Web Services annonce le lancement de Kinesis lors de re:Invent:2013, fortement inspiré par Kafka. Le service est réellement disponible en décembre 2013.
- 2015 : Kinesis Data Firehose
- 2016 : Kinesis Data Analytics
Architecture et écosystème
Bien que d'architecture et de concepts assez similaire, il est important de connaître l'équivalence des notions entre Kafka et Kinesis.
Comparaison des notions
| Kafka | Kinesis |
|---|---|
| Topic | Kinesis stream |
| Offset | Sequence |
| Partition | Shard |
| Broker | Instance |
| Facteur de réplication | Sans objet (les données sont automatiquement répliquées dans 3 zones de disponibilité) |
| Groupe de consommateurs | Nom de l'application (AppName) |
| Kafka Stream | Kinesis Analytics / Kinesis Firehose / Framework de streaming |
Écosystème Kafka
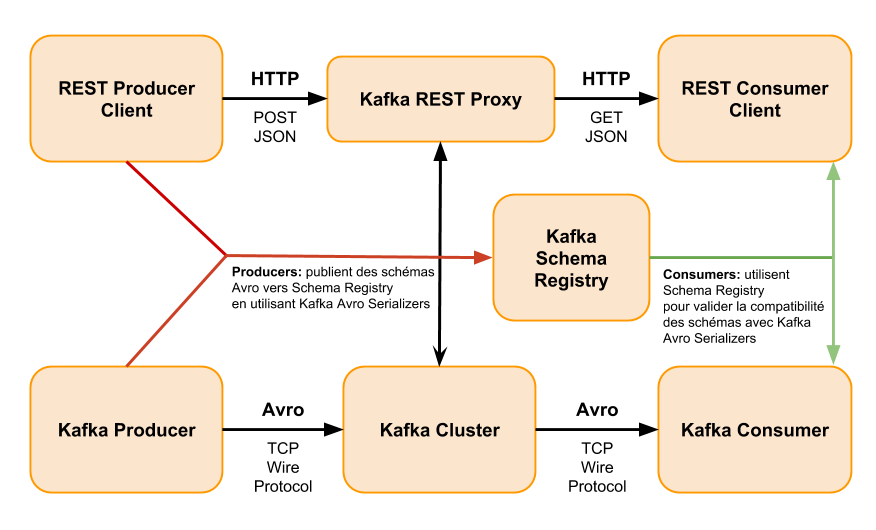
Zookeeper :
• stocke la composition du cluster
• gère indirectement les signaux de vie des brokers
• liste les consommateurs
Kafka Stream :
• Framework de streaming
Kafka Connect :
• Framework gérant l'alimentation et l'export des messages
Schema Registry :
• Permet le contrôle et le versioning des schémas des messages
Confluent Control Center :
• Monitoring et administration d'un cluster Kafka (Confluent)
Kafka Rest proxy :
• Expose les API Kafka en REST
Écosystème Kinesis
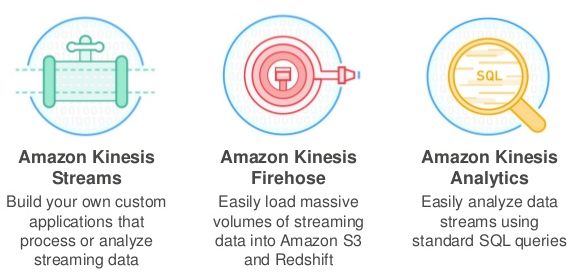
Amazon Kinesis Streams
• Stockage et streaming des messages
Amazon Kinesis Firehose
• Transfert des message vers/depuis S3/Redshift/Splunk/Amazon Elasticsearch Service
Amazon Kinesis Analytics
• Requêtage SQL des données contenues dans les messages
Cloudwatch
• Monitoring
DynamoDB
• Stockage de la position des consommateurs (sequence)
Kinesis Agent
• Alimentation Kinesis Stream depuis des fichiers (https://github.com/awslabs/amazon-kinesis-agent)
Kinesis Firehose permet d'alimenter la solution Kinesis. Il peut aussi transformer les données et alimenter d'autres systèmes tels que S3, Redshift ou ElasticSearch.
La création d'un flux peut se faire simplement depuis la console AWS, la scalabilité est automatisée ainsi que certaines optimisations (compressions, regroupement par lots).
Kinesis Analytics permet d'interroger les données stockées dans Kinesis avec des ordres SQL. Toute la partie technique (scalabilité, déploiement, …) est automatiquement gérée par le framework.
Différences entre les solutions
Nous allons détailler les critères différenciant et pertinant dans le choix d'une solution cible.
Architecturales
Kafka ne propose pas nativement de solution pour gérer le multi-datacenter, un cluster déployé sur deux datacenters sera vu comme un seul cluster et les latences entre les deux peuvent poser problème pour le bon fonctionnement.
La solution est donc de déployer un cluster dans chacun des datacenters et de les synchroniser avec une des solutions suivantes :
- MirrorMaker (open source)
- Confluent Replicator (étend MirrorMaker mais solution propriétaire)
Kinesis est par nature multi-datacenter puisque les services et les messages sont distribués automatiquement dans 3 datacenters (Availability Zone).
Il n'est par contre pas possible de déployer un même cluster dans plusieurs régions.
Performances et accès concurrents
Avec Kafka, il n'y a pas de limite sur le nombre d'accès à une partition mais en pratique les constats suivants ont été faits :
- On augmente les performances en augmentant le nombre de partitions d'un Topic.
- En augmentant le nombre de partitions on augmente la taille mémoire utilisée par les clients (buffer).
Si en théorie, il n'y a pas de limite globale avec Kinesis, la facturation est proportionnelle au nombre de shards utilisés. Il est donc important de connaître les seuils imposés sur les shards.
Kinesis impose des limitations sur les capacités des shards :
- Écriture : 1000 insertions par seconde ou 1Mo/s
- Lecture : 5 transactions par seconde ou 2 Mo/s
Si les besoins sont supérieurs alors il faut augmenter le nombre de shards (et donc la facturation).
Une autre possibilité consiste à utiliser la diffusion améliorée qui autorise 2 Mo/s par partition (utilisé en général pour les cas d'utilisation à plusieurs consommateurs). Là encore c'est une option payante.
Par défaut, chaque compte peut mettre en service jusqu'à 10 partitions par région. Au-delà il faut remplir un formulaire.
Latences
Du fait des différences d'architecture, les latences ne sont pas comparables entre une offre Kafka hébergée et Kinesis :
- Pas de colocalisation entre les données et les traitements
- Les limitations liées à la facturation présentées ci-dessus qui vont favoriser un faible nombre de shards
- Le déploiement systématique sur 3 datacenters
Kafka :
- Ecriture 10 ms
- Lecture 50 ms
Kinesis :
- Ecriture 35 ms
- Lecture 150 ms (mais plutôt une seconde avec les paramètres par défaut)
Il est à noter que Kinesis étant écrit en C++, il n'est pas soumis de la même façon que Kafka aux latences du Garbage Collector. Les latences sont donc plus stables.
Delivery semantics
Kafka peut proposer pour les producteurs une sémantique de type "Exactly once" avec une notion de transaction.
Kinesis propose une sémantique de type "at least once". Cela veut dire qu'il ne peut garantir qu'un message ne sera délivré qu'une seule fois.
Rétention
La rétention dans Kafka et Kinesis va déterminer la durée de conservation des messages dans leur système de stockage respectif.
Elle va définir :
- le temps imparti pour le traitement des messages
- le temps imparti pour la remise en état du système en cas de défaillance
- le temps imparti pour l'analyse d'éventuels problèmes (perte de message par exemple)
Valeurs par défaut :
- 24 heures pour Kinesis
- 168 heures (7 jours) pour Kafka
Ce délai de rétention est configurable dans les deux cas mais ne peut excéder 7 jours pour Kinesis.
Une solution habituelle afin d'augmenter ce délai, est de stocker les messages dans S3.
Il existe un projet nommé Kinesis VCR qui permet de rejouer les messages stockés dans S3 en utilisant l'API Kinesis.
NB : l'augmentation de la période de rétention au-delà d'un jour, est facturée pour Kinesis
Compaction log
La fonctionnalité de compaction d'une Log permet de conserver indéfiniment la dernière valeur du message pour chaque identifiant.
Cela permet d'être en mesure de reconstituer les données en cas de crash.
Cette fonctionnalité est aussi utilisée pour implémenter le GDPR dans Kafka (on insère une valeur nulle qui écrase l'ancienne valeur et permet donc de supprimer une donnée)
Taille maximale d'un message
Dans les deux systèmes les tailles des messages sont limitées :
- 1 Mo dans Kinesis
- 10 Mo dans Kafka (modifiable)
Toutefois les deux systèmes n'ont pas été conçus pour le traitement de messages de taille importante et privilégient les messages de 100 Ko maximum.
C'est d'autant plus vrai avec Kinesis où la taille des messages influe sur le débit et donc sur la facturation.
Tolérance à la panne (acquittement des messages)
Afin d'assurer la résilience des messages, les producteurs doivent être assurés du bon déroulement de l'insertion.
Kafka : un paramètre nommé ack permet de définir le nombre de brokers devant acquitter la bonne réception des messages. Ce paramètre est configurable et une bonne pratique est de le définir tel qu'une majorité de brokers soient impliqués.
Kinesis : lors de l'insertion d'un message, il est répliqué de manière synchrone dans les 3 zones de disponibilité d'une région.
Contrairement à Kafka on ne peut donc pas privilégier les performances au détriment de la disponibilité.
Compression
La compression des messages permet d'améliorer les performances et d'éviter la saturation du réseau.
Dans les deux systèmes, il existe un système natif de buffers afin d'optimiser les échanges réseau.
L'envoi vers le serveur ne se fait que lorsque le buffer à atteint sa capacité maximale ou qu'un temps d'attente est dépassé.
Kafka : Si un Topic peut être défini comme compressé, il est conseillé de le faire coté client, trois options sont alors possibles : None, GZip et Snappy.
Kinesis : Il n'existe pas d'équivalent et une compression doit être gérée de manière applicative.
Toutefois une optimisation permet d'en réduire le besoin.
Les enregistrements sont groupés et sérialisés en utilisant le format Protocol Buffers (Amazon Kinesis Producer Library).
Registre de schéma
Le registre de Schema (Schema Registry) est une solution open source de Confluent et permet de définir un schéma pour les messages des Topics et ainsi contrôler le formalisme des données et leur évolution.
Il permet de s'assurer de la compatibilité des schémas des producteurs et des consommateurs Kafka avec une vérification automatisée. Il fournit au consommateur des sérialiseurs compatibles avec les messages consommés.
Il n'existe pas d'offre similaire dans Kinesis mais il est toutefois possible de valider de manière applicative le format des messages publiés ou récupérés depuis la plateforme.
Maintenabilité
C'est bien sûr le point fort de l'offre d'AWS (et de toute offre de type SAAS), la maintenance du cluster est portée par AWS.
Cela permet de libérer les équipes de cette charge et donc de diminuer les coûts de maintenance.
À l'opposé on ne maîtrise pas les versions utilisées et les migrations sont donc plus fréquentes.
Header de messages
Cette fonctionnalité existe depuis la version 0.11 de Kafka et n'est pas présente dans Kinesis.
Elle permet d'ajouter des informations liées à un message sans en polluer le contenu.
Le plus souvent il s'agira d'informations techniques sur la provenance des messages ou leur format.
Monitoring
Kafka, comme beaucoup de programmes écrits en Java, expose de nombreux MBeans et permet d'être assez précis sur la santé d'un cluster et sur ses performances.
Les métriques exposées par Kinesis sont plus simples mais permettent tout de même de suivre l'état de santé du cluster et ses performances.
En termes d'outils de supervision et d'administration, les deux solutions principales sont les suivantes :
- Cloudwatch pour Kinesis.
- Confluent Control Center pour Kafka (outil payant).
Cloudwatch n'est bien sûr pas limité à Kinesis et offre donc l'avantage d'une interface de monitoring unifiée au détriment du nombre de métriques disponibles.
Outre la latence, le débit et le pourcentage OK (lecture et écriture) on trouve le retard entre le consommateur et le stream (âge de l'itérateur) et deux métriques dédiées à la facturation (dépassement limite en lecture/écriture).
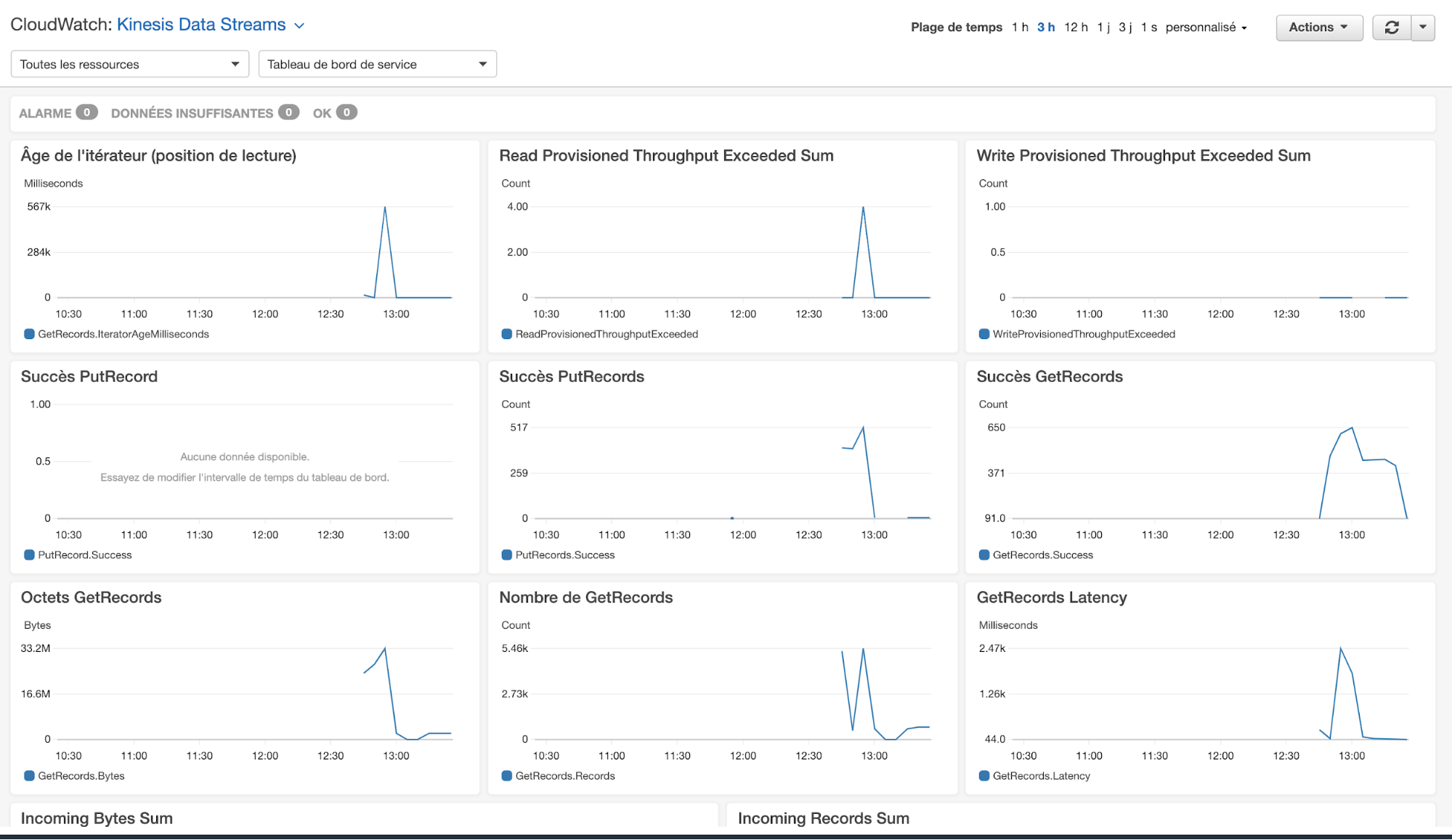
Les métriques peuvent être customisées et pour accéder à des métriques plus fines (au niveau shard), il faut payer un supplément.
Gestion des exceptions
Il existe deux façons d'interagir avec un service Kinesis :
- Au travers des librairies clientes, Kinesis Producer Library et Kinesis Client Library disponibles en Java et C++.
- En utilisant le SDK AWS et les API Kinesis.
L'utilisation des API Kinesis offre un meilleur contrôle des opérations et de meilleures performances au prix d'une complexité d'utilisation plus grande.
Par exemple seules les librairies KPL et KCL proposent un mécanisme de retry automatique.
Même en utilisant KPL et KCL, la gestion des codes d'erreurs est plus fine avec Kafka au travers du driver client.
En effet Kinesis est un service web et retourne donc un code HTTP qui n'offre pas la finesse du client Kafka.
Scalabilité (Partitionnement automatique)
Kinesis permet de mieux gérer la répartition de charge en proposant de :
- Scinder une partition (shard) afin de répartir la charge
- Réunir deux shards afin de limiter les coûts
Récemment (Re:Invent 2018) a d'ailleurs annoncé un nouveau service entièrement automatisé de dimensionnement du nombre de shards d'un cluster : AWS Application Auto Scaling.
Avec Kafka la modification du partitionnement se fait essentiellement avec l'ajout/suppression de brokers puis avec la création d'une nouvelle partition des données qui est une opération manuelle à moins de disposer de Confluent Control Center.
Atomicité inter-partitions
Dans Kafka cette fonctionnalité permet de grouper l'insertion de messages destinés à des partitions différentes et donc de garantir qu'un ensemble de messages liés seront tous correctement insérés.
Dans Kinesis, cette fonctionnalité n'est pas présente, l'insertion en batch étant limitée à un shard.
Gestion des offset
On appelle Offset dans Kafka et Séquence dans Kinesis la position unique d'un message dans les logs et par conséquent la position courante d'un consommateur dans sa lecture des messages d'un Topic/Stream.
Sauvegarder la position courante d'un consommateur permet de garantir qu'un message ne sera traité qu'une seule fois même en cas de reprise.
Kafka permet une gestion automatique ce cette sauvegarde (un thread asynchrone la sauvegarde automatiquement au bout de x secondes après la récupération d'un message) mais aussi une gestion manuelle.
Kinesis ne propose qu'une gestion manuelle appelée checkpoint.
Enfin, avec Kafka les Offset sont généralement stockés dans un topic spécial alors que Kinesis utilise DynamoDB pour le stockage des Séquences.
Horodatage automatique des messages
Les messages sont automatiquement horodatés par le serveur Kafka ou Kinesis.
Cette fonctionnalité est utile dans les cas suivants :
- permet de faire des filtres sur l'âge des messages,
- permet de faire des regroupements sur l'âge des messages, tout en évitant l'ajout d'un champ dans le corps du message.
La principale différence entre Kafka et Kinesis est l'impossibilité de définir (et donc surcharger) ce timestamp côté client lorsque l'on utilise le service Kinesis.
Tests unitaires et d'intégration
Pour Kafka il existe des frameworks qui vont faciliter les tests unitaires et d'intégration en simulant le comportement d'un cluster sans avoir à en déployer.
Il n'existe pas d'équivalent pour Kinesis (que seul AWS pourrait fournir).
Toutefois il existe des possibilités de simuler les services AWS avec le projet localstack : https://github.com/localstack/localstack
Streaming
De nombreux frameworks de Streaming sont compatibles avec Kafka :
- Kafka Streams
- Spark
- Flink
- Storm
- …
Avec Kinesis :
- Amazon Kinesis Firehose
- Amazon Kinesis Analytics
- Apache Spark, Flink, Storm, …
Langage d'interrogation SQL
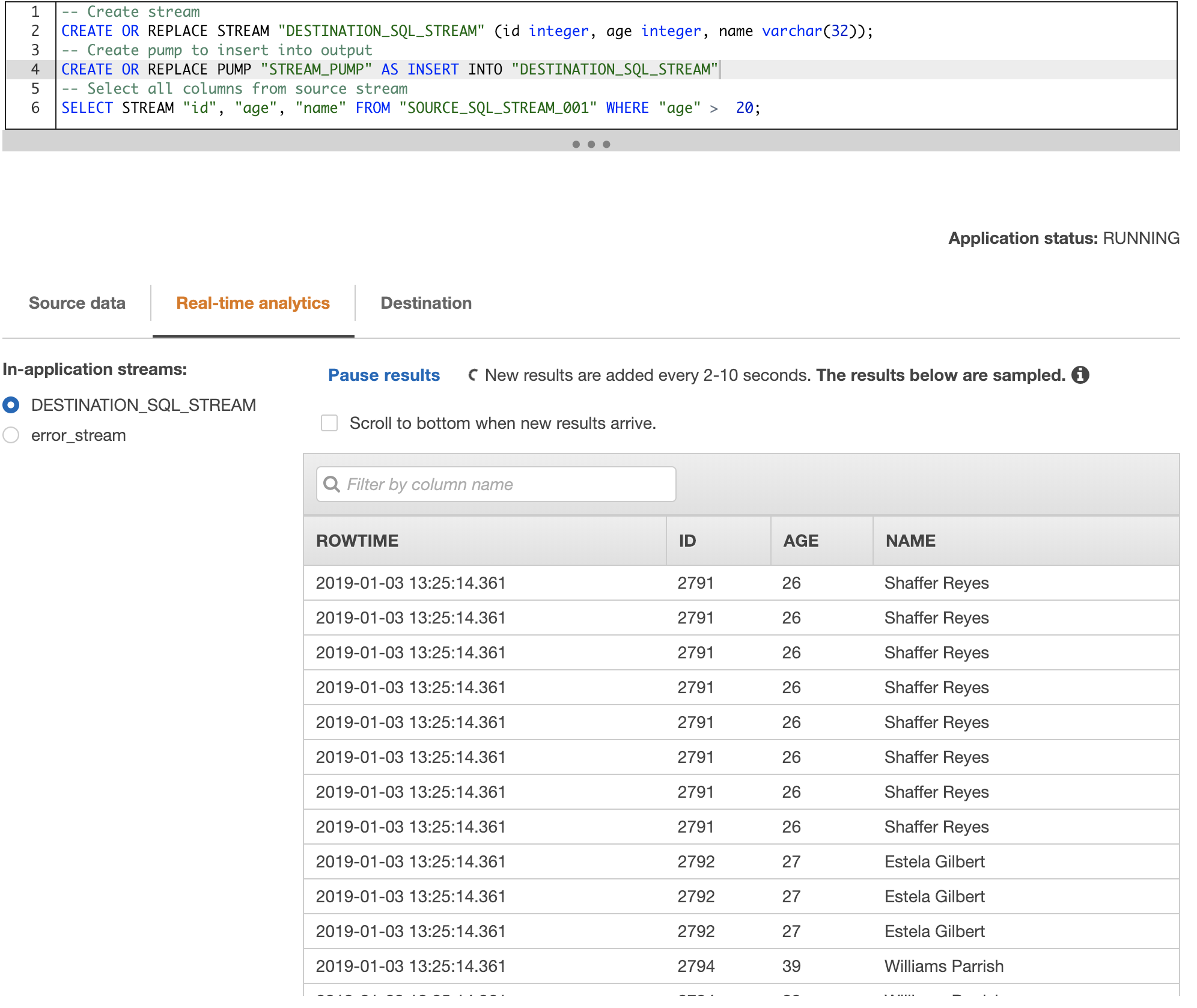
KSQL est un projet Confluent qui permet d'instancier un serveur REST ou une API permettant d'utiliser le langage SQL afin de requêter les messages des Topics (les ordres SQL sont traduits en programme Kafka Stream).
KSQL est assez complet mais reste limité par rapport aux possibilités offertes par Kafka Stream.
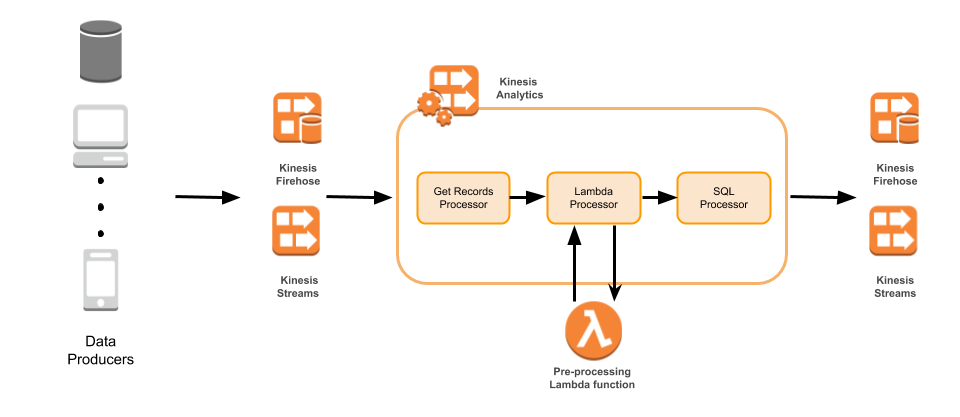
Kinesis Analytics poursuit le même but avec les différences suivantes :
- Autre source qu'un topic (Stream) Kinesis : par ex S3
- Les ordres SQL sont traduits en fonctions Lambda ou en programme Java (Flink)
- Auto-découverte du schéma
- Template SQL avec les principaux cas d'utilisations
- Destination (Kinesis Streams, Redshift, S3, …)
Plus d'informations Amazon Kinesis Analytics
Configuration des solutions
Kinesis, en tant que solution managée est beaucoup plus simple à configurer qu'un cluster Kafka. En conséquence il est beaucoup plus difficile de l'adapter au cas d'usage.
C'est donc côté client que la majorité des ajustements peuvent intervenir (27 paramètres tout de même pour la Kinesis Producer Library).
Sécurité
Kinesis permet les options suivantes :
- Mise en place de stratégies AWS IAM pour la gestion des autorisations
- SSL pour le chiffrement des flux
- Chiffrement/déchiffrement côté serveur avec AWS KMS des données stockées (chiffrement de bout en bout)
- Chiffrement/déchiffrement côté client.
- Audit avec AWS CloudTrail
Kafka permet les options suivantes :
- Authentification des connexions internes et externes : SSL ou SASL (Kerberos)
- Authentification entre brokers et ZooKeeper
- Client : Gestion des rôles (écriture et lecture)
- Chiffrement sur disque : pas géré par Kafka mais par l'OS.
Certains types de données (médicale, bancaire) exigent des garanties supplémentaires et peuvent être un frein à l'adoption du cloud grand public.
Certifications AWS Kinesis
- Conformité stockage et traitement de données médicales (loi HIPAA et programme FedRAMP)
- Certification HDS (Hébergeur de Données de Santé)
- Données bancaires (PCI DSS)
Automatisation du déploiement
Il n'y a pas de solution préférentielle pour Kafka, les solutions suivantes sont possibles :
- Kubernetes (à venir Cf. https://www.confluent.io/confluent-operator/)
- Chef https://www.chef.io/chef/
- Ansible https://github.com/confluentinc/cp-ansible
Pour Kinesis la solution privilégiée est bien évidemment AWS CloudFormation.
AWS CloudFormation est le framework de déploiement des solutions AWS.
Synthèse
| Critère | Avantage |
|---|---|
| Latences | Kafka |
| Delivery semantics | Kafka |
| Rétention | Kafka |
| Compaction log | Kafka |
| Taille maximale d'un message | Kafka |
| Tolérance à la panne (acquittement des messages) | Kafka |
| Compression | Kafka |
| Registre de schéma | Kafka |
| Maintenabilité | Kinesis |
| Header de messages | Kafka |
| Monitoring | Kinesis |
| Gestion des exceptions | Kafka |
| Scalabilité (Partitionnement automatique) | Kinesis |
| Atomicité inter-partitions | Kafka |
| Gestion des offset | Kafka |
| Horodatage automatique des messages | Kafka |
| Tests unitaires et d'intégration | Kafka |
| Framework de Streaming | Kafka |
| Langage d'interrogation SQL | Kinesis |
| Configuration des solutions (Simplicité) | Kinesis |
| Sécurité | Kinesis |
| Automatisation du déploiement | Kinesis |
Critères de choix solutions cibles
Il est important de connaître les cas d'usages et les besoins qui vont amener à choisir l'offre Kinesis plutôt que l'offre Kafka managé.
Kinesis
Pour un nouveau projet ou pour une migration on va privilégier Kinesis par rapport à Kafka dans les cas suivants :
- Réduire les coûts de maintenance
- Réduire les coûts d'utilisation (l'avantage dépendra du dimensionnement)
- Améliorer la scalabilité en réduisant les délais de mise à disposition d'un nouveau serveur.
- Charge très variable au cours du temps
Kafka
Pour un nouveau projet ou pour une migration on va privilégier Kafka par rapport à Kinesis dans les cas suivants :
- Utilisation de fonctionnalités non supportée par Kinesis :
- Utilisation des headers,
- Latence et performances très importante,
- Transaction (only once delivery).
- Coût (cluster important) :
- Kinesis n'est pas obligatoirement avantageux (nombre de shards très important)
- Coût (nombre important de clients) :
- Avec Kinesis, le nombre de clients simultanés est limité (lecture et écriture).
- Coût (volumétrie importante) :
- Avec Kinesis, le débit d'écriture est limité par shard.
- Coût (délai de rétention) :
- Au-delà d'un jour de rétention, Kinesis facture des coûts supplémentaires.
| Critère | Solution recommandée |
|---|---|
| Utilisation de fonctionnalités non supportée par Kinesis | Kafka (offre managée) |
| Données sensibles | Kafka (offre managée) |
| Latence | Kafka (offre managée) |
| Grand nombre de clients | Kafka (offre managée) |
| Coûts de maintenance | Kinesis |
| Scalabilité | Kinesis |
| Grande variabilité des sollicitations | Kinesis |
| Plateforme éphémère | Kinesis |
Migration
Migration des données
Il faut tout d'abord décider de la stratégie à adopter :
- Dual Run : Kafka et Kinesis vont être déployés en parallèle, le temps des validations
- Big Bang : Kinesis remplace Kafka à une date prédéfinie
Afin de faciliter la migration des données, il existe un connecteur capable d'exporter les données de Kafka vers Kinesis et développé par AWS : https://github.com/awslabs/kinesis-kafka-connector
C'est un jar à déployer sur la plateforme Kafka source et qui s'appuie sur kafka connect pour la récupération des messages.
Une autre solution consiste à développer du code Spark/Flink spécifique pour l'alimentation de Kinesis. Cette solution permet un meilleur contrôle (transformation des données, performances, ...)
Points d'attention :
- Rétention et donc volumétrie différente entre les deux systèmes,
- L'horodatage des messages est modifié.
Migration du code
Si les principes et la structuration du code sont identiques, la migration exige une réécriture complète du code.
Les clients Kinesis Producer Library (KPL) et Kinesis Consumer Library (KCL) sont écrits en C++ et utilisent des wrappers pour Java.
On peut aussi utiliser le SDK AWS mais qui est vu comme une offre dégradée d'utilisation de l'API Kinesis (pour les langages non encore supportés).
Migration du contrôle d'accès
Il n'y a pas de différence majeure dans les possibilités de sécurisation offertes par les deux plateformes.
La migration du contrôle d'accès sera toutefois une opération longue nécessitant un inventaire de l'existant.
Estimation du coût AWS
Le service Kinesis Data Analytics n'est pas (encore) disponible dans la région Paris, c'est pourquoi nous nous baserons sur la région "Dublin".
Kinesis Data Stream
La facturation de l'offre d'AWS va se faire selon plusieurs axes :
- un coût récurrent
- un coût d'utilisation
Exemple de tarification (Dublin) :
- Coûts fixes : 0,017 USD par heure et par shard
- Coûts d'insertions : 0,0165 USD pour 1 million d'ordres d'insertion (put)
Kinesis Data Firehose
Exemple de tarification (Dublin)
- Coûts d'insertions : 0,031 USD par Go par mois (500 premiers To)
- Conversions de format des données 0,019 USD par Go
Kinesis Data Analytics
Exemple de tarification (Dublin)
- Coûts fixes : 0,120 USD de l'heure (4 Go de mémoire, 1 vCPU)
Conclusion
Dans une architecture, ces deux solutions vont remplir le même rôle mais même si Kinesis est inspiré par Kafka, l'offre d'AWS présente des différences importantes en termes d'implémentation.
Certaines fonctionnalités étant totalement absentes, il convient de bien étudier les cas d'utilisations car Kafka ne pourra pas être remplacé purement et simplement par Kinesis.
Kinesis est toutefois la solution idéale pour harmoniser un SI, favoriser le Time To Market et s'adapter à une sollicitation variable ou en constante augmentation.
Aller plus loin
AWS Kinesis https://aws.amazon.com/fr/kinesis/
Disponibilité des services par régions https://aws.amazon.com/fr/about-aws/global-infrastructure/regional-product-services/
Monitoring Kinesis : https://docs.aws.amazon.com/fr_fr/streams/latest/dev/monitoring.html
Application Migration Strategies: "The 6 R's"
https://aws.amazon.com/fr/blogs/enterprise-strategy/6-strategies-for-migrating-applications-to-the-cloud/
AWS - en Route vers la Production https://blog.ippon.fr/2019/02/07/aws-et-si-on-faisait-de-la-production/
Is Public Cloud Cheaper Than Running Your Own Data Center ?
https://blogs.gartner.com/marco-meinardi/2018/11/30/public-cloud-cheaper-than-running-your-data-center/
