

Introduction
Cet article n'a rien à voir avec les dernières performances chinoises en matière spatiale et ne blessera aucun animal. Il s'agit juste de mettre en avant un concept de développement qui a jailli dans mon esprit il y a quelques mois et qui est la base d'un outil que j'ai depuis commencé à réaliser.
L'idée initiale est plutôt simple. D'un côté, grâce aux fournisseurs de Clouds publics, il est maintenant extrêmement facile d'héberger un site web, de construire des services REST et de tirer parti de services managés de type base de données. De l'autre côté, des frameworks JavaScript comme Angular, React ou Ember

(d'où le cochon d'Inde !) permettent de mettre en place des interactions utilisateurs extrêmement poussées directement au niveau du navigateur et s'appuient sur des services REST pour établir la communication avec le back-end.
En se focalisant sur Ember, son addon intégré Ember Data est capable de gérer totalement un modèle applicatif en incluant ses relations et de se charger des interactions avec le back-end en s'appuyant sur la spécification JSON API. Ce découplage entre un modèle stocké sur le navigateur et celui persisté au sein du back-end est clairement ce qui m'a poussé à utiliser cet (excellent) framework plutôt qu'un de ses concurrents.
Rapide vue d'architecture
En ayant cela dans la tête, mon idée était de construire une sorte de JHipster framework, totalement dédié au Cloud (pour le moment AWS), écrit en JavaScript, tirant parti des possibilités introduites par les architectures Serverless, et surtout facilitant au maximum le travail de développement, de test et de déploiement.
Cette solution s'articule autour de trois modes :
- Le Developer mode qui ne nécessite même pas de connexion Internet et s'apparente à la façon standard de construire une application avec Ember CLI. Cependant, ce mode ajoute une feature clef : la possibilité d'importer un fichier JDL décrivant le modèle métier, en créant immédiatement à la fois les différentes entités applicatives et des mocks intelligents s'appuyant sur l'add-on Ember CLI Mirage et sur la bibliothèque Faker.js. Pour citer la documentation d' Ember CLI Mirage, ce _mode permet au développeur de partager un prototype fonctionnel de son application, fonctionnant intégralement au niveau du client - avant même d'écrire la moindre ligne de son API.
_Le diagramme ci-dessous illustre ce fonctionnement en s'appuyant sur les différents concepts proposés par Ember :
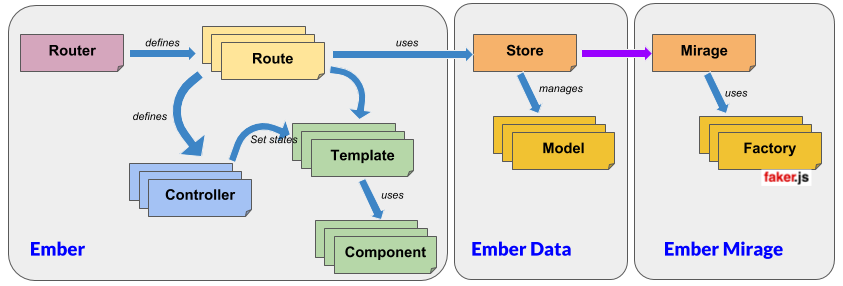
- L'Integration mode utilise la fonctionnalité de proxy d'Ember pour s'appuyer sur un back-end implémenté sur le Cloud au travers d'une API Gateway et persistant les données dans une base DynamoDB. Pour arriver à cela, ce mode tire parti du fait qu'Ember Data s'appuie fortement sur la spécification JSON API. Un des objectifs de la partie Cloud du framework est de mettre en place cette infrastructure, délivrant des services REST avec la sémantique attendue et transférant la 'payload' du message à une fonction Lambda interagissant avec la base DynamoDB. Ce mode de fonctionnement permet de tester localement l'application avec son véritable back-end avant de la déployer totalement sur le Cloud. Le diagramme suivant illustre le fonctionnement global et la substitution opérée entre Mirage et le Back-end Cloud :
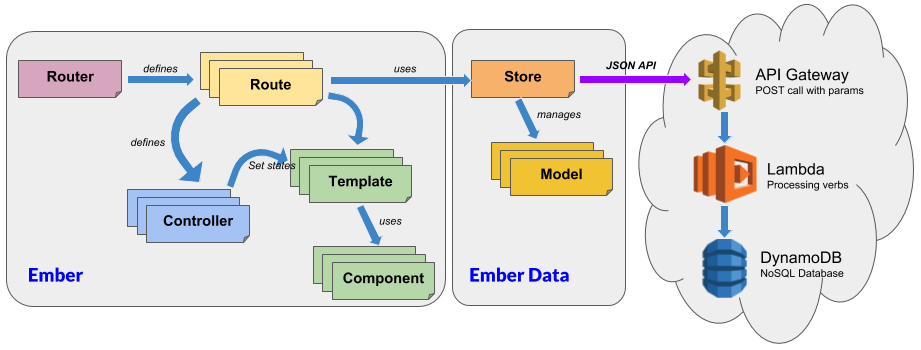
- Le production mode pousse simplement les ressources web vers un bucket S3 exposé via Cloudfront. L'application est ainsi mise à disposition de tout internaute !
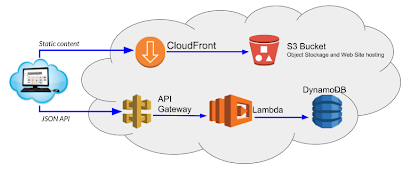
Dans un article ultérieur, nous brancherons également Cognito pour mettre en place des principes d'authentification et d'autorisation.
En route vers une démonstration !
Nous allons maintenant mettre en place un exemple complet ainsi que démontrer l'ensemble du processus pouvant conduire du développement à la 'production'. Le terme 'production' est sciemment mis entre guillemets car l'implémentation actuellement proposée reste du niveau d'un Proof Of Concept. Une implémentation capable d'affronter la production mériterait largement plus de réflexion et de travail...
Mise en place de l'environnement de développement
Le travail initial n'est pas différent de celui qu'on ferait pour une application Ember.js standard. Bien entendu, en préalable à toute autre opération, vous devez avoir Node.js et Ember CLI déjà installés sur votre ordinateur. Puis, vous tapez dans un Shell la commande habituelle :
ember new guineapig_inthecloud --no-welcome
L'option no_welcome permet de se débarrasser de l'addon Welcome et de l'écran par défaut proposé pour une application Ember.
Pour compléter cette installation et se rapprocher de notre environnement cible, vous devez installer mon add-on ember-aws-ehipster en tapant :
cd guineapig_inthecloud
ember install ember-aws-ehipster
Cet add-on va installer un certain nombre d'autres add-on bien précieux pour faire du développement sous ce framework (ils sont listés dans la page https://gitlab.ippon.fr/bpinel/ember-aws-ehipster/wikis/ember-included-add-ons) et surtout un nouveau blueprint pour générer automatiquement les objects du modèle, des données de tests correspondantes et des pages d'administration. Le fichier initial est tout simplement celui que vous pouvez construire à l'aide du JDL-Studio de JHipster. Voici celui que nous allons utiliser au cours de cet exemple :
entity User {
login String required minlength(4),
passwordHash String required minlength(8),
firstName String required minlength(3) maxlength(50),
lastName String,
email String,
imageUrl String,
activated Boolean,
createdBy String,
createdDate LocalDate,
lastModifiedBy String,
lastModifiedDate Instant
}
entity Authority {
name String required maxlength(30)
}
entity Todo {
title String required,
completed Boolean
}
relationship ManyToMany {
User{user(login)} to Authority{authority(name)}
}
relationship OneToMany {
User{user(login)} to Todo{todo}
}
Il faut remarquer que les deux objets Authority et User sont directement inspirés du modèle de base de JHipster et le modèle global se représente sous la forme :
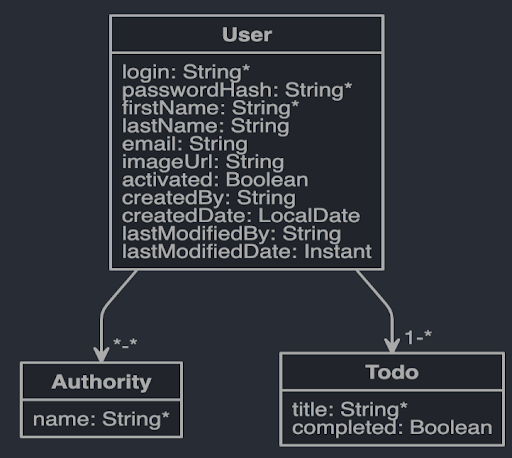
Le contenu mentionné précédemment doit être sauvegardé dans un fichier **todo.jh que l'on stockera directement dans le répertoire guineapig_inthecloud. Il suffit alors d'invoquer le blueprint jdl-importer en lançant la commande suivante :
ember g jdl-importer todo.jh
Ce blueprint va automatiquement créer l'ensemble du modèle présenté dans le fichier JDL, les factories permettant la génération de données de test et les pages d'administration correspondantes. On peut alors directement démarrer le serveur Node via :
ember s
Et constater en se rendant sur http://localhost:4200/entity-factory/todo qu'une page d'administration dédiée à l'objet todo est disponible :
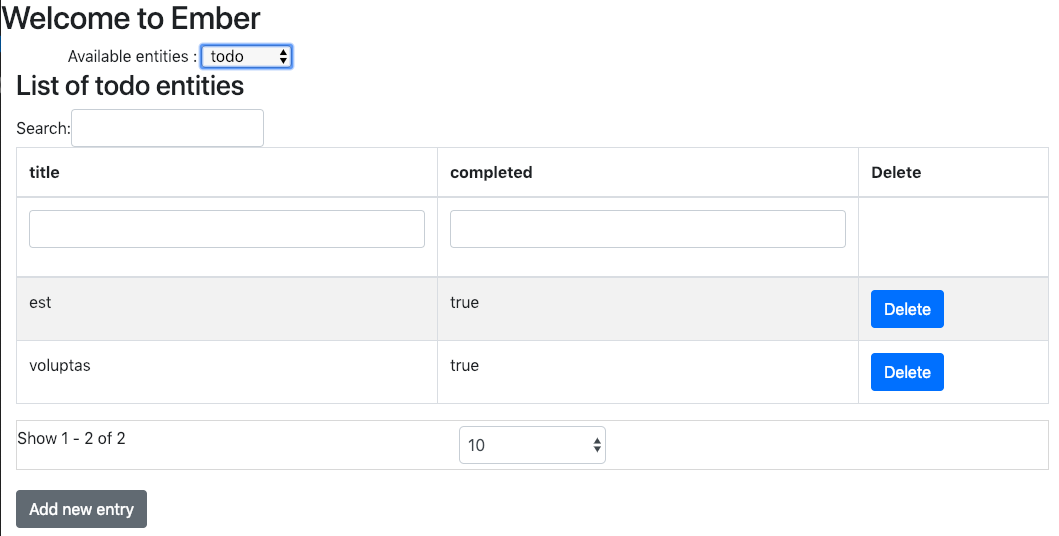
Bien entendu, ces pages d'administration restent très minimalistes, mais libre à vous de construire des interactions beaucoup plus abouties fonctionnellement et graphiquement avec les entités maintenant disponibles ! Si vous souhaitez voir un exemple d'une telle application, vous pouvez aller voir l'application Todo fournie dans le répertoire tests/dummy de l'addon (disponible sur https://gitlab.ippon.fr/bpinel/ember-aws-ehipster/tree/master/tests/dummy).
Tout cela est bien beau, mais pour le moment, on est loin de tout aspect Cloud ou Serverless !
Soyez un peu patient et poursuivez votre lecture pour voir que tout est déjà presque présent pour aller vers ce dispositif.
En route vers un back-end Serverless !
Quelques informations sur l'infrastructure du back-end
Comme déjà mentionné précédemment, Ember Data encapsule la communication avec le Back-end en fournissant une API de services. Voici un extrait de cette API et de sa traduction en vocabulaire REST :
| Method | HTTP Verb | Request example \ (for object Blog and id 123) |
| findRecord | GET | /blogs/123 |
| findRecord | GET | /blogs |
| createRecord | POST | /blogs |
| push | PUT | /blogs/123 |
| deleteRecord | DELETE | /blogs/123 |
Pour être un peu plus précis, l'implémentation par défaut d'Ember Data s'appuie sur la JSON API Specification. Cette spécification détaille finement à la fois les différents endpoints attendus et le contenu des messages transportés, notamment au niveau des relations entre les objets.
Un back-end qui se veut conforme à la spécification JSON API doit implémenter le vocabulaire HTTP comme illustré dans le diagramme suivant :
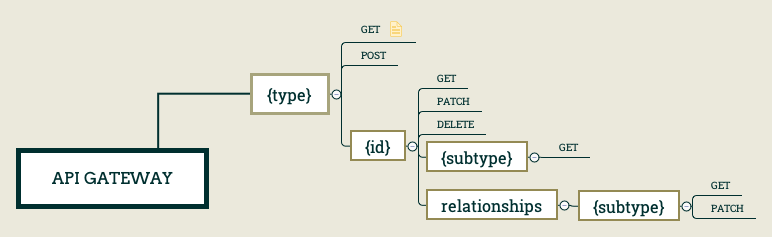
Pour mettre en place l'infrastructure complète de ce back end, je me suis principalement appuyé sur 3 services AWS :
- Une nouvelle API déclarée au sein de l'API Gateway pour supporter la sémantique REST attendue,
- Une fonction Lambda écrite en JavaScript et tournant sur Node.js 8.1 appelée par l'API Gateway et chargée de la logique de traitement des paramètres fournis, mais aussi de la gestion des relations,
- Une table DynamoDB chargée de persister l'ensemble des objets manipulés, indépendamment de leur contenu.
Cette infrastructure principale de backend est complétée par les éléments suivants :
- Trois buckets S3
- Le premier (lambda-jsonapi-code-bucket) est utilisé pour provisionner le code de la fonction Lambda lors de sa création,
- Les deux autres (ember-aws-ehipster-staging et ember-aws-ehipster-production) serviront ultérieurement pour stocker les versions 'staging' et 'production' de l'application.
- Un rôle IAM (lambda_jsonapi) permettant à la fonction Lambda d'accéder notamment à la base DynamoDB
- Deux entrées dans CloudFront correspondant respectivement aux deux buckets de 'staging' et de 'production'
Construction de l'infrastructure sur AWS
Plutôt que de passer par une construction 'à la mano' au travers des interfaces graphiques d'AWS, j'ai préféré passer par une approche automatisée à l'aide de scripts terraform, largement plus lisibles que les CloudFormation propre à AWS... Tous les fichiers nécessaires sont disponibles dans le répertoire 'cloud' du projet GitLab : https://gitlab.ippon.fr/bpinel/ember-aws-ehipster/tree/master/cloud.
Une fois ce répertoire récupéré et terraform installé, il suffit de lancer le provisionning de la plateforme par les commandes :
terraform init
terraform apply
Comme dit précédemment, les scripts Terraform vont aboutir à la création des ressources suivantes :
- 3 buckets S3 : lambda-jsonapi-code-bucket (pour le code du lambda), ember-aws-ehipster-staging and ember-aws-ehipster-production pour le stockage ultérieur des 2 versions du site statique,
- 1 rôle IAM lambda_jsonapi,
- 1 API gateway JsonApiRestGateway,
- 1 fonction lambda lambda-jsonapi,
- 1 table DynamoDB JsonApiTable.
En vous rendant sur votre console Amazon et sur l'API Gateway, vous devriez donc trouver une nouvelle entrée JsonApiRestGatewayAPI :
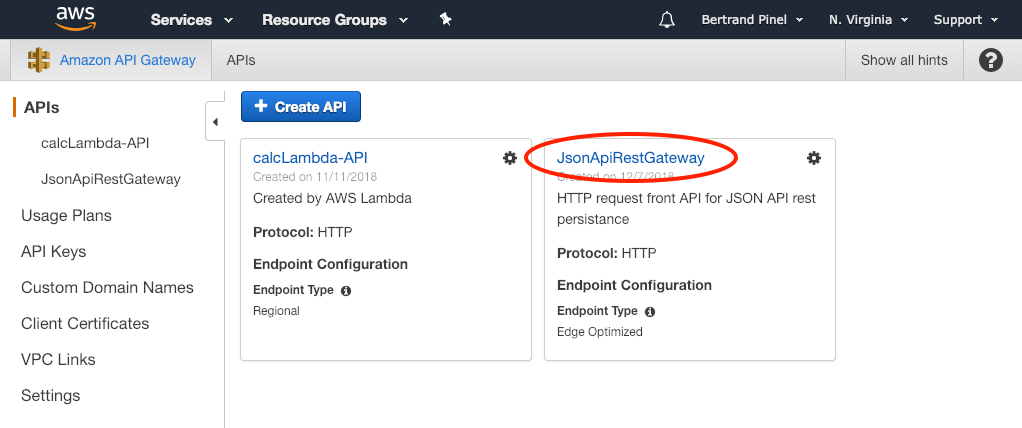
Dans cet écran, pour la suite des opérations, vous allez devoir aller récupérer l'URL d'invocation de l'API en vous rendant sur la page adéquate :
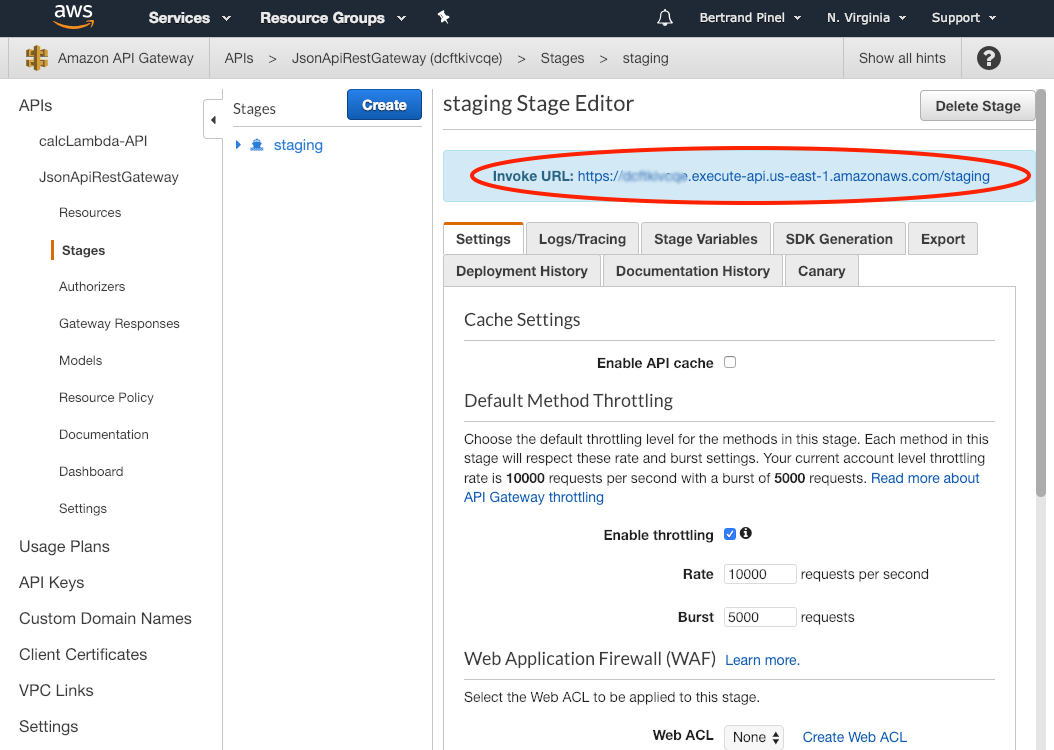
En effet, il va falloir indiquer à votre application Ember d'utiliser cette URL comme Gateway pour les appels d'Ember Data. Tout se passe dans le fichier_ config/environment.js_ au niveau des lignes suivantes :
if (environment === 'production') {
// here you can enable a production-specific feature
ENV.gatewayURL = 'https://xxxxxxxxxxx.execute-api.us-east-1.amazonaws.com/staging';
//ENV.gatewayURL = process.env.STAGING_GATEWAY_URL;
console.log("Setting staging gatewayURL to "+ENV.gatewayURL);
}
if (environment === 'staging') {
// here you can enable a staging-specific feature
ENV.gatewayURL = 'https://xxxxxxxxxxx.execute-api.us-east-1.amazonaws.com/staging';
//ENV.gatewayURL = process.env.PRODUCTION_GATEWAY_URL;
console.log("Setting production gatewayURL to "+ENV.gatewayURL);
}
Un petit test avant d'aller plus loin
Afin de vérifier le bon fonctionnement de notre infrastructure, on peut facilement lancer un test rapide. Pour cela, on se rend sur la console de l'API Gateway concernant la nouvelle API et plus particulièrement sur la méthode /{type} en GET pour déclencher un 'test' :
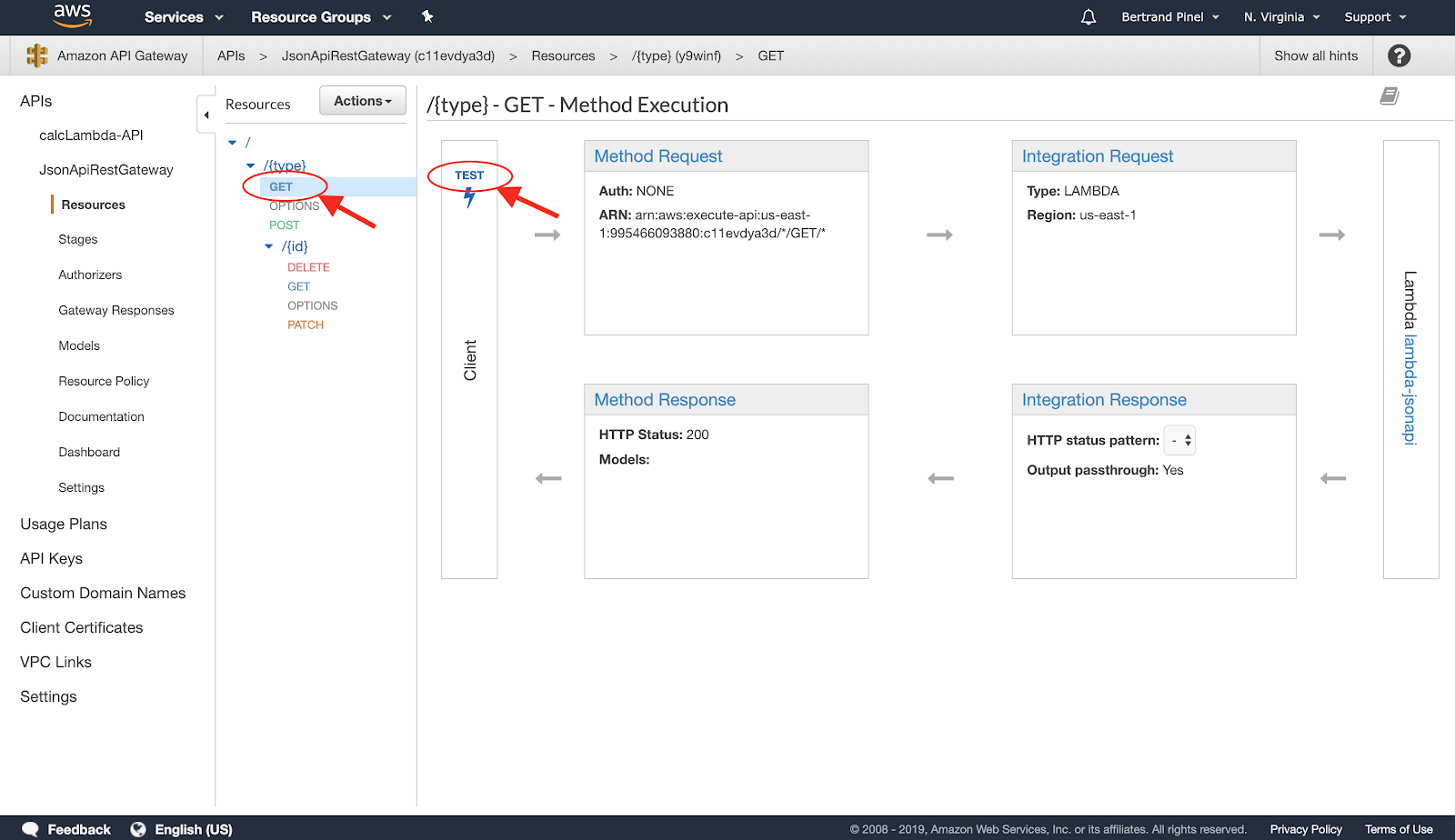
Sur l'écran qui s'affiche alors, il suffit de remplir le champ {type} (n'importe quelle valeur peut convenir) et de lancer le 'Test' comme montré dans la capture d'écran suivante :
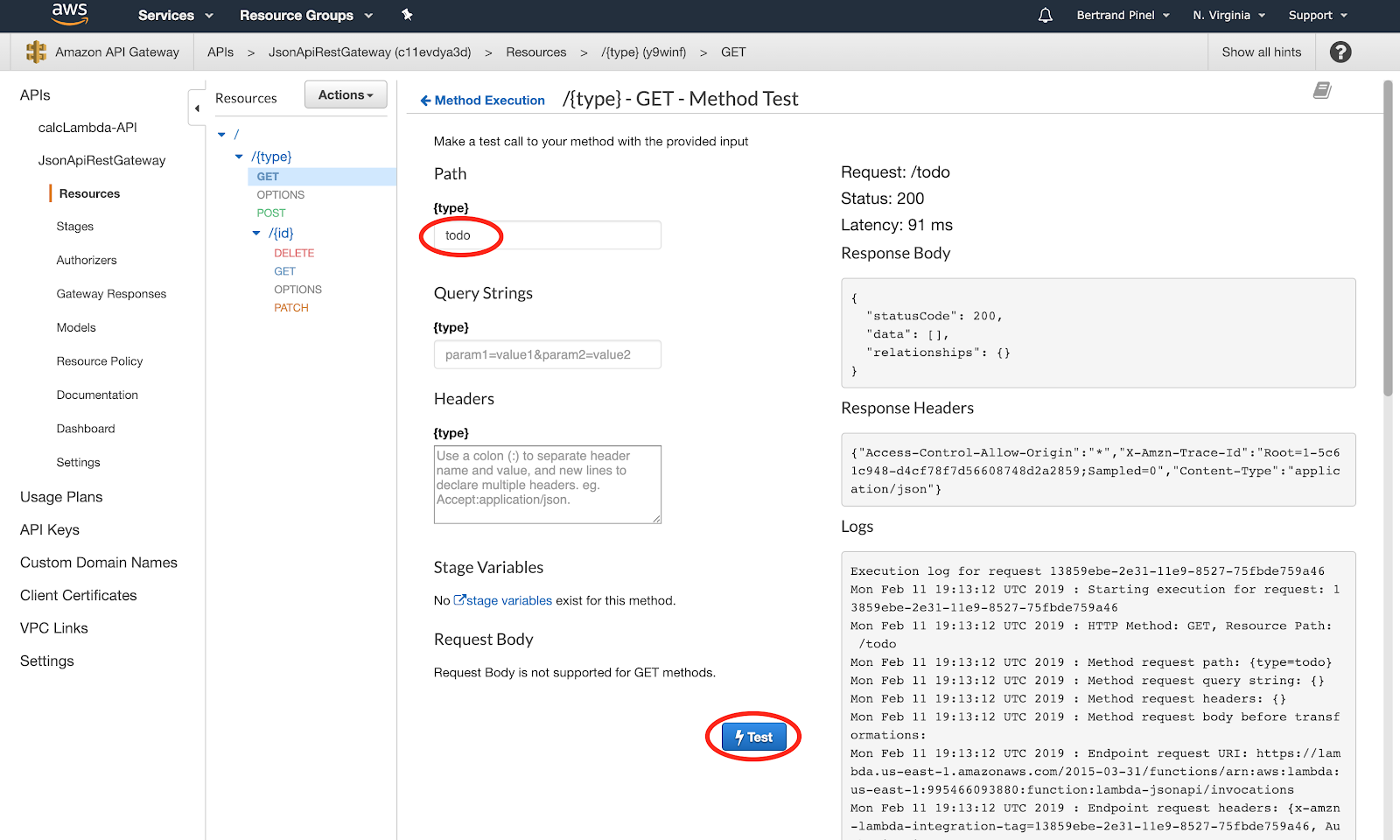
On doit recevoir un status code à 200 et une réponse du type :
{
"statusCode": 200,
"data": [],
"relationships": {}
}
Cette réponse signifie simplement qu'aucun objet du type demandé n'a été trouvé en base de données.
Revenons à notre application Ember
À partir de maintenant, tout est en place pour le tour de magie ! Pour cela, il suffit de redémarrer le serveur Ember, cette fois-ci en spécifiant comme proxy l'API Gateway créée précédemment :
ember s --proxy <API Gateway Invoke URL>
En retournant sur une des pages d'administration de l'application, par exemple via l'URL http://localhost:4200/entity-factory/authority, on obtient une page avec une table vide. Ce qui est bien logique vu l'absence de données au sein de notre nouvelle infrastructure :
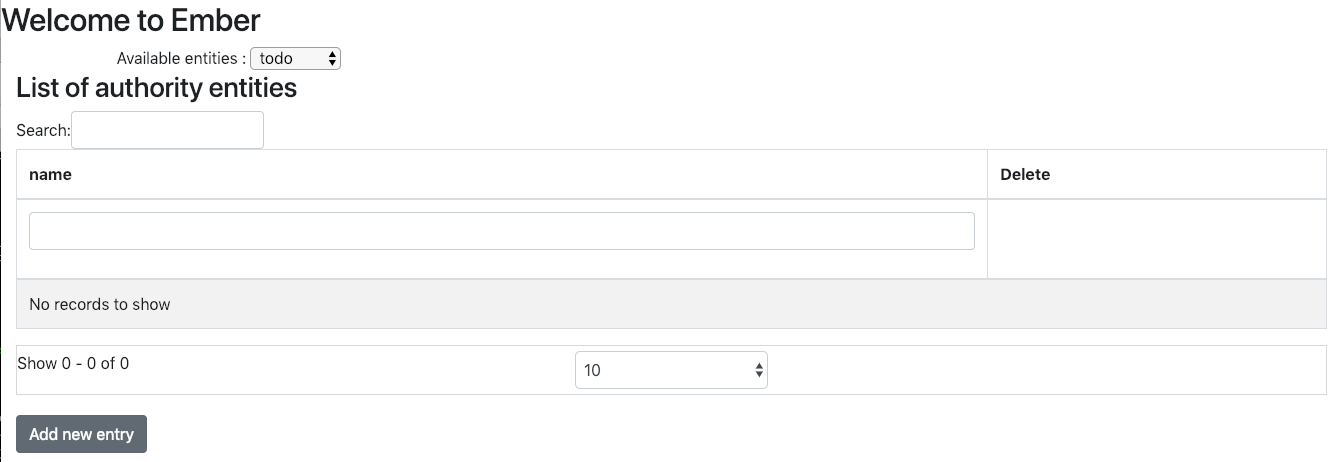
En cliquant sur le bouton "Add new entry", on va pouvoir renseigner une nouvelle 'Authority' :
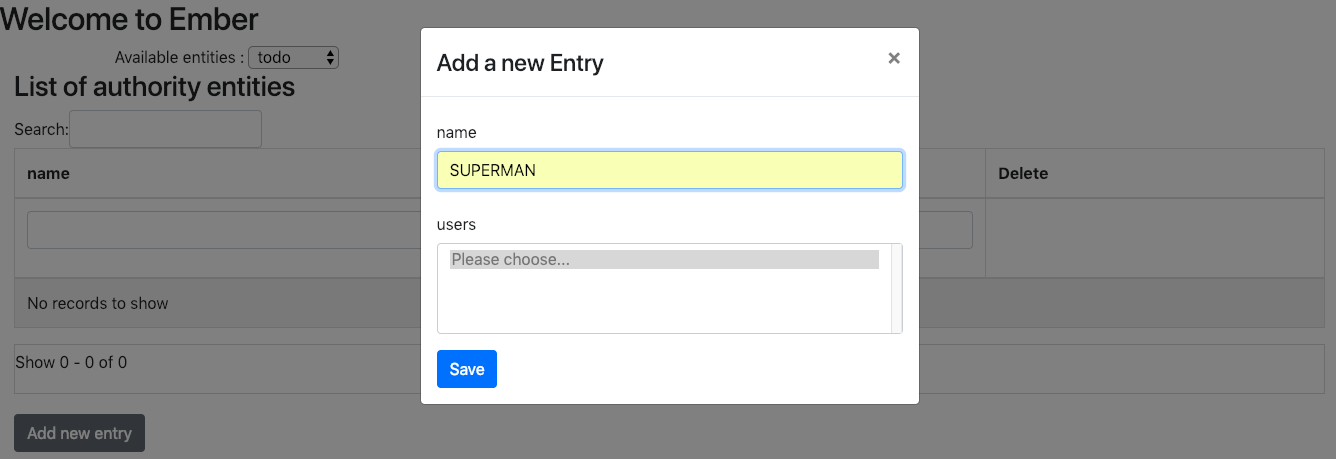
En retournant sur l'interface web de DynamoDB et en affichant le contenu de la table JsonApiTable, on retrouve bien notre nouvel objet créé :
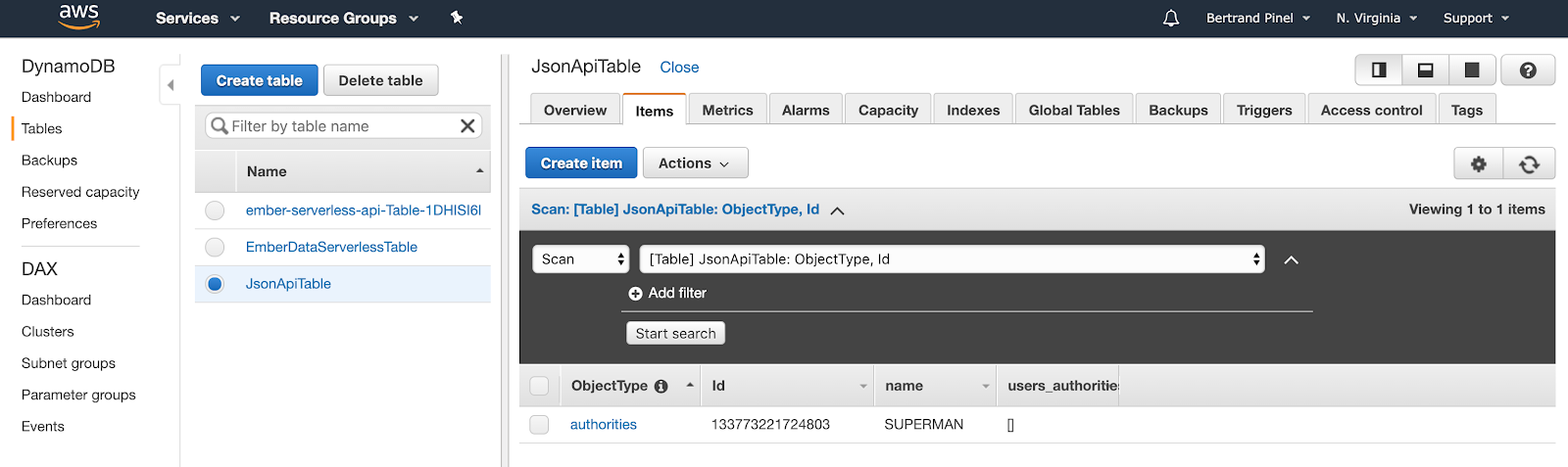
Vous pouvez également faire le chemin dans l'autre sens en créant la donnée via l'interface Web d'AWS pour la retrouver dans votre application Web !
Reste à héberger le tout dans le Cloud
Pour simplifier le processus de développement, nous allons à nouveau nous appuyer sur des addons Ember.
Le premier d'entre eux est en quelque sorte la colonne vertébrale d'implémentation de tout pipeline de déploiement. Il s'installe via la commande :
ember install ember-cli-deploy
Comme le montre le résultat de la commande, cet addon ne fait rien en lui-même mais attend qu'on lui fournisse des addons complémentaires :
ember-cli-deploy needs plugins to actually do the deployment work.
See http://ember-cli.github.io/ember-cli-deploy/docs/v0.1.0-beta/quick-start/
to learn how to install plugins and see what plugins are available.
Installed addon package.
Celui que nous allons installer est bien sûr celui concernant AWS:
ember install ember-cli-deploy-aws-pack
En fait, cet addon est un plugin pack, c'est-à-dire qu'il regroupe un ensemble d'addons dont voici la liste :
- Ember-cli-deploy-build : Permet le lancement de la construction de l'application web (à la façon d'un ember build) qui va se faire dans le répertoire tmp/deploy-dist,
- ember-cli-deploy-s3 : Addon central pour le déploiement de l'application dans un bucket S3, il s'appuie sur la configuration présente dans le fichier
config/deploy.js(voir un peu plus loin) pour assurer la synchronisation des fichiers, - ember-cli-deploy-revision-data : Assure la génération d'un identifiant pour chacune des versions de l'application. On verra plus tard comment cela nous permet de revenir sur des versions précédentes au niveau du déploiement dans S3,
- ember-cli-deploy-display-revisions : Permet l'affichage des identifiants de révision,
- ember-cli-deploy-manifest : En s'appuyant sur un fichier
manifest.txtcontenant la liste des fichiers composant l'application compilée, cet addon va permettre des déploiements partiels, - ember-cli-deploy-gzip : Assure la compression des fichiers résultant du build,
- ember-cli-deploy-cloudfront : Permet d'invalider un fichier (en particulier 'index.html') au niveau de la distribution CloudFront lors des re-déploiements.
La configuration des buckets S3 passe par le fichier config/deploy.js.
Ce fichier s'appuie fortement sur des variables d'environnement lues au travers des propriétés 'process.env.'. Pour plus de commodité, je vous conseille d'utiliser les capacités de l'addon ember-cli-deploy au travers de fichiers .env. créés dans le répertoire racine du projet (http://ember-cli-deploy.com/docs/v1.0.x/using-env-for-secrets/). On a ainsi trois fichiers .env, .env.staging et .env.production du type :
# .env
AWS_KEY='XXXXXXXXXXXXXXXXXXXX'
AWS_SECRET='XxXxxxxXXXXXX/XxxxXXXxx/xxxXXX'
AWS_REGION='us-east-1'
Pour les deux fichiers suivants, vous devez aller chercher dans la console AWS de CloudFront les identifiants des distributions que vous reporterez dans les fichiers adéquats :
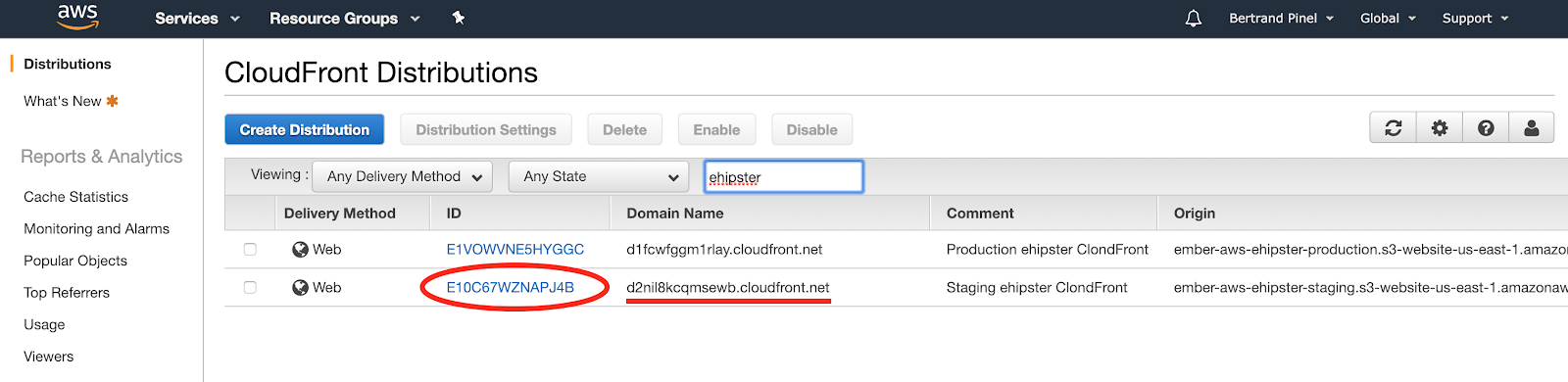
(A noter que cette console vous donne également l'URL exposé au niveau de CloudFront)
# .env.staging
STAGING_REGION='us-east-1'
STAGING_BUCKET='ember-aws-ehipster-staging'
STAGING_DISTRIBUTION='E10C67WZNAPJ4B'
# .env.production
PRODUCTION_REGION='us-east-1'
PRODUCTION_BUCKET='ember-aws-ehipster-production'
PRODUCTION_DISTRIBUTION='E1VOWVNE5HYGGC'
Le déploiement sur le cloud AWS (bucket S3 et distribution CloudFront) se fait alors à l'aide de la commande (pour l'environnement de staging) :
ember deploy staging --verbose
L'option --verbose permet d'illustrer les manipulations sur les empreintes de fichiers et sur le mécanisme de recopie des ressources sur le bucket S3.
On peut alors utiliser notre application directement sur le Cloud en utilisant l'URL exposée par CloudFront :
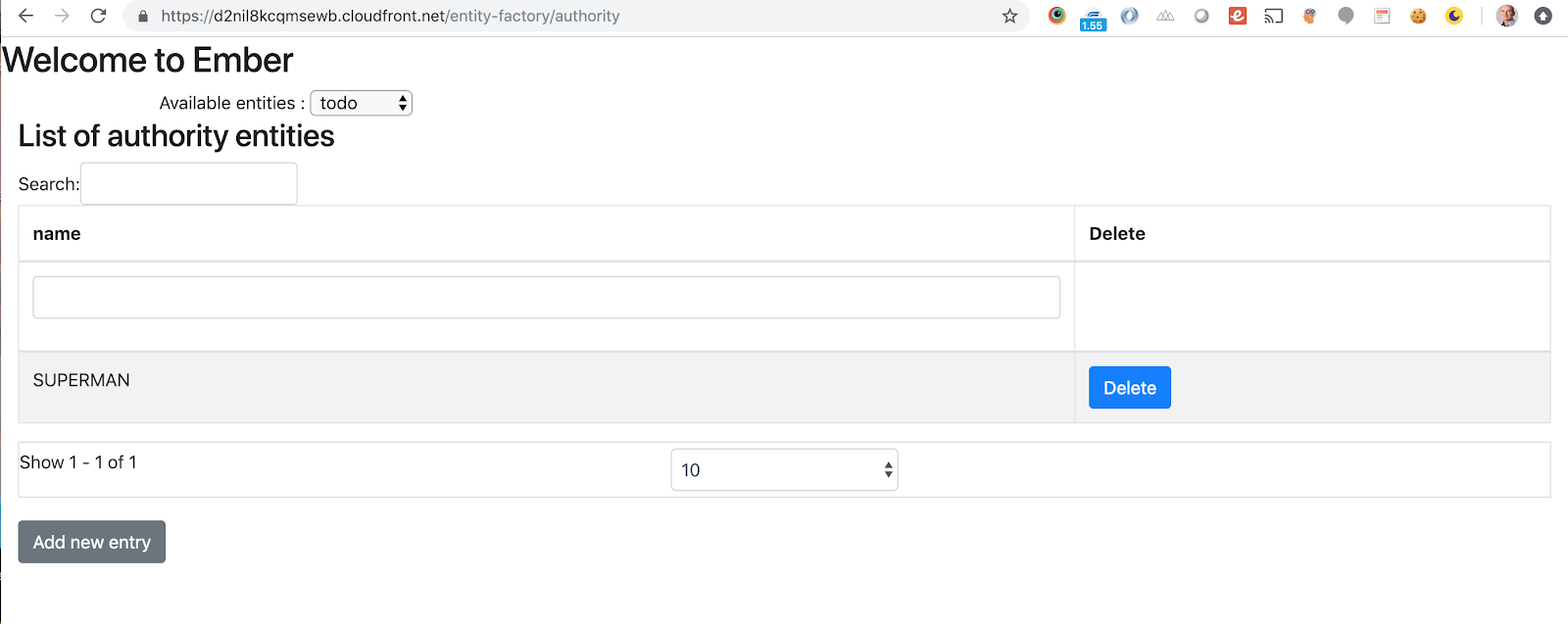
En matière de conclusion provisoire...
Certes, le framework mis en place ici est encore expérimental et incomplet. Il permet néanmoins en quelques commandes simples à la fois d'offrir un environnement de développement efficace, permettant des démonstrations rapides à l'aide de données de tests, mais également de pousser l'application sur le Cloud AWS en mode Serverless pour un déploiement 'Live'.
Le Web Serverless n'aura jamais été aussi simple !
