

1. Introduction
Les réticences de certains DSI à utiliser les fonctionnalités des clouds publics disparaissent. Les équipes IT sont donc de plus en plus amenées à utiliser les services managés d'un cloud public : rapidité de mise œuvre, paiement à l'usage, pas besoin de s'occuper de l'infrastructure "sous-jacente", réelles opportunités de rénover son infrastructure legacy. On teste, des POCs ou des MVP sont montés, et parfois ça tombe en marche !!
De plus en plus de projets sont lancés sur le cloud AWS. C'est une phase parfois un peu difficile à appréhender où les frontières entre les devs et les ops s’atténuent.
Si vous vous posez des questions du style, "on va avoir une prod qui tourne mais comment on va faire ?", "On y va ?" ce billet devrait vous intéresser.
Dans la suite de cet article, on part du principe que l'applicatif est développé par une équipe "tiers" et que l'architecture de production a été construite en connaissance de cause.
Comment assurer le "run de cet applicatif en prod sur AWS" ? Voici plusieurs points qui me semblaient intéressants de détailler dans ce billet. AWS fournit un panel d’outils très intéressants pour mettre en œuvre une gestion de production. Ces outils sont très facilement accessibles pour une équipe IT qui commence sa mutation vers le cloud.
-
le monitoring, et les dashboards de supervision : on va bien évidemment parler de CloudWatch.
-
l'alerting : avoir des métriques c'est bien, mais le mieux c'est de pouvoir anticiper les incidents. Pour cela, une surveillance de ces métriques est nécessaire. Nous verrons comment CloudWatch nous permet de faire cela. Et pendant qu'on y est, on verra également comment s'interfacer avec nos outils existants via des fonctions lambda.
-
Les logs : toujours dans CloudWatch, on terminera par mettre en place des log groups et voir comment les manipuler pour en extraire des informations. On parlera également d'une stack très répandue dans les équipes de prod : ELK pour ElasticSearch, LogStash, Kibana. AWS fournit "clé en main" ces 3 composants.
-
Les sauvegardes : "sauvegarder sur AWS ? Mais je croyais que ca ne plantait jamais !!". On abordera dans ce chapitre quelques techniques de sauvegarde.
-
La maintenance globale : Je vous propose de vous présenter “AWS System Manager” et vous montrer comment l'utiliser.
2. Monitoring : CloudWatch est notre ami
Depuis plusieurs années que je côtoie les infrastructures AWS, force est de constater que CloudWatch n'a pas forcément bonne réputation. C'est assez injuste je trouve. En y réfléchissant,
- les prods nécessitent de conserver les métriques dans une base "timeseries" : c'est la première fonctionnalité de CloudWatch. On peut cependant lui reprocher que, par défaut, CloudWatch ne conservera que 14 jours de données avec une granularité maximale de 5 minutes... 5 minutes c'est long à l'échelle d'un incident !! Pour de la production, il faudra penser à activer le mode "advanced" (activer le mode “avdanced” induit un coût, comptez 350 $ pour 45 000 métriques sur 1 mois) pour bénéficier d'une granularité à la seconde et de 2 ans de rétention. CloudWatch s’occupe de scaler la volumétrie de la base timeseries.
- Les dashboards de supervision : là aussi, CloudWatch permet de construire des dashboards de supervision et on peut même les créer via des scripts. Par contre, effectivement, les fonctions d'affichage sont moins riches que d'autres produits (la notion de dérivée par exemple). Mais c'est un faux problème. Il existe de nombreux plugins "CloudWatch" pour les produits du marché. (Par exemple Grafana). Si vous ne souhaitez pas utiliser les dashboards CloudWatch, vous pouvez les reconstruire dans Grafana par exemple. Je vous invite à jeter un œil à ce lien :
https://github.com/monitoringartist/grafana-aws-cloudwatch-dashboards
Cela vous donnera des dashboards déjà prêts à l'emploi. Il suffira simplement de créer un “user” avec uniquement un “programmatic access” et limiter les permissions de cet utilisateur à la lecture des métriques CloudWatch comme détaillé dans l’exemple ci-dessous.
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"autoscaling:Describe*",
"cloudwatch:Describe*",
"cloudwatch:Get*",
"cloudwatch:List*",
"logs:Get*",
"logs:Describe*",
"sns:Get*",
"sns:List*"
],
"Effect": "Allow",
"Resource": "*"
}
]
}
2.1. Prérequis
Pour que les métriques puissent remonter correctement dans CloudWatch, il est nécessaire d'autoriser vos machines EC2 à envoyer les valeurs de ces métriques vers le service AWS. En toute logique, vos machines EC2 sont associées à un profil déterminant le rôle qu'elle assume lorsqu'elle sont "UP". Il sera nécessaire que ce rôle contienne l'une des policies suivantes :
- CloudWatchAgentServerPolicy
- CloudWatchAgentAdminPolicy : le même que précédemment + les permissions de pousser des fichiers sur le parameterStore de SSM. J'y reviendrai mais c'est la Policy CloudWatchAgentAdminPolicy que nous utiliserons.
2.2. Utilisation des métriques & "custom métriques"
Par défaut, AWS fournit un ensemble de métriques, chacune rangée dans un "namespace" :
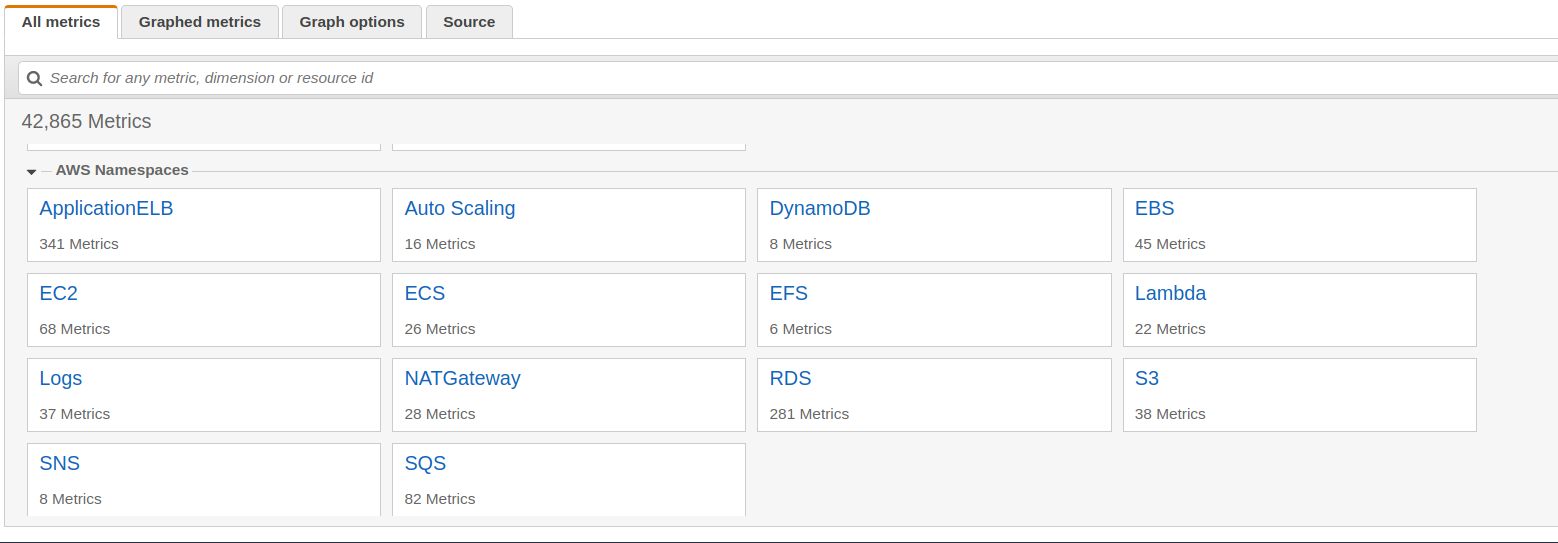
L'ensemble de ces métriques est donc prêt à l'emploi et peut déjà vous aider à mettre en place de l'alerting (cf § 3).
Evidemment, certaines métriques spécifiques à votre application ou les métriques correspondant à la consommation mémoire ne sont pas disponibles. Si on fouille un peu les docs Amazon, on tombe sur ceci :
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/mon-scripts.html
Les scripts fournis par AWS permettent de récupérer entre autre :
- Memory Utilization – Memory allocated by applications and the operating system, exclusive of caches and buffers, in percentages.
- Memory Used – Memory allocated by applications and the operating system, exclusive of caches and buffers, in megabytes.
- Memory Available – System memory available for applications and the operating system, in megabytes.
- Disk Space Utilization – Disk space usage as percentages.
- Disk Space Used – Disk space usage in gigabytes.
- Disk Space Available – Available disk space in gigabytes.
- Swap Space Utilization – Swap space usage as a percentage.
- Swap Space Used – Swap space usage in megabytes.
L'idée est simple : sur chaque machine EC2 de votre infrastructure, il faut mettre en place une entrée dans votre crontab qui, toutes les minutes, appelle un script perl qui vient récupérer les métriques et les "push" dans un namespace de CloudWatch "linux System".
Voici un script "tout en un" :
#!/bin/bash
yum update -y
sudo yum install -y perl-Switch perl-DateTime perl-Sys-Syslog perl-LWP-Protocol-https perl-Digest-SHA.x86_64 unzip
cd /home/ec2-user/
curl https://aws-cloudwatch.s3.amazonaws.com/downloads/CloudWatchMonitoringScripts-1.2.2.zip -O
unzip CloudWatchMonitoringScripts-1.2.2.zip
rm -rf CloudWatchMonitoringScripts-1.2.2.zip
echo "*/1 * * * * root /home/ec2-user/aws-scripts-mon/mon-put-instance-data.pl --mem-util --mem-used --mem-avail --disk-space-util --disk-path=/ --from-cron" >> /etc/crontab
Evidemment, si vous avez plusieurs machines EC2 à déployer sur votre infrastructure, on aura créé une "AMI" afin de ne pas avoir à faire cela manuellement, ou utiliser une librairie comme “Cloud Init”.
Il ne vous aura peut-être pas échappé que ce mécanisme limite la récupération des métriques à la minute (c'est la plus petite unité que l'on peut utiliser dans la crontab). Pour du monitoring plus précis, nous devrons utiliser l'agent CloudWatch. Je vous le présente dans le paragraphe suivant.
2.3. Installation de l'agent CloudWatch
Dans ce paragraphe, je vous présente une installation manuelle de l'agent CloudWatch. Bien évidemment, rien ne vous empêche de le scripter sous forme d'un playbook Ansible, une recette Chef, une classe Puppet ou de l'inclure directement dans votre image "AMI" qui servira à la création de vos machines EC2. Je rappelle que la machine doit avoir un profile contenant la policy qui lui permet d'envoyer ses métriques à CloudWatch.
L'agent CloudWatch est installable facilement via un package dépendant de votre OS. Voici le lien :
https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/install-CloudWatch-Agent-on-first-instance.html
Cherchez le tableau Download the CloudWatch Agent Package on an Amazon EC2 Instance Using an S3 Download Link
Sur la machine, finalement, on passe une commande du style :
sudo yum install -y https://s3.amazonaws.com/amazoncloudwatch-agent/amazon_linux/amd64/latest/amazon-cloudwatch-agent.rpm
# Interactions avec l'agent
# sudo status amazon-cloudwatch-agent
# sudo start amazon-cloudwatch-agent
# sudo stop amazon-cloudwatch-agent
L'agent est installé mais il n'est pas configuré. Pour cela, on va générer un fichier de configuration et enregistrer ce fichier dans le "ParameterStore". Ceci fonctionnera uniquement si vous avez mis la policy CloudWatchAgentAdminPolicy.
# passer root
[ec2-user@ip-AA-BB-CC-DD bin]# sudo -i
[root@ip-AA-BB-CC-DD bin]# cd /opt/aws/amazon-cloudwatch-agent/bin
[root@ip-AA-BB-CC-DD bin]# ls -rlt
total 62744
-rwxr-xr-x 1 root root 791 14 nov. 06:23 start-amazon-cloudwatch-agent
-rw-r--r-- 1 root root 11 14 nov. 06:23 CWAGENT_VERSION
-rwxr-xr-x 1 root root 15626387 14 nov. 06:23 config-translator
-rwxr-xr-x 1 root root 9824313 14 nov. 06:23 config-downloader
-rwxr-xr-x 1 root root 6585 14 nov. 06:23 amazon-cloudwatch-agent-ctl
-rwxr-xr-x 1 root root 12205069 14 nov. 06:23 amazon-cloudwatch-agent-config-wizard
-rwxr-xr-x 1 root root 26564471 14 nov. 06:23 amazon-cloudwatch-agent
# lancer le wizard
[root@ip-AA-BB-CC-DD bin]# ./amazon-cloudwatch-agent-config-wizard
Le script va vous poser des questions auxquelles il faudra répondre.
A noter qu'à la question : Which default metrics config do you want?
Cela correspond aux métriques suivantes :
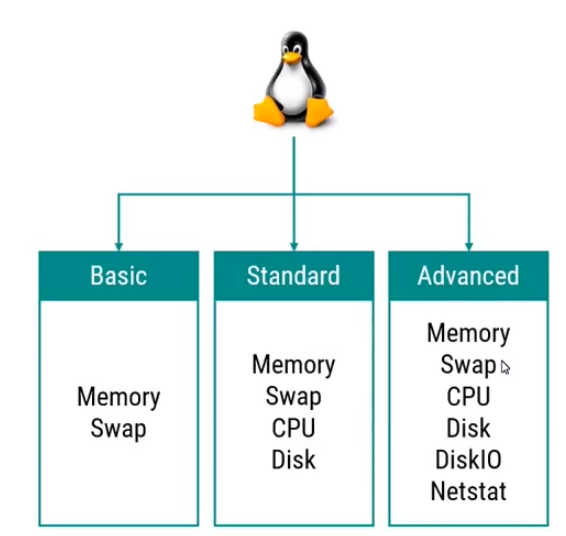
A la question Do you want to store the config in the SSM parameter store?
Répondre “Yes”. Cela va enregistrer la configuration que vous avez déterminée en fonction de vos réponses et permettre de la ré-utiliser pour plus tard.
ATTENTION : Il faut que le nom du fichier enregistré dans le "Parameter Store" commence par AmazonCloudWatch.
Noter également que le fichier config.json est généré dans le répertoire "bin" et est modifiable.
Enfin, pour démarrer l'agent CloudWatch avec une configuration définie :
# démarrer avec un fichier de configuration stocké dans le ParameterStore de SSM
sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl
-a fetch-config -m ec2 -c ssm:AmazonCloudWatch-agent-config -s
# démarrer avec un fichier de configuration local à la machine
sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -a fetch-config -m ec2 -c file:configuration-file-path -s
Si vous avez un fichier de configuration déjà prêt à l’emploi, vous pouvez également l’uploader directement dans le parameterStore avec terraform :
##Ajout de la conf pour les agents Cloudwatch
resource "aws_ssm_parameter" "cw-agent-config" {
name = "AmazonCloudWatch-cw-agent-config"
type = "String"
value = "${file("ssm.json")}"
}
L'agent va s'occuper de récupérer les métriques à des fréquences < à la minute (selon ce qui est indiqué dans le fichier de configuration), les envoyer sur CloudWatch dans un namespace "CW-Agent".
Voici ce que cela donne :
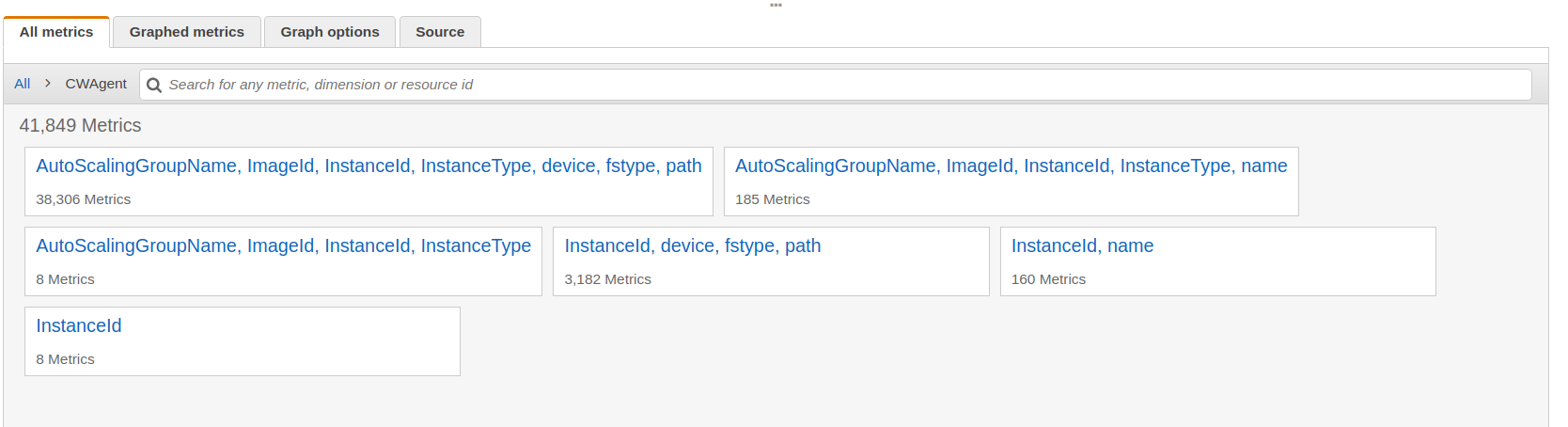
Je profite de la capture d'écran pour introduire la notion de "Dimension" (que l'on retrouvera un peu plus tard). Ici, on voit que les métriques sont rangées en 6 “tas”. Chacun de ces tas est constitué d'au moins une dimension. Si on clique sur "AutoScalingGroupName, ImageId, InstanceId, InstanceType, device, fstype, path", on trouve des métriques. Par exemple, la métrique disk_used_percent est associée aux dimensions suivantes :
- Instance Name
- AutoScalingGroupName
- ImageId
- InstanceId
- InstanceType
- device
- fstype
- path
2.4 Les dashboards CloudWatch
CloudWatch permet de créer des dashboards de supervision. Je ne vais pas détailler ici comment construire vos dashboards depuis la console : c’est suffisamment intuitif.
Je voulais simplement attirer votre attention sur le fait qu’il est possible, depuis terraform, de créer vos propres dashboards. Voici un exemple :
resource "aws_cloudwatch_dashboard" "filesystem-dashboard" {
dashboard_name = "filesystem-dashboard-TF"
dashboard_body = <<EOF
{
"widgets": [
{
"type": "metric",
"x": 0,
"y": 0,
"width": 12,
"height": 9,
"properties": {
"metrics": [
[ "CWAgent", "disk_used_percent", "path", "/", "InstanceId", "i-0aaaaa", "AutoScalingGroupName", "AutoScalingGroupNginx", "ImageId", "ami-0b9fee3a2d0596", "InstanceType", "c5.xlarge", "device", "nvme0n1p1", "fstype", "ext4" ],
[ "...", "i-0aaaaab", ".", ".", ".", ".", ".", ".", ".", ".", ".", "." ]
],
"view": "timeSeries",
"stacked": false,
"region": "eu-west-1",
"title": "NGINX - DiskSpaceUtilization (/)",
"period": 300,
"yAxis": {
"left": {
"min": 0
}
}
}
},
{
"type": "metric",
"x": 12,
"y": 0,
"width": 12,
"height": 9,
"properties": {
"view": "timeSeries",
"stacked": false,
"metrics": [
[ "CWAgent", "disk_used_percent", "path", "/", "InstanceId", "i-0ccccccb", "AutoScalingGroupName", "ECSAutoScalingGroup", "ImageId", "ami-0b9fee3a2d0596ed1", "InstanceType", "m5.xlarge", "device", "nvme0n1p1", "fstype", "ext4" ],
[ "...", "i-0cccccc1", ".", ".", ".", ".", ".", ".", ".", ".", ".", "." ],
[ "...", "i-0cccccc2", ".", ".", ".", ".", ".", ".", ".", ".", ".", "." ],
[ "...", "i-0cccccc3", ".", ".", ".", ".", ".", ".", ".", ".", ".", "." ]
],
"region": "eu-west-1",
"yAxis": {
"left": {
"min": 0
}
},
"title": "ECS - DiskSpaceUtilization"
}
}
]
}
EOF
}
Ici, le fichier de configuration a été récupéré en exportant un dashboard créé à la main.
2.5 Conclusion
J'arrête ici ce chapitre car, mine de rien, l'objectif est rempli : on a tous les éléments pour faire remonter dans CloudWatch, les métriques nécessaires pour le bon suivi de notre applicatif.
Si vraiment votre applicatif nécessite de suivre une métrique non couverte par l'agent CloudWatch, pensez qu'il est toujours possible de le faire manuellement. C'est expliqué ici :
https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/publishingMetrics.html
Cela va donner quelque chose comme ceci :
aws cloudwatch put-metric-data --metric-name $CW_METRIC_NAME --namespace "Custom" --dimensions Instance=$INSTANCE_ID --value $RET --unit "Count" --region $AWS_REGION 2> /dev/null
Un peu plus tard dans cet article, lorsqu'on parlera des "log group", je vous montrerai une autre façon d'obtenir des métriques, comme par exemple le nombre d'erreurs de type XXXX dans un fichier sur 30 secondes.
Si les machines EC2 sont déjà construites et qu'il faut installer l'agent CloudWatch sur chacune d'elles, je vous détaillerai, dans la 3eme partie de cet article l'utilisation de "SSM" et la possibilité d'installer en masse sur vos machines des paquets et de les configurer.
3. Alerting : CloudWatch / Lambda : la combinaison gagnante
La notion d’”Alerting” est une notion pas forcément si simple. En fonction de votre organisation, de vos contraintes, l’alerting peut être plus ou moins souple. Ici, on va déjà mettre en place un “alerting 1er niveau” : La santé de l’infrastructure. J’y inclus donc les % de remplissage des filesystems, les métriques réseau, la consommation mémoire, cpu etc …
On va mettre en place l’alerting sur la surveillance du remplissage du “/”.
AWS a introduit la notion d’Autoscaling Group. Mine de rien, ca permet de rajouter de l’élasticité à votre infrastructure. Mais là n’est pas le propos. De nombreux outils “old school” d’alerting se base sur la notion d’un identifiant VM. C’est problématique car l’utilisation des auto-scaling group “casse” ce principe : les machines se créent à la volée et disparaissent. Si vos outils ne sont pas capables de s’adapter à ce principe, il faut penser à investir dans un autre produit. Sur AWS, on va utiliser le principe de “tag” qui nous permettra de nous adresser à un groupe de machines EC2.
Pour chaque machine EC2, on va créer une alerte concernant son “/”. Pour faire cela, on va utiliser terraform.
#######################
# Recuperation des references aux machines EC2 ECS
#######################
data "aws_instances" "ec2-ecshost" {
filter {
name = "tag:aws:autoscaling:groupName"
values = ["${var.auto_scaling_groupname}"]
}
}
#######################
# ECSHOST : Creation d'une Alarme sur le taux occupation FileSystem
#######################
resource "aws_cloudwatch_metric_alarm" "ecshost_fs" {
alarm_name = "${var.aws_prefix}-ecshost-fs-alarm-${count.index}"
comparison_operator = "GreaterThanOrEqualToThreshold"
evaluation_periods = "1"
metric_name = "disk_used_percent"
namespace = "CWAgent"
period = "60"
statistic = "Average"
threshold = "${var.cloudwatch_alarm_fs_thresold}"
alarm_description = "This metric monitors ecshost ${data.aws_instances.ec2-ecshost.ids[count.index]} % fs"
alarm_actions = [ "${aws_sns_topic.cw-alarm.arn}" ]
count = "${length(data.aws_instances.ec2-ecshost.ids)}"
dimensions {
path = "/"
InstanceId = "${data.aws_instances.ec2-ecshost.ids[count.index]}"
device = "xvda1"
fstype = "ext4"
}
}
data.aws_instances.ec2-ecshost contient la liste de nos machines. On la parcourt avec le “count” et “l’index”.
Vous aurez peut-être remarqué également l’attribut “alarm_actions”. Il fait référence à une liste de files SNS. On crée une file SNS comme ceci :
#######################
# Creation du topic de notification
#######################
resource "aws_sns_topic" "cw-alarm" {
name = "${var.aws_prefix}-${var.sns_topic_name}"
}
L'alarme va permettre de capter des événements. Pour traiter ces événements, le principe général est simple :

L’idée est de déposer un “event” dans une file (SNS, pour Simple Notification Service). L’arrivée de l’event déclenche une ou plusieurs fonctions lambda. Ces fonctions lambda vont servir à:
envoyer un mail
envoyer un message sur slack
appeler n’importe quel api (sms, création de ticket; etc …)
Détaillons ici la transmission de l’event à une API (Redmine en l’occurrence).
#######################
# Souscription de la fonction lambda au topic
#######################
resource "aws_sns_topic_subscription" "topic-subscription-cw-alarm" {
topic_arn = "${aws_sns_topic.cw-alarm.arn}"
protocol = "lambda"
endpoint = "${aws_lambda_function.createRedmineIssues.arn}"
}
Côté sécurité, comme toujours, vous ne pourrez rien faire si vous n’autorisez pas votre fonction lambda. On va donc créer une “permission” qu’on va lui affecter :
#######################
# Creation de la permission lambda
#######################
resource "aws_lambda_permission" "with_sns" {
statement_id = "AllowExecutionFromSNS"
action = "lambda:InvokeFunction"
function_name = "${aws_lambda_function.createRedmineIssues.arn}"
principal = "sns.amazonaws.com"
source_arn = "${aws_sns_topic.cw-alarm.arn}"
}
#######################
# Les policy nécessaires à la fonction lambda
#######################
resource "aws_iam_policy" "lambda_policy" {
name = "lambda_redmine"
path = "/"
description = "IAM policy for the lambda function"
policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "arn:aws:logs:*:*:*",
"Effect": "Allow"
}
]
}
EOF
}
Créons ensuite un rôle et associons la policy à ce rôle :
#######################
# Création du rôle associé à la fonction lambda
#######################
resource "aws_iam_role" "lambda_role" {
name = "lambda_role_redmine"
assume_role_policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "sts:AssumeRole",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Effect": "Allow",
"Sid": ""
}
]
}
EOF
}
#######################
# Association du rôle à la politique
#######################
resource "aws_iam_role_policy_attachment" "lambda_policy_attachment" {
role = "${aws_iam_role.lambda_role.name}"
policy_arn = "${aws_iam_policy.lambda_policy.arn}"
}
OK. Côté sécurité, on a terminé. Maintenant, il s’agit de coder la fonction lambda. Fonction assez basique : elle récupère de l’environnement de la fonction lambda des paramètres qu’elle utilise par la suite pour envoyer une requête de type HTTPS.
from __future__ import print_function
import boto3
import json
import logging
import os
from base64 import b64decode
from urllib2 import Request, urlopen, URLError, HTTPError
# The base-64 encoded, encrypted key (CiphertextBlob) stored in the kmsEncryptedHookUrl environment variable
redmine_api_key = os.environ['redmine_api_key']
redmine_api_url = "https://" + os.environ['redmine_api_url'] + "/issues.json"
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def lambda_handler(event, context):
logger.info("Event: " + str(event))
message = json.loads(event['Records'][0]['Sns']['Message'])
logger.info("Message: " + str(message))
alarm_name = message['AlarmName']
new_state = message['NewStateValue']
reason = message['NewStateReason']
instance_id = message['Trigger']['Dimensions'][0]['value']
redmine_message = {
'issue': {
'project_id': os.environ['redmine_project_id'],
'tracker_id': os.environ['redmine_tracker_id'],
'status_id': os.environ['redmine_status_id'],
'priority_id': os.environ['redmine_priority_id'],
'is_private': os.environ['redmine_is_private'],
'subject': "Instance ID : %s Alarm %s triggered" % (instance_id, alarm_name),
'description': "%s" % (reason)
}
}
req = Request(redmine_api_url, json.dumps(redmine_message))
req.add_header('Content-Type', 'application/json')
req.add_header('X-Redmine-API-Key', redmine_api_key)
try:
response = urlopen(req)
response.read()
logger.info("Ticket posted to project with ID : %s", os.environ['redmine_project_id'])
except HTTPError as e:
logger.error("Ticket failed to be created: %d %s", e.code, e.reason)
except URLError as e:
logger.error("Server connection failed: %s", e.reason)
Créons la fonction lambda en associant et le code python et le rôle :
#######################
# Definition de la fonction lambda avec
# association du role et du code python
#######################
resource "aws_lambda_function" "createRedmineIssues" {
filename = "createRedmineIssues.zip"
function_name = "createRedmineIssues"
role = "${aws_iam_role.lambda_role.arn}"
handler = "createRedmineIssues.lambda_handler"
runtime = "python2.7"
environment {
variables = {
redmine_api_key = "${var.redmine_api_key}"
redmine_api_url = "${var.redmine_api_url}"
redmine_priority_id = "${var.redmine_priority_id}"
redmine_project_id = "${var.redmine_project_id}"
redmine_status_id = "${var.redmine_status_id}"
redmine_tracker_id = "${var.redmine_tracker_id}"
redmine_is_private = "${var.redmine_is_private}"
}
}
}
C’est terminé. On a branché nos métriques à un “consommateur”, qu’il s’agisse de l’envoi d’un mail ou de la consommation d’une API.
