
Dans le cadre de notre série d’articles sur Couchbase Server, nous allons maintenant nous intéresser à la notion de cluster.
Un des aspects attractifs de Couchbase, c’est que la distribution des données sur plusieurs serveurs est très facile à comprendre et à mettre en œuvre.
Je vais tâcher de vous en convaincre dans le présent article ; pour cela, nous allons mettre en place un cluster Couchbase et simuler une situation de panne. Au passage, nous en apprendrons un peu plus sur la notion de réplication des données au sein du cluster.
Pourquoi créer un cluster ?
Couchbase est une technologie de base de données distribuée. C’est-à-dire que les données d’une même base sont réparties sur plusieurs serveurs que l’on nomme des nœuds.
L’ensemble des nœuds qui contribuent à héberger des données s’appelle un cluster (ou grappe en français).
Un cluster permet d’implémenter deux fonctions importantes :
- La scalabilité horizontale ;
- La disponibilité.
Scalabilité
Pour faire face à la croissance de la base de données ou de l’activité il faut disposer d’un levier pour augmenter les ressources, qu'il s'agisse de la capacité de traitement ou de stockage. Dans une base de données NoSQL distribuée cela se fait par l’ajout de nœuds au cluster. On appelle ça la scalabilité horizontale.
Chaque noeud étant hébergé sur une machine dédiée, la capacité physique du cluster augmente avec l’ajout de noeuds.
Couchbase donne la possibilité d’ajouter facilement un nœud au cluster ; nous verrons comment dans la suite de l’article.
Disponibilité
On considère qu’un système est disponible quand il est capable de répondre même en cas de panne d’un de ses composants ou d’un composant d’infrastructure.
Lorsqu’on distribue une base de données au sein d’un cluster, la perte d’un nœud du cluster ne doit pas empêcher le cluster de fonctionner. Mais encore faut-il que la part des données hébergée par le nœud défaillant ne soit pas perdue.
Couchbase met en œuvre un système de réplicas assurant que les données hébergées par un nœud ne seront pas perdues en cas de perte de ce nœud.
Principes de fonctionnement d’un cluster Couchbase
Nous allons présenter ici quelques éléments clés permettant de comprendre la distribution des données dans un cluster Couchbase. Ce faisant, je vous indiquerai les liens vers la documentation qui vous permettra d'appréhender le sujet dans le détail.
Tout d’abord, il peut être utile de consulter la page Terminology qui donne une définition des concepts généraux.
Topologie du cluster
Le document Distributed Data Management donne un aperçu global des notions de distribution et de réplication.
Tout d’abord, il faut retenir que Couchbase est conçu de telle sorte qu’il n’y a pas de hiérarchie entre les noeuds. Pour ceux qui seraient habitués à d’autres systèmes de distribution (celui de MongoDB par exemple), il faut savoir qu’il n’y a pas de notion de maître/esclave dans Couchbase.
Cependant chaque noeud héberge un certain nombre de services (Data Service, Query Service) qu’il est possible d’activer ou de désactiver. Dans le cas où certains services ne sont hébergés que par certains noeuds, on ne peut pas considérer que les noeuds sont équivalents.
Il y a donc deux approches possibles pour construire la topologie de son cluster Couchbase.
- Une approche simple dans laquelle tous les noeuds jouent le même rôle en exécutant tous les même services ;
- Une approche plus complexe appelée Multi-Dimensional Scaling permettant d’optimiser les performances du cluster en allouant différemment les ressources pour les différents services.
Les opérations de niveau cluster sont assurées par le Cluster Manager, service qui s’exécute de façon distribuée sur tous les noeuds.
Distribution et réplication au sein du cluster
Dans Couchbase, l’unité de base de données est l’item (selon la terminologie) mais on peut aussi l’appeler document.
Au sein d’un cluster on trouvera, pour un document donné (identifié par un identifiant unique), une copie active du document hébergée sur un noeud précis et jusqu’à trois réplicas hébergés sur d’autres noeuds.
Au sein d’un cluster, les items sont regroupés dans des partitions appelées vBuckets.
Internally, Couchbase Server uses a mechanism called vBuckets (synonymous to shard or partition) to automatically distribute data across nodes, a process sometimes known as "auto-sharding". vBuckets help enable data replication, failover, and dynamic cluster reconfiguration.
Sur chaque serveur il existe des vBuckets actifs et des vBuckets de réplicas.
Lorsqu’on accède à un document, c’est toujours la copie active qui est accédée. Si un noeud du cluster devient indisponible les vBuckets de réplicas présents sur d’autre serveurs deviennent actifs à leur tour pour continuer à servir la donnée. C’est ce que l’on nomme le mécanisme de failover.
Mécanismes de Failover et Rebalance
Le Failover est l’opération qui consiste à retirer un noeud du cluster. C’est à cette occasion que les vBucket réplicas deviennent actifs sur les autres noeuds.
Le Rebalance est l’opération qui consiste à redistribuer les vBuckets au sein du cluster afin d’obtenir une distribution équilibrée.
Il existe trois modes de Failover :
- Graceful failover : on retire un noeud du cluster volontairement; dans ce cas on n’a pas d’interruption de service ;
- Hard failover : on retire manuellement un noeud que l’on a détecté comme étant défectueux. Dans ce cas, tant que le noeud défectueux n’a pas été retiré, le cluster ne fonctionne plus ;
- Automatic failover : le cluster peut, s’il est paramétré pour, retirer automatiquement un noeud qui ne répond plus.
Il faut noter que l’Automatic Failover n’est pas activé par défaut dans Couchbase. Ceci car il faut respecter certaines règles dans le dimensionnement du cluster pour que le failover automatique se passe sans risque.
Toute opération de Failover d’un noeud doit être suivie d’une opération de Rebalance.
Réplication entre data-centers
Le mécanisme de réplication interne au cluster est utilisé pour assurer la redondance et donc la disponibilité des données en cas de panne d’un noeud au sein d’un réseau local.
Par ailleurs Couchbase dispose également d’un mécanisme de réplication entre deux clusters qui peuvent par exemple représenter deux data centers éloignés géographiquement. Ce mécanisme est appelé XDCR pour Cross Datacenter Replication.
XDCR n’est pas le sujet de cet article mais il est très important de savoir que ce service existe, il fait de Couchbase une technologie appréciée pour sa capacité à répliquer de façon transparente des données entre deux zones distantes.
Mise en place d’un cluster de test
Nous allons créer un cluster de trois nœuds qui seront nommés :
- couchbase-node-1
- couchbase-node-2
- couchbase-node-3
Création du cluster avec un premier nœud
Comme dans le premier article, nous allons démarrer un premier nœud contenant des données à l’aide de l’image docker sandbox de Couchbase.
docker run -t --name couchbase-node-1 -p 8091-8094:8091-8094 -p 11210:11210 couchbase/sandbox:5.0.0-beta
En réalité, l’image sandbox crée un cluster avec un nœud et un bucket contenant des données.
On accède à l’interface d’administration : http://localhost:8091 [Administrator/password].
L’écran Servers nous montre tous les nœuds du cluster.
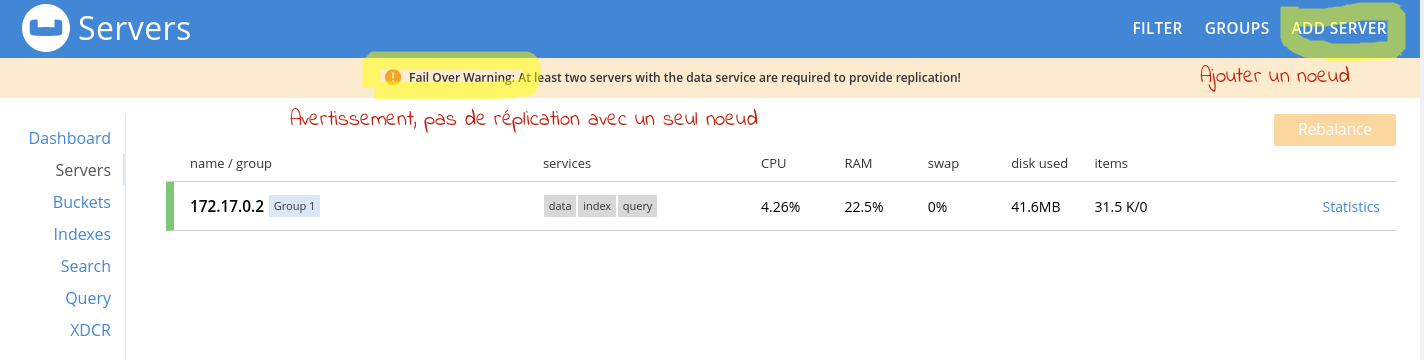
On constate ici que le cluster ne dispose que d’un nœud et Couchbase nous avertit que, dans ces conditions, le système de réplicas ne peut pas être opérationnel.
En effet le bucket travel-sample qui est défini dans l’image sandbox est configuré de telle sorte que chaque document doit avoir un réplica.
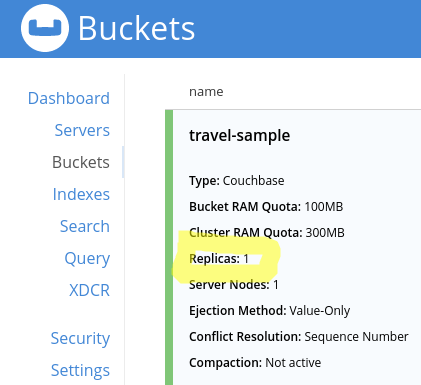
Il faut donc plus d’un nœud au cluster pour que le système de réplicas soit opérationnel.
Ajout de nœuds au cluster
Sur la même machine, on démarre deux nœuds supplémentaires en entrant les commandes suivantes :
docker run -t --name couchbase-node-2 -d couchbase/server:community-5.0.1
docker run -t --name couchbase-node-3 -d couchbase/server:community-5.0.1
Remarque : dans le cadre de cet article, on utilise Docker pour simuler facilement un réseau de trois serveurs hébergeant chacun un noeud Couchbase. En situation de production, on hébergerait les noeuds sur des serveurs distincts.
Astuce : par la suite, il va nous falloir l’adresse IP de ces deux nœuds au sein du réseau docker. On peut afficher l’adresse IP du nœud couchbase-node-2 (par exemple) à l’aide de la commande suivante :
docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' couchbase-node-2
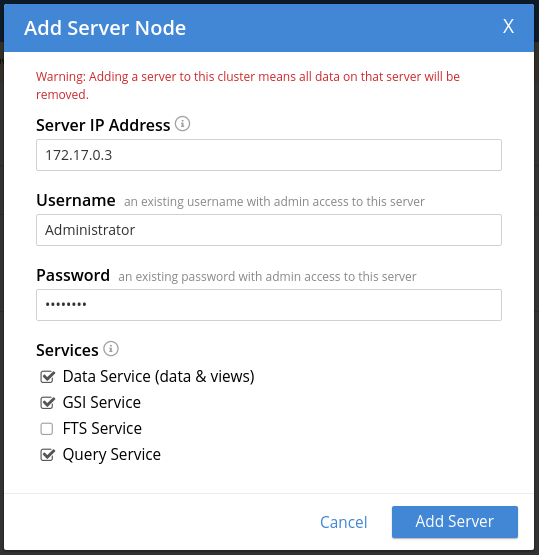
Pour ajouter un nœud au cluster, on clique sur le bouton ADD SERVER que l’on a vu dans l’écran Servers (voir la copie d’écran plus haut).
C’est ici qu’il faut saisir l’adresse IP du nœud.
Après avoir ajouté les deux nœuds couchbase-node-2 et couchbase-node-3 au cluster on les voit dans l’écran Servers.
Cependant, ce n’est pas encore terminé. Il faut lancer une opération de répartition des documents sur le cluster car, dans l’état actuel, la distribution des documents sur les trois nœuds n’est pas effective. Cette opération s’appelle Rebalance.
Regardons dans la colonne items pour chacun des nœuds. On voit que le nœud couchbase-node-1 (celui qui a l’adresse IP 172.17.0.2 dans l’exemple) héberge 31,5 K documents alors que les autres nœuds n’en hébergent pas.
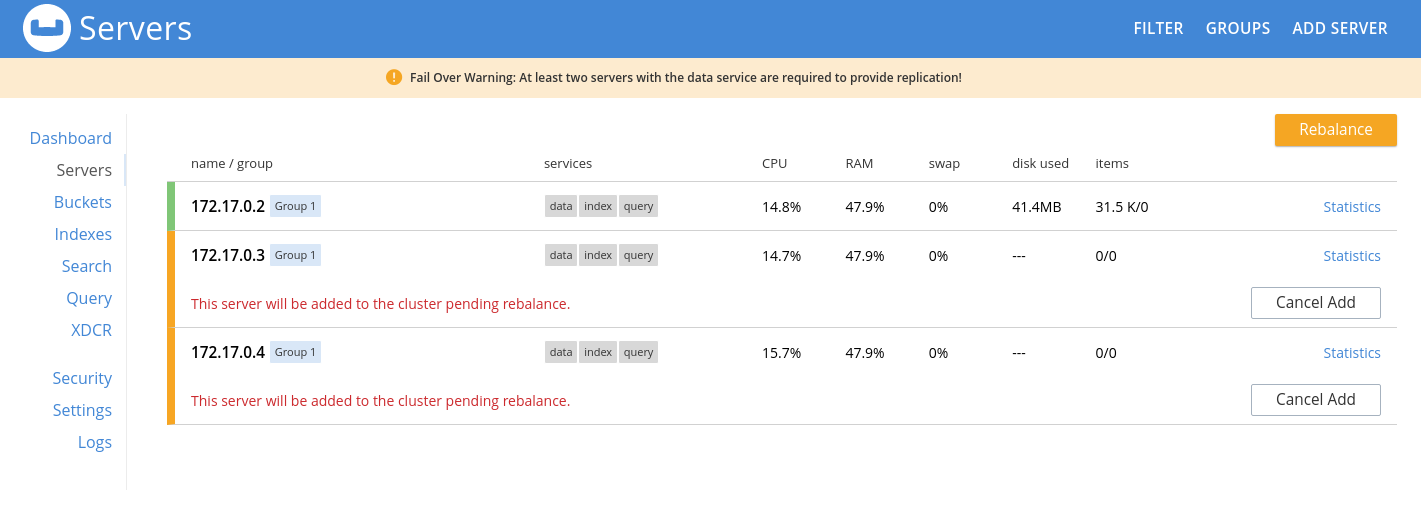
Pour distribuer les documents sur tous les nœuds du cluster, on clique sur le bouton Rebalance.
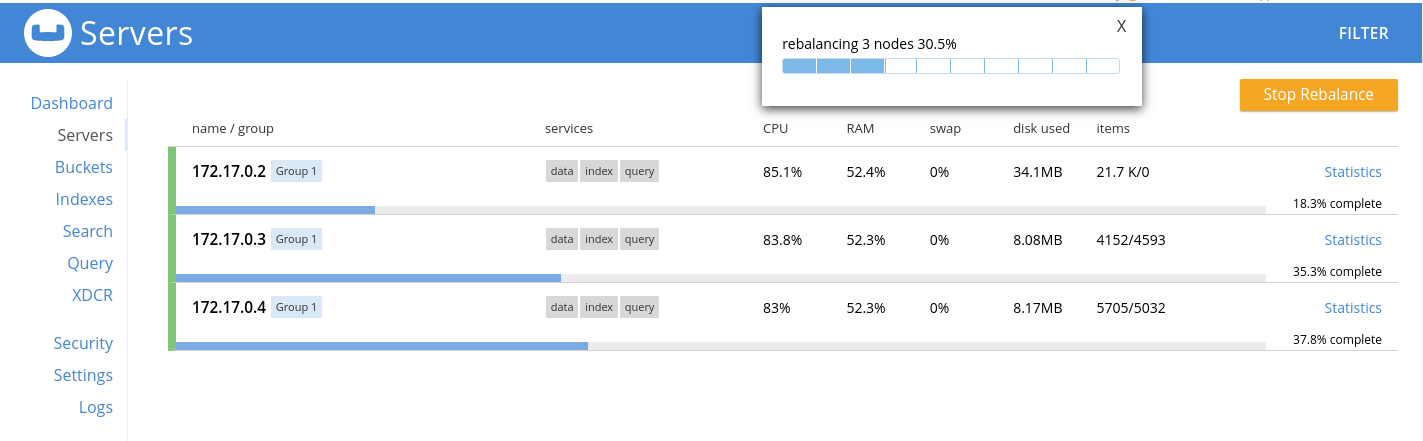
L’opération dure quelques instants mais l’interface d’administration affiche une barre de progression.
Une fois le Rebalance terminé, on voit que la distribution des documents est équitable : on a trois nœuds ; chaque nœud héberge environ 10 000 documents (voir la colonne Items).

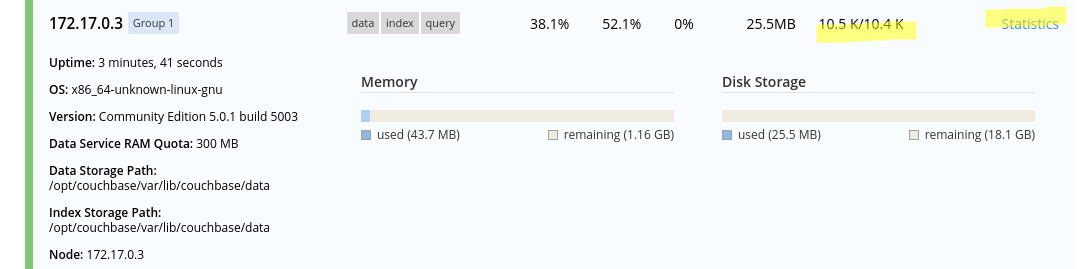
Nous allons inspecter plus précisément un nœud en particulier, le nœud couchbase-node-2.
L’écran ci-dessous nous indique que ce nœud héberge environ 10 500 documents actifs et 10 400 replicas.
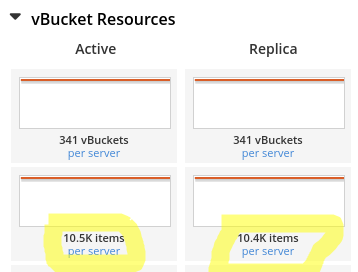
En cliquant sur le lien Statistics, on voit toutes les métriques du nœud. Dans la section vBucket, on voit effectivement le nombre de documents actifs et de réplicas.
Simulation d’une panne et failover
Nous allons maintenant faire tomber le nœud couchbase-node-2 pour voir ce qui se passe au niveau du cluster.
Il suffit de stopper le conteneur docker qui héberge le nœud.
docker stop couchbase-node-2
De retour dans l’interface d’administration, on voit maintenant que le nœud est tombé.
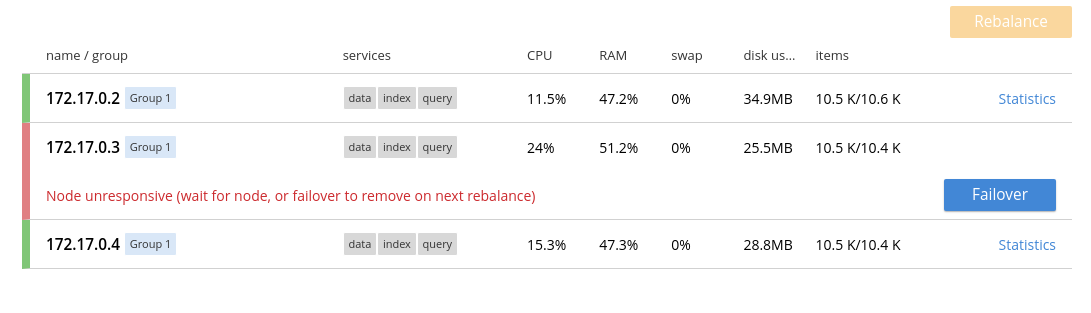
À ce stade, le cluster est inutilisable. En effet, le nœud couchbase-node-2 ne répondant pas, un tiers des documents n’est pas accessible. Le cluster refusera tout simplement de répondre à toute requête. Pour que le cluster réponde à nouveau, il faut explicitement déclarer le nœud couchbase-node-2 comme perdu, ce que nous allons faire en cliquant sur le bouton Failover.

L’opération de failover a effectué les deux choses suivantes :
- Le nœud couchbase-node-2 a été mis hors service ;
- Les réplicas des documents qui étaient hébergés par le nœud couchbase-node-2 ont été activés sur les autres nœuds afin d’être rendus à nouveau accessibles.
Si on regarde la colonne items, pour le nœud 1 par exemple, on remarque qu’il y a 15 000 documents actifs et environ 5000 réplicas. En fait, les 5000 réplicas de documents appartenant au nœud 2 sont devenus actifs.
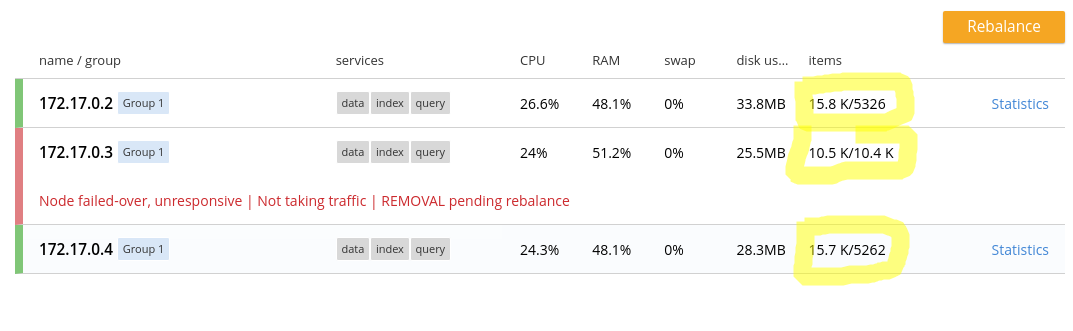
Au point où nous en sommes, le cluster se remet à fonctionner, cependant la situation n’est pas durable car le cluster est déséquilibré et les documents initialement hébergés par le nœud 2 n’ont plus de réplica.
Il faut effectuer une opération de Rebalance. A l’issue de cette opération nous avons à nouveau un cluster équilibré, cependant il tourne à présent sur deux nœuds, ce qui n’était pas notre situation de départ.

Il ne nous reste plus qu’à démarrer un nouveau nœud Couchbase, à l’ajouter au cluster et à « rebalancer » à nouveau le tout pour retrouver notre cluster initial.
